[Ynoi2019模拟赛]Yuno loves sqrt technology I
题目大意:
给定一个长为\(n\)的排列,\(m\)次询问,每次查询一个区间的逆序对数。
强制在线。
解题思路:
众所周知lxl是个毒瘤,Ynoi道道都是神仙题
首先我们知道,归并排序可以求逆序对。
归并排序是怎么求逆序对的呢?
先递归左半边\([l,mid]\),再递归右半边\([mid+1,r]\),计算两边的贡献,然后加上满足\(i\in[l,mid]\),\(j\in[mid+1,r]\),且\(a_i>a_j\)的数对\(i,j\)的个数。
因此,一个区间的逆序对问题,可以分成多个区间的逆序对问题,然后计算任意两个不同区间产生的贡献。
分块,对每个块进行排序。
我们需要预处理的信息有:
1. 每个元素到其所在块块首这段区间的逆序对个数\(pre_x\)。
2. 每个元素到其所在块块尾这段区间的逆序对个数\(suf_x\)。
3. 块\(i\)到\(j\)这一整段区间的逆序对个数\(F[i][j]\)。
4. \(cnt[i][j]\),表示前\(i\)个块中,小于等于(或大于等于)\(j\)的元素个数。
计算\(pre,suf\),用树状数组在每块内扫一遍即可,计算一块的时间复杂度为\(O(S\log S)\),总时间复杂度\(O(n\log S)\)(\(S\)为块大小)。
计算\(F\)的话,有\(F[i][j]=F[i][j-1]+F[i+1][j]-F[i+1][j-1]+(i所在块和j所在块产生的贡献)\),即两边加起来减去重复,然后计算两边多出来的贡献。时间复杂度\(O(\dfrac{n^2}S)\)。
计算\(cnt\),先前缀和,然后对每个块内再前缀和即可。时间复杂度\(O(\dfrac{n^2}{S})\)。
设\(i\)所在块的块首为\(b_i\),块尾为\(e_i\)。
然后,对于一段区间询问\([L,R]\):
1. 若\(L\)和\(R\)在同一块内,则拆分成\([b_L,R]\)和\([b_L,L-1]\)这两个区间的差,内部贡献就是求出的\(pre\)的值,两块的贡献用归并求。
2. 若\(L\)和\(R\)不在同一块内,则拆分成\([L,e_L],[e_L+1,b_R-1],[b_R,R]\)的和,三个区间内部贡献都已经预处理\(pre,x,suf\),然后,边角与中间块的贡献,可以枚举每个边角元素,然后利用预处理出的\(cnt\)的值计算贡献。两个边角的贡献,则归并求即可。
用归并求逆序对,需要得到两个边角的有序数列,然后可以线性得到贡献。由于对每块都排好序,则只需要\(O(S)\)扫描边角块内元素,把在区间内的按顺序加入即可。
时间复杂度\(O(\dfrac{n^2}S+mS)\)。
然后这样似乎常数很大啊,被卡常的说〒▽〒
多次试验得出结果,我的\(S\)取160左右跑的比较快(然而根据复杂度看应该取\(\sqrt n\)),估计是询问常数大。
然后~~愉快地~~加了IO优化,编译指令,硬卡过去了(不保证代码每次提交都能过)。
哦对了,本题要开long long。
C++ Code:
// luogu-judger-enable-o2
#pragma GCC optimize("Ofast")
#pragma GCC optimize("unroll-loops")
#pragma GCC target("sse,sse2,sse3,ssse3,sse4,popcnt,abm,mmx,avx,tune=native")
#include<cstdio>
#include<cctype>
#include<algorithm>
#include<cstring>
#include<ctime>
#define N 100001
#define siz 160
class istream{
char buf[13000003],*s;
public:
inline istream(){
#ifndef ONLINE_JUDGE
freopen("input.txt","r",stdin);
#endif
buf[fread(s=buf,1,13000001,stdin)]='\n';
}
template<typename T>
inline void operator>>(T&rhs){
for(rhs=0;!isdigit(*s);++s);
while(isdigit(*s))rhs=rhs*10+(*s++&15);
}
}in;
struct BiT{
int b[N];
inline void add(int i,int x){for(;i<N;i+=i&-i)b[i]+=x;}
inline int ask(int i){int ret=0;for(;i;i^=i&-i)ret+=b[i];return ret;}
}t;
int n,m,a[N],L[666],R[666],bel[N],blocks,pre[N],suf[N],cnt[666][N];
long long F[666][666],ans;
