微信小程序开发
原文: https://www.cnblogs.com/MrFlySand/p/19122125
微信小程序开发文档:https://developers.weixin.qq.com/miniprogram/dev/framework/
https://developers.weixin.qq.com/miniprogram/dev/framework/ability/pre-fetch.html
01 常用功能
1.1 常用快捷键
【必会!VSCode 最实用的快捷键】 https://www.bilibili.com/video/BV19jS2YHEZM/?share_source=copy_web&vd_source=e382d5e4e6b9fca0eddfd09f9d93b3b8
先将光标定位到函数开头的左括号 {或} 处,再按下Ctrl + Shift + \
ctrl+shift+[折叠代码,ctrl+shift+]展开代码
打开工程:code + 路径
打开指定文件:ctrl + p0
打开/关闭终端:ctrl + ~ (1左边的按键)
跳转到行:ctrl + g
按单词移动光标:ctrl + 左右
选中单词:ctrl + d (重复按可以多选)
选中行:ctrl + l (重复按会同时选择下一行)
移动行:alt + 上下
格式化代码:ctrl + shift + i
跳转到定义:f12
查看当前文件符号:ctrl + shift + o
剪切/复制当前行:ctrl + x / ctrl + c (什么都不选的时候)
切换tab:alt+数字
顺序切换tab:ctrl + pageup / pagedown
关闭文件:ctrl+w
关闭所有文件:ctrl + k w (ctrl不松手)
ctrl+b 打开主侧边栏
ctrl+shift+e 打开文件管理器
ctrl+0 焦点聚焦到主侧边栏
ctrl+1 焦点聚焦到代码编辑器
alt + 1234 切换到第1234页
ctrl+~ 聚焦到终端
ctrl+shift+space 重新出现函数信息提示
ctrl+\ 添加分屏
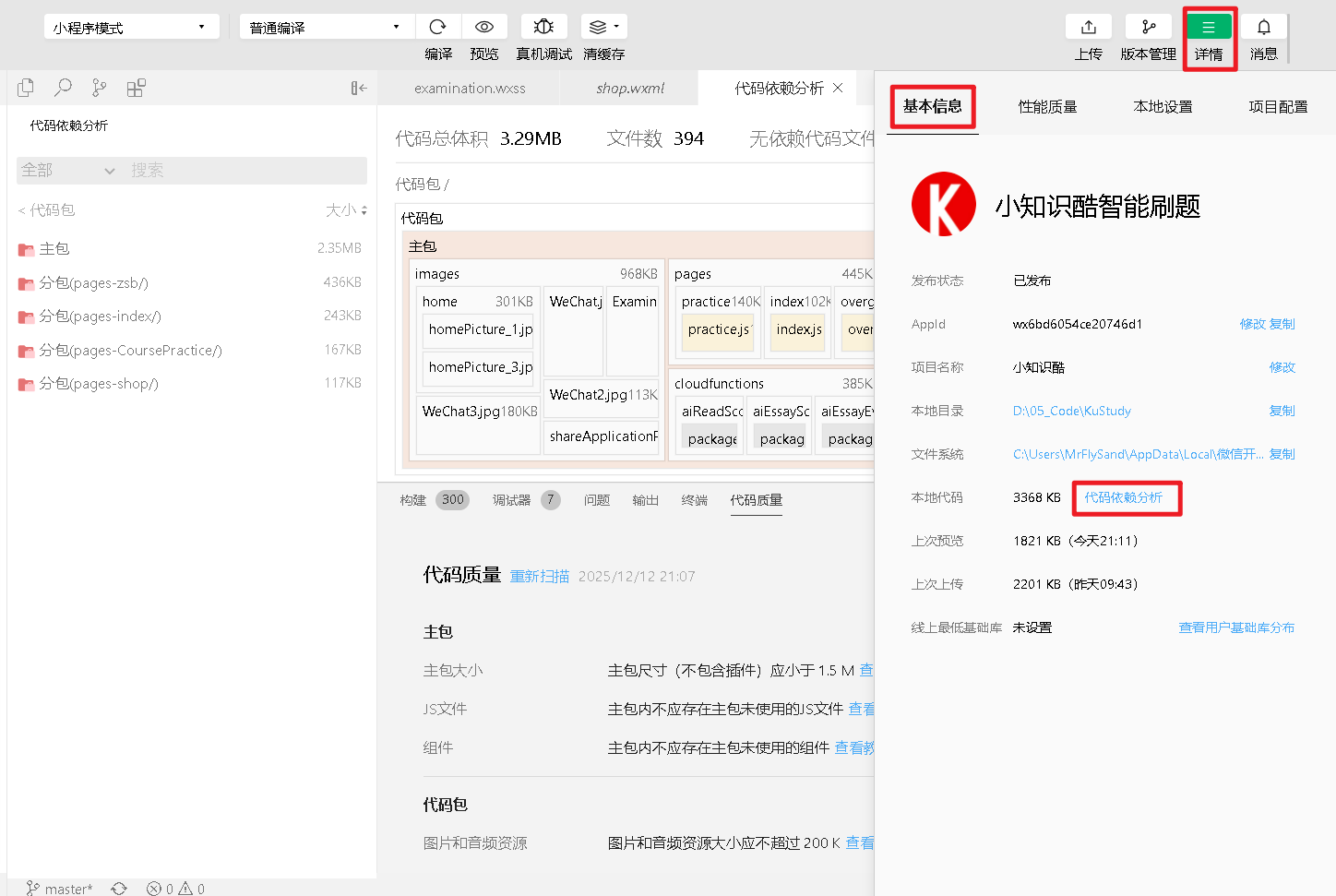
1.2 代码包分析
右上角【详情】-【基本信息】-【代码依赖分析】
1.3 通用命令行列出js中的函数名和函数功能介绍
使用方法:node listFunctions.js 复制相对路径/文件名.js

#!/usr/bin/env node
// 使用方法:node listFunctions.js 复制相对路径/文件名.js
const fs = require('fs');
const path = require('path');
// 函数解析器
function parseJSFunctions(fileContent) {
const functions = [];
const functionPatterns = [
// function声明:function name() { ... }
/function\s+([\w$]+)\s*\(/g,
// 箭头函数:const name = () => { ... }
/(?:const|let|var)\s+([\w$]+)\s*=\s*\(?[\w\s,]*\)?\s*=>/g,
// 对象方法:name: function() { ... }
/([\w$]+)\s*:\s*function\b/g,
// 简写对象方法:name() { ... }
/([\w$]+)\s*\(\s*\)\s*\{/g
];
// JSDoc注释匹配
const jsdocPattern = /\/\*\*([\s\S]*?)\*\//g;
const jsdocInfo = [];
let jsdocMatch;
while ((jsdocMatch = jsdocPattern.exec(fileContent)) !== null) {
const start = jsdocMatch.index;
const end = start + jsdocMatch[0].length;
const comment = jsdocMatch[1].trim();
// 提取功能介绍
let description = '';
const lines = comment.split('\n');
for (let line of lines) {
line = line.trim().replace(/^\*/, '').trim();
if (line.startsWith('@description')) {
description = line.slice('@description'.length).trim();
break;
} else if (line && !line.startsWith('@')) {
description = line.trim();
break;
}
}
jsdocInfo.push({
start: start,
end: end,
description: description
});
}
// 解析函数定义
for (const pattern of functionPatterns) {
let match;
while ((match = pattern.exec(fileContent)) !== null) {
const functionName = match[1];
if (functionName && functionName !== 'function' && !functions.find(f => f.name === functionName)) {
// 查找最近的JSDoc注释
let description = '无功能介绍';
const functionStart = match.index;
for (const jsdoc of jsdocInfo) {
if (jsdoc.end < functionStart) {
const distance = functionStart - jsdoc.end;
if (distance < 100 && distance > 0) {
description = jsdoc.description;
}
}
}
functions.push({
name: functionName,
description: description
});
}
}
}
// 按出现顺序排序
functions.sort((a, b) => fileContent.indexOf(a.name) - fileContent.indexOf(b.name));
return functions;
}
// 主函数
function main() {
const fileName = process.argv[2];
if (!fileName) {
console.log('请指定要解析的JS文件路径');
return;
}
const filePath = path.resolve(fileName);
if (!fs.existsSync(filePath)) {
console.log(`文件 ${filePath} 不存在`);
return;
}
if (path.extname(filePath) !== '.js') {
console.log('请指定JavaScript文件');
return;
}
try {
const content = fs.readFileSync(filePath, 'utf8');
const functions = parseJSFunctions(content);
console.log('\n当前JS文件的函数列表:');
console.log('=' . repeat(120));
functions.forEach((func, index) => {
console.log(`${index + 1}. ${func.name}, ${func.description}`);
});
console.log('=' . repeat(120));
console.log(`共找到 ${functions.length} 个函数`);
} catch (error) {
console.log(`解析文件时出错:${error}`);
}
}
// 执行主函数
main();
1.4 同步、异步、并发、并行
这四个是计算机/编程中描述任务执行方式的核心概念,用生活例子简单讲:
1. 同步(Synchronous)
核心:按顺序做,等上一个做完再做下一个
比如做饭:先等水烧开,再下面条,全程盯着等步骤完成,不能同时干别的。
2. 异步(Asynchronous)
核心:不用等上一个做完,先做别的,等结果出来再回来处理
比如做饭:煮着水的同时,先去切菜;水开了会有“沸腾”的提示,再回来下面条,不用干等。
3. 并发(Concurrency)
核心:“看起来同时”处理多个任务,实际是快速切换着做
比如一个人同时“回消息+吃饭”:吃一口、回一条消息,快速交替,看起来像同时在做,但实际是串行切换。
4. 并行(Parallelism)
核心:真的“同时”做多个任务,需要多个执行单元(比如多核CPU)
比如两个人同时干活:一个人回消息,另一个人吃饭,各自独立做,是真正的“同时进行”。
关键差异
- 同步/异步:看“是否需要等待任务完成”;
- 并发/并行:看“是快速切换(并发),还是真的同时做(并行)”。
02 版本控制

这些按钮都和 Git 版本控制 相关,作用如下:
- 推送:将本地仓库已提交的代码变更,上传到远程仓库(如 GitHub、GitLab 等),让团队成员同步你的修改。
- 抓取:从远程仓库获取最新的代码变更信息,但不会自动合并到本地当前分支(仅拉取“变更记录”,不影响本地代码)。
- 拉取:从远程仓库获取最新代码,并自动合并到本地当前分支(相当于「抓取 + 合并」的组合操作),用于同步远程最新代码到本地。
- 贮藏:临时保存工作区(未提交的)修改,方便切换分支、处理其他任务(之后可通过“应用贮藏”恢复这些修改)。
- 应用贮藏:将之前用“贮藏”保存的修改,恢复到工作区。
- 分支:管理分支的操作(如创建、切换、删除分支等)。分支可让你在不影响主代码的前提下,开发新功能或修复 Bug。
- 合并:将一个分支的代码变更,合并到当前所在分支(比如开发完新功能的
feature分支,合并到master分支)。
官方教程:https://developers.weixin.qq.com/miniprogram/dev/devtools/wechatvcs.html
如下图,红色为以前的代码,绿色为当前代码
设置存储的仓库
1.1 ssh密钥认证
要在“微信开发者·代码管理”中添加 SSH 密钥,需分生成密钥、复制公钥、粘贴添加三步:
步骤 1:生成 SSH 密钥对(电脑终端操作)
代码上传到git失败?

- 打开 Git Bash(安装 Git 后自带的终端工具,Windows、Mac、Linux 都可用)。
- 输入命令生成密钥(把
"你的邮箱@example.com"换成自己的邮箱,一路回车用默认设置):
执行后,密钥会保存在系统默认路径(如 Windows 是ssh-keygen -t rsa -C "你的邮箱@example.com"C:\Users\你的用户名\.ssh,Mac/Linux 是~/.ssh),生成两个文件:id_rsa(私钥,自己留着,别泄露)和id_rsa.pub(公钥,需要复制的部分)。
