7.27笔记 1(Redis的穿透,击穿,雪崩)
Redis的穿透
例如一张数据库表的ID都是从1开始递增。但是如果请求查找的ID都是负数,那么Redis就毫无意义,每一次查找请求都会由数据库处理,只不过每一个都返回空罢了。
缓存穿透就是一直在查一堆不存在的数据,缓存就会出现大量不命中的现象,所以请求就全走数据库了。可能回导致数据库崩溃,以及整个服务瘫痪
解决方案:
- 对于不存在的数据(布隆过滤器),应该在发起请求之前进行校验拦截。不合法的数据请求不能到数据库层
- 使用锁去控制数据库的请求,避免大量请求同时对数据库发起请求
Redis的雪崩(很多数据都失效)
Redis的作用:
1,因为Redis是在内存中的,而数据库是在硬盘中持久化。
内存的访问速度明显快于内存的访问速度。这就是Redis快的原因
2,缓存分担了一部分的sql请求,支持了更高的并发
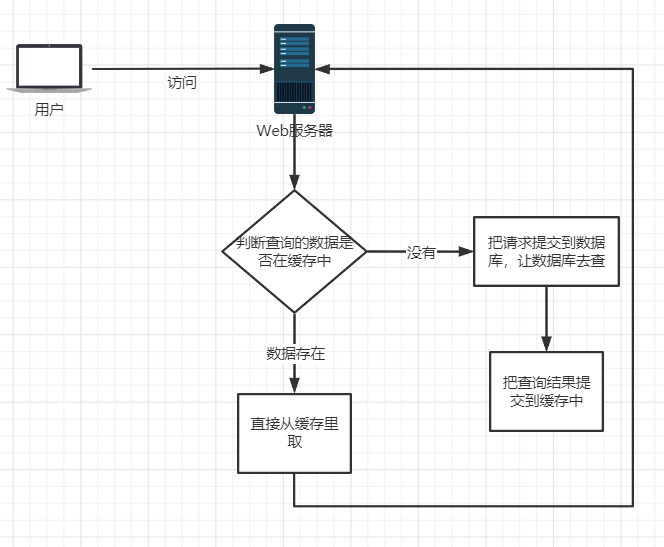
雪崩的情况
首先Redis无法把数据库的所有数据都存到缓存中,内存和硬盘没有可比性。因此Reids要对缓存进行定期删除(惰性删除+定期删除),并对删除的缓存进行持久化。
那么当Redis刚把一批缓存删除后,大量数据访问Redis,导致了Redis重启甚至失效。那么大量数据直接取访问数据库,增大了数据库的压力,甚至崩溃
解决方案
- 随机设置缓存的失效时间,防止同一时间大量数据缓存失效
- 设置热点数据永不过期
- 缓存数据库分布式部署
Redis的击穿(并发查询同一条数据)
缓存的击穿是指缓存中没有,但是数据库中却有(大概率是由于缓存失效导致的)。此时有正好并发量很大,同时去读取缓存又没读到,那么他们就会一起去读数据库。依然增大了数据库的压力
解决方案
-
设置热点数据,热点数据永不过期,这就减少了击穿的概率
-
接口的限流,熔断,降级:重要接口要进行限流操作,防止用户的恶意操作,当接口中的某些服务不可用时,要进行熔断,快速返回机制
-
使用布隆过滤器:就是一个hash set,用来快速判断某个元素是否存在于集合中
布隆过滤器:是由布隆在1970年提出的,是由很长的二进制向量和一系列的随机映射函数组成,布隆过滤器的作用就是检索一个元素是否在集合中。
布隆算法相当于一个hash set,但是和传统的hash set 不同的是这个算法不需要存储key,对于每个key,只需要k个比特位来存储key是否在集合中
算法过程
在判断key是否在集合中,只需要用k个hash函数算出k个散列值,并查询数据中的对应比特位,如果这个比特位为一,则验证在集合中存在(不需要存贮key,节约空间)
优点是:
- 空间效率和查询时间都远超过一般的算法。
- 插入效率和查询效率都是常数
- 布隆过滤器本身并不保存数据,使用于保密严格高的场合
缺点就是:
- 有一定的误识别的概率(布隆过滤器会给出存在,但是整个元素并不在集合里),
- 以及删除困难,
- 但是不会出现识别错误的情况
-
加互斥锁:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号