
HQL、Criteria查询详解,离线查询,查询优化
HQL查询详细
排序
正序
from com.jinxin.bean.Customer order by cust_id asc
反序
from com.jinxin.bean.Customer order by cust_id desc
实例:
Session session = HBUtils.currentSession();
Transaction tx = session.beginTranaction();
// ===========================
String hql = "from com.jinxin.bean.Customer order by cust_id asc";
Query query = session.createQuery(hql);
List<Customer> lists = query.list();
// ===========================
tx.commit();
聚合函数
| 函数 | 说明 |
| count() | 计数总列数 |
| sum() | 求和 |
| avg() | 求平均数,浮点型,因为平均数不一定为整数 |
| max() | 求最大值 |
| min() | 求最小值 |
实例:
String hql = "select count(*) from com.jinxin.Customer"; Query query = session.createQuery(hql); Number number = (Number) query.uniqueResult();
聚合函数的结果使用Number类接收,Number类是所有基本类型包装类的父类,因为聚合函数的结果不全为整数,所以用Number类接收一定没错!
投影查询
投影查询说白了就是只查询数据库表的某一列或者某几列,并不把所有的列都查询出来
例如:select cust_name from com.jinxin.bean.Customer 就是只查询名字这一列
String hql = "select cust_id, cust_name from com.jinxin.bean.Customer"; Query query = session.createQuery(hql); List<Object[]> lists = query.list();
上面的代码使用投影查询返回的是List<Object[]>类型,每条查询结果是一个Object数组,这样得到的结果显然不太好操作,那么能不能将这些结果封装成对应的实体类对象呢?显然可以
如果想要在返回的时候得到的是实体类对象集合,那么hql语句就应该如下书写
select new Customer(cust_id, cust_name) from com.jinxin.bean.Customer
像上面这样查询需要在对应的实体类中创建相应参数的构造方法,而且还有加上无参构造方法,因为书写了构造方法,默认的无参构造就不在了,这显然不符合Hibernate实体创建规则
在实体类对象Customer.java中添加对应参数的构造方法
public Customer(Long cust_id, String cust_name){
this.cust_id = cust_id;
this.cust_name = cust_name;
}
public Customer(){
super();
}
实例:
String hql = "select new Customer(cust_id, cust_name) from Customer"; Query query = session.createQuery(hql); List<Customer> lists = query.list();
多表查询
原生sql多表查询
交叉连接(笛卡尔积)
select * from a, b
内连接
- 隐式内连接:select * from A, B where b.id = a.id
- 显示内连接:select * from A inner join B on b.id = a.id
外连接
- 左外:select * from A left join B on b.id = a.id
- 右外:select * from A right join B on b.id = a.id
内连接、左外、右外查询关系
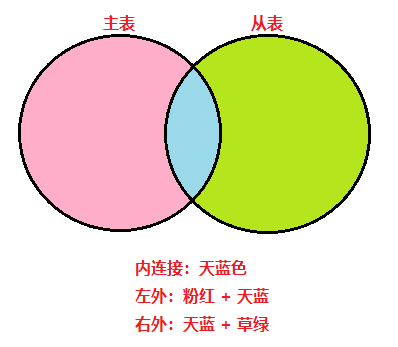
HQL多表查询
内连接
普通内连接
from Customer c inner join c.linkMans (linkMans为存储另一个实体类对象的集合)
String hql = "from Customer c inner join c.linkMans"; Query query = session.createQuery(hql); // Object数组中封装了两个对象,Customer跟LinkMan对象 List<Object[]> lists = query.list();
迫切内连接
from Customer c inner join fetch c.linkMans 迫切内连接与普通内连接相比多了一个fetch关键字
String hql = "from Customer c inner join c.linkMans"; Query query = session.createQuery(hql); // 迫切内连接只有Customer一个对象,linkMan被封装到Customer的那个集合里面了 List<Customer> lists = query.list();
外连接
左外连接
from Customer c left join c.linkMans
左外连接也分普通的左外跟迫切左外
String hql = "from Customer c left join c.linkMans"; Query query = session.createQuery(hql); // 出现所有的Customer列跟被关联了的LinkMan列 List<Object[]> lists = query.list();
右外连接
from Customer c right join c.linkMans
右外连接同样分为普通右外跟迫切右外
String hql = "from Customer c right join c.linkMans"; Query query = session.createQuery(hql); // 出现所有的LinkMan列跟关联了的Customer列 List<Object[]> lists = query.list();
Object对象查询(扩展)
HQL当想要查询某张表时,只需要 from 该表的实体类就可以了,那么,如果将这个对象换成 java.lang.Object后会怎样呢?