步骤 2:复制公钥内容
- 找到
id_rsa.pub文件(路径参考步骤 1),用记事本/文本编辑器打开。 - 全选并复制文件里的所有内容(从
ssh-rsa开头到邮箱结尾的完整字符串)。
步骤 3:在平台粘贴并添加公钥
- 回到截图的“SSH 密钥”页面,在“在这里粘贴您的公钥”输入框中,粘贴刚复制的公钥内容。
- 在“名称”输入框中,给密钥起个好记的名字(比如“个人电脑 SSH 密钥”)。
- 点击“添加 SSH 密钥”按钮,完成添加。
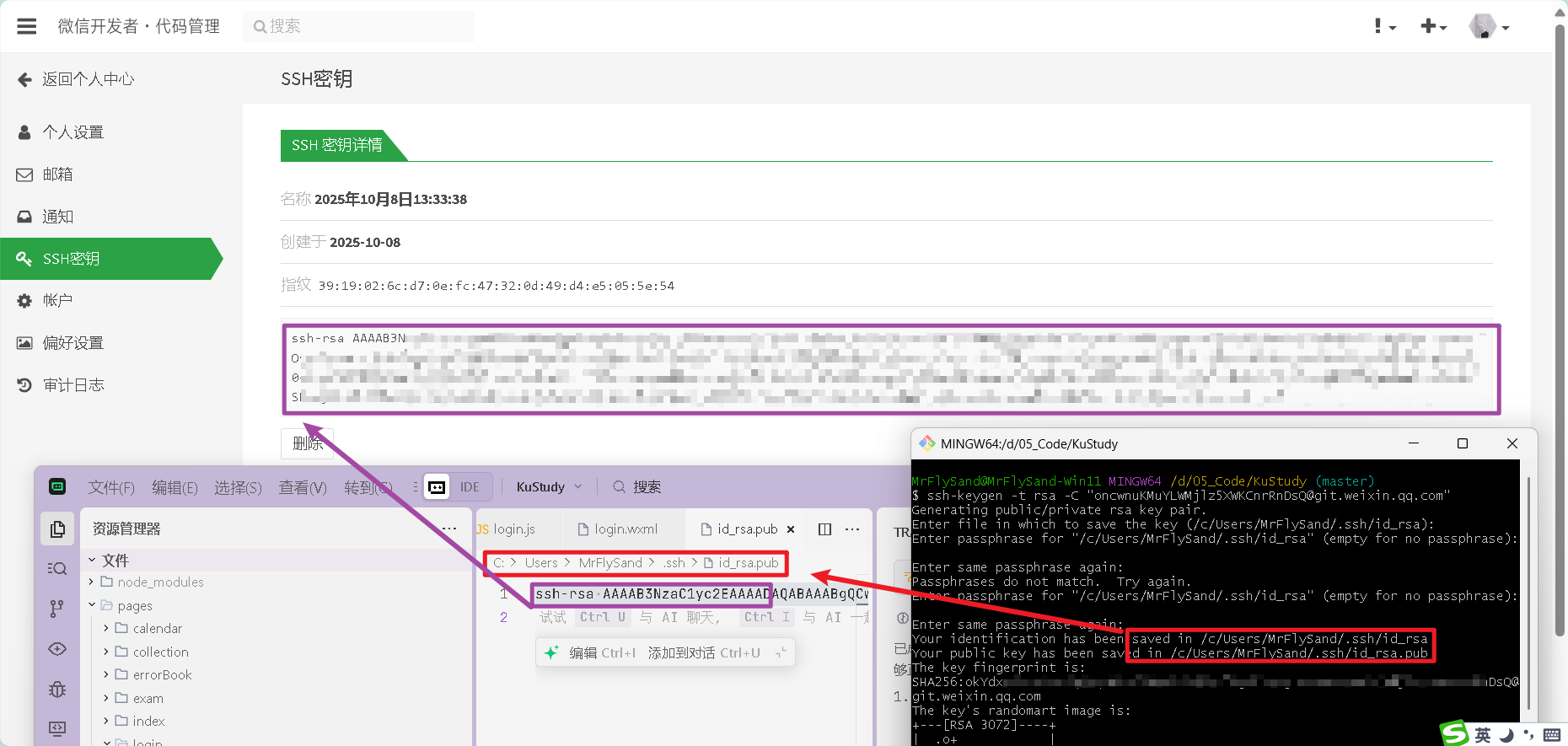

这样配置后,你的电脑就能通过 SSH 协议(更安全、免密码)与“微信开发者·代码管理”的仓库交互(拉取、推送代码)啦~
02 云开发
【数据同步出错了,让老板痛失 1 个亿!】 https://www.bilibili.com/video/BV1Xvnoz7EKJ/?share_source=copy_web&vd_source=e382d5e4e6b9fca0eddfd09f9d93b3b8
2.1 开通“云开发”
- 详情
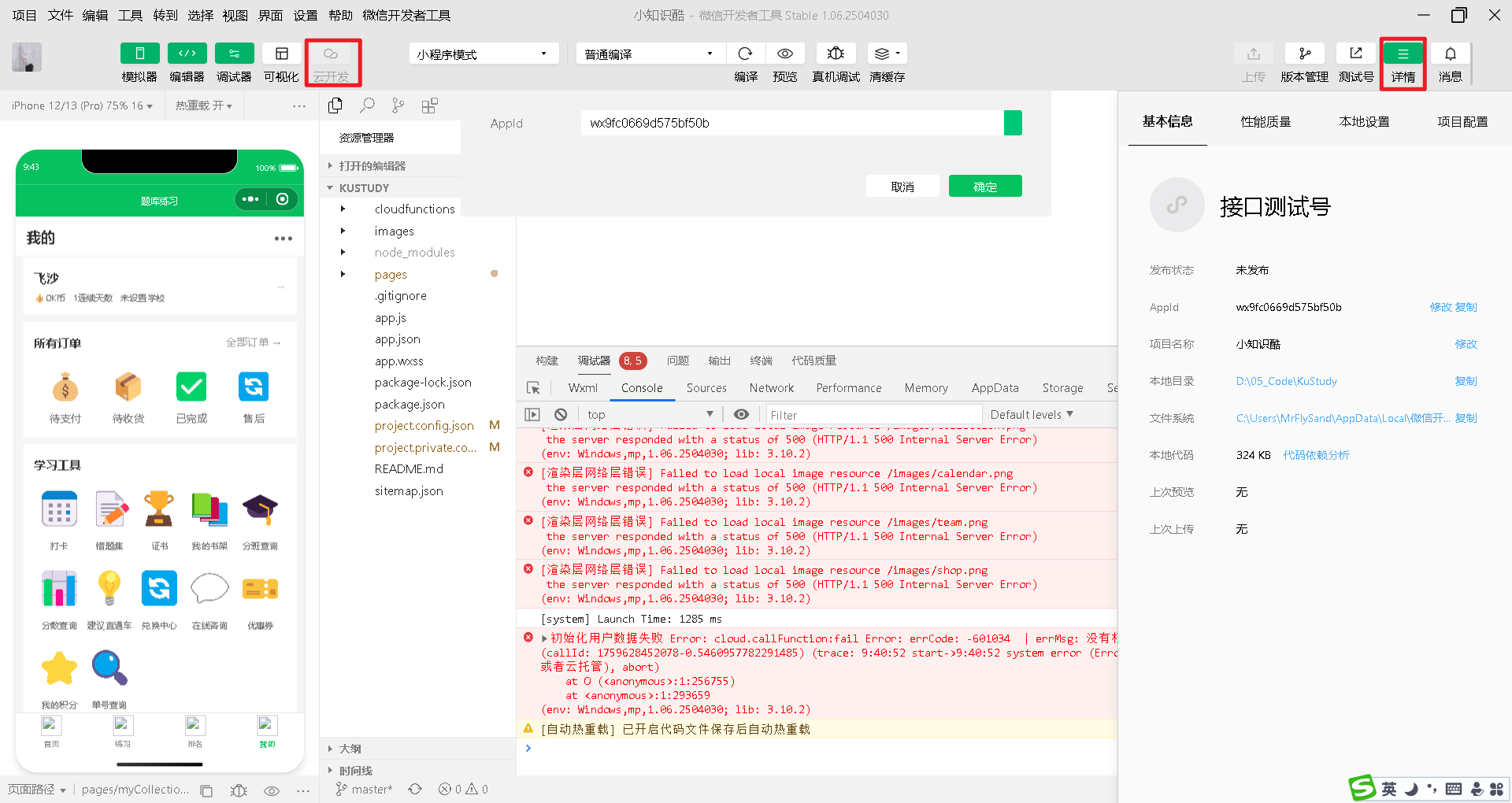
- 复制微信小程序的appID到微信小程序的appID
- 代码:添加数据到数据库Users中
const dbUsers = wx.cloud.database().collection('Users') // 引用 Users 集合
//添加数据到数据库Users中
dbUsers.add({
data: {
_openId: userInfo.openId,
nickName: userInfo.nickName,
avatarUrl: userInfo.avatarUrl,
createTime: new Date()
}
})
云开发初始化
-
将
env设置为自己云开发的id

-
参考
① https://developers.weixin.qq.com/miniprogram/dev/wxcloudservice/wxcloud/guide/init.html
② https://www.bilibili.com/video/BV1Uz4y197Uz/?spm_id_from=333.337.search-card.all.click&vd_source=b8e4168387f0df9d4df9652223fb9f4b
③ 【小程序云开发之数据库操作】 https://www.bilibili.com/video/BV1Uz4y197Uz/?share_source=copy_web&vd_source=e382d5e4e6b9fca0eddfd09f9d93b3b8
wx.cloud.init({
env: '修改为自己的云开发“环境ID”'
})

- 登录

云函数部署
- 参考链接 https://blog.csdn.net/Pomprogram/article/details/116308475
- 右击文件夹
cloudfunctions配置环境
- 右击要部署的文件夹,上传所有文件
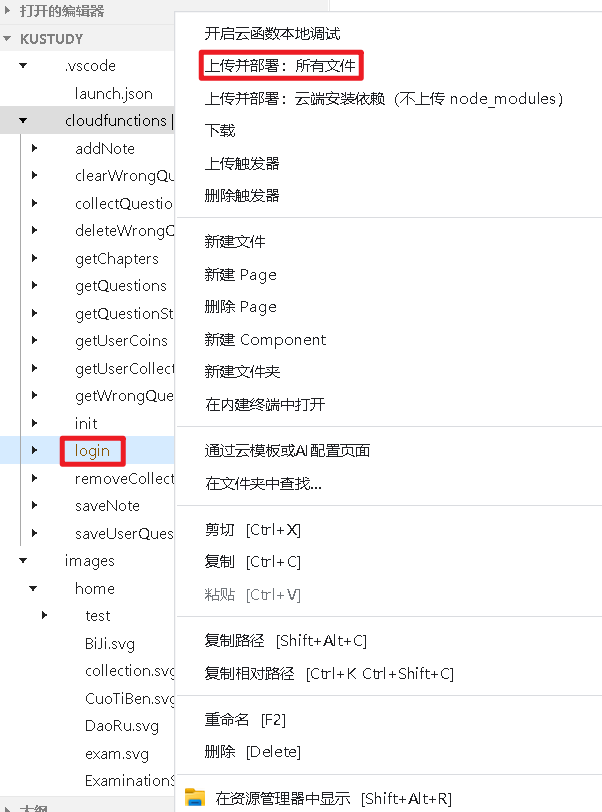
- 添加
新的云函数时 要先重复步骤2的内容,再对新的云函数右击选择“上传并部署:云端安装依赖”
这两个是微信云函数部署时的不同策略,核心区别体现在上传内容、依赖管理方式上,具体对比如下:
一、核心差异
| 维度 | 上传并部署:所有文件 | 上传并部署:云端安装依赖(不上传node_modules) |
|---|---|---|
| 上传内容 | 包含本地云函数文件夹内的所有文件(含node_modules依赖文件夹、代码文件、package.json等) |
仅上传代码文件(如index.js)和package.json,不上传本地的node_modules |
| 依赖安装方式 | 直接使用本地已安装好的node_modules(依赖随文件一起上传到云端) |
云端根据package.json中的依赖列表,自动下载安装node_modules |
| 部署耗时 | 若node_modules体积大(如依赖多),上传耗时较长 |
仅传代码文件,上传速度快;但需等待云端安装依赖,总耗时取决于云端下载速度 |
| 依赖一致性 | 云端依赖与本地完全一致(用的是本地已验证过的依赖版本) | 可能因云端npm版本、网络问题,导致安装的依赖版本与本地不一致 |
二、适用场景
-
上传并部署:所有文件
- 适用场景:本地已调试好依赖(如
wx-server-sdk版本已确认兼容)、依赖较复杂(避免云端安装出错); - 优势:依赖版本可控,避免云端安装的兼容性问题;
- 劣势:
node_modules体积大时,上传速度慢。
- 适用场景:本地已调试好依赖(如
-
上传并部署:云端安装依赖
- 适用场景:依赖简单(如仅需
wx-server-sdk)、想减少上传体积; - 优势:上传速度快,无需传输大体积的
node_modules; - 劣势:依赖版本可能与本地不一致,若
package.json未锁定版本,易出现兼容性问题。
- 适用场景:依赖简单(如仅需
获取用户的openid
参考链接://https://git.weixin.qq.com/wx_wx6bd6054ce20746d1/KuStudy/blob/9cd4157de2f2b06aeb966ad627f43a5cb05e7536/pages/login/login.js
获取用户的微信昵称和ID: https://developers.weixin.qq.com/miniprogram/dev/framework/open-ability/userProfile.html
https://developers.weixin.qq.com/miniprogram/dev/framework/open-ability/login.html
https://developers.weixin.qq.com/miniprogram/dev/api/open-api/login/wx.login.html
openid:https://developers.weixin.qq.com/miniprogram/dev/framework/open-ability/login.html
- 文件路径:
page\login\login.js,一定要使用wx.cloud.callFunction才能使用云函数。
getUserInfoByTap: function() {
console.log('用户点击授权登录');
// 使用wx.login获取用户的openid
wx.login({
success: (res) => {
console.log('wx.login返回结果:', res);
// 检查是否成功获取到code
if (res.code) {
// 调用云函数login获取用户openid
wx.cloud.callFunction({
name: 'login',// 云函数名称
data: {
code: res.code // 传递登录凭证code到云函数
},
success: (loginRes) => {
console.log('云函数login成功,返回结果:', loginRes);
},
fail: (err) => {
console.error('云函数调用失败:', err);
this.handleLoginFail('登录失败,请重试');
}
})
}
}
})
},
- 文件
cloudfunctions\login\index.js为云函数
// 云函数入口文件
const cloud = require('wx-server-sdk') // 引入微信云开发 SDK
cloud.init({
env: '你的云开发ID',
}) // 初始化云开发环境
// 云函数入口函数
exports.main = async (event, context) => {
const wxContext = cloud.getWXContext();
return {
openid: wxContext.OPENID, // 用户唯一标识(核心)
appid: wxContext.APPID, // 你的小程序 APPID
unionid: wxContext.UNIONID // 多端统一标识(需满足 UnionID 获取条件)
}
};
app.js中设置初始化云开发环境
onLaunch: function() {
// 初始化云开发环境
if (wx.cloud) {
wx.cloud.init({
env: 'kustudy2025-2gxdfl2c8d10f3df',
traceUser: true,
success: res => {
console.log('云开发环境初始化成功', res);
// 缓存云开发环境是否可用的状态
wx.setStorageSync('cloudEnvAvailable', true);
},
fail: err => {
console.error('云开发环境初始化失败', err);
// 缓存云开发环境是否可用的状态
wx.setStorageSync('cloudEnvAvailable', false);
// 显示友好的提示信息给用户
wx.showToast({
title: '云开发环境不可用',
icon: 'none',
duration: 2000
});
}
})
} else {
console.error('当前微信版本不支持云开发,请升级到最新版本');
wx.setStorageSync('cloudEnvAvailable', false);
}
},
03 数据库
【5★20分钟入门数据库】 https://www.bilibili.com/video/BV1Mm5kzHEWA/?share_source=copy_web&vd_source=e382d5e4e6b9fca0eddfd09f9d93b3b8
第二范式(2NF):消除非主属性对主键的部分依赖。和主键不讲同一件事的单开一张表
- 两张表,1:n的关系,n的那张添加外键
第三范式(3NF)消除非主属性之间的传递依赖(和主键不是直接相关的移出去)
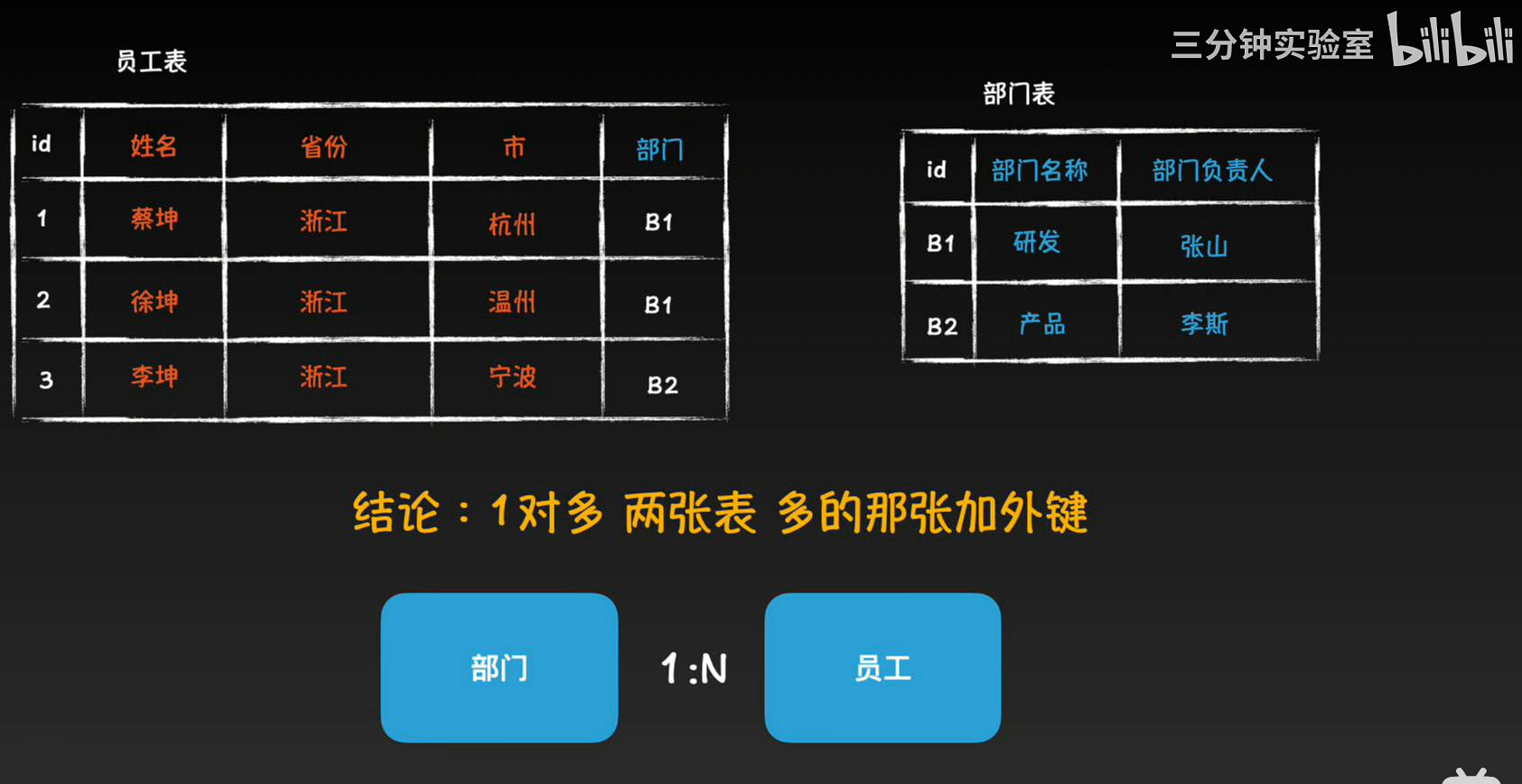
- m:n 三张表,第三张表两个外键
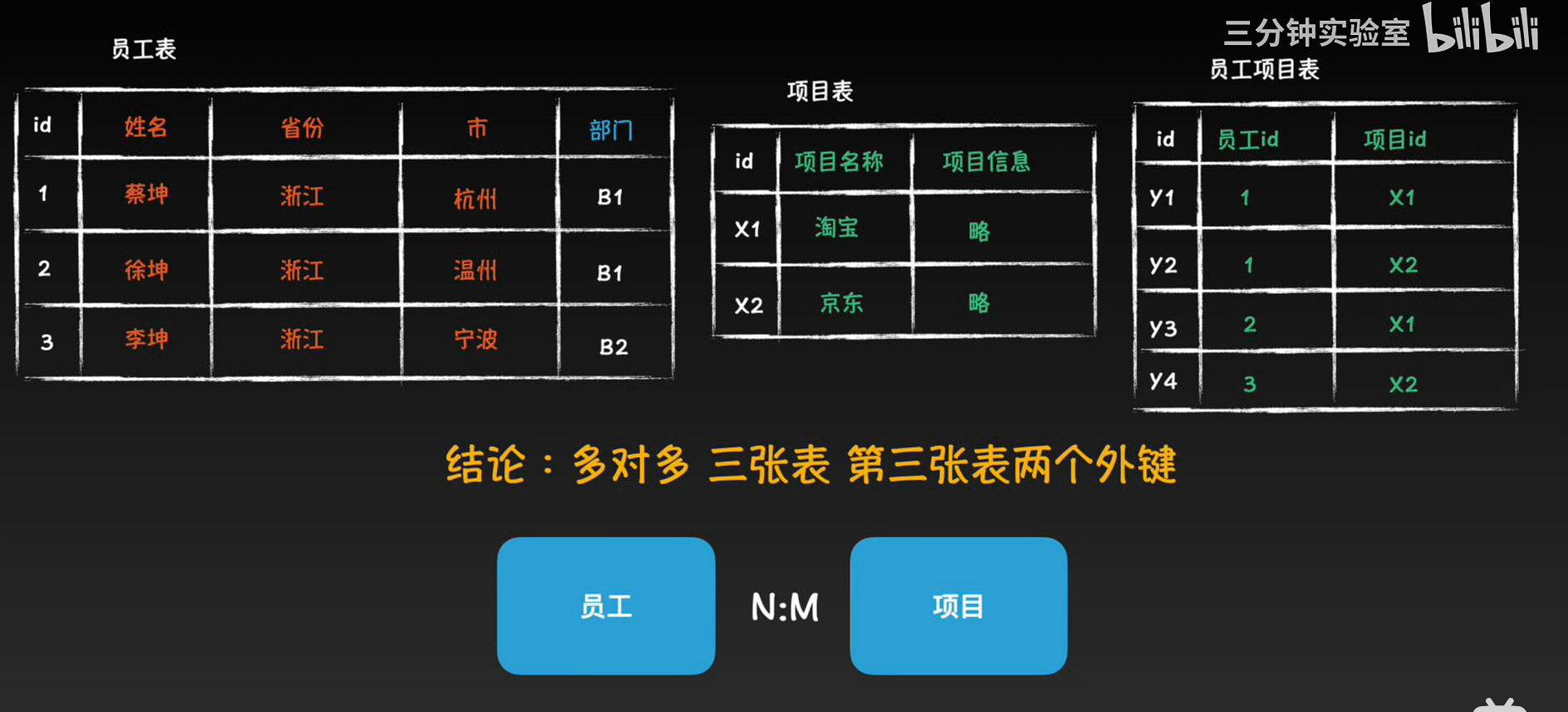
n:m
(一)从数据库中获取信息
// 从数据库获取用户的完整信息,包括K币
const db = wx.cloud.database();
const userResult = await db.collection('Users').where({_openid: openid}).get();
console.log('从数据库获取用户信息结果:', userResult);
- 如何你获取不到信息,要看看设置权限。设置“所有人可读”,然后再重启小程序。
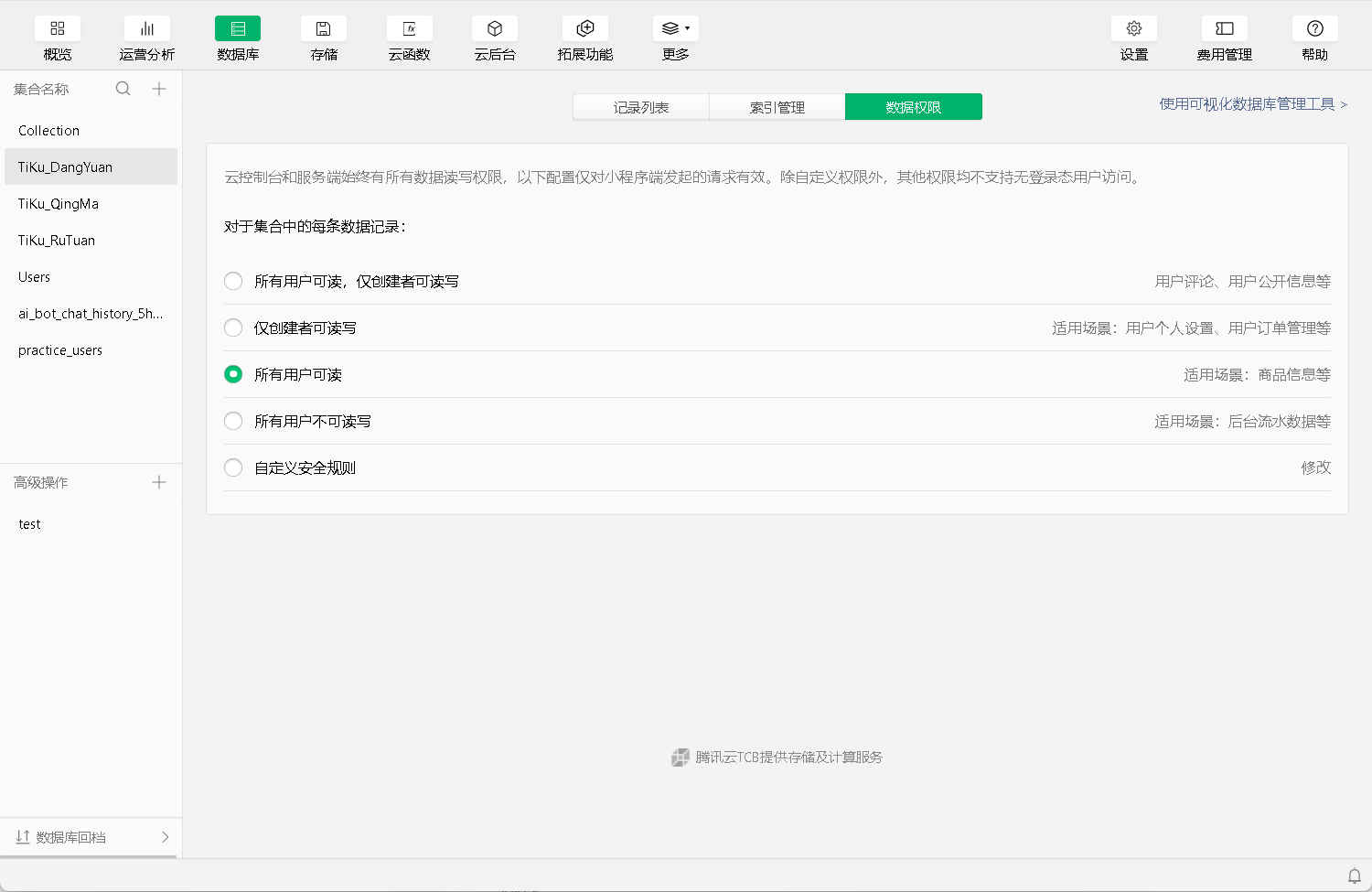
2. 索引

(二)添加数据到数据库Users中
const dbUsers = wx.cloud.database().collection('Users') // 引用 Users 集合
//添加数据到数据库Users中
dbUsers.add({
data: {
_openId: userInfo.openId,
