数据库
数据库
MySQL服务器逻辑框架
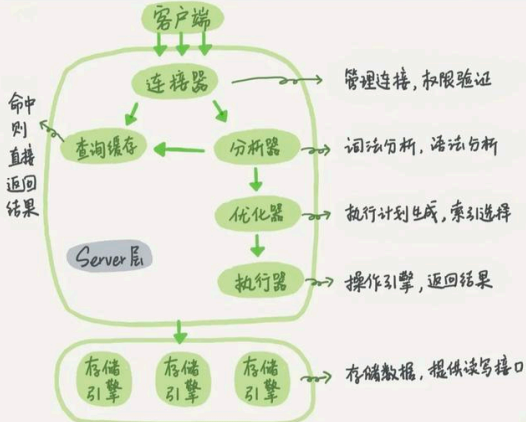
(1)第一层:处理客户端连接、授权认证等。
(2)第二层:服务器层,负责查询语句的解析、优化、缓存以及内置函数的实现、存储过程等。
(3)第三层:存储引擎,负责MySQL中数据的存储和提取。MySQL中服务器层不管理事务,事务是由存储引擎实现的。MySQL支持事务的存储引擎有InnoDB、NDB Cluster等,其中InnoDB的使用最为广泛;其他存储引擎不支持事务,如MyIsam、Memory等。
事务
事务(Transaction)指一个操作,由多个步骤组成,要么全部成功,要么全部失败。
举例:转账,假设A账户向B账号转账,那么涉及两个操作:
从 A 账户扣钱。
往 B 账户加入等量的钱。
这种场景下,不能A 账户扣了钱,B 账户却没加钱的情况,要么同时成功并提交,要么同时失败并回滚。
提交与回滚
典型的MySQL事务操作形式如下:
start transaction; # 标识事务开始
…… #一条或多条sql语句
commit; # 提交事务
如果sql语句执行出现问题,会调用rollback,回滚所有已经执行成功的sql语句。当然,也可以在事务中直接使用rollback语句进行回滚。
MySQL中默认采用的是自动提交(autocommit)模式,如下所示:
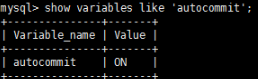
在自动提交模式下,如果没有start transaction显式地开始一个事务,那么每个sql语句都会被当做一个事务执行提交操作。
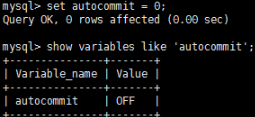
如果关闭了autocommit,则所有的sql语句都在一个事务中,直到执行了commit或rollback,该事务结束,同时开始了另外一个事务。
事务四大特性
A 原子性(Atomicity):作为一个整体,包含在其中的对数据库的操作要么全部被执行,要么都不执行
- 实现主要基于undo log
C 一致性(Consisstency):事务在执行前后,数据库必须满足一些预定义的一致性规则,否则回滚
- 实现主要基于redo log
I 隔离性(Isolation):多个事务并发执行时,一个事务的执行不影响其他事务的执行
- 实现主要基于锁机制(包含next-key lock)、MVCC(包括数据的隐藏列、基于undo log的版本链、ReadView)
D 持久性(Durability):已被提交的事务对数据库的修改应该永久保存在数据库中
- 事务追求的最终目标,一致性的实现既需要数据库层面的保障,也需要应用层面的保障
事务日志
-
undo log(回滚日志)
当事务对数据库进行修改时,InnoDB会生成对应的undo log;当事务对数据库进行修改时,InnoDB会生成对应的undo log;
undo log属于逻辑日志,它记录的是sql执行相关的信息。当发生回滚时,InnoDB会根据undo log的内容做与之前相反的工作:
-
对于每个insert,回滚时会执行delete;
-
对于每个delete,回滚时会执行insert;
-
对于每个update,回滚时会执行一个相反的update,把数据改回去。
当事务执行update时,其生成的undo log中会包含被修改行的主键(以便知道修改了哪些行)、修改了哪些列、这些列在修改前后的值等信息,回滚时便可以使用这些信息将数据还原到update之前的状态
-
-
redo log(重做日志)
背景:InnoDB作为MySQL的存储引擎,数据是存放在磁盘中的,但如果每次读写数据都需要磁盘IO,效率会很低。为此,InnoDB提供了缓存(Buffer Pool),Buffer Pool中包含了磁盘中部分数据页的映射,作为访问数据库的缓冲:当从数据库读取数据时,会首先从Buffer Pool中读取,如果Buffer Pool中没有,则从磁盘读取后放入Buffer Pool;当向数据库写入数据时,会首先写入Buffer Pool,Buffer Pool中修改的数据会定期刷新到磁盘中(这一过程称为刷脏)。