String hql3 = "from java.lang.Object"; // 会查询所有的表 Query query = session.createQuery(hql3); List list = query.list();
当把实体类对象换成 Object 对象后,这条指令将会查询数据库所有的表,这样做的好处就是。。。没有好处,试想一下,如果表的数量非常非常多,这时候执行这条查询,估计和死循环差不多了。
So,该方法了解即可,绝对不推荐使用!
Criteria语法详解
基本查询
Criteria c = session.createCriteria(Customer.class); List<Customer> lists = c.list();
排序
正序
Criteria c = session.createCriteria(Customer.class);
c.addOrder(Order.asc("cust_id")); // 正序
List<Customer> lists = c.list();
反序
Criteria c = session.createCriteria(Customer.class);
c.addOrder(Order.desc("cust_id")); // 反序
List<Customer> lists = c.list();
统计
即使用聚合函数
Criteria c = session.createCriteria(Customer.class); c.setProjection(Projections.rowCount()); List<Customer> lists = c.list();
离线查询
在使用criteria查询数据库时,因为查询的条件不同,需要些不同的查询方法,而如果使用离线查询,在web层或者service层就组装好了查询条件,因此,不论查询条件如何,在Dao层只需要写一个查询方法就好了
如图:
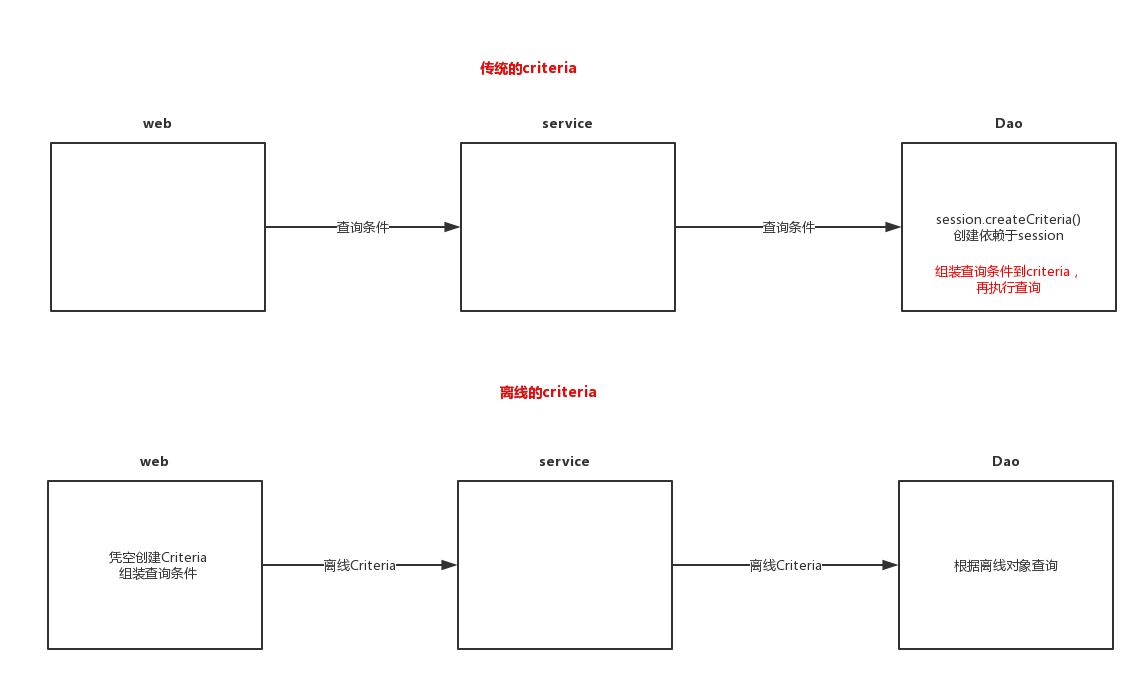
上图很好的阐述了离线查询与传统的查询的区别,即组装查询的位置变换了
service / web
在service或者web层组装查询条件
DetachedCriteria dc = DetachedCriteria.forClass(Customer.class); dc.add(Restrictions.idEq(6L)); // 拼装条件(与普通的Criteria一致)
Dao
在Dao层查询
Criteria c = dc.getExecutableCriteria(session); // 将离线Criteria转换成传统的Criteria List list = c.list();
查询优化
类级别查询
- get()方法:没有任何策略,使用时立即查询数据库的数据
- load()方法:应用类级别的加载策略,在执行时,不发送任何的SQL语句,返回一个对象,使用该对象时,才执行查询
懒加载|延迟加载
使用懒加载时仅仅获得对象,没有使用对象就不会查询,使用对象时才进行查询
public void fun1(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//---------------------------------------------------------
Customer c = session.get(Customer.class, 2l); // 使用get()方法进行查询,程序执行到这里就向想数据库查询数据
System.out.println(c);
//----------------------------------------------------------
tx.commit();
session.close();
}
public void fun2(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//---------------------------------------------------------
Customer c = session.load(Customer.class, 2l); // 使用load()方法进行查询,程序执行到这里不会查询
System.out.println(c); // 在该处使用到该对象时才会向数据库查询数据
//----------------------------------------------------------
tx.commit();
session.close();
}
配置是否懒加载
配置某个实体类对象是否使用懒加载,应该在其相应的orm元数据配置文件中配置
<class name="Customer" table="cst_customer" lazy="false"></class>
lazy属性:
- true(默认值):即使用懒加载,查询类时,会返回代理对象,会在使用属性时,根据关联的session查询数据库。