nickName: userInfo.nickName,
avatarUrl: userInfo.avatarUrl,
createTime: new Date()
}
})
(三)添加数据表到数据库
- 内容都要改为文本型
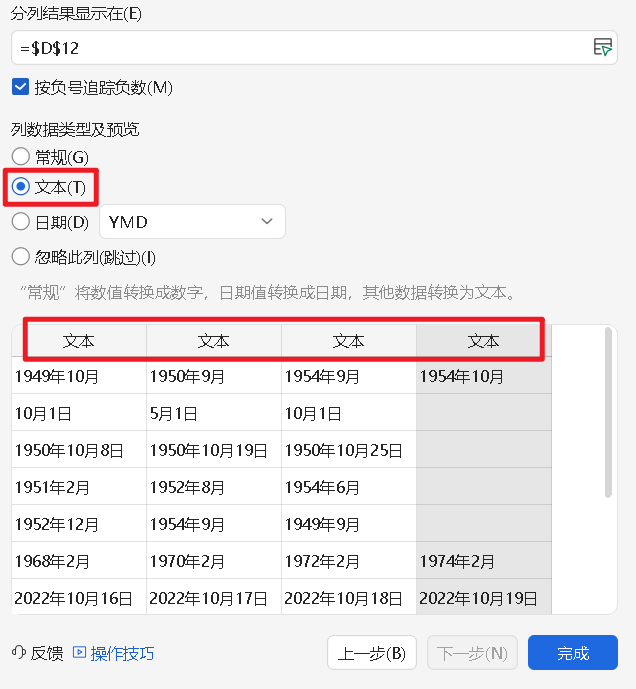
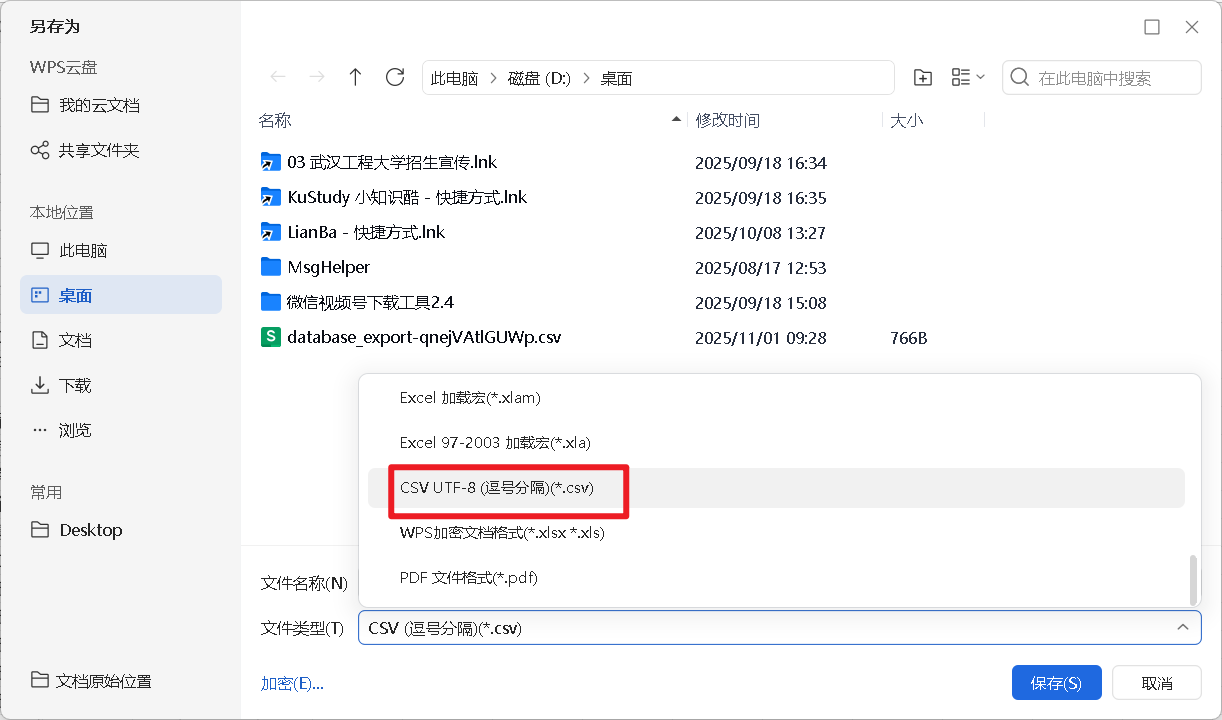
- 乱码:https://ask.csdn.net/questions/8214765
使用gbk打开,再使用utf-8保存,上传到云开发
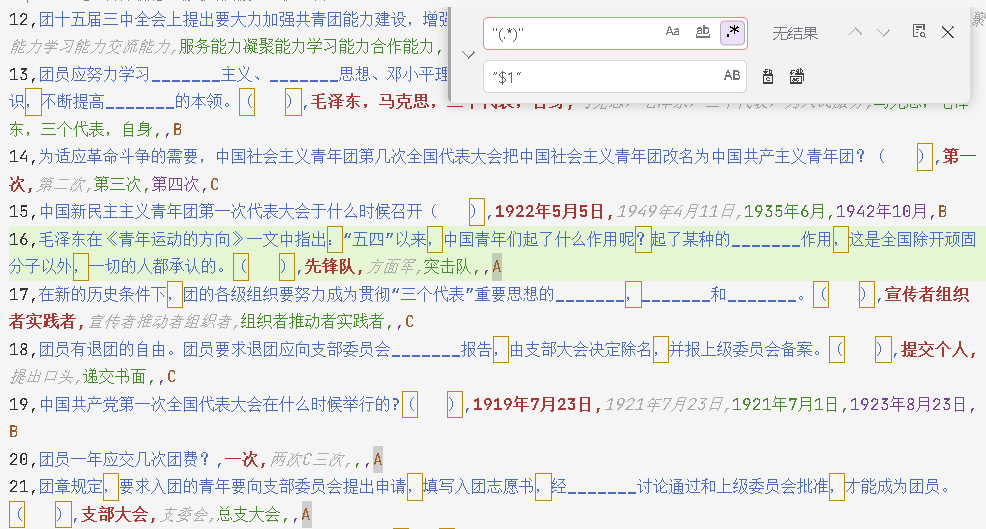
-
将
"(.*)"替换为“$1”,将'(.*)'替换为“$1”,数据中不能存在英文单引号或双引号
-
检查错误
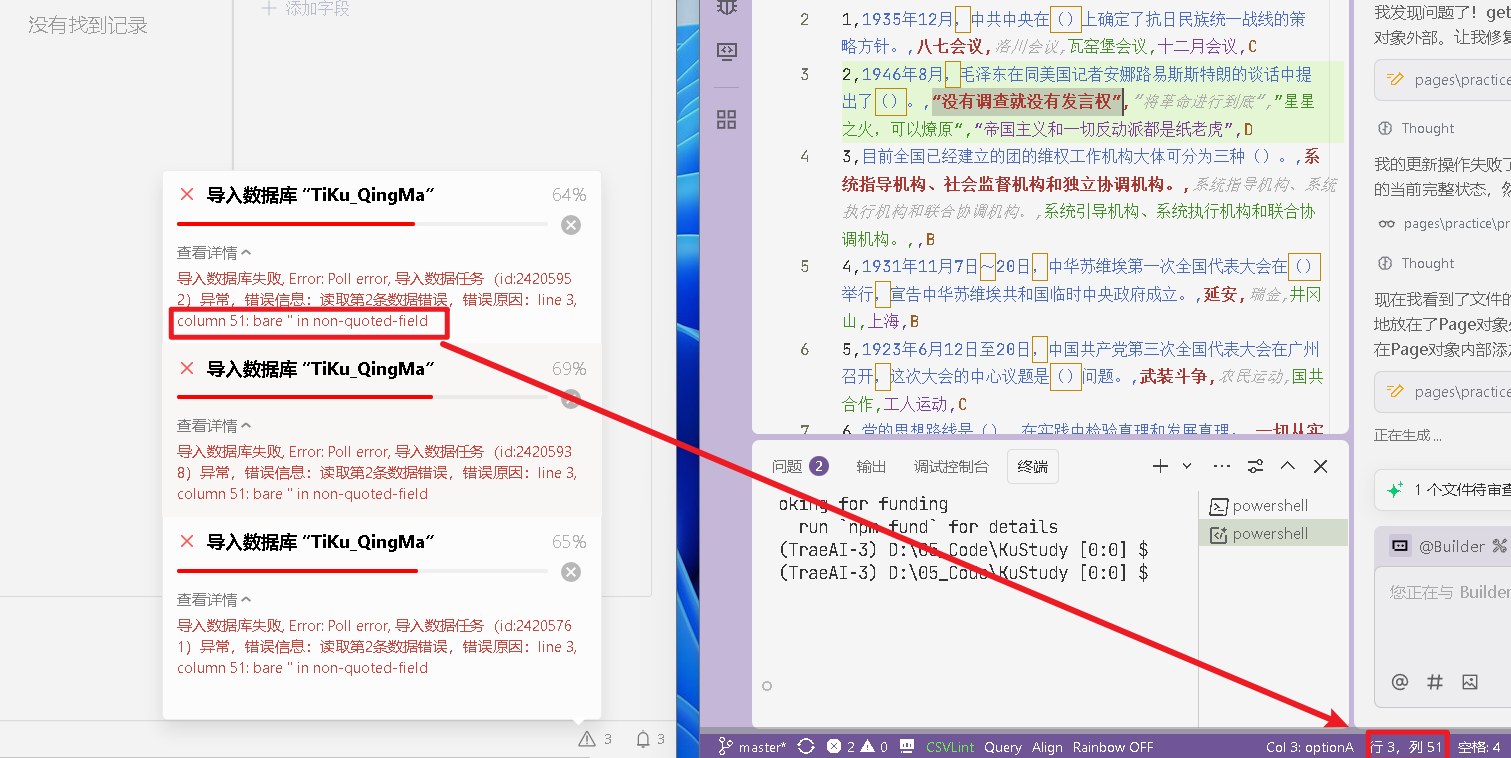
this.questions = allData; 和 wx.setStorageSync(collectionName, allData);的区别
this.questions = allData; 和 wx.setStorageSync(collectionName, allData); 是两种完全不同的数据存储方式,核心区别体现在存储位置、生命周期、用途上,具体如下:
| 维度 | this.questions = allData; |
wx.setStorageSync(collectionName, allData); |
|---|---|---|
| 存储位置 | 当前页面/组件的内存实例中(临时存储) | 用户设备的本地存储中(持久化存储,如手机硬盘) |
| 生命周期 | 随页面/组件实例销毁而消失(如用户跳转页面、关闭小程序) | 持久化保存,除非主动删除(小程序关闭后重新打开仍存在,甚至卸载后可能保留) |
| 用途 | 用于当前页面/组件的实时数据绑定与交互 | 用于长期保存数据(如用户答题记录、本地缓存的题库数据) |
| 数据读取方式 | 直接通过 this.questions 访问(内存读取,速度极快) |
需通过 wx.getStorageSync(collectionName) 读取(磁盘IO,速度较慢) |
| 大小限制 | 无明确限制,但过多会占用内存,影响小程序性能 | 受小程序本地存储总容量限制(通常为10MB,超出会报错) |
| 页面渲染关联 | 若后续用 this.setData({ questions: this.questions }) 可触发页面重新渲染 |
与页面渲染无直接关联,需先读取到内存中再通过 setData 绑定渲染 |
举例理解:
假设 allData 是用户当前正在做的一套题库数据:
- 用
this.questions = allData;:将题库数据存到当前页面的内存中,方便快速访问(如渲染题目、判断用户答案),用户离开该页面后,数据自动释放,不占用额外资源。 - 用
wx.setStorageSync('questionBank', allData);:将题库数据存到本地存储,用户下次打开小程序时,可直接从本地读取,无需重新请求服务器,节省流量和加载时间。
开发建议:
- 临时使用、仅当前页面需要的数据(如页面交互状态、临时计算结果)→ 用
this.xxx存储。 - 需要长期保存、跨页面共享或下次打开仍需使用的数据(如用户配置、离线缓存的内容)→ 用
wx.setStorageSync存储。
核心区别:this.setData({ isCorrect: isCorrect }) 是官方指定的页面数据更新方式(触发渲染),this.isCorrect 是直接操作页面实例属性(不触发渲染),具体差异如下:
| 维度 | this.setData({ isCorrect: isCorrect }) |
this.isCorrect = isCorrect |
|---|---|---|
| 存储位置 | 数据存入页面的 data 对象(this.data.isCorrect) |
数据直接挂载到页面实例上(与 data 无关) |
| 是否触发渲染 | 是!会通知小程序重新渲染页面中绑定 {{isCorrect}} 的组件 |
否!仅在实例上存储数据,页面DOM不会更新 |
| 访问方式 | 需通过 this.data.isCorrect 读取(更新后的数据同步在 data 中) |
直接通过 this.isCorrect 读取 |
| 数据限制 | 支持复杂数据(对象、数组),但需注意浅拷贝,过大数据会影响性能 | 无特殊限制,但不参与页面数据绑定 |
| 使用场景 | 需在页面中展示/更新的数据(如答题正确与否的状态、分数变化) | 仅当前页面临时使用、无需渲染到页面的中间数据(如临时计算结果) |
举个直观例子:
假设页面WXML有:
<view>答题结果:{{isCorrect ? '正确' : '错误'}}</view>
1. 用 this.setData(页面会更新):
const isCorrect = true;
this.setData({ isCorrect }); // 触发页面渲染
console.log(this.data.isCorrect); // 正确:输出 true(从data中读取)
// 页面会显示「答题结果:正确」
2. 用 this.isCorrect(页面不更新):
const isCorrect = true;
this.isCorrect = isCorrect; // 仅存储在实例,不触发渲染
console.log(this.isCorrect); // 输出 true(从实例属性读取)
console.log(this.data.isCorrect); // 输出 undefined(未存入data)
// 页面仍显示原始内容,不会更新为「正确」
关键注意事项:
- 小程序页面的数据绑定依赖
data对象,只有通过setData更新data中的数据,页面才会同步渲染。 - 直接给
this赋值(this.xxx)的变量,不属于页面绑定数据,仅作为临时存储,页面销毁后数据丢失。 - 若想让
this.isCorrect的数据同步到页面,需额外调用this.setData({ isCorrect: this.isCorrect })。
简单总结:需要在页面上显示或更新的状态(如答题结果、表单值),必须用 this.setData;仅临时使用、不用展示的数据,可直接用 this.xxx 存储。
要不要我帮你整理一份小程序数据更新常用场景对照表?涵盖临时数据、页面渲染数据、跨页面数据的存储方式和调用示例,方便直接参考使用。
2.2 图片显示
要解决图片消失的问题,可按以下步骤排查并处理:
步骤1:验证图片路径是否正确
- 打开微信开发者工具的资源管理器,找到
images文件夹,确认WeChat2.jpg确实存在,且文件名大小写完全匹配(小程序路径对大小写敏感)。 - 若路径错误(如文件名拼写错误、文件夹层级不对),需修正路径为正确的
src="/images/WeChat2.jpg"。
步骤2:检查样式冲突,确保图片可显示
微信小程序中,父元素或图片自身的样式可能导致图片被隐藏。可通过以下方式调整:
方法A:调整图片 mode(推荐)
在 <image> 标签中添加 mode="aspectFit",该模式会保持图片纵横比并确保图片完全显示(长边填满容器,短边可能留空,但图片不变形):
<image src="/images/WeChat2.jpg" mode="aspectFit" role="img"></image>
方法B:明确设置图片/父容器样式
打开对应页面的 wxss 文件(如 overgraduateInformation.wxss 或 index.wxss),添加以下样式,强制图片按比例显示:
/* 针对图片的样式 */
.container-nav image {
width: 100%; /* 宽度自适应父容器 */
height: auto; /* 高度自动按比例缩放 */
display: block;/* 消除默认间隙 */
}
/* 针对父容器的样式(若父容器高度为0,需设置) */
.container-nav {
height: auto; /* 或根据需求设置固定高度,如 300rpx */
}
步骤3:检查图片格式与完整性
确认 WeChat2.jpg 是支持的格式(jpg、png、gif 等),且图片文件未损坏(可在电脑中直接打开验证)。
通过以上步骤,可解决图片路径错误、样式冲突或显示模式导致的“图片消失”问题,同时保证图片高度不变形。
3.1 数据库批量导出和导入
要实现腾讯云文档型数据库(CloudBase)的多集合批量导出+企业环境批量导入,可通过「手动操作」(适合少量集合)或「CLI命令行」(适合大量集合)完成,具体步骤如下:
一、手动批量导出(个人开发者端)
适用于集合数量较少的场景:
- 登录个人开发者的腾讯云CloudBase控制台,进入目标云环境的「文档型数据库」→「集合管理」;
- 对每个需要迁移的集合(如
BookTeam、Collection等):- 点击集合名称进入「文档列表」;
- 点击「导出数据」,选择格式为
JSON(兼容性最优),确认后下载文件,命名为「集合名.json」(如BookTeam.json);
- 将所有导出的
JSON文件整理到同一个本地文件夹(方便后续导入)。
二、手动批量导入(企业端)
需在企业主体的腾讯云CloudBase环境中操作:
- 登录企业主体的腾讯云CloudBase控制台,进入目标云环境的「文档型数据库」→「集合管理」;
- 对每个要导入的集合:
- 若企业环境无对应集合,先点击「+」创建同名集合(如
BookTeam); - 进入该集合的「文档列表」,点击「导入数据」,选择本地对应的「集合名.json」文件,确认导入(保持默认配置即可);
- 若企业环境无对应集合,先点击「+」创建同名集合(如
- 重复步骤2,完成所有集合的数据导入。
三、CLI命令行批量操作(适合大量集合)
若集合数量较多,用命令行工具更高效:
步骤1:安装CloudBase CLI
在本地终端执行:
npm install -g @cloudbase/cli
步骤2:个人端批量导出
- 登录个人开发者账号:
tcb login
- 批量导出指定集合(将
envId替换为个人环境ID,collections后填需要导出的集合名):
tcb database export --envId 个人环境ID --collections BookTeam Collection DB_Information --output ./export_data
执行后,所有集合的JSON文件会保存到本地./export_data文件夹。
步骤3:企业端批量导入
- 登录企业主体账号:
tcb login # 若已登录个人账号,需先执行`tcb logout`退出
- 批量导入所有集合(将
envId替换为企业环境ID):
tcb database import --envId 企业环境ID --input ./export_data
执行后,工具会自动识别./export_data中的集合文件,批量创建集合并导入数据。
关键注意事项
- 权限要求:操作双方需具备对应云环境的「数据库管理员」权限;
- 格式兼容:优先选择
JSON格式导出/导入,避免格式不兼容问题; - 数据一致性:导入前需确保企业环境无同名集合(或已清空旧数据),避免数据冲突。
是否需要我帮你整理一份CLI命令行操作的详细参数说明表?
