mongodb索引
创建索引
单键或复合键
创建索引命令:db.<collection>.createIndex(<keys>, <options>)
返回结果:
{
createCollectionAutomatically: false,
numIndexesBefore: 1,
numIndexesAfter: 2,
ok: 1
}
createCollectionAutomatically是否自动创建了集合(集合不存在时,直接创建索引会导致该属性为true。集合已存在,创建索引,该值为false)numIndexesBefore创建索引之前,索引的数量numIndexesAfter创建索引之后,索引的数量ok是否成功
复合键索引的顺序很重要,其可支持的查询方式为前缀子查询
如(A,B,C)索引支持的查询方式为(A)、(A,B)、(B,A)、(A,B,C)、(B,A,C)、(B,C,A)、(C,A,B)、(C,B,A)。例子如下:
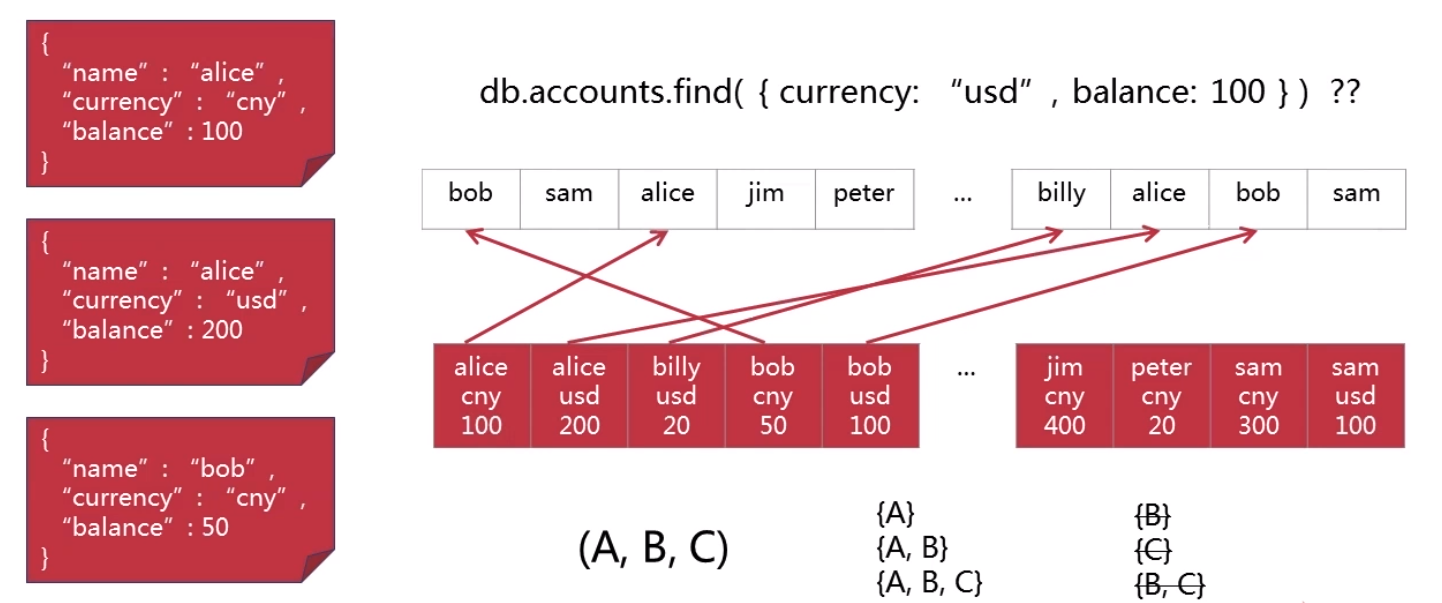
上述索引已经按照{name: 1, currency: 1, balance: -1}的方式创建索引了,可以看到查询携带name属性的查询方式时,创建的索引才会被用到。而不携带name属性时,创建的索引无作用,还是需要通过遍历进行查找。
多键索引
创建索引的key是数组形式时,MongoDB会自动创建多键索引。此时数组中的每一个元素都会作为索引中的一个键,被保存起来,分别指向对应的完整文档的内存地址。
例如如下集合:
[
{name: 'alice', currency: ['CNY', 'USD']}
{name: 'bob', currency: ['GBP', 'USD']}
]
创建索引:db.<collection>.createIndex({currency: 1}),此时的索引映射情况如下:
'CNY' ---> {name: 'alice', currency: ['CNY', 'USD']}
'GBP' ---> {name: 'bob', currency: ['GBP', 'USD']}
'USD' ---> {name: 'alice', currency: ['CNY', 'USD']}
'USD' ---> {name: 'bob', currency: ['GBP', 'USD']}
如果查询操作是针对数据中元素而执行的,此时就会用到多键索引
查看索引
命令:db.<collection>.getIndexes(),返回数组形式的所有索引情况,如:
[
{
"v" : 2,
"key" : { //创建索引时的key
"_id" : 1
},
"name" : "_id_" //索引名称
},
{
"v" : 2,
"key" : {
"name" : 1
},
"name" : "name_1"
}
]
索引效果
查询效果
使用explain()可查看当前查询效果,返回值中注意一下信息:
{
queryPlanner: {
winningPlan: {
stage: 'COLLSCAN', //COLLSCAN表示数据库没找到很好的查询方法,直接全集合扫描。如果是这样,说明没有用到索引
......
}
}
......
