ML11 My_Bagging_Of_Logistic
ML实战:手动实现Bagging集成学习
- 使用了sklearn自带的乳腺癌数据集
- 由于自身电脑条件不足,虽然Bagging是并行的,但是在实验中采用了依次训练各个基学习器的方法
代码实现
Bagging类
from Logistic_class import LogisticRegression
import numpy as np
np.set_printoptions(suppress=True)
class Bagging:
def __init__(self,x=None,y=None,T=5):
'''
:param x: 数据集
:param y: 数据标签
:param T: 基学习器个数
:param Base: 基学习器列表
:param m: 数据集大小
:param D: 每个基学习器的训练数据
'''
self.x=x
self.y=y
self.Base=[]
self.D=[]
self.m=len(self.x)
self.T=T
def bootstrap(self):
#自助采样
index=np.random.choice(self.m,size=self.m)
return index
def Random_Sampling(self):
#用自主采样的数据训练基学习器
for i in range(self.T):
index=self.bootstrap()
self.D.append(index)
self.Base.append(LogisticRegression(self.x[index],self.y[index]))
def fit(self,alpha=0.3,iter_count=500):
#参数拟合
self.Random_Sampling()
for i in range(self.T):
self.Base[i].fit(alpha,iter_count)
def predict(self,x):
#预测函数,简单投票法
y_predict=np.zeros((len(x),1))
for i in range(self.T):
y_predict+=self.Base[i].predict(x)
for i in range(len(x)):
if y_predict[i]>0:
y_predict[i]=1
elif y_predict[i]<0:
y_predict[i]=0
else:
y_predict[i]=np.random.choice([0, 1])
return y_predict
主函数
from Bagging_class import Bagging
import numpy as np
import sys
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn import datasets
np.set_printoptions(suppress=True)
#获取数据集
x=datasets.load_breast_cancer().data
y=datasets.load_breast_cancer().target
#分割数据集
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.1,random_state=np.random.randint(0,30))
X = np.arange(1, len(y_test) + 1)
#构建Bagging模型并训练
bagging=Bagging(x_train,y_train,5)
bagging.fit(10,3000)
y_predict=bagging.predict(x_test)
#画图,可视化输出
plt.figure(figsize=(15,4),dpi=80)
plt.scatter(X,y_test,label='real',marker='s',color='blue')
plt.scatter(X,y_predict,label='predict',marker='x',color='red')
plt.legend(loc=[1,0])
plt.grid(True,linestyle='--',alpha=0.5)
plt.yticks(y_test[::1])
plt.xticks(X[::1])
plt.xlabel('index of tests')
plt.ylabel('target')
plt.savefig('E:\python\ml\ml by myself\Ensemble_Learning\Bagging\Bagging_Of_Logistic.png')
sys.exit(0)
结果
预测结果与真实标签的对比
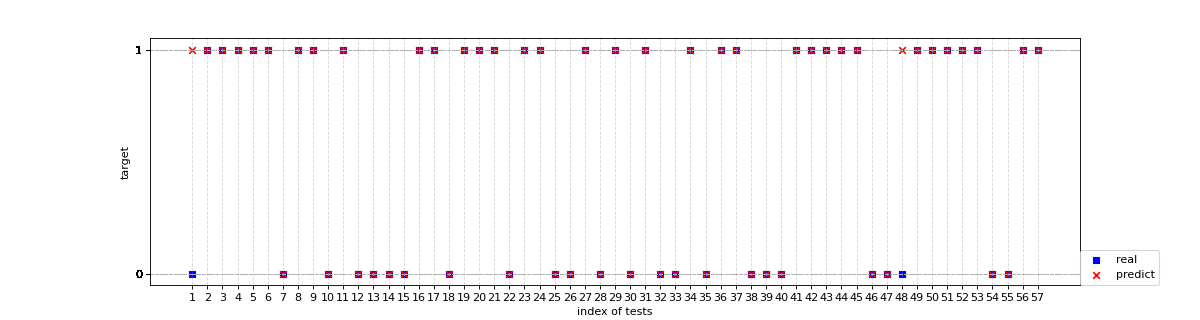
单一学习器和Bagging对比


在100次训练中,集成学习平均错误个数为3.26,而逻辑回归平均错误个数为4.18

 浙公网安备 33010602011771号
浙公网安备 33010602011771号