06 文章
6.1 腾讯云创建子账号
要使用子账号替代主账号API密钥,需通过腾讯云“访问管理”功能完成子账号创建、权限配置、密钥生成三个核心步骤,具体操作如下:
步骤1:创建子账号
- 登录腾讯云控制台,进入「访问管理」页面;
- 在左侧导航栏选择「用户管理」→「用户」,点击「新建用户」;
- 选择「自定义创建」,填写子账号名称、备注等基本信息;
- 在“访问方式”中勾选「编程访问」(需生成API密钥用于接口调用),点击“下一步”。
步骤2:配置子账号权限(遵循“最小权限原则”)
为避免权限过度开放,仅给子账号分配业务所需的最小权限:
- 在“权限设置”环节,点击「关联策略」;
- 根据实际业务需求选择预设策略(例如:若子账号用于调用AI接口,可选择「QcloudNlpFullAccess」;若用于云函数操作,可选择「QcloudSCFFullAccess」);
- 若无匹配的预设策略,可创建「自定义策略」,精确配置所需接口/资源的操作权限,完成后点击“完成”。
步骤3:生成子账号API密钥
- 子账号创建完成后,返回「访问管理」→「API密钥管理」;
- 在页面顶部的“用户”下拉框中,选择刚创建的子账号;
- 点击「新建密钥」,系统会生成该子账号对应的
SecretId和SecretKey,请及时复制保存(SecretKey仅展示一次,需妥善保管)。
步骤4:使用子账号密钥
将原代码/配置中主账号的SecretId和SecretKey,替换为子账号生成的密钥,即可完成子账号的接口调用/资源操作。
通过子账号操作,可有效隔离主账号的全局权限,即使子账号密钥泄露,也仅会影响其被授权的有限资源,大幅降低安全风险。
6.2 使用 ai 腾讯云混元大模型
作为新手,你可以按照以下从基础准备到代码实现的全流程详细步骤解决这个问题,每一步都配操作细节:
一、前置准备:确认账号与开通服务
(签名失败的前提是要先有可用的服务和权限)
- 开通腾讯云混元大模型服务(作文评分用的接口所属服务)
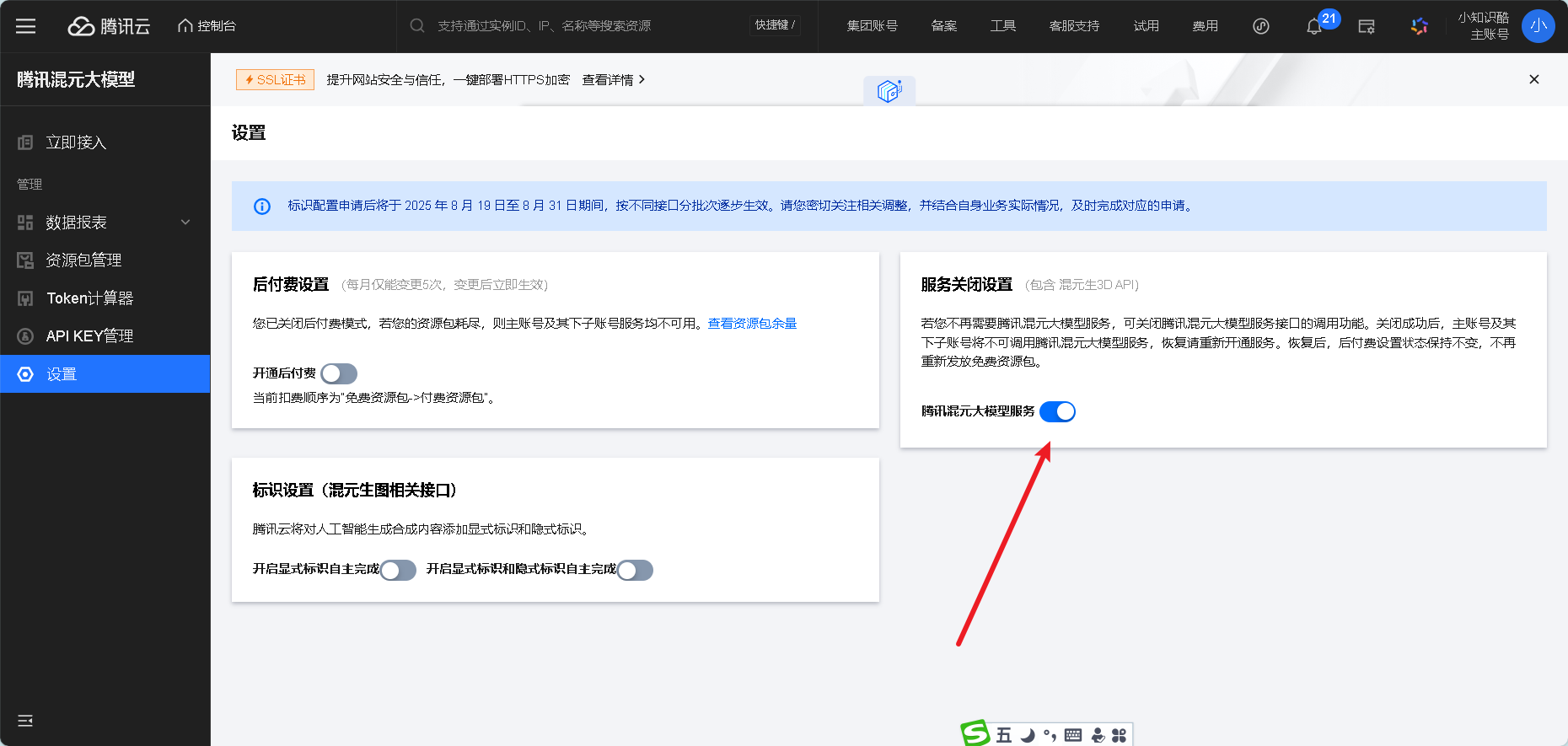
二、步骤1:创建子账号并获取正确的密钥(避免用主账号,更安全)
主账号密钥权限过高,新手优先用子账号密钥:
-
进入「访问管理(CAM)」控制台:https://console.cloud.tencent.com/cam
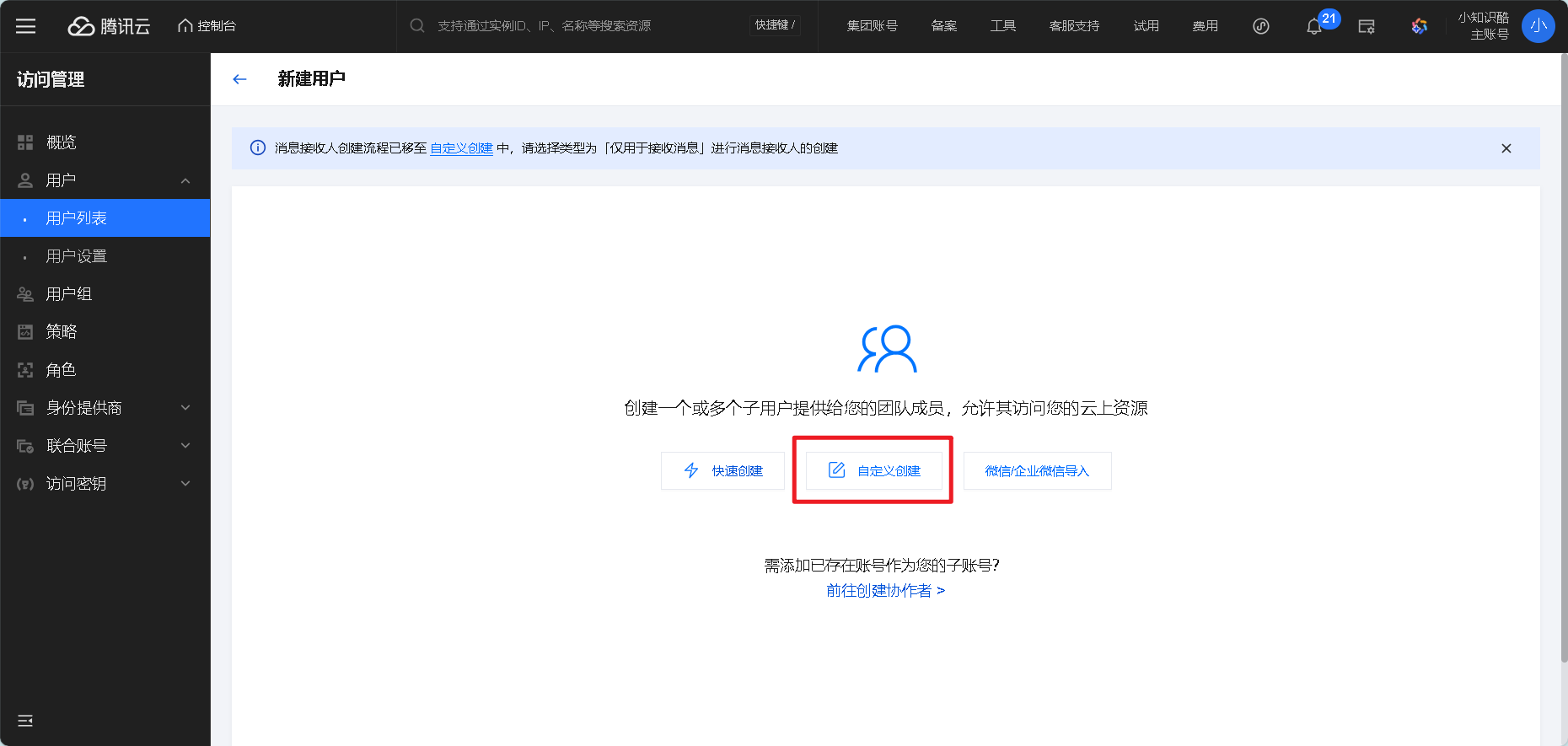
-
左侧菜单选「用户管理」→「用户」→ 点击「新建用户」
-
选择「自定义创建」- [可访问资源并接收消息],填写子账号名称(比如
essay-score-user),勾选「编程访问」(必须选,才能生成API密钥),点击「下一步」
-
权限配置:先选「直接关联策略」,然后点击「新建自定义策略」(因为预设策略可能搜不到)
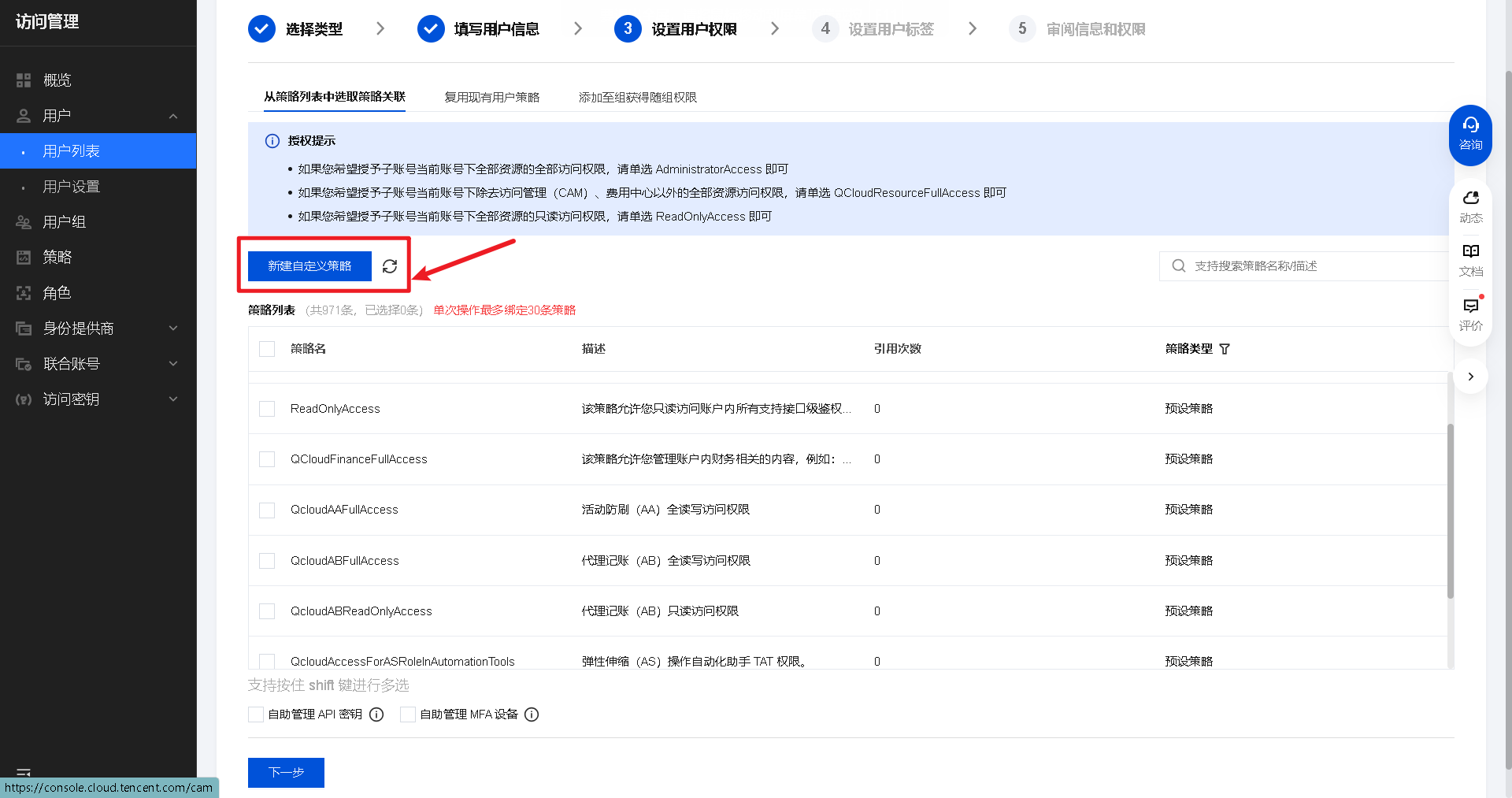
-
选择「按策略语法创建」→「空白模板」,粘贴以下策略(仅开放混元大模型调用权限):
{
"version": "2.0",
"statement": [
{
"effect": "allow",
"action": [
"hunyuan:ChatCompletions"
],
"resource": "*"
}
]
}
点击「下一步」,命名策略(比如Hunyuan-Essay-Score),点击「完成」
5. 回到子账号权限配置页(图5),搜索并勾选刚创建的Hunyuan-Essay-Score策略,点击「完成」
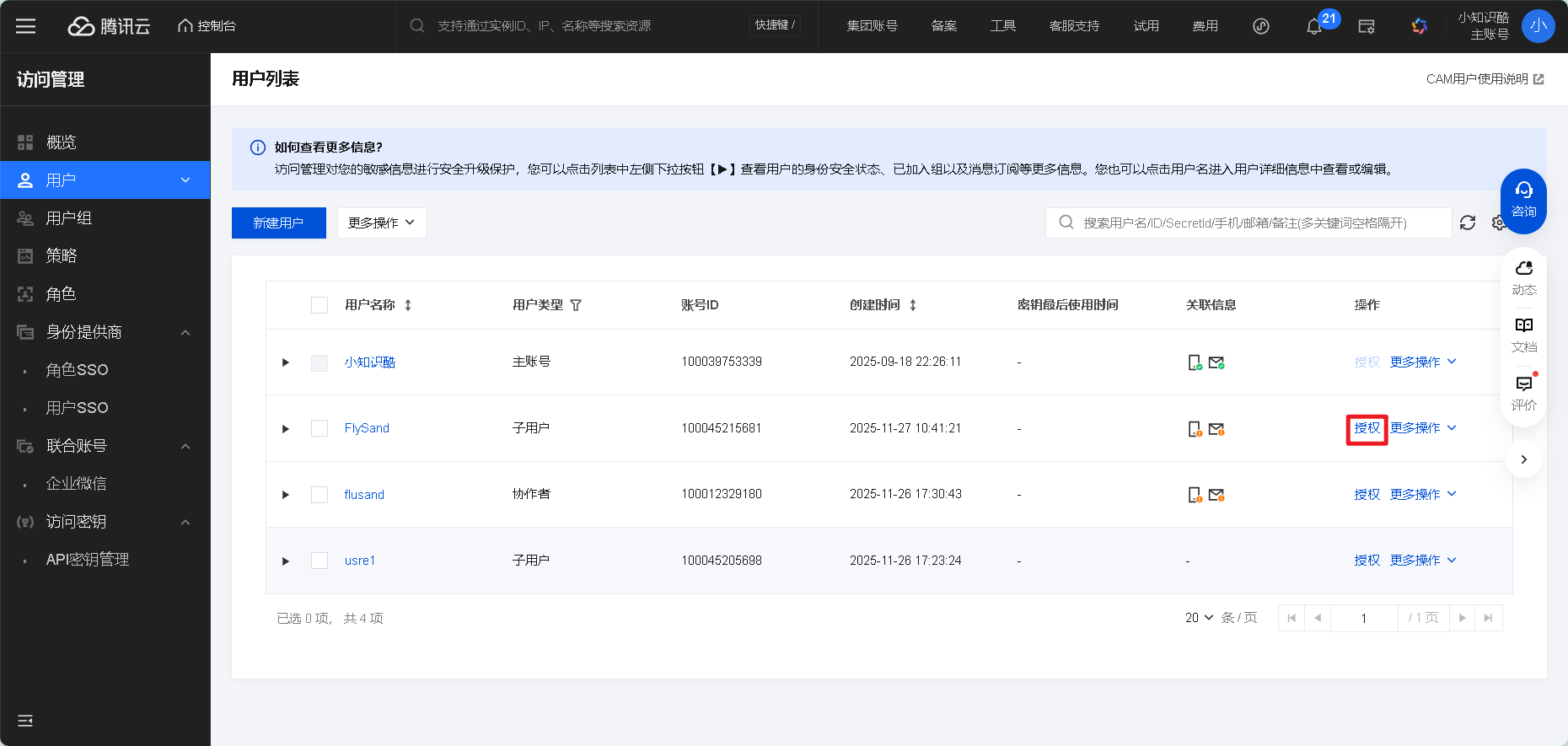
图5
- 子账号创建完成后,点击该子账号的「API密钥」→「新建密钥」,会生成
SecretId和SecretKey(SecretKey仅显示一次,务必复制保存到本地文档)
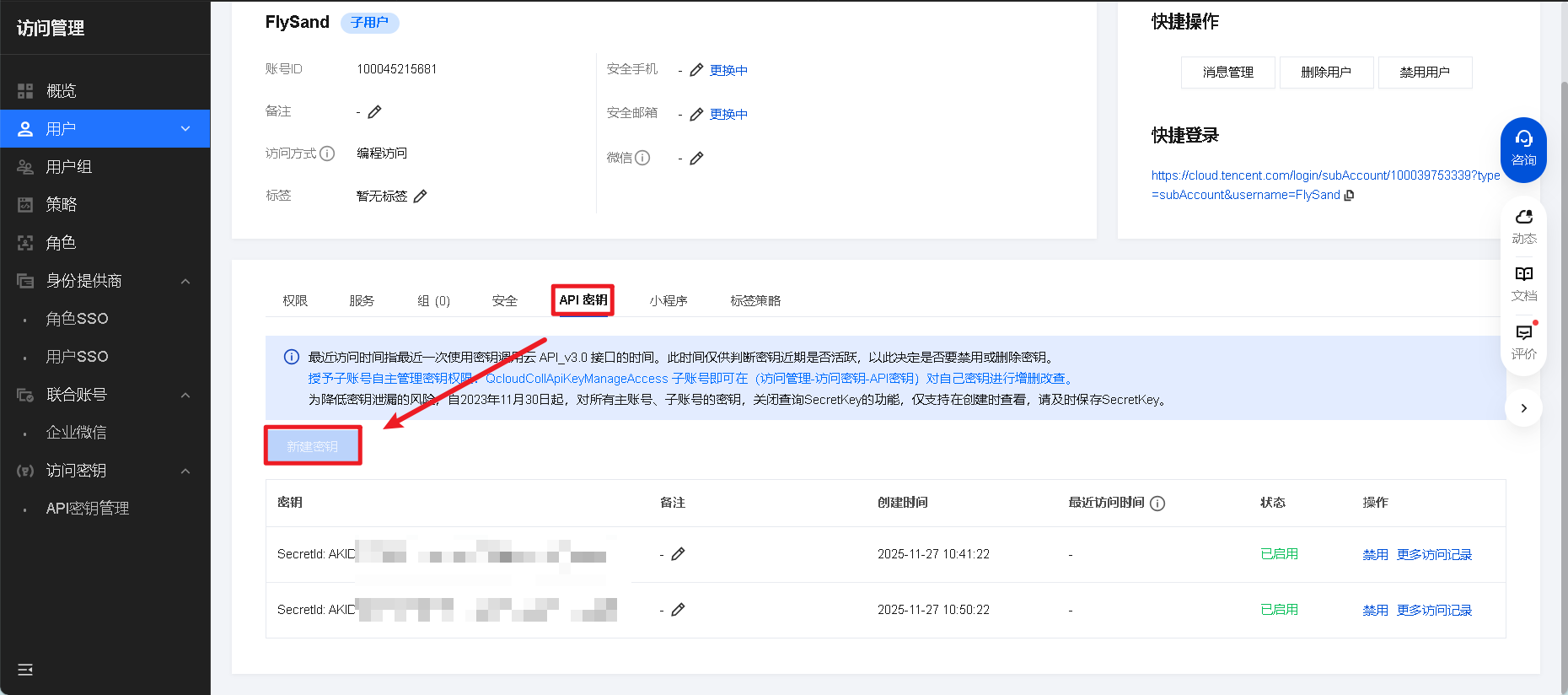
API密钥/SecretId
三、步骤2:用官方SDK调用接口(自动处理签名,避免手动错误)
手动生成签名是新手最容易出错的环节,必须用腾讯云官方SDK,SDK会自动处理签名逻辑:
- 打开你的小程序云函数项目(比如之前的
aiScore云函数),在云函数目录下执行:# 安装腾讯云官方SDK(Node.js环境,和你的Eaxm.js对应) npm install tencentcloud-sdk-nodejs - 替换云函数代码为以下内容(复制后只需要改
SecretId和SecretKey):// 云函数入口文件 const tencentcloud = require("tencentcloud-sdk-nodejs"); // 引入混元大模型的客户端(对应作文评分接口) const HunyuanClient = tencentcloud.hunyuan.v20230901.Client; exports.main = async (event, context) => { try { // 1. 配置客户端(替换成你子账号的SecretId和SecretKey) const client = new HunyuanClient({ credential: { secretId: "你的子账号SecretId", // 替换这里 secretKey: "你的子账号SecretKey", // 替换这里 }, region: "ap-guangzhou", // 必须选这个地域(混元大模型的核心地域) profile: { httpProfile: { endpoint: "hunyuan.tencentcloudapi.com", // 固定地址 }, }, }); // 2. 定义作文评分的提示词和用户作文 const userEssay = event.userEssay; // 从前端传递的用户作文 const params = { Model: "hunyuan-pro", // 混元大模型的版本(免费可用) Messages: [ { Role: "System", Content: "你是英语作文评分老师,按0-100分评分,维度:语法准确性30分、内容契合度25分、结构完整性20分、词汇丰富度25分。先返回分数(仅数字),再用50字说明理由。" }, { Role: "User", Content: userEssay } ], }; // 3. 调用API评分 const result = await client.ChatCompletions(params); // 解析结果(提取分数和评语) const aiReply = result.Choices[0].Message.Content; const score = aiReply.match(/\d+/)[0]; const comment = aiReply.replace(/^\d+/, "").trim(); return { code: 0, data: { score, comment } }; } catch (err) { console.error("作文评分失败:", err); return { code: -1, msg: "评分失败,请稍后重试" }; } };
我的代码如下:
// 云函数:scoreEssay
// 功能:调用腾讯云混元大模型API对作文进行评分
// 使用说明:
// 1. 在小程序端调用:wx.cloud.callFunction({ name: 'scoreEssay', data: { userEssay: '用户作文内容' } })
// 2. 返回结果:{ success: true, data: { score: 分数, comment: '评语' } } 或 { success: false, error: '错误信息' }
const cloud = require('wx-server-sdk');
// 导入腾讯云基础SDK
const tencentcloud = require("tencentcloud-sdk-nodejs");
// 引入混元大模型的客户端(对应作文评分接口)
const HunyuanClient = tencentcloud.hunyuan.v20230901.Client;
// 初始化云开发环境
cloud.init({
env: cloud.DYNAMIC_CURRENT_ENV
});
/**
* 云函数入口函数
* @param {Object} event - 事件对象,包含前端传递的参数
* @param {string} event.userEssay - 用户作文内容
* @param {Object} context - 上下文对象
* @returns {Object} - 评分结果
*/
exports.main = async (event, context) => {
try {
console.log('云函数被调用,事件参数:', event);
// 1. 验证参数
if (!event.userEssay || typeof event.userEssay !== 'string') {
console.error('参数验证失败: 用户作文内容不存在或不是字符串');
return {
success: false,
error: '作文内容不能为空'
};
}
// 2. 配置客户端(从环境变量获取密钥)
const client = new HunyuanClient({
credential: {
secretId: process.env.TENCENTCLOUD_SECRET_ID || "you", // 请替换为您的腾讯云SecretId
secretKey: process.env.TENCENTCLOUD_SECRET_KEY || "you", // 请替换为您的腾讯云SecretKey
},
region: "ap-beijing", // 混元大模型默认地域为北京
profile: {
httpProfile: {
endpoint: "hunyuan.tencentcloudapi.com", // 固定地址
},
},
});
// 3. 定义作文评分的提示词和用户作文
const userEssay = event.userEssay; // 从前端传递的用户作文
const params = {
Model: "hunyuan-pro", // 混元大模型的版本
Messages: [
{
Role: "system", // 角色名应为小写
Content: "你是英语作文评分老师,按0-100分评分,维度:语法准确性30分、内容契合度25分、结构完整性20分、词汇丰富度25分。先返回分数(仅数字),再用50字说明理由。"
},
{
Role: "user", // 角色名应为小写
Content: userEssay
}
],
};
// 4. 调用API评分
console.log('准备调用混元大模型API,参数:', params);
const result = await client.ChatCompletions(params);
console.log('API调用成功,返回结果:', result);
// 5. 解析结果(提取分数和评语)
if (!result.Choices || result.Choices.length === 0) {
console.error('模型返回结果格式错误: Choices不存在或为空', result);
return {
success: false,
error: '模型返回结果格式错误'
};
}
const aiReply = result.Choices[0].Message.Content;
console.log('模型返回的内容:', aiReply);
const scoreMatch = aiReply.match(/\d+/);
if (!scoreMatch) {
console.error('无法从模型返回结果中提取分数', aiReply);
return {
success: false,
error: '无法从模型返回结果中提取分数'
};
}
const score = scoreMatch[0];
const comment = aiReply.replace(/^\d+/, "").trim();
// 6. 返回成功结果,保持与前端代码兼容的格式
return {
success: true,
data: {
score,
comment
}
};
} catch (err) {
console.error("作文评分失败 - 完整错误信息:", JSON.stringify(err, null, 2));
console.error("错误类型:", typeof err);
console.error("错误message:", err.message);
console.error("错误code:", err.code);
// 返回错误信息,保持与前端代码兼容的格式
return {
success: false,
error: err.message || err.code || '评分失败,请稍后重试'
};
}
};
四、步骤3:前端传递作文并测试
- 小程序前端JS页面(比如
