
Prometheus【普罗米修斯】+Grafana部署企业级监控之 规则(rule)配置及报警 (三)
一、配置规则
前面已经部署了prometheus、node_exporter、alertmanager和grafana,并介绍了PromQL,且对于metrics进行了查询演示。
本文配置各项规则,完成记录及告警。
prometheus的规则分为记录规则和告警规则,rule_files 主要用于配置 rules 文件,它支持多个文件以及文件目录。
1.1 当前配置:
cat /usr/local/prometheus/prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- "10.0.0.15:9093"
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['10.0.0.14:9090']
- job_name: 'nodes'
static_configs:
- targets:
- "10.0.0.14:9100"
- "10.0.0.15:9100"
- "10.0.0.16:9100"
- job_name: 'alertmanagers'
static_configs:
- targets:
- "10.0.0.15:9100"1.2 记录规则配置:
记录规则可以预先计算经常需要或计算量大的表达式,并将其结果保存为一组新的时间序列。这样,查询预先计算的结果通常比每次需要原始表达式都要快得多。这对于仪表板非常有用,仪表板每次刷新时都需要重复查询相同的表达式。
记录和告警规则存在于规则组中。组中的规则以规则的时间间隔顺序运行。记录和告警规则的名称必须是有效的度量标准名称。
注意:冒号是为用户定义的记录规则保留的,不应该被exporter使用。
mkdir /usr/local/prometheus/rules
vim /usr/local/prometheus/rules/node-record-rules.yml
groups:
- name: node-record
rules:
#system
- record: node:up
expr: up{job="nodes"}
labels:
job: "nodes"
unit:
desc: "节点是否在线,在线1,不在线0"
- record: node:name
expr: count by (nodename) (node_uname_info)
labels:
job: "nodes"
unit:
desc: "节点的主机名"
- record: node:uptime
expr: time() - node_boot_time_seconds{}
labels:
job: "nodes"
unit: s
desc: "节点的运行时间"
#cpu
- record: node:cpu:num
expr: count by (instance) (node_cpu_seconds_total{job="nodes",mode='system'})
labels:
job: "nodes"
unit: v
desc: "节点的cpu 核数"
- record: node:cpu:idle:percent
expr: avg by (instance) (irate(node_cpu_seconds_total{job="nodes",mode="idle"}[5m])) * 100
labels:
job: "nodes"
unit: "%"
desc: "5m的cpu 空闲百分比"
- record: node:cpu:used:percent
expr: (1 - avg by (instance) (irate(node_cpu_seconds_total{job="nodes",mode="idle"}[5m]))) * 100
labels:
job: "nodes"
unit: "%"
desc: "5m的cpu 总使用百分比"
- record: node:cpu:system:percent
expr: avg by (instance) (irate(node_cpu_seconds_total{job="nodes",mode="system"}[5m])) * 100
labels:
job: "nodes"
unit: "%"
desc: "节点的cpu system使用百分比"
- record: node:cpu:user:percent
expr: avg by (instance) (irate(node_cpu_seconds_total{job="nodes",mode="user"}[5m])) * 100
labels:
job: "nodes"
unit: "%"
desc: "节点的cpu user使用百分比"
- record: node:cpu:iowait:percent
expr: avg by (instance) (irate(node_cpu_seconds_total{job="nodes",mode="iowait"}[5m])) * 100
labels:
job: "nodes"
unit: "%"
desc: "节点的cpu iowait使用百分比"
- record: node:cpu:other:percent
expr: avg by (instance) (irate(node_cpu_seconds_total{job="nodes",mode=~"softirq|nice|irq|steal"}[5m])) * 100
labels:
job: "nodes"
unit: "%"
desc: "节点的cpu other使用百分比"
#memory
- record: node:memory:total
expr: node_memory_MemTotal_bytes{job="nodes"}
labels:
job: "nodes"
unit: bytes
desc: "节点的mem 总大小"
- record: node:memory:avail
expr: node_memory_MemAvailable_bytes{job="nodes"}
labels:
job: "nodes"
unit: bytes
desc: "节点的mem avail大小"
- record: node:memory:free
expr: node_memory_MemFree_bytes{job="nodes"}
labels:
job: "nodes"
unit: bytes
desc: "节点的mem free大小"
- record: node:memory:used
expr: node_memory_MemTotal_bytes{job="nodes"} - node_memory_MemFree_bytes{job="nodes"}
labels:
job: "nodes"
unit: bytes
desc: "节点的mem used总大小"
- record: node:memory:actuallyused
expr: node_memory_MemTotal_bytes{job="nodes"} - node_memory_MemAvailable_bytes{job="nodes"}
labels:
job: "nodes"
unit: bytes
desc: "节点的mem used实际大小"
- record: node:memory:avail:percent
expr: node_memory_MemAvailable_bytes{job="nodes"} / node_memory_MemTotal_bytes{job="nodes"} * 100
labels:
job: "nodes"
unit: "%"
desc: "节点的mem avail百分比"
- record: node:memory:free:percent
expr: node_memory_MemFree_bytes{job="nodes"} / node_memory_MemTotal_bytes{job="nodes"} * 100
labels:
job: "nodes"
unit: "%"
desc: "节点的mem free百分比"
