ZooKeeper简介
ZooKeeper 简介:核心概念、协议原理与实战应用
一、ZooKeeper 简介
ZooKeeper 是一个高性能的分布式协调服务,其本质是一个分布式、高可用的键值存储系统,尤其适用于以下场景:
- 配置管理
- 分布式锁
- 集群选举
- 命名服务
它基于 ZAB 协议(Zookeeper Atomic Broadcast)保证数据强一致性,内部使用类似文件系统的树形结构管理数据,每个节点称为 ZNode,支持事件监听机制(Watcher)。
二、核心术语详解
2.1 基本术语
| 术语 | 说明 |
|---|---|
| ZNode | 数据的基本单元,既可当目录也可当文件,支持持久、临时、顺序等类型 |
| Leader | 处理所有写请求,并同步数据到 Follower 和 Observer |
| Follower | 接收 Leader 同步数据,同时响应读请求 |
| Observer | 不参与选举,仅接收数据同步,提升读性能 |
| Watcher | 事件监听机制,实现分布式事件通知 |
2.2 分布式理论关联
| 理论 | 说明 |
|---|---|
| CAP 定理 | 一致性、可用性、分区容忍性不可兼得 |
| BASE 理论 | 基本可用、软状态、最终一致性,强调灵活可用性 |
| Quorum 机制 | 多数派投票原则,实现强一致性 |
2.3 常用缩略词
| 缩写 | 全称 |
|---|---|
| ZAB | Zookeeper Atomic Broadcast Protocol |
| FIFO | First In First Out |
| TCP | Transmission Control Protocol |
三、架构模型与数据模型
3.1 集群架构
ZooKeeper 采用主从结构:
Client
│
├───> Leader(写请求处理 + 事务同步)
│ │
│ ├──> Follower(参与选举 + 同步 + 读请求处理)
│ └──> Observer(只读节点)
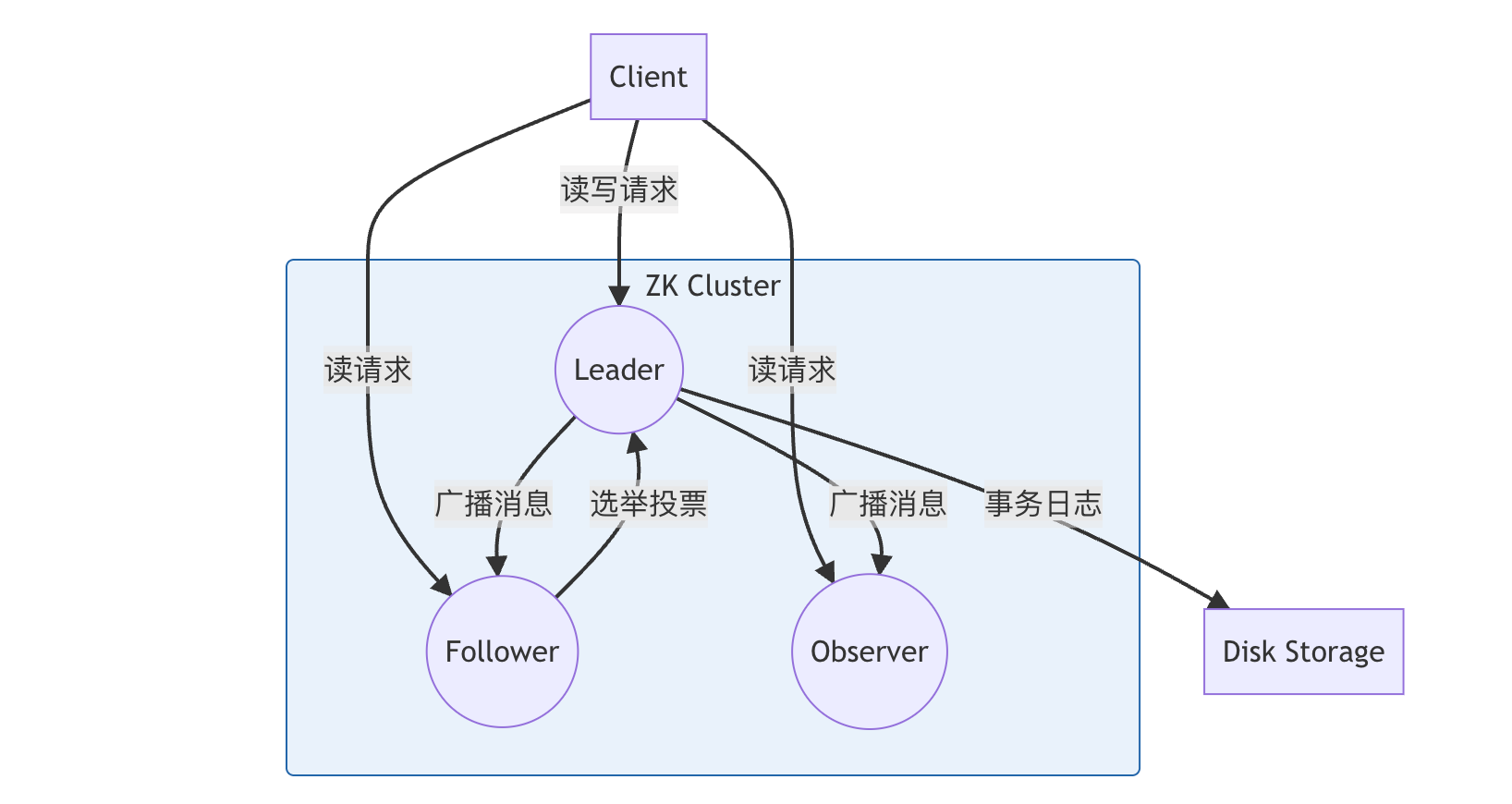
- 写请求必须通过 Leader 处理
- 读请求可由任意副本(Follower/Observer)响应
- 所有写操作通过 ZAB 协议 同步
3.2 数据模型(ZNode)
ZNode 结构如下:
-
数据内容:最多 1MB
-
版本信息:
cversion、dataVersion、aclVersion -
时间戳:
ctime(创建时间)、mtime(修改时间) -
ACL 权限:支持 IP、digest、world、super 模型
-
节点类型:
- PERSISTENT:持久节点
- EPHEMERAL:临时节点(随会话消失)
- SEQUENTIAL:顺序节点
- EPHEMERAL_SEQUENTIAL:临时顺序节点
3.3 Watcher 监听机制
工作流程:
- 客户端注册监听
- 服务端触发事件后通知客户端
- 客户端接收到通知后可决定是否重新注册监听
特性:
- 一次性触发:需手动重新注册
- 顺序保证:事件顺序符合 ZAB 协议
- 轻量通知:仅通知“发生了变化”,不附带变化内容
四、核心算法与一致性协议
4.1 ZAB 协议工作机制
ZAB 是 ZooKeeper 的原子广播协议,分为两个阶段:
阶段一:Leader 选举(崩溃恢复)
以 Fast Leader Election 为例介绍投票流程详细步骤:
初始状态
- 所有ZooKeeper服务器启动时都处于LOOKING状态,开始寻找或选举Leader。
投票规则
每个服务器按照以下规则投票:
首先投给自己,投票内容包含:
-
自己服务器的ID (myid)
-
自己最后处理的事务ZXID (最大事务ID)
-
当前的epoch值
收到其他服务器的投票后,比较:
-
优先比较ZXID,较大的优先
-
如果ZXID相同,则比较服务器ID,较大的优先