Eaxm.js)中,调用云函数时传递作文内容:// Eaxm.js中提交作文的方法 submitEssay() { const userEssay = "这里是用户输入的英语作文内容"; // 替换成实际输入框的值 wx.cloud.callFunction({ name: "aiScore", // 你的云函数名称 data: { userEssay }, success: (res) => { console.log("评分结果:", res.result.data); // 拿到分数和评语 }, fail: (err) => { console.error("调用云函数失败:", err); } }); } - 部署云函数:在微信开发者工具中,右键云函数目录→「部署」
五、如果仍报错的排查点
-
确认
SecretId/SecretKey是子账号的,且没有复制错误; -
确认子账号已关联了
Hunyuan-Essay-Score策略;
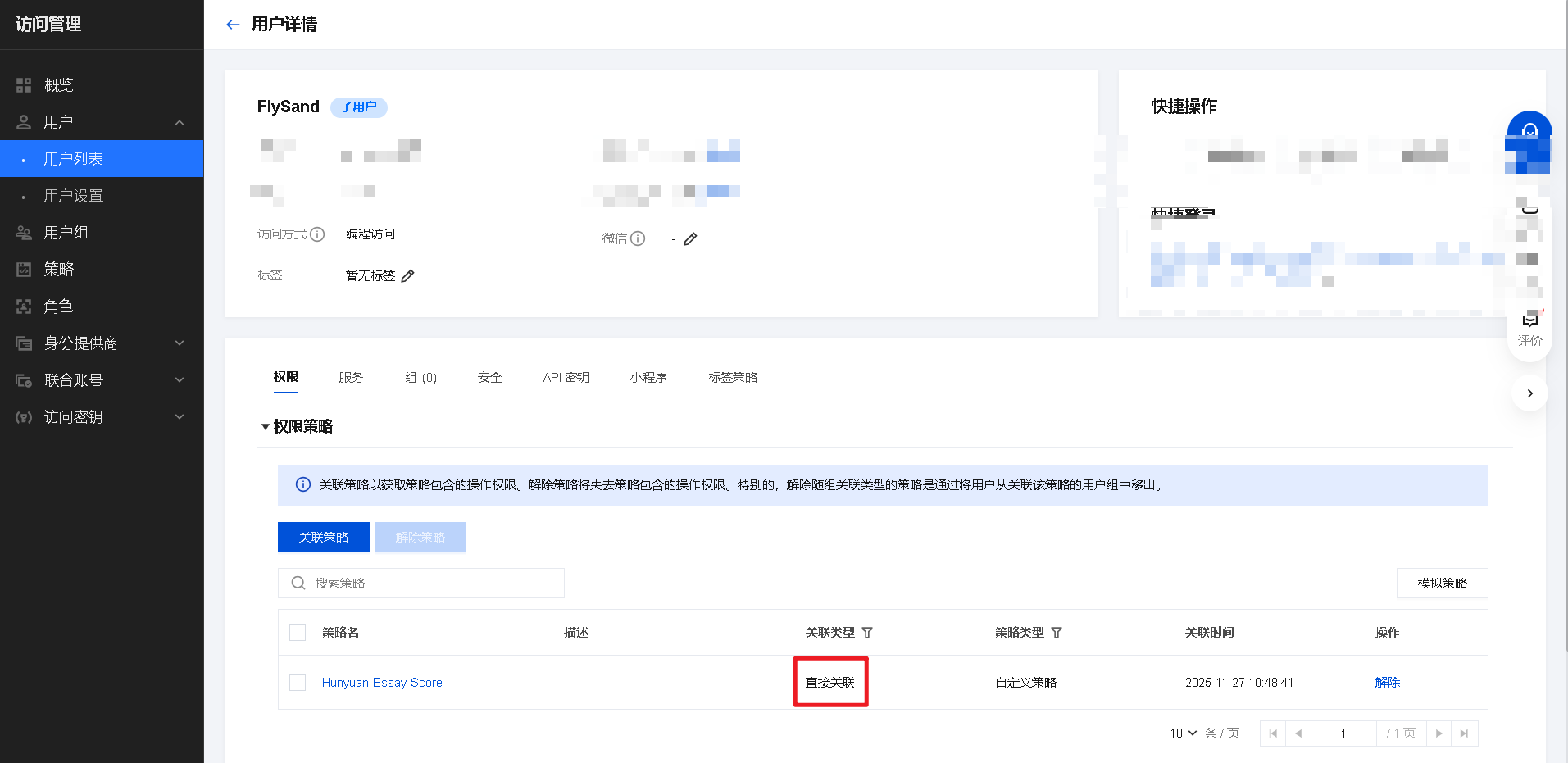
-
确认云函数的「执行环境」是Node.js 16+(在云函数配置中查看)。操作步骤:【云函数】-【版本与配置】-【配置】

-
重新上传最新的云函数,清除缓存,刷新。
参考网站(官方权威文档)
- 混元大模型
ChatCompletions接口文档(你的作文评分核心接口):https://cloud.tencent.com/document/api/1464/61951 - 腾讯云Node.js SDK使用文档:https://cloud.tencent.com/document/sdk/Nodejs
- 访问管理(CAM)子账号创建文档:https://cloud.tencent.com/document/product/598/13674
- 混元大模型开通指南:https://cloud.tencent.com/document/product/1729/101834
6.3 富文本
官方参考文档:https://developers.weixin.qq.com/miniprogram/dev/component/rich-text.html
rich-text是微信小程序中的核心组件,主要用于渲染富文本内容(包含HTML标签、自定义节点的文本),解决普通text组件仅能展示纯文本、无法处理带格式文本的问题。
核心功能:
- 解析HTML/自定义节点:支持渲染
<div>``<p>``<img>``<span>等常见HTML标签,以及<node>自定义节点,可直接展示从后端获取的富文本数据(如带格式的文章、商品详情、答题解析等); - 样式兼容与自定义:能通过
nodes属性传入结构化数据(数组/HTML字符串),并支持对标签设置自定义样式(如字体、颜色、图片大小),适配小程序的样式规则; - 安全过滤:默认会过滤危险标签/属性(如
<script>),避免XSS攻击,也可通过nodes手动控制渲染内容,保证安全性。
典型场景:
展示带格式的答题解析、作文评语、新闻资讯等包含多类样式/标签的文本内容。
6.4 Markdown语法
微信小程序解析Markdown核心依赖「mp-html」组件(支持Markdown渲染+富文本解析,是小程序生态中最成熟的方案),以下是标准化操作步骤:
步骤一:安装Markdown解析组件(mp-html)
mp-html 内置Markdown解析能力,无需额外写解析逻辑,先完成安装和构建:
- 打开项目终端:在微信开发者工具中,点击「终端」→「新建终端」(或直接打开项目根目录的系统终端);
- 安装mp-html包:执行npm安装命令,将组件安装到项目中:
npm install mp-html --save - 构建小程序npm包:小程序无法直接识别原生npm包,需构建适配包:
- 在开发者工具顶部菜单中,点击「工具」→「构建npm」;
- 等待构建完成,项目根目录会生成
miniprogram_npm文件夹(mp-html组件会被打包到该目录); - 确认「详情」→「本地设置」中已勾选「使用npm模块」(默认勾选,若未勾选需手动开启)。
步骤二:配置组件引用(全局/页面级)
将mp-html组件注册到小程序中,支持全局注册(所有页面可用)或页面级注册(仅当前页面可用):
方式1:全局注册(推荐,所有页面通用)
打开项目根目录的 app.json,在 usingComponents 中添加组件路径:
{
"pages": [...], // 原有页面配置
"usingComponents": {
"mp-html": "miniprogram_npm/mp-html" // 核心:配置mp-html组件路径
}
}
方式2:页面级注册(仅单个页面使用)
若仅个别页面需要解析Markdown,打开目标页面的 xxx.json(如 pages/markdown/markdown.json):
{
"usingComponents": {
"mp-html": "miniprogram_npm/mp-html"
}
}
步骤三:在页面中渲染Markdown内容
完成组件配置后,在WXML/JS中传入Markdown文本,实现解析渲染:
- WXML中引用组件:添加mp-html标签,绑定Markdown内容:
<!-- pages/markdown/markdown.wxml --> <view class="markdown-container"> <!-- content 属性传入Markdown文本 --> <mp-html content="{{markdownContent}}" type="markdown" <!-- 明确指定解析类型为Markdown --> lazy-load="{{false}}" <!-- 关闭懒加载,确保内容即时渲染 --> /> </view> - JS中定义Markdown内容:在页面JS中设置需要解析的Markdown文本(可来自接口/本地):
// pages/markdown/markdown.js Page({ data: { // 示例Markdown内容(可替换为接口返回的Markdown文本) markdownContent: `
作文评分规则
一、评分维度
- 内容契合度(40%):核心观点明确得满分
- 语法准确性(20%):无拼写错误得满分
二、分数档位
| 档位 | 分数 |
|---|---|
| 优秀 | 9-10分 |
| 良好 | 7-8分 |
`
},
onLoad(options) {
// 若Markdown内容来自云函数/接口,可在此请求并赋值
// wx.cloud.callFunction({
// name: 'getMarkdown',
// success: (res) => {
// this.setData({ markdownContent: res.result.content });
// }
// });
}
});
3. **可选:样式优化**:添加自定义样式,适配Markdown渲染后的排版:
```css
/* pages/markdown/markdown.wxss */
.markdown-container {
padding: 20rpx;
font-size: 28rpx;
line-height: 1.6;
}
/* 覆盖mp-html默认样式,如标题、列表 */
.mp-html h1 {
font-size: 36rpx;
color: #333;
margin: 20rpx 0;
}
.mp-html ul li {
margin: 10rpx 0;
list-style: disc;
margin-left: 30rpx;
}
关键补充说明
- 特殊内容处理:若Markdown文本包含小程序不支持的标签(如
<iframe>),mp-html会自动过滤,可通过tag-style属性自定义标签样式; - 动态更新内容:若Markdown内容需动态修改(如切换不同规则),直接通过
this.setData({ markdownContent: 新内容 })即可重新渲染; - 兼容性:mp-html支持小程序基础库≥2.8.3,若需兼容更低版本,可在「详情」→「本地设置」中调整基础库版本。
6.5 云开发省钱秘诀
要解决“减少调用次数”的问题,首先明确1次调用次数的计算规则,再针对性优化:
一、“1次调用次数”的计算规则(以微信小程序云服务为例)
结合你提供的“云数据库调用次数计算规则”(每执行1次数据库请求,计为1次调用),微信小程序云数据库中,所有发起服务器请求的操作函数都会消耗调用次数,具体包含以下类别:
一、查询类操作(发起“读取数据”请求)
这类操作是向云服务器请求读取数据,无论操作多少条数据,一次请求计1次调用:
get():
包括单条查询(如where({_id: 'xxx'}).get())、多条查询(如where({type: 1}).get()),或结合orderBy/limit/skip/field等链式条件后的get(),整个查询最终执行get()时算1次调用。count():
统计集合/查询结果的文档数量(如你之前的collection('ShoppingEvaluation').count()),执行count()会发起1次统计请求,算1次调用。aggregate().end():
执行聚合查询(如aggregate().match({score: 100}).group({_id: '$type', total: {$sum: 1}}).end()),end()是聚合请求的最终执行函数,算1次调用。
二、写入/修改类操作(发起“写数据”请求)
这类操作是向云服务器提交数据修改,无论操作单条/多条文档,一次请求计1次调用:
add():
添加文档(包括单文档add({data: {...}})、多文档add([{data: {...}}, {data: {...}}])),执行add()算1次调用。update():
更新文档(如where({_id: 'xxx'}).update({data: {...}}),或批量更新where({type: 1}).update({data: {...}})),执行update()算1次调用。remove():
删除文档(如where({_id: 'xxx'}).remove()、批量删除where({status: 0}).remove()),执行remove()算1次调用。set():
替换/新增文档(若文档存在则替换内容,不存在则新增),如doc('xxx').set({data: {...}}),执行set()算1次调用。
三、事务类操作(发起“事务请求”)
通过 runTransaction 执行事务(事务内可包含多个读写操作),整个事务是1次服务器请求,计1次调用:
await wx.cloud.database().runTransaction(async (transaction) => {
// 事务内的多次操作(如get/update)
const doc = await transaction.collection('xxx').doc('yyy').get();
await transaction.collection('xxx').doc('yyy').update({data: {...}});
});
// 整个runTransaction算1次调用
注意:不会消耗调用次数的情况
只有“构建查询条件的链式方法”(未发起实际请求)不会消耗次数,比如:
where({type: 1})(仅构建查询条件,未请求数据)orderBy('createTime', 'desc')(仅排序,未请求数据)limit(10)(仅限制数量,未请求数据)
这些方法只是“组装请求参数”,只有最终执行 get/count/add/update/remove/end/runTransaction 等发起服务器请求的函数时,才会消耗1次调用次数。
二、减少调用次数的核心方法(结合你的题目类小程序场景)
1. 合并请求:把“多次调用”改成“1次调用”
- 云函数合并:原本需多次调用云函数获取不同数据(比如“获取题目列表+获取用户答题记录”),改为1次云函数调用,在函数内完成多逻辑处理后返回所有数据;
- 数据库批量查询:比如要查多个题目,用
in条件1次查询(db.collection('questions').where({question_id: {$in: [1,2,3]}}).get()),替代多次单条查询。
2. 本地缓存:复用已有数据,避免重复调用
- 用小程序本地缓存(
wx.setStorageSync/wx.getStorageSync)存储不常变化的数据(比如题目分类、章节列表),仅首次加载时调用接口,后续直接读缓存(定期更新缓存即可); - 示例:用户打开“入党题目”页面,首次调用接口获取题目后缓存,1小时内再次打开页面直接读缓存。
3. 优化业务逻辑:避免冗余/重复调用
- 防抖/节流:用户操作触发的请求(比如搜索框输入),加“防抖”(输入停止后延迟0.5秒再调用),避免每输入1个字符就触发1次调用;
- 懒加载:页面中隐藏的模块(比如“答案解析”),等用户点击“查看解析”时再调用接口,而非页面加载时就请求。
4. 前端处理:减少不必要的云服务调用
- 前端能完成的逻辑(比如数据格式化、简单的条件筛选),直接在小程序前端处理,不用放到云函数中执行;
- 示例:题目列表的排序(按章节排序),前端拿到全量数据后本地排序,替代“调用云函数排序后返回”。
一、这4个参数的含义(以微信小程序云服务为例)
