4-hadoop的运行模式(本地)
Hadoop的运行模式
Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
Hadoop官方网站:http://hadoop.apache.org/
2.7.2版本官网:http://hadoop.apache.org/docs/r2.7.2/
文档:http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/SingleCluster.html
Grep案例
在hadoop文件夹下新建input文件夹
进行拷贝配置文件
命令:在hadoop文件目录下
cp etc/hadoop/*.xml input/
执行测试命令
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input/ output/ 'dfs[a-z.]+'
解释:
首先使用hadoop命令 找到jar (指定jar的地址) grep为测试的案例
其次是指定输入路径 input/ 均是一些配置文件 output/ 为输出路径(注意:这个文件夹不需要创建)
最后使用一个正则表达式进行字符的验证
注意:output文件不能创建否则会进行报错:该文件夹已经存在
执行程序可以发现(部分):
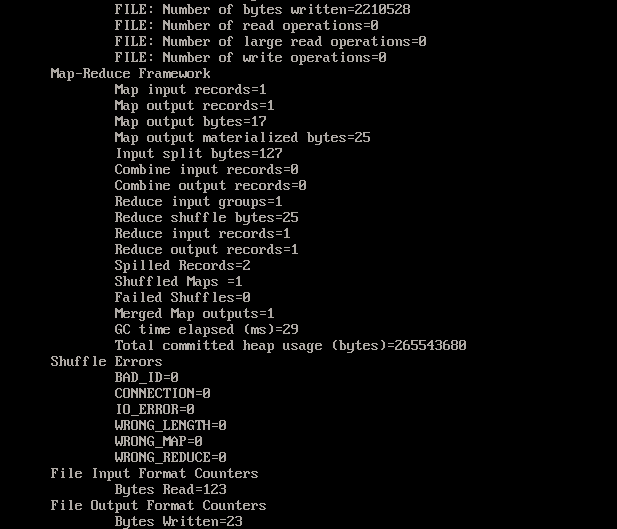
此时进入output目录下:

_SUCCESS:表示执行成功
part-r-0000:表示执行之后生成的数据文件
此时查询part-r-0000查询匹配的相关正则表达式的内容

wordcount案例
在hadoop目录下创建wcinput文件夹
统计关键词出现的次数
进行新创建的文件夹目录下出啊昂见wc.input文件夹
文件地内容:
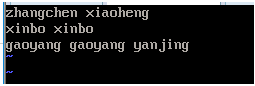
命令:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput/ wcoutput/
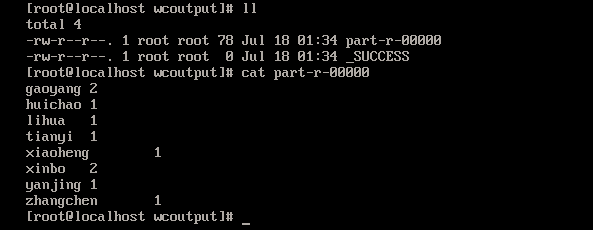
进入wcoutput进行查看

 浙公网安备 33010602011771号
浙公网安备 33010602011771号