哈希集合和哈希表——分离链表法
哈希表的核心:
1、使用散列函数将键转化为数组索引
2、碰撞处理,即处理两个键的散列值相同时的情况
分离链接法
基本原理和步骤:
1、初始化一个链表数组(即哈希表)
2、将键转化为数组索引:
将键key转化为哈希码(hashCode()),然后调用哈希函数(hash())转化为数组的索引
3、碰撞处理:
每个数组的元素是一个链表,得到索引后进入链表,可以用equals()比较链表中的key与传入的key是否存在,进而处理冲突
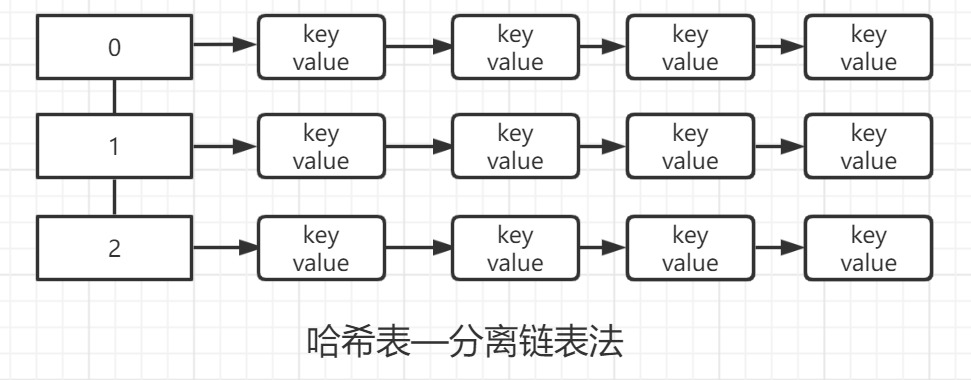
4、完成哈希表的remove(),contains(),isEmpty(),get(),put()等操作。
代码实现
由于需要key、value两个值和一个指向下一节点的next,所以需要自定义链表
点击查看自定义链表代码
public class SequentialSearchST<Key, Value> {
private Node first;
private class Node {//链表节点
Key key;
Value value;
Node next;
public Node(Key key, Value value, Node next) {
this.key = key;
this.value = value;
this.next = next;
}
}
public Value get(Key key) {
for (Node node = first; node != null; node = node.next) {
if (node.key.equals(key)) {
return node.value;
}
}
return null;
}
public void put(Key key, Value value) {
/*if (get(key) != null) {//当key存在时
Node node = first;
while (node != null) {
if (node.key.equals(key)) {
node.value = value;
break;
}
node = node.next;
}
} else {//当key不存在时
Node node = first;
while (node.next != null) {
node = node.next;
}
node.next = new Node(key, value, null);
}*/
for (Node node = first; node != null; node = node.next) {
if (node.key.equals(key)) {//命中
node.value = value;
return;
}
}
first = new Node(key, value, first);//未命中
}
public void remove(Key key){//这里的删除并不是删除节点,而是将键对应的值改为null
for (Node node=first; node!=null ; node=node.next) {
if(node.key.equals(key)) {
node.value=null;
return;
}
}
}
}
1、初始化哈希表(一般初始化数组的长度为素数,这样能使键值对分布更平均,减少查询时间,提高效率)
private int M;//键值对总数
private int N;//散列表大小
private SequentialSearchST<Key, Value>[] st;
public SeparateChainingHashTable() {
this(97);
}
public SeparateChainingHashTable(int M) {//创建M条链表
this.M = M;
st = (SequentialSearchST<Key, Value>[]) new SequentialSearchST[M];
for (int i = 0; i < M; i++) {
st[i] = new SequentialSearchST<>();
}
}
2、将键转化为数组索引(hashCode()使用key类型自己的,一般Java已经帮你写好了,比如String已经默认实现了hashCode())
public int hash(Key key) {
//通过%M可以不发生数组索引越界
return key.hashCode() % M;
}
3、处理碰撞以及各种方法的实现
3.1、get() 方法实现
点击查看get()代码
public Value get(Key key) {
return (Value) st[hash(key)].get(key);
}
public Value get(Key key) {
for (Node node = first; node != null; node = node.next) {
if (node.key.equals(key)) {
return node.value;
}
}
return null;
}
3.2、remove() 方法实现
remove() 方法的实现有两种方式
- 第一种是删去整个节点
- 第二种是将key键对应的值赋为null,达到删除节点的效果。
点击查看remove()代码
public void remove(Key key){
st[hash(key)].remove(key);
N--;
}
public void remove(Key key){//这里的删除并不是删除节点,而是将键对应的值改为null
for (Node node=first; node!=null ; node=node.next) {
if(node.key.equals(key)) {
node.value=null;
return;
}
}
}
3.3、put() 方法实现
点击查看代码
public void put(Key key, Value value) {
st[hash(key)].put(key, value);
N++;
}
public void put(Key key, Value value) {
for (Node node = first; node != null; node = node.next) {
if (node.key.equals(key)) {//命中
node.value = value;
return;
}
}
first = new Node(key, value, first);//未命中
//下面这段是第一次写出来的,可以忽略不看
/*if (get(key) != null) {//当key存在时
Node node = first;
while (node != null) {
if (node.key.equals(key)) {
node.value = value;
break;
}
node = node.next;
}
} else {//当key不存在时
Node node = first;
while (node.next != null) {
node = node.next;
}
node.next = new Node(key, value, null);
}*/
}
3.4、isEmpty() 方法实现
点击查看isEmpty()代码
public boolean isEmpty() {
return N == 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号