- false:将lazy属性设置为false后,load方法会与get方法的没有任何区别。调用时立即加载数据
所以,为了提高效率,建议使用懒加载
注意:使用懒加载时要确保调用属性加载数据时,session还是打开的,否则会抛出 no - session 的异常
关联级别查询
集合策略
对于一对多来说,一的一方掌握着多的一方的集合,那么在使用该集合的时候也会有相关的查询策略
关于集合策略的两个属性,以及取值
- lazy属性:决定是否进行延迟加载
- true(默认值):延迟加载
- false:立即加载
- extra:极其懒惰
- fetch属性:决定加载策略,使用什么类型的Sql语句加载集合
- select(默认值):单表查询加载集合
- join:使用多表查询加载集合
- subselect:使用子查询加载集合
lazy属性跟fetch属性都可以在orm元数据中通过相关的配置来改变值
<set name="linkMens" lazy="extra" fetch="subselect">
extra极其懒惰的效果与懒加载的效果基本一致,只有在获取集合的size时,才会体现出区别,极其懒加载在获取集合的size时会使用聚合函数count()进行查询,就仅仅只是获取数据库数据的条数而已
public void fun3(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//---------------------------------------------------------
Customer c = session.get(Customer.class, 2l);
Set<LinkMan> linkMens = c.getLinkMens();// 关联级别
System.out.println(linkMens.size()); // 在这里extra会使用聚合函数count()向数据库查询记录的条数
System.out.println(linkMens);
//----------------------------------------------------------
tx.commit();
session.close();
}
关联策略
对于一对多来说,多的一方查询时也有相关的查询策略
关于关联策略的两个属性
- lazy属性:决定是否进行延迟加载
- false:立即加载
- proxy:由一的一方的对象的类级别加载策略决定,即lazy属性的值与其一致
- fetch属性:决定加载策略,使用什么类型的Sql语句加载集合
- select(默认值):单表查询加载集合
- join:使用多表查询加载集合
在orm元数据中进行相关的配置
<many-to-one name="customer" column="lkm_cust_id" class="Customer" fetch="join" lazy="proxy"></many-to-one>
需要注意的是,不论是集合策略还是关联策略,当fetch属性配置成了join多表查询后,会一次性将数据都取出来,所以lazy属性设置为何值,都会失效
结论: 为了提高效率,fetch的选择应为select, lazy的取值应该选取true(即全部使用默认值)
批量抓取
关于批量抓取的一个属性
batch-size属性:当该属性设置为几表示一次抓取几个对象的集合,比如batch-size="3"表示抓取客户集合时,一次抓取3个客户的联系人的集合
在orm元数据中配置
<set name="linkMens" batch-size="3">
例:
public void fun1(){
Session session = HibernateUtils.openSession();
Transaction tx = session.beginTransaction();
//---------------------------------------------------------
String hql = "from Customer";
Query query = session.createQuery(hql);
List<Customer> list = query.list();
// 如果不设置批量抓取,测每次循环都会去数据库查询当前客户的联系人
// 如果设置了batch-size="3",则一次抓取三个客户的联系人集合,即每三次循环查询一次
for(Customer c : list){
System.out.println(c.getLinkMens());
}
//----------------------------------------------------------
tx.commit();
session.close();
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号