

Scrapy

Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试
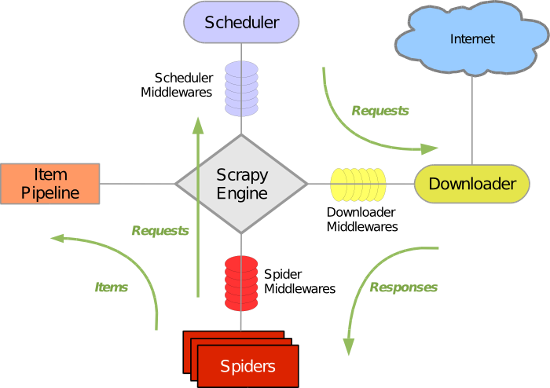
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓
1.基本命令


1 1. scrapy startproject 项目名称 2 - 在当前目录中创建中创建一个项目文件(类似于Django) 3 4 2. scrapy genspider [-t template] <name> <domain> 5 - 创建爬虫应用 6 如: 7 scrapy gensipider -t basic oldboy oldboy.com 8 scrapy gensipider -t xmlfeed autohome autohome.com.cn 9 PS: 10 查看所有命令:scrapy gensipider -l 11 查看模板命令:scrapy gensipider -d 模板名称 12 13 3. scrapy list 14 - 展示爬虫应用列表 15 16 4. scrapy crawl 爬虫应用名称 17 - 运行单独爬虫应用
文件说明:
- scrapy.cfg 项目的主配置信息。(真正爬虫相关的配置信息在settings.py文件中)
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
- spiders 爬虫目录,如:创建文件,编写爬虫规则
# -*- coding: utf-8 -*- import scrapy import io import sys sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['chouti.com'] start_urls = ['http://dig.chouti.com/'] def parse(self, response): print(response.url)
import io sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
2.爬取所有url的文本
1 # -*- coding: utf-8 -*- 2 import scrapy 3 import io 4 import sys 5 from scrapy.selector import Selector 6 7 sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8') 8 class ChoutiSpider(scrapy.Spider): 9 name = 'chouti' 10 allowed_domains = ['baidu.com'] 11 start_urls = ['http://www.baidu.com/'] 12 def parse(self, response): 13 div=Selector(response=response).xpath("//div") 14 for a in div: 15 u=a.xpath('.//a/text()').extract() 16 u = a.xpath('.//a/text()').extract_first() 17 #text获取标签中的文本 18 #extract()将对象转化为字符串 19 print(u) 20 for r in u: 21 print(r)
3,利用爬取深度爬取url
setting中添加DEPTH_LIMIT=1
1 # -*- coding: utf-8 -*- 2 import scrapy 3 from scrapy.selector import Selector 4 import hashlib 5 from scrapy.http import Request 6 class BaiduSpider(scrapy.Spider): 7 name = 'baidu' 8 allowed_domains = ['baidu.com'] 9 start_urls = ['http://www.baidu.com/s?tn=news&rtt=1&bsst=1&wd=热点&cl=2'] 10 s_url=set() 11 def parse(self, response): 12 #寻找id为page的标签 13 page=Selector(response=response).xpath("//p[@id='page']") 14 #寻找p标签下面的a标签 15 page_a=page.xpath("./a/@href").extract() 16 for a in page_a: 17 md5_url=self.md5(a) 18 if md5_url in self.s_url: 19 pass 20 else: 21 22 self.s_url.add(md5_url) 23 a="http://www.baidu.com%s"%a 24 25 #将url传送到调度器中,与爬取深度相关,在下载器下载完执行callback函数指定的self.parse函数 26 yield Request(url=a,callback=self.parse) 27 print(a) 28 print(len(self.s_url)) 29 def md5(self,url): 30 obj=hashlib.md5() 31 obj.update(bytes(url,encoding="utf-8")) 32 return obj.hexdigest()
4,piplines和item
piplines是进行数据持久化操作的,对数据进行存储
item是生成一个对象,该对象有中有你需要你进行持久化的数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号