Pandas --DataFrame基本操作
一.介绍
DataFrame是pandas中另一个核心数据结构,它是一个二维的、大小可变的、可以存储多种类型数据的表格结构。每一列可以是不同的类型(数值、字符串、布尔值等),并且有行索引和列索引。类似于Excel表格或SQL数据库中的表。它由行和列组成,每一列都是一个Series对象。DataFrame是pandas中最常用的数据结构。
DataFrame的核心作用:
数据存储:可以存储多种类型的数据,并且可以方便地处理缺失数据。
数据操作:提供了大量的方法来进行数据清洗、转换、筛选、聚合等操作。
数据对齐:基于行和列的标签进行数据对齐。
数据集成:可以轻松地从多种数据源(如CSV、Excel、SQL数据库等)加载数据,并导出为多种格式。
时间序列处理:支持时间序列数据,提供了日期范围生成、频率转换、移动窗口计算等功能。
DataFrame的使用场景:
数据清洗和预处理:处理缺失值、重复值、数据类型转换等。
数据分析和探索:通过分组、聚合、透视表等操作探索数据。
数据可视化:可以配合Matplotlib、Seaborn等库进行数据可视化。
机器学习数据准备:准备特征矩阵和目标变量。
时间序列分析:处理带有时间戳的数据,进行重采样、滑动窗口等操作。
数据库风格的操作:进行类似SQL的查询、连接、合并等操作。
二.创建 DataFrame对象和属性查看
2.1 创建 DataFrame
除了以下方式创建DataFrame,还可以文件读取创建----使用pd.read_csv('filename.csv') 或 df = pd.read_excel('filename.xlsx')
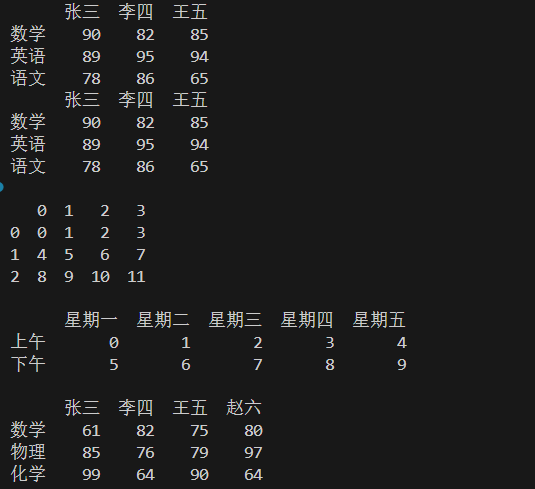
import numpy as np import pandas as pd """ 创建DataFrame的二维数组(行与列)。 包括: 利用python字典 利用Series 利用ndarray数组 """ #利用python字典创建DataFrame data={ "张三":{"数学":90,"英语":89,"语文":78}, "李四":{"数学":82,"英语":95,"语文":86}, "王五":{"数学":85,"英语":94,"语文":65} } df=pd.DataFrame(data) print(df) #利用Series(基于字典)创建DataFrame s1=pd.Series({"数学":90,"英语":89,"语文":78}) s2=pd.Series({"数学":82,"英语":95,"语文":86}) s3=pd.Series({"数学":85,"英语":94,"语文":65}) df=pd.DataFrame({"张三":s1,"李四":s2,"王五":s3}) print(df) #通过numpy二维数组创建DataFrame #arange(12)是0~11的数,把它改组成3行四列的二维数组 df=pd.DataFrame(np.arange(12).reshape(3,4)) print(df) #上面的创建没有指定行与列的名称,这里创建时指定行与列 ind=['上午',"下午"] col=["星期一","星期二","星期三","星期四","星期五"] df=pd.DataFrame(np.arange(10).reshape(2,5),columns=col,index=ind) print(df) #成绩随机生成60~100,生成三行四列 ind=["数学","物理","化学"] col=["张三","李四","王五","赵六"] df=pd.DataFrame(np.random.randint(60,100,(3,4)),columns=col,index=ind) print(df)
2.2 DataFrame属性
DataFrame和Series的属于类似,都有index, columns、values、dtypes等
s1=pd.Series({"数学":90,"英语":89,"语文":78})
s2=pd.Series({"数学":82,"英语":95,"语文":86})
s3=pd.Series({"数学":85,"英语":94,"语文":65})
df=pd.DataFrame({"张三":s1,"李四":s2,"王五":s3})
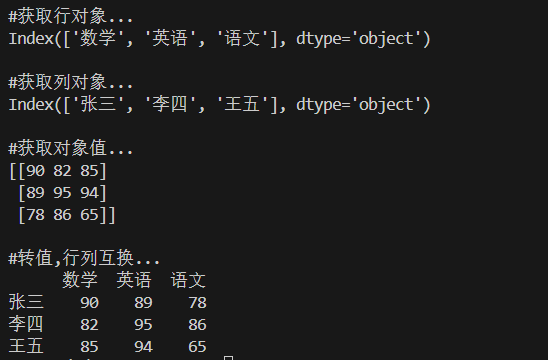
print("\n#获取行对象...")