这是云服务的核心资源消耗指标,对应不同的资源类型:
- 本月容量:指云存储的存储空间占用(比如你上传的图片、文件等资源的总大小),当前用了3MB,配额是3GB。
- 本月调用次数:指云服务接口的请求次数(包括云函数调用、云数据库操作、云存储操作等),当前用了14万次,配额20万次/月。
- 本月CDN流量:指通过CDN(内容分发网络)传输资源产生的流量(比如用户访问你小程序里的图片、文件时,通过CDN加速下载的流量),当前用了3KB,配额10GB/月。
- 本月云函数资源使用量:指云函数执行消耗的资源总量(单位是GBs,即“内存规格×执行时长”,比如1GB内存的函数运行1秒,消耗1GBs),当前用了155GBs,配额15万GBs/月。
二、节约成本的对应方法
每个参数对应不同的优化方向,按需调整即可降低资源消耗:
1. 节约「本月容量」(云存储空间)
- 清理冗余资源:删除小程序中未使用的旧文件(比如测试用的图片、过期的题目附件);
- 压缩资源体积:图片用
TinyPNG等工具压缩后再上传,文档类文件转PDF格式(比Word更小); - 减少重复存储:相同的资源(比如通用的章节封面图)只存1份,避免重复上传。
2. 节约「本月调用次数」
- 合并请求:把多个云函数/数据库请求合并为1次(比如“获取题目+用户答题记录”用1个云函数完成);
- 本地缓存:常用且不常变的数据(比如章节列表)存在小程序本地缓存(
wx.setStorageSync),避免重复调用接口; - 防抖节流:用户操作(比如搜索输入)加“防抖”(输入停止0.5秒后再调用接口),避免频繁触发请求。
3. 节约「本月CDN流量」
- 按需开启CDN:仅将高频访问的静态资源(比如首页 banner)放到CDN,低频资源(比如冷门题目图片)直接走云存储访问;
- 优化资源缓存:给CDN资源设置较长的缓存时间(比如静态图片缓存7天),用户重复访问时直接用本地缓存,无需重新下载;
- 压缩传输资源:同“本月容量”的资源压缩逻辑,减少传输时的流量消耗。
4. 节约「本月云函数资源使用量」
- 优化函数逻辑:删除云函数内的冗余代码、减少不必要的循环/计算,缩短函数执行时间;
- 数据库加索引:给云数据库的查询字段(比如
question_id)加索引,减少云函数等待数据库查询的时间; - 降低函数配置:非高负载的云函数,选择较小的内存规格(比如从2GB内存改为1GB),内存越小,GBs的消耗速度越慢。
6.6 微信开发者工具查看 本地数据
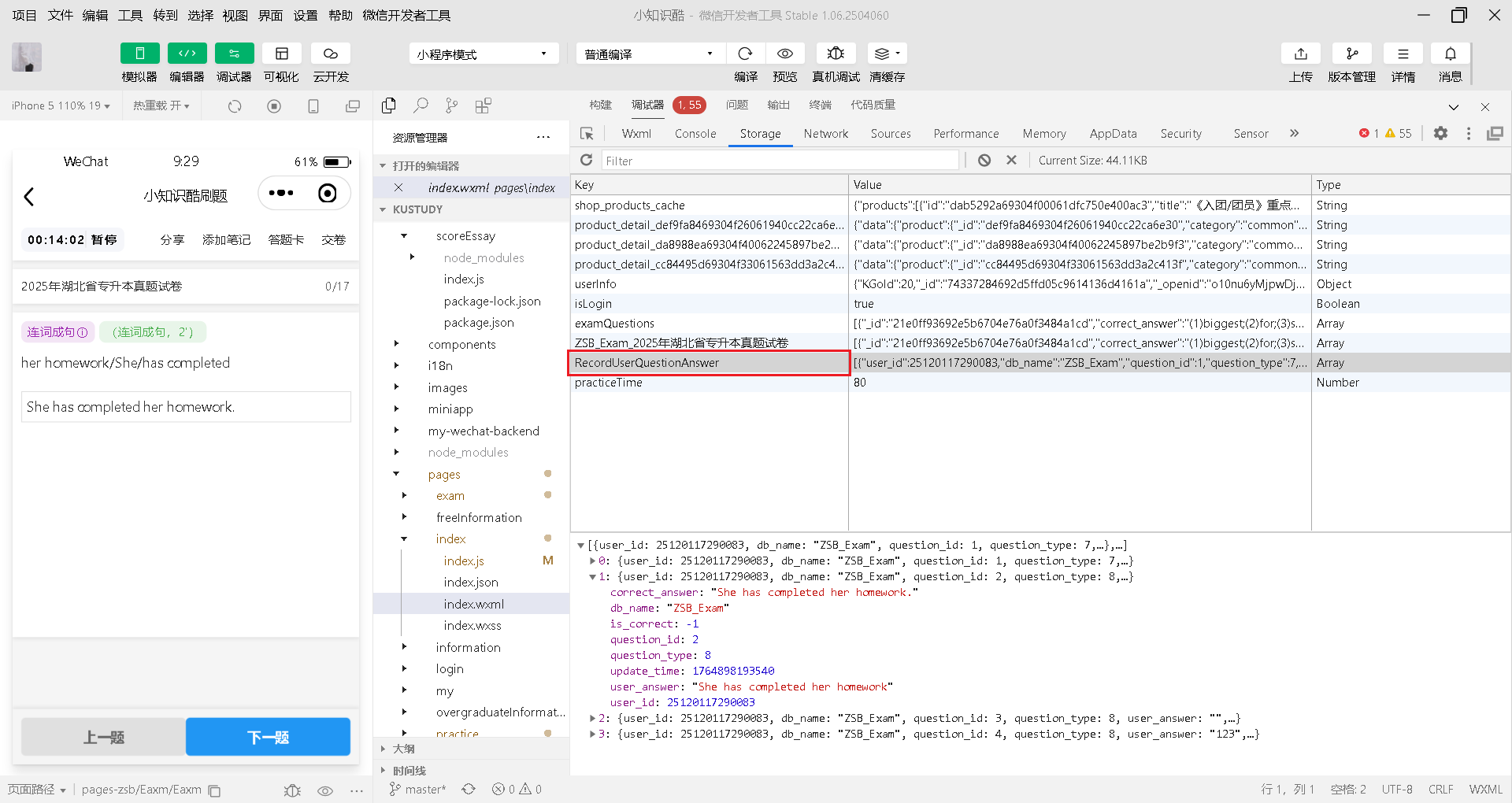
在微信小程序中,本地数据主要分为 本地缓存(Storage) 和 页面/组件的运行时数据(AppData),可通过微信开发者工具快速查看:
一、查看「本地缓存(Storage)」(持久化存储的数据)
本地缓存是通过 wx.setStorageSync/wx.setStorage 存储的持久化数据(关闭小程序后仍保留),查看步骤:
-
打开微信开发者工具,进入你的小程序项目;
-
点击顶部菜单栏的 “Storage”面板(在Console、Sources等面板旁边);
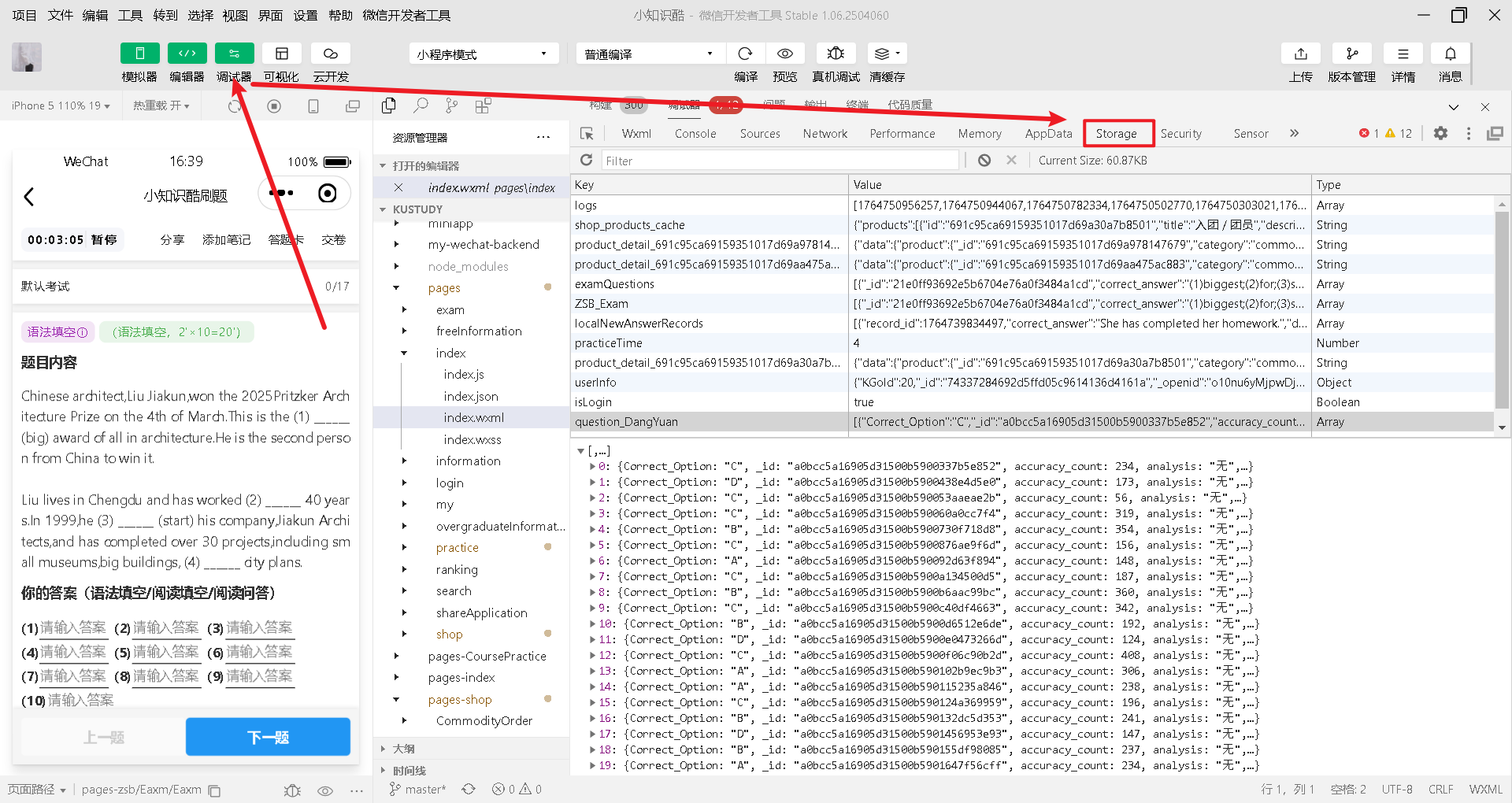
-
面板中会显示当前小程序存储的所有键(key)和值(value),可直接查看、编辑或删除。
-
刷新数据:点击其他数据,再点击你需要的数据进行查看。
二、查看「页面/组件的运行时数据(AppData)」(临时运行数据)
AppData是页面/组件 data 中存储的临时数据(页面销毁后消失),查看步骤:
-
在开发者工具中运行小程序,进入目标页面;
-
点击顶部菜单栏的 “AppData”面板;
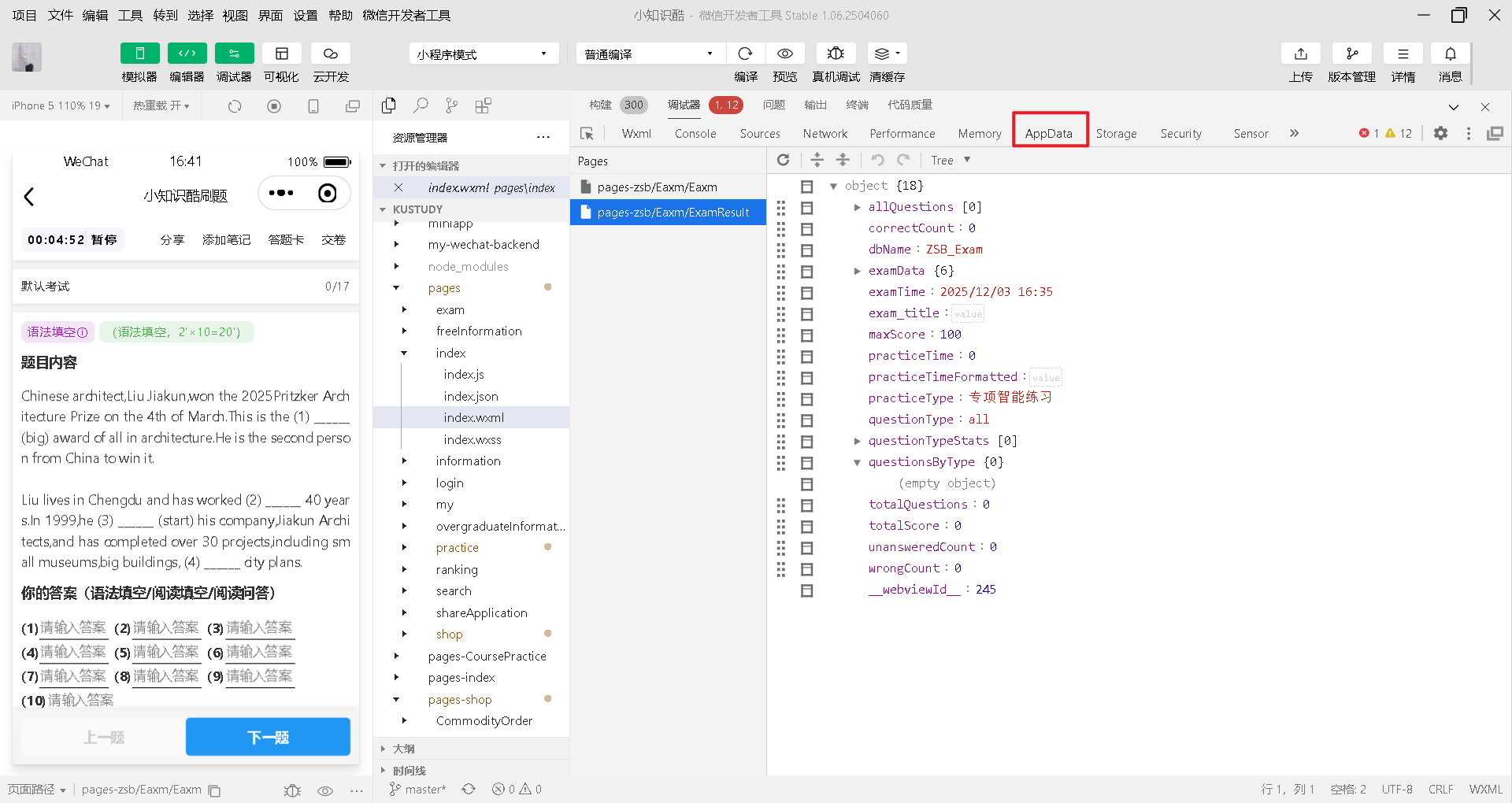
-
面板中会展示当前页面(或选中的组件)的
data数据,实时同步页面数据的变化(比如页面this.setData后会立即更新)。
补充:真机调试时查看本地数据
若需在真机上查看,可开启真机调试:
- 开发者工具中点击「真机调试」按钮,用手机微信扫码连接;
- 连接成功后,开发者工具的
Storage/AppData面板会同步显示真机上的本地数据。
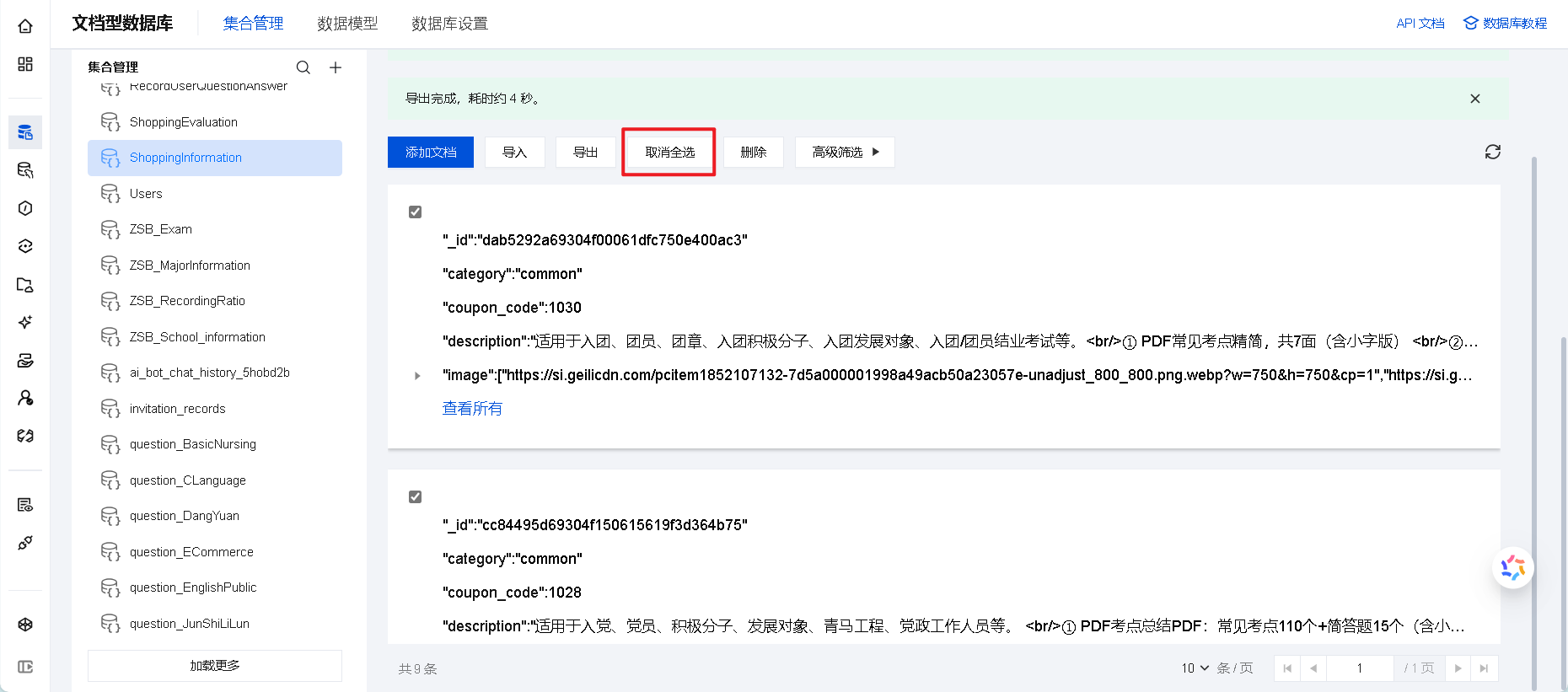
6.7 数据导出和导入
1、选择需要导出的数据,点击【导出】
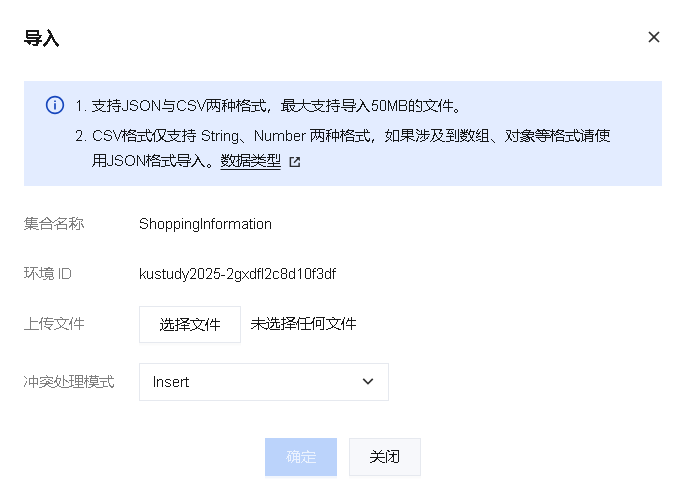
2、查看导出文件

3、导入json:【导入数据】-【选择json文件】,注意:JSON文件格式如上图
08 深拷贝和浅拷贝
深拷贝和浅拷贝是编程语言中处理对象/数据复制时的两种方式,核心区别在于是否对嵌套的引用类型数据进行彻底复制。以下从作用和区别两方面详细说明:
一、核心作用
两者的根本目的都是创建一个原数据的副本,避免对副本的修改直接影响原数据(或反之),本质是解决“引用类型数据共享内存地址”导致的联动修改问题。
二、核心区别(以“嵌套对象”为例)
假设存在一个嵌套结构的对象(包含基本类型和引用类型):
const obj = {
name: "张三", // 基本类型(字符串)
info: { age: 20 } // 引用类型(嵌套对象)
};
1. 浅拷贝(Shallow Copy)
-
复制规则:只复制对象的“表层结构”——
- 对于基本类型属性(如字符串、数字):直接复制值,原数据和副本的基本类型属性相互独立;
- 对于引用类型属性(如嵌套对象、数组):只复制引用地址(即副本的引用类型属性与原数据指向同一块内存)。
-
示例(JavaScript中
Object.assign()、扩展运算符...都是浅拷贝):const shallowCopy = { ...obj }; // 浅拷贝obj // 修改副本的基本类型属性:不影响原数据 shallowCopy.name = "李四"; console.log(obj.name); // 仍为"张三" // 修改副本的引用类型属性:原数据会被同步修改(因为共享内存) shallowCopy.info.age = 30; console.log(obj.info.age); // 变为30(被影响了) -
特点:
- 效率高(只复制表层,不递归处理嵌套);
- 不彻底:嵌套的引用类型数据仍会“联动修改”。
2. 深拷贝(Deep Copy)
-
复制规则:递归复制对象的“所有层级”——
无论基本类型还是引用类型,都会创建全新的副本,原数据和副本的所有属性(包括嵌套的引用类型)都指向不同的内存地址,完全独立。 -
示例(JavaScript中可通过
JSON.parse(JSON.stringify())或递归函数实现):const deepCopy = JSON.parse(JSON.stringify(obj)); // 深拷贝obj // 修改副本的引用类型属性:原数据不受影响 deepCopy.info.age = 30; console.log(obj.info.age); // 仍为20(未被影响) -
特点:
- 彻底独立:原数据和副本无任何关联,修改互不影响;
- 效率较低(需要递归处理所有嵌套层级,消耗更多资源)。
三、总结对比表
| 维度 | 浅拷贝 | 深拷贝 |
|---|---|---|
| 复制范围 | 仅表层结构(基本类型复制值,引用类型复制地址) | 所有层级(递归复制,包括嵌套的引用类型) |
| 独立性 | 嵌套引用类型仍共享内存,会联动修改 | 完全独立,修改互不影响 |
| 效率 | 高(无需递归) | 低(递归处理,消耗更多资源) |
| 适用场景 | 数据结构简单(无嵌套引用类型)或无需独立修改嵌套内容 | 数据结构复杂(有多层嵌套引用类型),需要完全独立的副本 |
简单说:浅拷贝是“表面复制”,深拷贝是“彻底复制”,选择哪种取决于是否需要嵌套数据完全独立。
6.8 bindblur和bindinput的区别
在微信小程序中,bindblur 和 bindinput 是表单元素(如 input、textarea 等)常用的事件绑定,核心区别在于触发时机和适用场景,具体如下:
一、触发时机
-
bindinput:实时触发(内容变化时)
当输入框的内容发生改变时立即触发(比如用户每输入/删除一个字符、粘贴内容等),触发频率与内容变化频率一致。例:用户在输入框中输入“abc”,会触发3次
bindinput(输入“a”时1次,“b”时1次,“c”时1次)。 -
bindblur:失焦时触发(结束输入时)
当输入框从“被选中状态”变为“未选中状态”(即失去焦点)时触发,通常是用户完成输入后点击其他区域(如空白处、按钮)导致输入框失去焦点时触发,仅触发1次。例:用户输入完内容后,点击页面其他地方,输入框失去焦点,此时触发
bindblur。
二、适用场景
-
bindinput:需要实时响应输入的场景
用于实时处理输入内容,比如:- 实时显示输入字数统计(如“已输入5/20字”);
- 实时验证输入格式(如实时提示“手机号格式错误”);
- 实时搜索联想(输入时实时显示匹配的搜索结果)。
代码示例(实时显示输入内容):
<input bindinput="handleInput" placeholder="请输入内容" />Page({ handleInput(e) { // e.detail.value 是实时输入的内容 console.log("当前输入:", e.detail.value); } }) -
bindblur:需要在输入完成后处理的场景
用于输入结束后统一处理,比如:- 输入完成后的最终验证(如提交前检查“密码是否符合规则”);
- 输入完成后自动提交(如失去焦点后保存内容);
- 隐藏输入相关的临时提示(如输入时显示的“正在输入...”提示,失焦后隐藏)。
代码示例(失焦后验证输入):
<input bindblur="handleBlur" placeholder="请输入手机号" />Page({ handleBlur(e) { const phone = e.detail.value; // 失焦后验证手机号格式 if (!/^1[3-9]\d{9}$/.test(phone)) { wx.showToast({ title: "手机号格式错误", icon: "none" }); } } })
三、核心区别总结
| 维度 | bindinput |
bindblur |
|---|---|---|
| 触发时机 | 输入内容实时变化时触发 | 输入框失去焦点时触发 |
| 触发频率 | 随内容变化多次触发 | 输入结束后仅触发1次 |
| 核心用途 | 实时响应、实时处理输入内容 | 输入完成后统一验证/提交 |
简单说:bindinput 管“输入过程中”的实时交互,bindblur 管“输入结束后”的最终处理。
6.9 函数注释
微信小程序JS函数的注释需兼顾可读性、规范性和团队协作,核心采用「JSDoc 规范注释」(工业级标准,编辑器可智能提示),辅以单行/多行注释。以下是完整的注释说明、规范及贴合你场景的示例:
一、核心注释类型
| 注释类型 | 语法格式 | 适用场景 | 特点 |
|---|---|---|---|
| 单行注释 | // 注释内容 |
临时说明、行内注释、简单逻辑标注 | 简洁,仅单行,适合短文本 |
| 多行注释 | /* 注释内容 */ |
块级逻辑说明、临时屏蔽代码 | 支持多行,无结构化标签,不推荐函数说明 |
| JSDoc 规范注释 | /** 注释内容 */ |
函数/方法的详细说明(首选) | 支持参数、返回值、异步等结构化标签 |
二、JSDoc 核心标签(函数注释必用)
| 标签 | 作用 | 示例 |
|---|---|---|
@description |
函数核心功能描述 | @description: 交卷后触发AI作文评分 |
@param |
入参说明(类型+名称+含义+是否必传) | @param {String} essayContent - 作文内容(必传) |
@returns |
返回值说明(类型+结构+含义) | @returns {Promise<Object>} 评分结果 |
@async |
标记异步函数(含async/await) | @async |
@throws |
异常场景说明 | @throws {Error} AI调用超时抛出异常 |
@example |
函数调用示例 | @example handleSubmitExam('我的作文') |
@todo |
待优化/待完成事项 | @todo 增加评分缓存逻辑 |
三、不同场景的函数注释示例(贴合你的作文评分场景)
1. 页面(Page)中的函数注释
(1)生命周期函数注释(onLoad/onShow)
Page({
/**
* @description: 页面加载时执行,初始化作文评分相关数据
* @param {Object} options - 页面跳转参数
* @param {String} options.examId - 考试ID(可选)
* @param {String} options.essayId - 作文ID(可选)
* @returns {void} 无返回值
*/
onLoad(options) {
this.setData({
examId: options.examId || '',
essayContent: '',
isScoring: false
});
},
/**
* @async
* @description: 交卷按钮点击事件,触发AI作文评分(异步)