}
queryPlanner显示的是被查询优化器选择出来的查询计划winningPlan文档类型,详细显示查询优化程序选择的查询计划winningPlan.stage阶段名称。每个阶段都有每个阶段特有的信息。例如,IXSCAN阶段将包括索引边界以及特定于索引扫描的其他数据。如果阶段具有子阶段或多个子阶段,则阶段将具有inputStage或inputStages
阶段操作描述
| 描述 | 说明 |
|---|---|
| COLLSCAN | 集合扫描 |
| IXSCAN | 索引扫描 |
| FETCH | 检出文档 |
| SHARD_MERGE | 合并分片中结果 |
| SHARDING_FILTER | 分片中过滤掉孤立文档 |
| LIMIT | 使用limit 限制返回数 |
| PROJECTION | 使用 skip 进行跳过 |
| IDHACK | 针对_id进行查询 |
| COUNT | 利用db.coll.explain().count()之类进行count运算 |
| COUNTSCAN | count不使用Index进行count时的stage返回 |
| COUNT_SCAN | count使用了Index进行count时的stage返回 |
| SUBPLA | 未使用到索引的$or查询的stage返回 |
| TEXT | 使用全文索引进行查询时候的stage返回 |
| PROJECTION | 限定返回字段时候stage的返回 |
如果是用到了索引,则上面的stage不会为COLLSCAN。举个利用到索引的explain返回例子:
{
queryPlanner: {
winningPlan : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN", //index scan索引
"keyPattern" : { //通过哪个索引
"name" : 1
},
"indexName" : "name_1", //使用的索引的名称
......
}
......
}
}
......
}
上面的信息,表明了两个阶段,一是IXSCAN通过索引进行扫描,一是FETCH检出文档。
检出效果
上面的explain操作中,存在FETCH阶段。此时更好的优化策略是将FETCH也消除掉,使用方法是将检出的文档返回字段被索引覆盖到,就会更加高效
此处要注意一个地方,返回的字段为复合索引字段的任意非空子集(无需前缀无需顺序),都可以让查询优化器使用到索引,从而不需要从真正的文档中检出字段,直接从索引中检出
排序效果
如果需要排序也要能利用到复合索引,条件比较苛刻,需要满足以下几点:
- 前缀子查询
- 顺序与索引顺序一致
- 排序方式与索引一致(字段指定的1或-1)
- 只首个属性的排序时,1或-1都可
如建立了复合索引{a: 1, b:-1},当sort({a:1})、sort({a:-1})、sort({a: 1, b:-1})时,可用到IXSCAN。而使用sort({a:1, b:1})、sort({a:-1, b:-1})、sort({b:-1, a:1})、sort({b:-1})时,则会出现COLLSCAN。
删除索引
命令db.<collection>.dropIndex(<索引名称或索引定义>)
如果需要修改已经创建的索引,需要先删除,然后再新建
唯一索引
命令:db.<collection>.createIndex(<key>, {unique: true})
其限制key中的索引值在所有文档中只能存在唯一的值,不能重复。如果文档中,已经存在该属性重复的一些文档,该创建索引的命令将不会执行成功。
还要注意一个小细节:
当唯一索引创建成功后,如果新加入的文档不包含该索引所定义的字段时,由于唯一性约束,新文档中该字段会被认为null(不会被查询出来),而如果继续插入的文档还是不包含该字段,则不能进行插入了,因为null已经存在了。
所以,如果新增的文档中不包含唯一性索引字段,则只有第一篇缺失该字段的文档将会被写入数据库
复合键索引情况类似,存在几种情况:
- 完全不包含复合索引的字段时,新插入的第一篇的文档的所有复合索引字段的值,会被认为是null。再次插入相同的文档,则不会被允许
- 包含部分复合索引的字段时,其他索引字段会被认为是null,再次插入时也不会被允许
总结特点,没有值的字段都认为是null,组合起来的对象不能重复
例如,创建唯一复合索引{name: 1, balance: -1},则以下文档是可以同时进行存储的:
[
{name: 'a'},
{balance: 100},
{name: 'a', balance: 100}
{num: 1}
]
而再次插入上面任意一条,都不会被允许。
稀疏性
建立稀疏性索引的命令:db.<collection>.createIndex(<key>, {sparse: true})
稀疏性相对于唯一性而言,文档限制就较为宽泛了。如果建立了稀疏性的索引,则只会将包含索引字段的文档加入索引中(即使该字段为null)
例如,建立了索引:db.<collection>.ceateIndex({name: 1}, {sparse: true}),就会存在以下文档的情况:
{name: 'a', balance: 100} //会被加入索引
{balance: 200} //不会被加入索引,但会被存储
{name: null, balance: 50} //会被加入索引
利用稀疏性索引,可以节省索引所占用的存储空间。当集合中有很大一部分的文档是缺少该字段时,就没有必要将这些文档加入索引中了。
复合索引的稀疏性可以任意组合的重复插入。
唯一性与稀疏性可以同时设置
索引既可以是唯一的,也可以是稀疏的。利用两者的组合,可以解决唯一性索引只能保存第一篇缺失索引的文档,使得可以保存多篇缺失索引的文档。总结特点就是,存在该字段的,保证字段值唯一,不存在该字段的,可以存入,但不加入索引。这样就提升了集合的灵活性。
生存时间
命令:db.<collection>.createIndex(<key>, {expireAfterSeconds: <秒数>})
注意,此时key中的键,只能是时间属性或包含时间属性的数组,如果是其他类型的字段将不会触发过期删除的特性。另外,时间过期设置对复合键索引无效。
字段为包含时间属性的数组时,以最小(最久远)的那个日期为准,用以计算是否过期。
数据库使用后台线程用来删除过期文档,是具有一定的延迟的,该延迟具有不确定性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号