print(df.index)
print("\n#获取列对象...")
print(df.columns)
print("\n#获取对象值...")
print(df.values)
print("\n#转值,行列互换...")
print(df.T)
三. DataFrame 基本操作
包括:提取和修改数据,添加数据,删除数据,删除DataFrame本身
3.1 DataFrame列的提取
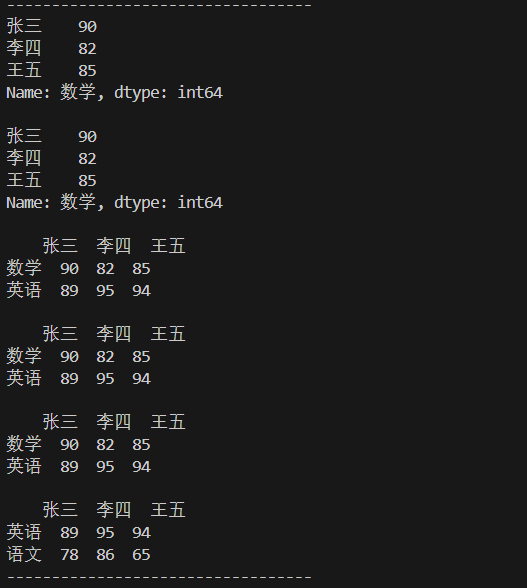
#利用Series(基于字典)创建DataFrame s1=pd.Series({"数学":90,"英语":89,"语文":78}) s2=pd.Series({"数学":82,"英语":95,"语文":86}) s3=pd.Series({"数学":85,"英语":94,"语文":65}) df=pd.DataFrame({"张三":s1,"李四":s2,"王五":s3}) #输出列的数据,可以理解【张三】是列名 print(df["张三"]) #上面输出等价于隐藏索引dt.iloc[:,0]和显示索引df.loc[:,"张三"] #输出列的数据,可以理解为下标索引为0的对应列,也就是【张三】列 #df.iloc[:,0]中[:]冒号表示获取所有行 print(df.iloc[:,0]) #输出列的数据,可以理解获取带有【张三】列标签对应的行数据,也就是【张三】列 print(df.loc[:,"张三"]) #同时提取二列数据,对应用一个list print(df.loc[:,["张三","李四"]])

3.2 DataFrame列的修改
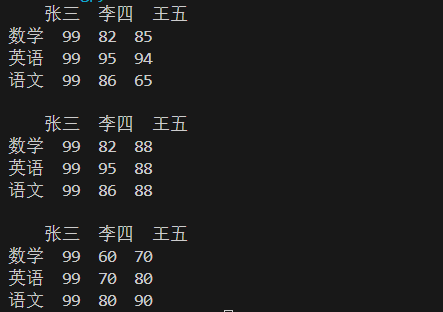
#修改列数据, 指定张三列,更改对应数据 df.loc[:,"张三"]=[99,99,99] print(df) #修改列数据,索引下标2,是修改【王五】列的数据 df.iloc[:,2]=[88,88,88] print(df) #修改列数据,修改索引下标为1,2的二列数据,对应【李四】=60,70,80 和【王五】列=70,80,90 df.iloc[:,1:3]=[[60,70],[70,80],[80,90]] print(df)
3.3 DataFrame行的提取
#提取数学这一行的数据 print("----------------------------------") print(df.loc["数学"]) print("") #提取行下标为0的,也就是数学这一行的数据,同等于df.loc["数学"] print(df.iloc[0]) print("") #提取数学和英语这二行的数据 print(df.loc[["数学","英语"]]) print("") #提取行下标为0和1的,也就是数学和英文这二行的数据,同等于df.loc[["数学","英语"]] print(df.iloc[:2]) print("") #提取前二行的数据 print(df.head(2)) print("") #提取最后二行的数据 print(df.tail(2)) print("----------------------------------")