* @param {Object} e - 点击事件对象(无实际入参,仅占位)
* @returns {Promise<void>} 无返回值
* @throws {Error} AI调用超时/失败、参数缺失时抛出异常
* @todo 增加重复点击防重逻辑
*/
async handleSubmitExam(e) {
try {
const { essayContent } = this.data;
if (!essayContent) throw new Error('作文内容不能为空');
wx.showLoading({ title: '发起评分...', mask: true });
// 调用触发评分云函数
const res = await wx.cloud.callFunction({
name: 'essayScoreTrigger',
data: { essayContent, openid: wx.getStorageSync('openid') }
});
// 轮询评分结果
this.pollScoreResult(res.result.taskId);
} catch (err) {
wx.showToast({ title: err.message, icon: 'none' });
} finally {
wx.hideLoading();
}
},
/**
* @async
* @description: 轮询查询AI评分结果
* @param {String} taskId - 评分任务ID(必传)
* @param {Number} retryCount - 已重试次数(默认0)
* @returns {Promise<void>} 无返回值
* @example pollScoreResult('xxx123', 0)
*/
async pollScoreResult(taskId, retryCount = 0) {
const maxRetry = 15; // 最多轮询30秒(2秒/次)
if (retryCount >= maxRetry) {
wx.showToast({ title: '评分超时', icon: 'none' });
return;
}
const res = await wx.cloud.callFunction({
name: 'essayScoreQuery',
data: { taskId }
});
if (res.result.status === 'finished') {
// 跳转结果页
wx.navigateTo({
url: `/pages-zsb/Eaxm/ExamResult?score=${res.result.score}`
});
} else {
// 2秒后继续轮询
setTimeout(() => this.pollScoreResult(taskId, retryCount + 1), 2000);
}
}
});
2. 云函数中的函数注释
// cloudfunctions/essayScoreTrigger/index.js
const cloud = require('wx-server-sdk');
cloud.init();
const db = cloud.database();
/**
* @description: 通用工具函数:校验作文内容参数合法性
* @param {String} content - 作文内容
* @returns {Boolean} 校验通过返回true,失败抛出异常
* @throws {Error} 内容为空/超过5000字时抛出异常
*/
function validateEssayContent(content) {
if (!content || content.trim() === '') {
throw new Error('作文内容不能为空');
}
if (content.length > 5000) {
throw new Error('作文内容超过5000字上限');
}
return true;
}
/**
* @async
* @description: 云函数唯一入口:触发AI作文评分任务(不等待结果)
* @param {Object} event - 前端传入参数
* @param {String} event.essayContent - 作文内容(必传)
* @param {String} event.openid - 用户OpenID(必传)
* @param {String} [event.examId] - 考试ID(可选)
* @param {Object} context - 云函数上下文(无需前端传参)
* @returns {Promise<Object>} 触发结果
* @returns {Number} return.code - 0成功/-1失败
* @returns {String} return.taskId - 评分任务ID(成功时返回)
* @returns {String} [return.errMsg] - 失败原因(失败时返回)
*/
exports.main = async (event, context) => {
try {
// 校验参数
validateEssayContent(event.essayContent);
// 生成任务ID
const taskId = db.collection('essayScoreTasks').doc().id;
// 存入数据库
await db.collection('essayScoreTasks').doc(taskId).set({
data: {
taskId,
essayContent: event.essayContent,
openid: event.openid,
examId: event.examId || '',
status: 'processing',
createTime: db.serverDate()
}
});
// 异步调用AI(不await)
(async () => {
const aiResult = await callTraeAI(event.essayContent);
await db.collection('essayScoreTasks').doc(taskId).update({
data: { status: 'finished', score: aiResult.score }
});
})();
return { code: 0, taskId };
} catch (err) {
return { code: -1, errMsg: err.message };
}
};
3. 组件(Component)中的方法注释
Component({
properties: {
// 作文得分
essayScore: {
type: Number,
value: 0
}
},
methods: {
/**
* @description: 组件内方法:展示作文评分详情弹窗
* @param {Number} score - 作文得分
* @param {String} evaluation - 作文评价
* @returns {void} 无返回值
*/
showScoreDetail(score, evaluation) {
this.setData({
showDetailModal: true,
currentScore: score,
currentEvaluation: evaluation
});
}
}
});
四、注释规范与最佳实践
- 优先用JSDoc:业务函数、云函数、组件方法必须用JSDoc注释,单行注释仅用于临时说明;
- 参数/返回值要精准:
- 标注参数类型(
String/Number/Object/Array/Promise); - 必传参数标注「必传」,可选参数用
[参数名]; - 返回值若为对象,拆解字段说明(如
return.code);
- 标注参数类型(
- 异步函数必标@async:明确告知调用方该函数是异步(返回Promise);
- 异常场景要标注:用
@throws说明函数可能抛出的异常,方便调用方做错误处理; - 注释与代码同步:代码逻辑修改后,必须更新注释(避免注释与代码矛盾);
- 避免冗余注释:无需注释“点击按钮触发事件”这类显而易见的逻辑,重点注释「业务逻辑、参数规则、异常场景」;
- 统一风格:团队内保持注释格式一致(如参数说明用「-」分隔,返回值拆解清晰)。
总结
小程序JS函数注释的核心是「JSDoc规范」,通过结构化标签清晰说明函数的功能、参数、返回值、异常等信息,既方便自己维护,也能让团队成员快速理解代码;单行/多行注释仅作为补充,用于简单说明或临时标注。结合你的作文评分场景,重点注释异步函数、云函数入口、参数校验逻辑,能大幅提升代码的可维护性。
6.10 内容机制
这个界面是微信小程序开发者工具的性能监控面板,这里的「Memory」是内存占用的监控指标,对应小程序运行过程中不同进程的内存资源消耗,核心作用是帮助开发者监控、优化小程序的性能与稳定性,具体说明如下:
一、先理解截图中「Memory」的对应对象
小程序采用「逻辑层(App Service)+ 渲染层(Webview)」的双线程架构,截图中不同模块的「Memory」对应不同线程的内存占用:
- App Service 的 Memory(137.15M):对应小程序逻辑层进程的内存占用(逻辑层负责运行 JS 代码、处理数据、调用接口等);
- Webview: pages/shop/shop 的 Memory(81.9M):对应「shop 页面」渲染层进程的内存占用(渲染层负责页面渲染、DOM 操作、样式渲染等);
- 同理,
Webview: pages/index/index的 Memory 是「index 页面」渲染层的内存占用。
二、「Memory」的核心作用
在小程序开发中,监控「Memory」的核心目的是保障小程序的运行性能与稳定性,具体作用包括:
-
反映资源消耗程度
内存是程序运行的核心资源之一,小程序的代码执行、数据存储(比如globalData、页面data)、页面渲染都需要占用内存。「Memory」数值直接体现当前小程序消耗了多少系统内存。 -
预警性能风险
- 若「Memory」数值过高(比如超过 500M),可能导致小程序卡顿、响应变慢(系统分配给小程序的内存有限,占用过高会挤压其他进程资源);
- 若内存持续增长且无法回落,可能触发系统的「内存回收机制」,导致小程序闪退、崩溃(尤其是在内存较小的低端设备上)。
-
排查性能/稳定性问题
- 若发现「Memory」持续上升(比如切换页面后,前一个页面的内存未下降),通常是内存泄漏(比如未销毁的定时器、未解绑的事件监听、冗余的全局数据等),需要针对性优化;
- 若某个页面的 Webview 内存异常高(比如单页面内存超过 200M),可能是页面包含大量图片、复杂 DOM 结构,需要优化资源/页面结构。
简单来说,「Memory」是小程序运行状态的“健康指标”之一——通过监控它,能及时发现内存相关的性能问题,避免小程序出现卡顿、闪退等影响用户体验的情况。
6.11 设计原则
结合你提出的“无轮播、单按钮、数据分层存储”核心设计思路,从用户体验、数据管理、交互逻辑、性能优化、合规性等维度,为你的专升本刷题小程序补充以下设计要点,既保持简洁性,又能提升实用性和稳定性:
一、交互反馈:单按钮操作的“确定性”补充
单按钮是核心设计,但用户点击后若无反馈,易产生“是否操作成功”的疑惑,需补充:
- 操作即时反馈
- 点击按钮后添加加载动效(如转圈图标),避免用户重复点击;
- 操作成功/失败时给出轻提示(如“进入刷题成功”“网络异常,请重试”),而非静默处理。
- 按钮视觉强化
- 按钮采用高对比度配色(如专升本主题的蓝色/橙色,避免浅灰等低辨识度颜色),尺寸占屏幕宽度70%以上,位置固定在页面中下(拇指易触达区);
- 按钮文案用动词+目标的简洁表述(如“开始刷题”“继续刷题”,而非模糊的“进入”“点击”)。
二、数据管理:分层存储的“细节优化”
你提到“个性化内容存云库、固定内容存缓存”,需补充具体的存储策略,避免数据异常:
- 缓存的“更新与兜底”
- 题库缓存添加版本号机制:当后台题库更新时,小程序检测版本号差异,自动刷新缓存(避免用户看到旧题);
- 缓存失效兜底:若缓存读取失败(如清理缓存后),自动从云数据库重新拉取题库,并再次存入缓存。
- 个性化数据的“增量同步”
- 刷题记录不每次全量上传,而是增量同步(仅上传本次新增的答题记录),减少云数据库调用次数和数据传输量;
- 关键节点同步:比如用户完成一套题、退出刷题页面时触发同步,而非每答一题就同步(避免频繁调用)。
- 个性化数据的“备份与恢复”
- 云数据库中为用户刷题记录添加时间戳和版本标识,支持用户“恢复到某一时间段的刷题记录”(比如误删记录时可回溯);
- 设备切换时(如从微信切换到微信分身),自动从云库拉取历史数据,覆盖本地缓存,保证数据一致。
三、页面设计:无轮播后的“空间利用”
去掉轮播图后,首页需简洁但不空洞,同时突出核心功能:
- 核心信息轻量展示
- 首页仅保留用户基础信息(如昵称、已刷题目数)+单功能按钮,其余信息(如刷题统计、题库分类)放在二级页面;
- 避免冗余元素(如广告位、无关图标),保持页面留白,降低视觉干扰。