int x[666],y[666],lx,ly;
int c[N],d[N];
struct Pair{
int first,second;
inline bool operator<(const Pair&rhs)const{return first<rhs.first;}
}b[N];
inline int merge(int*a,int*b,int la,int lb){
int ia=1,ib=1,ret=0;
while(ia<=la&&ib<=lb)
if(a[ia]<b[ib])++ia;else ret+=la-ia+1,++ib;
return ret;
}
void init(){
blocks=(n-1)/siz+1;
for(int i=1;i<=blocks;++i)L[i]=R[i-1]+1,R[i]=i*siz;
R[blocks]=n;
for(int i=1;i<=n;++i)b[i]=(Pair){a[i],i};
for(int i=1;i<=blocks;++i){
memcpy(cnt[i],cnt[i-1],sizeof*cnt);
std::sort(b+L[i],b+R[i]+1);
for(int j=L[i];j<=R[i];++j)bel[j]=i,++cnt[i][a[j]],c[j]=b[j].first;
int x=0;
for(int j=L[i];j<=R[i];++j){
t.add(a[j],1);
x+=t.ask(n)-t.ask(a[j]);
pre[j]=x;
}
F[i][i]=x;
for(int j=L[i];j<=R[i];++j){
suf[j]=x;
t.add(a[j],-1);
x-=t.ask(a[j]-1);
}
}
for(int len=1;len<=blocks;++len){
for(int j=n-1;j;--j)cnt[len][j]+=cnt[len][j+1];
for(int i=1;i<=blocks;++i)
if(len+i>blocks)break;else{
const int j=i+len;
F[i][j]=F[i+1][j]+F[i][j-1]-F[i+1][j-1]+merge(c+L[i]-1,c+L[j]-1,R[i]-L[i]+1,R[j]-L[j]+1);
}
}
}
struct ostream{
char buf[8000005],*s;
inline ostream(){s=buf;}
inline void operator<<(long long d){
if(!d){
*s++='0';
}else{
static long long w;
for(w=1;w<=d;w*=10);
for(;w/=10;d%=w)*s++=d/w^'0';
}
*s++='\n';
}
inline ostream&operator<<(const char&c){*s++=c;return*this;}
inline~ostream(){fwrite(buf,1,s-buf,stdout);}
}cout;
int main(){
in>>n;in>>m;
for(int i=1;i<=n;++i)in>>a[i];
init();
while(m--){
long long ll,rr;in>>ll;in>>rr;
const int l=ll^ans,r=rr^ans,bL=bel[l],bR=bel[r];
// const int l=ll,r=rr,bL=bel[l],bR=bel[r];
lx=ly=0;
if(bL==bR){
for(int i=L[bL];i<=R[bL];++i)
if(l<=b[i].second&&b[i].second<=r)y[++ly]=c[i];else
if(b[i].second<l)x[++lx]=c[i];
ans=pre[r]-((l==L[bL])?(0):(pre[l-1]))-merge(x,y,lx,ly);
}else{
ans=F[bL+1][bR-1]+pre[r]+suf[l];
const int*cR=cnt[bR-1],*cL=cnt[bL];
for(int i=L[bL];i<=R[bL];++i)
if(b[i].second>=l)ans+=cR[1]-cR[x[++lx]=c[i]]-cL[1]+cL[c[i]];
for(int i=L[bR];i<=R[bR];++i)
if(b[i].second<=r)ans+=cR[(y[++ly]=c[i])+1]-cL[c[i]+1];
ans+=merge(x,y,lx,ly);
}
cout<<ans;
}
return 0;
}
说到底,块大小取$\dfrac{\sqrt n}2$才能过的原因还是常数问题。
在本机上随机数据开O2测,块大小取$\sqrt n$时,预处理要跑$0.22\rm s$,而整个程序运行完要$1.2\rm s$,常数差了$4\sim 5$倍!