- record: node:memory:used:percent
expr: (1 - node_memory_MemAvailable_bytes{job="nodes"} / node_memory_MemTotal_bytes{job="nodes"}) * 100
labels:
job: "nodes"
unit: "%"
desc: "节点的mem used百分比"
#load
- record: node:load:load1
expr: node_load1
labels:
job: "nodes"
unit:
desc: "节点1m load"
- record: node:load:load5
expr: node_load5
labels:
job: "nodes"
unit:
desc: "节点5m load"
- record: node:load:load15
expr: node_load15
labels:
job: "nodes"
unit:
desc: "节点15m load"
- record: node:load:load1:sum
expr: sum by (job) (node_load1)
labels:
job: "nodes"
unit:
desc: "节点1m 整体load"
- record: node:load:load5:sum
expr: sum by (job) (node_load5)
labels:
job: "nodes"
unit:
desc: "节点5m 整体load"
- record: node:load:load15:sum
expr: sum by (job) (node_load15)
labels:
job: "nodes"
unit:
desc: "节点15m 整体load"
#disk
- record: node:disk:root:total
expr: node_filesystem_size_bytes{job="nodes",fstype=~"ext.*|xfs",mountpoint ="/"}
labels:
job: "nodes"
unit: bytes
desc: "节点 / 分区 disk总大小"
- record: node:disk:boot:total
expr: node_filesystem_size_bytes{job="nodes",fstype=~"ext.*|xfs",mountpoint ="/boot"}
labels:
job: "nodes"
unit: bytes
desc: "节点 /boot 分区 disk总大小"
- record: node:disk:root:avail
expr: node_filesystem_avail_bytes{job="nodes",fstype=~"ext.*|xfs",mountpoint ="/"}
labels:
job: "nodes"
unit: bytes
desc: "节点 / 分区 disk avail大小"
- record: node:disk:boot:avail
expr: node_filesystem_avail_bytes{job="nodes",fstype=~"ext.*|xfs",mountpoint ="/boot"}
labels:
job: "nodes"
unit: bytes
desc: "节点 /boot 分区 disk avail大小"
- record: node:disk:root:used
expr: node_filesystem_size_bytes{job="nodes",fstype=~"ext.*|xfs",mountpoint ="/"} - node_filesystem_avail_bytes{job="nodes",fstype=~"ext.*|xfs",mountpoint ="/"}
labels:
job: "nodes"
unit: bytes
desc: "节点 / 分区 disk used大小"
- record: node:disk:boot:used
expr: node_filesystem_size_bytes{job="nodes",fstype=~"ext.*|xfs",mountpoint ="/boot"} - node_filesystem_avail_bytes{job="nodes",fstype=~"ext.*|xfs",mountpoint ="/boot"}
labels:
job: "nodes"
unit: bytes
desc: "节点 /boot 分区 disk used大小"
- record: node:disk:root:avail:percent
expr: node_filesystem_avail_bytes{job="nodes",fstype=~"ext.*|xfs",mountpoint ="/"} / node_filesystem_size_bytes{job="nodes",fstype=~"ext.*|xfs",mountpoint ="/"} * 100
labels:
job: "nodes"
unit: "%"
desc: "节点 / 分区 disk avail百分比"
- record: node:disk:boot:avail:percent
expr: node_filesystem_avail_bytes{job="nodes",fstype=~"ext.*|xfs",mountpoint ="/boot"} / node_filesystem_size_bytes{job="nodes",fstype=~"ext.*|xfs",mountpoint ="/boot"} * 100
labels:
job: "nodes"
unit: "%"
desc: "节点 /boot 分区 disk avail百分比"
- record: node:disk:root:used:percent
expr: (1 - node_filesystem_avail_bytes{job="nodes",fstype=~"ext.*|xfs",mountpoint ="/"} / node_filesystem_size_bytes{job="nodes",fstype=~"ext.*|xfs",mountpoint ="/"}) * 100
labels:
job: "nodes"
unit: "%"
desc: "节点 / 分区 disk used百分比"
- record: node:disk:boot:used:percent
expr: (1 - node_filesystem_avail_bytes{job="nodes",fstype=~"ext.*|xfs",mountpoint ="/boot"} / node_filesystem_size_bytes{job="nodes",fstype=~"ext.*|xfs",mountpoint ="/boot"}) * 100
labels:
job: "nodes"
unit: "%"
desc: "节点 /boot 分区 disk used百分比"
- record: node:disk:read:rate
expr: irate(node_disk_read_bytes_total{job="nodes"}[5m])
labels:
job: "nodes"
unit: bytes/s
desc: "节点的磁盘设备5m read速率"
- record: node:disk:write:rate
expr: irate(node_disk_written_bytes_total{job="nodes"}[5m])
labels:
job: "nodes"
unit: bytes/s
desc: "节点的磁盘设备5m write速率"
- record: node:disk:read:rate:count
expr: irate(node_disk_reads_completed_total{job="nodes"}[5m])
labels:
job: "nodes"
unit: iops
desc: "节点的磁盘5m read速率"
- record: node:disk:write:rate:count