Buffer Pool的使用大大提高了读写数据的效率,但是也带了新的问题:如果MySQL宕机,而此时Buffer Pool中修改的数据还没有刷新到磁盘,就会导致数据的丢失,事务的持久性无法保证。
于是,redo log被引入来解决这个问题:当数据修改时,除了修改Buffer Pool中的数据,还会在redo log记录这次操作;当事务提交时,会调用fsync接口对redo log进行刷盘。如果MySQL宕机,重启时可以读取redo log中的数据,对数据库进行恢复。redo log采用的是WAL(Write-ahead logging,预写式日志),所有修改先写入日志,再更新到Buffer Pool,保证了数据不会因MySQL宕机而丢失,从而满足了持久性要求。
既然redo log也需要在事务提交时将日志写入磁盘,为什么它比直接将Buffer Pool中修改的数据写入磁盘(即刷脏)要快呢?主要有以下两方面的原因:
(1)刷脏是随机IO,因为每次修改的数据位置随机,但写redo log是追加操作,属于顺序IO。
(2)刷脏是以数据页(Page)为单位的,MySQL默认页大小是16KB,一个Page上一个小修改都要整页写入;而redo log中只包含真正需要写入的部分,无效IO大大减少。
-
binlog(归档日志)
-
relaylog(中继日志)
锁
-
全局锁
-
表级锁
-
行锁
MVCC
多版本并发控制,以乐观锁为理论基础。
通过对数据行的多个版本管理来实现数据库的并发控制。这样就可以通过比较版本号决定数据是否显示,读取数据时不需要加锁也可保证事务的隔离效果。
MVCC 的核心实现主要基于两部分:版本链和读视图。
MVCC 通过版本链实现多版本管理,通过 Read View 生成策略的不同实现,实现「读已提交」和「可重复读」这两种隔离级别。
- 「读已提交」每次查询都会重新生成一个 Read View,做到每次提交后的数据可被当前事务读到。
- 「可重复读」一直使用启动事务时生成的 Read View,直到当前事务提交,以此保证可重复读。
事务并发问题
-
脏读(Dirty Read):读取未提交数据。
事务 A 读取事务 B 尚未提交的数据,此时如果事务 B 发生错误并回滚,那么事务 A 读取到的数据就是脏数据。
-
不可重复读(Non-repeatable Read):前后多次读取,数据内容不一致。
事务 A 在事务 B 开始前读和事务 B 结束后读的数据不一样,因为数据被事务 B 修改了。
-
幻读(Phantom Read):同一个查询在不同时间产生不同的结果集
事务 A 在读取某个范围内的记录时,事务 B 在该范围内插入了新记录或删除了旧记录,事务 A 再次读取该范围内的记录时,前后获取的结果集不同,产生了幻读。
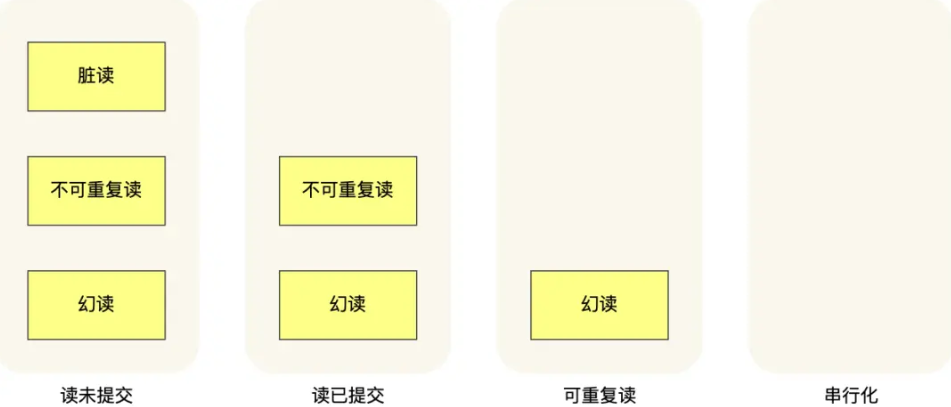
事务隔离级别
- 读未提交(Read Uncommitted)
- 读已提交(Read Committed)
- 可重复读(Repeatable Read)
- 串行化(Serializable)
索引
索引的概念
索引的类别
索引什么时候被需要
索引什么时候不被需要
索引什么时候失效
分库分表
- what
- why
- when
- how
- 分库分表前
- 切哪个:如何选择分标键,非分表键如何查询
- 切多少:如何选择分表策略
- 怎么切:垂直,水平分库分表
- 什么刀:如何选择中间件
- 数据倾斜:如何避免热点倾斜
- 数量评估:如何评估分库数量
- 分库分表后
- 如何解决胯节点join关联,聚合函数问题
- 如何处理事务
- 如何解决分页问题
- 分布式ID
- 分库分表前

 浙公网安备 33010602011771号
浙公网安备 33010602011771号