所以块开小一半平衡了常数能卡过好像也有道理
以下是shadowice1984神仙的优秀做法,稳定的$O(n\sqrt n)$:
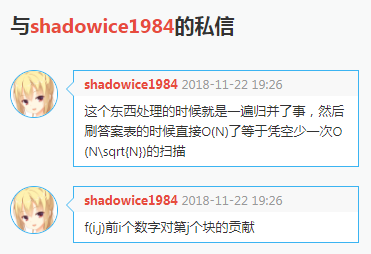
讲清楚点,就是:
$f[i][j]$表示$a_1\sim a_i$能与第$j$块中的数字产生多少逆序对。
计算的方法的话,就是对于每个块,都和所有数进行一遍归并,记录下每个数对块的贡献。
然后再做一遍前缀和即可。$O(n\sqrt n)$。
注意上述预处理要考虑$a_i$在第$j$个块的前面还是后面。
之后的话,原来的$cnt$数组就可以扔掉了,对于边角对整块的贡献,就可以枚举每个块,然后用贡献的前缀和进行计算。单次$O(\sqrt n)$,比原来用$cnt$数组少了1倍常数。
而且,计算$F$的时候可以省掉一个$O(\sqrt n)$的归并。
然后常数就非常优秀了。
现在不加任何编译指令,块大小为$\sqrt n$也能保证每次提交基本都过了(虽然总用时比原来多QAQ)。
C++ Code:
#include<cstdio>
#include<cctype>
#include<algorithm>
#include<cstring>
#define N 100002
#define siz 317
class istream{
char buf[15000003],*s;
public:
inline istream(){
#ifndef ONLINE_JUDGE
freopen("input.txt","r",stdin);
#endif
buf[fread(s=buf,1,15000001,stdin)]='\n';
}
template<typename T>
inline void operator>>(T&rhs){
for(rhs=0;!isdigit(*s);++s);
while(isdigit(*s))rhs=rhs*10+(*s++&15);
}
}in;
struct BiT{
int b[N];
inline void add(int i,int x){for(;i<N;i+=i&-i)b[i]+=x;}
inline int ask(int i){int ret=0;for(;i;i^=i&-i)ret+=b[i];return ret;}
}t;
int n,m,a[N],L[320],R[320],bel[N],blocks,pre[N],suf[N],f[320][N];
long long F[320][320],ans;
int x[320],y[320],lx,ly;
int c[N],d[N];
struct Pair{
int first,second;
inline bool operator<(const Pair&rhs)const{return first<rhs.first;}
}b[N];
inline int merge(int*a,int*b,int la,int lb){
int ia=1,ib=1,ret=0;
while(ia<=la&&ib<=lb)
if(a[ia]<b[ib])++ia;else ret+=la-ia+1,++ib;
return ret;
}
void init(){
blocks=(n-1)/siz+1;
for(int i=1;i<=blocks;++i)L[i]=R[i-1]+1,R[i]=i*siz;
R[blocks]=n;
for(int i=1;i<=n;++i)b[i]=(Pair){a[i],i};
for(int i=1;i<=blocks;++i){
std::sort(b+L[i],b+R[i]+1);
for(int j=L[i];j<=R[i];++j)bel[j]=i,c[j]=b[j].first,d[j]=b[j].second;
int x=0;
for(int j=L[i];j<=R[i];++j){
t.add(a[j],1);
x+=t.ask(n)-t.ask(a[j]);
pre[j]=x;
}
F[i][i]=x;
for(int j=L[i];j<=R[i];++j){
suf[j]=x;
t.add(a[j],-1);
x-=t.ask(a[j]-1);
}
}
std::sort(b+1,b+n+1);
for(int j=1;j<=blocks;++j){
for(int i=1,k=L[j];i<=n;++i){
const int id=b[i].second;
while(k<=R[j]&&b[i].first>c[k])++k;
if(id<L[j])
f[j][id]=k-L[j];else
if(id>R[j])
f[j][id]=R[j]-k-(k<=R[j]&&b[i].first==c[k])+1;
}
}
for(int i=1;i<=blocks;++i)
for(int j=2;j<=n;++j)f[i][j]+=f[i][j-1];
for(int len=1;len<=blocks;++len){
for(int i=1;i<=blocks;++i)
if(len+i>blocks)break;else{
const int j=i+len;
F[i][j]=F[i+1][j]+F[i][j-1]-F[i+1][j-1]+f[j][R[i]]-f[j][L[i]-1];
}
}
}
struct ostream{
char buf[9000005],*s;
inline ostream(){s=buf;}
inline void operator<<(long long d){
if(!d){
*s++='0';
}else{
static long long w;
for(w=1;w<=d;w*=10);
for(;w/=10;d%=w)*s++=d/w^'0';
}
*s++='\n';
}
inline ostream&operator<<(const char&c){*s++=c;return*this;}
inline~ostream(){fwrite(buf,1,s-buf,stdout);}
}cout;
int main(){
in>>n;in>>m;
for(int i=1;i<=n;++i)in>>a[i];
init();
while(m--){
long long ll,rr;in>>ll;in>>rr;
const int l=ll^ans,r=rr^ans,bL=bel[l],bR=bel[r];
lx=ly=0;
if(bL==bR){
for(int i=L[bL];i<=R[bL];++i)
if(l<=d[i]&&d[i]<=r)y[++ly]=c[i];else
if(d[i]<l)x[++lx]=c[i];
ans=pre[r]-((l==L[bL])?(0):(pre[l-1]))-merge(x,y,lx,ly);
}else{
ans=F[bL+1][bR-1]+pre[r]+suf[l];
for(int i=bL+1;i<bR;++i)
ans+=(f[i][R[bL]]-f[i][l-1])+(f[i][r]-f[i][L[bR]-1]);
for(int i=L[bL];i<=R[bL];++i)
if(d[i]>=l)x[++lx]=c[i];
for(int i=L[bR];i<=R[bR];++i)
if(d[i]<=r)y[++ly]=c[i];
ans+=merge(x,y,lx,ly);
}
cout<<ans;
}
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号