3.4 DataFrame行的修改
#修改语文这行的数据,全部为100 df.loc["语文"]=[100,100,100] print(df) print("") #修改行下标为2也就是语文这行的数据,全部为99 df.iloc[2]=[99,99,99] print(df) print("") #修改数学和语文这二行的数据 df.loc[["数学","语文"]]=[[100,100,100],[60,60,60]] print(df) print("") #修改数学和英语这二行的数据 df.iloc[:2]=[[50,50,50],[40,40,40]] print(df) print("")
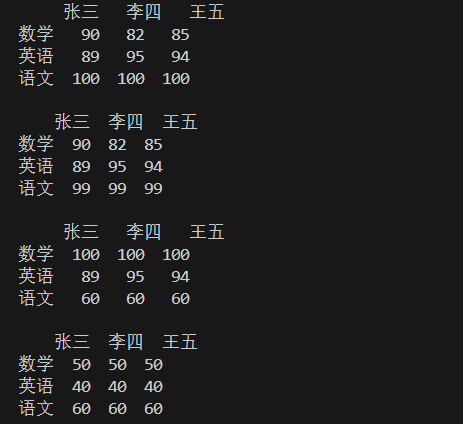
3.5 增加行数据和列数据
s1=pd.Series({"数学":90,"英语":89,"语文":78})
s2=pd.Series({"数学":82,"英语":95,"语文":86})
s3=pd.Series({"数学":85,"英语":94,"语文":65})
df=pd.DataFrame({"张三":s1,"李四":s2,"王五":s3})
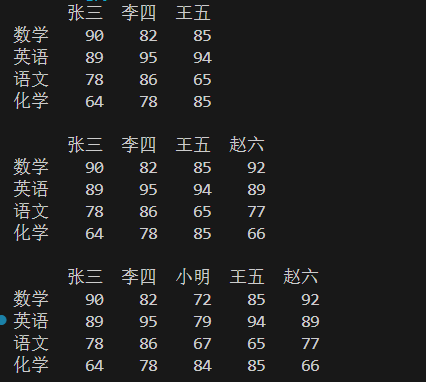
#增加一行数据, 相当于df.loc["化学",:]=np.random.randint(60,100,3)所有的列
df.loc["化学"]=np.random.randint(60,100,3)
print(df)
print("")
#增加一列数据,添加赵六的成绩,
df["赵六"]=np.random.randint(60,100,4)
print(df)
print("")
#使用insert()增加列数据,在第3列显示插入的列数据
df.insert(2,"小明",np.random.randint(60,100,4))
print(df)
print("")
3.6 删除行和列的数据
#利用Series(基于字典)创建DataFrame s1=pd.Series({"数学":90,"英语":89,"语文":78}) s2=pd.Series({"数学":82,"英语":95,"语文":86}) s3=pd.Series({"数学":85,"英语":94,"语文":65}) df=pd.DataFrame({"张三":s1,"李四":s2,"王五":s3}) #使用del删除列数据,只保留了李四和王五 del df["张三"] print(df) print("") #axis=1删除列中的数据,axis=0删除行中的数据,下面是删除语文这行的数据 df.drop(labels="语文",axis=0,inplace=True) print(df) print("") #删除df本身 del df

 浙公网安备 33010602011771号
浙公网安备 33010602011771号