- 自适应布局适配
- 按钮和文字大小适配不同屏幕尺寸(如用
rpx单位),避免小屏手机按钮被截断、大屏手机按钮过小; - 针对老年用户/低视力用户,支持字体大小调整(二级页面添加“字体设置”),兼顾易用性。
- 按钮和文字大小适配不同屏幕尺寸(如用
四、异常处理:避免用户操作“卡壳”
小程序运行中可能出现网络、数据异常,需补充容错设计:
- 离线操作支持
- 断网时,用户的刷题记录先存入本地缓存,联网后自动同步到云数据库(避免断网导致记录丢失);
- 网络异常时,给出“离线模式,数据将在联网后同步”的提示,而非直接报错。
- 数据校验机制
- 同步个性化数据到云库前,校验数据格式(如答题记录的题目ID、分数是否合法),避免脏数据入库;
- 云库读取失败时,用本地缓存的历史数据兜底(如“云端数据加载失败,显示本地历史记录”)。
五、合规与隐私:个性化数据的“安全保障”
涉及用户刷题记录等个人数据,需符合微信小程序隐私规范:
- 隐私政策与授权
- 首次进入小程序时,弹出隐私政策提示,用户同意后再获取/存储用户信息(如
user_id); - 云数据库中对用户数据做脱敏处理(如不存储用户手机号等敏感信息,仅保留必要的
user_id和刷题记录)。
- 首次进入小程序时,弹出隐私政策提示,用户同意后再获取/存储用户信息(如
- 数据删除权限
- 提供“删除个人刷题记录”的功能(符合《个人信息保护法》),用户可自主删除部分或全部记录,删除后云库和本地缓存同步清理。
六、运营与迭代:简洁性下的“拓展性”
单按钮设计不代表功能单一,可通过二级页面预留拓展空间,同时便于后续迭代:
- 功能入口的“隐藏式拓展”
- 首页保留单按钮作为核心入口,其他功能(如题库分类、刷题统计、个人设置)放在“我的”页面(点击头像/昵称进入),既保持首页简洁,又能承载更多功能。
- 用户行为埋点
- 在核心操作节点(如按钮点击、刷题完成、数据同步)添加简单埋点(如统计按钮点击率、各题库的刷题量),通过云开发统计分析用户行为,后续可根据数据优化功能(比如用户更爱刷高数题,就强化高数题库入口)。
总结
补充的设计要点均围绕你的核心需求(简洁、低调用、数据安全)展开,既不破坏“单按钮、无轮播”的简洁性,又能解决小程序运行中的数据异常、用户体验、合规性等问题,让小程序既易用又稳定。
如果需要,我可以为你梳理一份小程序首页布局的具体设计稿文字版,包含元素位置、尺寸、配色建议,方便你直接落地开发。
6.12 使用云函数和使用普通数据库请求的区别
在微信云开发中, 普通数据库请求(小程序端直接操作) 和 云函数(云端运行代码操作) 是两种核心数据交互方式,核心区别体现在权限、安全性、逻辑复杂度等维度,下面结合你的专升本小程序场景详细说明:
一、云函数 vs 普通数据库请求的核心区别
| 对比维度 | 普通数据库请求(小程序端直接操作) | 云函数(云端运行代码) |
|---|---|---|
| 权限范围 | 受小程序端数据库权限限制(默认:仅能读写「自己创建」的记录;需手动配置权限) | 默认拥有管理员权限(可读写所有集合的所有记录,无需额外配置) |
| 安全性 | 操作逻辑/请求参数暴露在小程序端(用户可篡改请求,比如恶意获取他人数据) | 逻辑代码运行在云端,用户无法查看/篡改,数据操作更安全 |
| 逻辑复杂度 | 仅支持简单的单集合CRUD(增删改查),无法处理多表联查、复杂计算 | 支持复杂业务逻辑(多集合联查、数据聚合、循环批量操作),还能调用第三方API |
| 请求次数消耗 | 小程序端每调用1次db接口,消耗1次云开发请求次数 |
小程序端调用1次云函数,无论云函数内执行多少数据库操作,仅消耗1次云函数请求次数(数据库操作不额外计次) |
| 性能 | 小程序端→云数据库,跨网络请求,速度受用户网络影响 | 云函数→云数据库(同机房),网络延迟低,数据库操作速度更快 |
| 开发成本 | 简单直接(小程序端写db.collection即可) |
需单独编写云函数代码、部署到云端,开发步骤稍多 |
二、哪些情况下必须/优先使用云函数?
结合你的专升本小程序场景,以下情况建议用云函数:
1. 需要高权限操作数据库的场景
小程序端默认权限有限(比如无法修改其他用户的刷题记录、无法删除全量题库数据),而云函数是管理员权限,适合:
- 统计全专业/全平台的排名(需要读取所有用户的成绩数据);
- 批量更新题库(比如后台更新所有题目内容,小程序端无权限操作他人创建的题库);
- 重置用户的刷题记录(比如管理员后台操作,小程序端无法修改其他用户数据)。
2. 需要复杂业务逻辑的场景
普通数据库请求仅支持简单CRUD,云函数可以处理多步骤/多集合的逻辑:
- 考生提交试卷后,自动计算总分+更新排名+生成错题集(需要同时操作「答题记录集合」「排名集合」「错题集合」3个集合);
- 多表联查(比如根据
user_id同时获取「用户信息」「刷题记录」「错题集」,合并数据后返回给小程序端)。
3. 需要隐藏敏感逻辑/数据的场景
小程序端代码是暴露的(用户可反编译看到请求参数),云函数逻辑在云端,适合:
- 处理考试成绩的排名规则(比如“总分相同则按专业课成绩排序”的逻辑,避免用户篡改排序规则);
- 调用第三方API(比如获取专升本院校的录取分数线,云函数中存储API密钥,避免密钥暴露在小程序端)。
4. 需要减少请求次数的场景
小程序端调用1次云函数,可在云函数内执行多个数据库操作,仅消耗1次请求次数:
- 批量同步1000条刷题记录(小程序端分10批调用批量
add需10次请求;云函数内循环批量add,小程序端仅调用1次云函数); - 考生登录时,同时获取“用户信息+已刷题目数+未完成试卷”(云函数内查3个集合,小程序端1次请求就能拿到所有数据)。
5. 需要定时/后台任务的场景
云函数支持定时触发(无需小程序端调用),适合:
- 每天凌晨自动统计昨日刷题数据,更新用户的周/月刷题报告;
- 考试结束后自动关闭答题入口(定时修改题库的“是否可答”状态)。
三、反例:哪些情况用普通数据库请求更合适?
简单、仅操作“用户自己的数据”的场景,用普通请求更高效:
- 考生查询自己的刷题记录;
- 考生提交自己的单题答案;
- 考生修改自己的昵称/头像。
总结(结合你的场景)
- 比如“考生查看自己的错题”:用普通数据库请求;
- 比如“管理员统计全专业排名”:用云函数;
- 比如“考生提交试卷后自动算分+更新排名”:用云函数。
需要我帮你写一个“考生提交试卷后,云函数自动计算总分并更新排名”的示例代码吗?
07 数据保存
7.1 wx.setStorageSync 是微信小程序中同步式本地存储API,用于将数据持久化到小程序本地缓存中,以下是其相关语法、参数、示例及注意事项:
一、基本语法
wx.setStorageSync(key, data)
二、参数说明
| 参数名 | 类型 | 必填 | 说明 |
|---|---|---|---|
key |
string | 是 | 本地缓存的唯一键名(本地名称)(后续读取/删除数据需通过此key操作) |
data |
any | 是 | 要存储的数据(最终会被转为字符串存储;若为对象/数组,需先通过JSON.stringify序列化) |
三、使用示例
1. 存储基础类型数据(字符串/数字/布尔)
// 存储字符串
wx.setStorageSync('username', '张三');
// 存储数字
wx.setStorageSync('score', 90);
// 存储布尔值
wx.setStorageSync('isLogin', true);
2. 存储对象/数组(需先序列化)
小程序本地缓存仅支持存储字符串,因此 对象/数组需通过 JSON.stringify 转为字符串后存储 :
// 存储商品列表数组
const productList = [
{ id: 1, title: '2025年湖北专升本真题' },
{ id: 2, title: '英语作文模板' }
];
// 序列化后存储
wx.setStorageSync('productList', JSON.stringify(productList));
// 存储用户信息对象
const userInfo = { id: 1001, name: '李四', age: 22 };
wx.setStorageSync('userInfo', JSON.stringify(userInfo));
四、错误处理
wx.setStorageSync 是同步API,执行失败会直接抛出错误,需通过 try/catch 捕获异常 :
try {
const data = { content: '作文内容...' };
wx.setStorageSync('essayData', JSON.stringify(data));
console.log('存储成功');
} catch (err) {
console.error('存储失败:', err);
wx.showToast({ title: '数据存储失败', icon: 'none' });
}
五、注意事项
-
数据类型限制:
- 直接存储对象/数组会被转为
"[object Object]"等无意义字符串,必须用JSON.stringify序列化; - 不支持存储函数、
undefined(会被忽略)、循环引用对象(会报错)。
- 直接存储对象/数组会被转为
-
存储容量限制:
- 单个
key对应的data大小不超过 1MB; - 小程序本地缓存总容量不超过 10MB,超出会存储失败。
- 单个
-
同步特性:
wx.setStorageSync是同步执行,会阻塞当前线程;若存储大量数据,建议改用异步APIwx.setStorage避免页面卡顿。
wx.setStorageSync(同步存储)和 wx.setStorage(异步存储)是微信小程序本地存储的两个核心API,核心区别在于执行机制、线程阻塞性、使用方式,具体对比如下:
一、核心区别:同步 vs 异步执行
| 维度 | wx.setStorageSync(同步) |
wx.setStorage(异步) |
|---|---|---|
| 执行机制 | 同步执行:调用后等待存储操作完成,才会继续执行后续代码。 | 异步执行:调用后立即继续执行后续代码,存储操作在后台完成,结果通过回调/Promise返回。 |
| 线程阻塞性 | 会阻塞当前JS线程:若存储大量数据(如1MB以上的数组),会导致页面卡顿、响应延迟。 | 不会阻塞线程:存储操作在异步队列中执行,不影响当前页面的交互和渲染。 |
| 使用语法 | 直接调用,返回存储结果(失败则抛出错误),需用 try/catch 处理异常。 |
需传入回调函数(success/fail/complete),或通过 wx.promiseify 转为 Promise 用 async/await。 |
| 错误处理方式 | 通过 try/catch 捕获存储失败的异常。 |
通过 fail 回调函数,或 Promise.catch() 捕获异常。 |
二、代码示例对比
1. wx.setStorageSync(同步)
try {
// 同步存储:执行到这一行时,会等待存储完成再继续
wx.setStorageSync('bigData', JSON.stringify(largeArray)); // largeArray是大量数据
console.log('存储成功(同步)'); // 存储完成后才会执行这行
} catch (err) {
console.error('存储失败(同步):', err); // 捕获同步存储的错误
}
2. wx.setStorage(异步)
方式1:回调函数
// 异步存储:调用后立即执行后续代码,存储结果通过回调返回
wx.setStorage({
key: 'bigData',
data: JSON.stringify(largeArray),
success: () => {
console.log('存储成功(异步)'); // 存储完成后才会执行这里
},
fail: (err) => {
console.error('存储失败(异步):', err); // 异步存储的错误在这里捕获
}
});
console.log('后续代码(异步)'); // 这行代码会在存储操作发起后立即执行
方式2:async/await(需转Promise)
// 微信小程序基础库2.10.0+支持直接用Promise写法
async function saveData() {
try {
await wx.setStorage({
key: 'bigData',
data: JSON.stringify(largeArray)
});
console.log('存储成功(异步Promise)');
} catch (err) {
console.error('存储失败(异步Promise):', err);
}
}
saveData();
console.log('后续代码(异步Promise)'); // 先执行这行,再执行存储结果
三、适用场景
wx.setStorageSync:适合存储少量数据(如用户ID、开关状态),或需要“存储完成后立即使用数据”的场景(同步执行保证顺序)。wx.setStorage:适合存储大量数据(如商品列表、作文内容),或不依赖存储结果立即执行后续逻辑的场景(避免页面卡顿)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号