
计算相同key的数据平均值 - aggregateByKey

查看源码发现 aggregateByKey 的返回值与传入的zeroVlue类型是一样的
package com.pzb.rdd.operator.transform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @Description TODO aggregateByKey小练习
* @author 海绵先生
* @date 2023/3/16-15:17
*/
object Spark18_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// TODO 计算相同key值数据的平均值
val rdd: RDD[(String, Int)] = sc.makeRDD(List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5), ("a", 6)
), 2)
// (Int,Int):第一个表示相同key的value之和,第二个Int表示相同key出现的次数
val newRDD: RDD[(String, (Int, Int))] = rdd.aggregateByKey((0, 0))(
(t, v) => {
(t._1 + v, t._2 + 1) // t表示的是初始值元组
},
(t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
)
// 计算平均值
val resultRDD: RDD[(String, Int)] = newRDD.map(
data => (data._1, data._2._1 / data._2._2)
)
resultRDD.collect().foreach(println)
/*
(b,4)
(a,3)
*/
// 模式匹配,如果不这样写,就要用"()",并且把value当成一个整体,像上面map一样
val resultRDD2: RDD[(String, Int)] = newRDD.mapValues {
case (total, count) => {
total / count
}
}
resultRDD2.collect().foreach(println)
/*
(b,4)
(a,3)
*/
sc.stop()
}
}
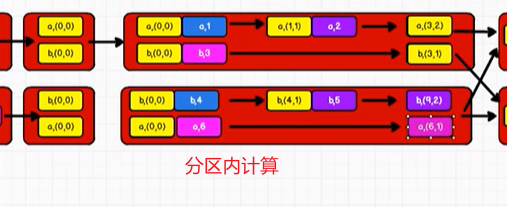
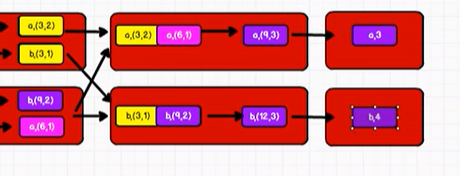
另外一种实现方式:
package com.pzb.rdd.operator.transform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @Description TODO
* @author 海绵先生
* @date 2023/3/16-15:17
*/
object Spark19_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// TODO transform算子 - combineByKey
val rdd: RDD[(String, Int)] = sc.makeRDD(List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5), ("a", 6)
), 2)
// combineByKey : 方法需要三个参数
// 第一个参数表示:将相同key的第一个数据进行结构的转换,实现操作
// 第二个参数表示:分区内的计算规则
// 第三个参数表示:分区间的计算规则
val newRDD: RDD[(String, (Int, Int))] = rdd.combineByKey(
v => (v, 1), // 指定不同key的第一个value元素格式
(t: (Int, Int), v) => { // 因为需要动态识别,所以要事先标明数据类型,否则有肯能会出错
(t._1 + v, t._2 + 1) // t._1 + v:value的总数
},
(t1: (Int, Int), t2: (Int, Int)) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
)
val resultRDD: RDD[(String, Int)] = newRDD.mapValues {
case (sum, count) => sum / count
}
resultRDD.collect().foreach(println)
/*
(b,4)
(a,3)
*/
sc.stop()
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号