投票流程
发起投票:
-
每个服务器初始化时先投给自己
-
投票信息:(epoch, zxid, server_id)
接收投票:
-
每个服务器接收来自其他服务器的投票
-
将接收到的投票与自己的投票进行比较
更新投票:
-
如果接收到的投票比自己的投票"更优"(ZXID更大或ZXID相同但server_id更大)
-
则更新自己的投票为接收到的投票
统计投票:
-
服务器统计是否有超过半数的服务器(quorum)支持同一个投票
-
如果有,则确定Leader
确认Leader:
-
当选Leader的服务器切换到LEADING状态
-
其他服务器切换到FOLLOWING状态
选举完成条件
- 当某个服务器获得超过半数的相同投票时,选举结束
- 被选中的服务器成为Leader,其余成为Follower
阶段二:事务广播(数据同步)
客户端请求处理
-
写请求接收:
- 客户端向任意服务器发送写请求
- 如果是Follower接收,会将请求转发给Leader
-
事务提案(Proposal):
- Leader为每个写请求生成一个事务提案(Proposal)
- 提案包含:ZXID(事务ID)、请求内容、时间戳等
- 每个提案都有唯一的、单调递增的ZXID
提案广播阶段
-
发送提案:
- Leader将事务提案发送给所有Follower
- 使用FIFO通道保证发送顺序
-
Follower处理提案:
- Follower收到提案后,先写入本地事务日志(未提交)
- 然后向Leader发送ACK响应
-
等待法定人数确认:
- Leader等待直到收到超过半数Follower的ACK
- 这个阶段称为"法定人数确认"(Quorum Ack)
提交阶段(Commit)
-
提交通知:
- 当Leader收到足够ACK后,广播COMMIT消息
- COMMIT消息包含要提交的ZXID
-
事务提交:
- Follower收到COMMIT后,将事务应用到内存数据库
- 更新lastProcessedZxid
-
响应客户端:
- Leader在本地提交后响应客户端
- 注意:客户端可能在所有Follower提交前就收到响应
4.2 持久化机制
事务日志格式
[4B 魔法值][4B 长度][事务内容(含 ZXID、操作类型、数据)]
快照触发策略
- 日志文件超过阈值(如 64MB)
- ZXID 累计超过指定数值(如 100,000)
数据恢复步骤
- 加载最新快照
- 按顺序重放事务日志
- 清除旧日志(默认保留最近3个快照对应日志)
五、典型应用场景
5.1 分布式配置中心
统一管理分布式系统配置,如 Hadoop、Spark、Flume 等
- 在
/configs/xxx路径存放配置信息 - 客户端注册
NodeDataChangedWatcher - 配置更新后,所有客户端感知变化并动态加载新配置
5.2 集群成员管理(如 Kafka Broker)
动态感知集群成员上线下线
- 各节点启动时在
/brokers/ids/[id]下创建临时节点 - 消费方监听子节点变化实现自动负载均衡
- 节点掉线后临时节点自动删除
5.3 分布式锁服务
保证资源的互斥访问(如 HBase RegionServer)
- 使用临时顺序节点
- 排序后第一个节点获得锁
- 客户端监听前一个节点删除事件
优点:
- 锁释放自动(客户端断开连接)
- 公平性保证
- 跨语言支持(Java、Go、Python 等)
5.4 命名服务
为分布式组件生成全局唯一 ID(如订单 ID、任务 ID)
- 使用 SEQUENTIAL 节点生成唯一编号
- 结合临时节点也可用于唯一身份标识(服务注册)
六、总结
ZooKeeper 提供了一套稳定、可靠的分布式协调机制,帮助开发者优雅解决:
- 分布式一致性问题
- 配置统一与动态感知
- 服务发现与注册
- 分布式同步与锁控制

 浙公网安备 33010602011771号
浙公网安备 33010602011771号