expr: irate(node_disk_writes_completed_total{job="nodes"}[5m])
labels:
job: "nodes"
unit: iops
desc: "节点的磁盘5m write速率"
#filesystem
- record: node:inode:root:total
expr: node_filesystem_files{job="nodes",fstype=~"ext4|xfs",mountpoint="/"}
labels:
job: "nodes"
unit:
desc: "节点 / 分区 inode总数"
- record: node:inode:boot:total
expr: node_filesystem_files{job="nodes",fstype=~"ext4|xfs",mountpoint="/boot"}
labels:
job: "nodes"
unit:
desc: "节点 /boot 分区 inode总数"
- record: node:inode:root:free
expr: node_filesystem_files_free{job="nodes",fstype=~"ext4|xfs",mountpoint="/"}
labels:
job: "nodes"
unit:
desc: "节点 / 分区 inode free数"
- record: node:inode:boot:free
expr: node_filesystem_files_free{job="nodes",fstype=~"ext4|xfs",mountpoint="/boot"}
labels:
job: "nodes"
unit:
desc: "节点 /boot 分区 inode free数"
- record: node:inode:root:used
expr: node_filesystem_files{job="nodes",fstype=~"ext4|xfs",mountpoint="/"} - node_filesystem_files_free{job="nodes",fstype=~"ext4|xfs",mountpoint="/"}
labels:
job: "nodes"
unit:
desc: "节点 / 分区 inode used数"
- record: node:inode:boot:used
expr: node_filesystem_files{job="nodes",fstype=~"ext4|xfs",mountpoint="/boot"} - node_filesystem_files_free{job="nodes",fstype=~"ext4|xfs",mountpoint="/boot"}
labels:
job: "nodes"
unit:
desc: "节点 /boot 分区 inode used数"
- record: node:inode:root:free:percent
expr: node_filesystem_files_free{job="nodes",fstype=~"ext4|xfs",mountpoint="/"} / node_filesystem_files{job="nodes",fstype=~"ext4|xfs",mountpoint="/"} * 100
labels:
job: "nodes"
unit: "%"
desc: "节点 / 分区 inode free百分比"
- record: node:inode:boot:free:percent
expr: node_filesystem_files_free{job="nodes",fstype=~"ext4|xfs",mountpoint="/boot"} / node_filesystem_files{job="nodes",fstype=~"ext4|xfs",mountpoint="/boot"} * 100
labels:
job: "nodes"
unit: "%"
desc: "节点 /boot 分区 inode free百分比"
- record: node:inode:root:used:percent
expr: (1 - node_filesystem_files_free{job="nodes",fstype=~"ext4|xfs",mountpoint="/"} / node_filesystem_files{job="nodes",fstype=~"ext4|xfs",mountpoint="/"}) * 100
labels:
job: "nodes"
unit: "%"
desc: "节点 / 分区 inode used百分比"
- record: node:inode:boot:used:percent
expr: (1 - node_filesystem_files_free{job="nodes",fstype=~"ext4|xfs",mountpoint="/boot"} / node_filesystem_files{job="nodes",fstype=~"ext4|xfs",mountpoint="/boot"}) * 100
labels:
job: "nodes"
unit: "%"
desc: "节点 /boot 分区 inode used百分比"
#filefd
- record: node:filefd:total
expr: node_filefd_maximum{job="nodes"}
labels:
job: "nodes"
unit:
desc: "节点的最大文件描述符"
- record: node:filefd:allocated
expr: node_filefd_allocated{job="nodes"}
labels:
job: "nodes"
unit:
desc: "节点的文件描述符打开个数"
- record: node:filefd:allocated:percent
expr: node_filefd_allocated{job="nodes"} / node_filefd_maximum{job="nodes"} * 100
labels:
job: "nodes"
unit: "%"
desc: "节点的文件描述符打开百分比"
#network
- record: node:network:device:name
expr: node_network_device_id{device!~"lo|docker.|cali.*"}
labels:
job: "nodes"
unit:
desc: "节点的网卡名"
- record: node:network:netin:bit:rate
expr: avg by (instance) (irate(node_network_receive_bytes_total{device=~"eth0|eth1|ens33|ens37"}[1m]) * 8)
labels:
job: "nodes"
unit: bits/s
desc: "节点网卡1m内 每秒接收的比特数"
- record: node:network:netout:bit:rate
expr: avg by (instance) (irate(node_network_transmit_bytes_total{device=~"eth0|eth1|ens33|ens37"}[1m]) * 8)
labels:
job: "nodes"
unit: bits/s
desc: "节点网卡1m内 每秒发送的比特数"
- record: node:network:netin:packet:rate
expr: avg by (instance) (irate(node_network_receive_packets_total{device=~"eth0|eth1|ens33|ens37"}[1m]))
labels:
job: "nodes"
unit: "个/秒"
desc: "节点网卡1m内 每秒接收的数据包个数"
- record: node:network:netout:packet:rate
expr: avg by (instance) (irate(node_network_transmit_packets_total{device=~"eth0|eth1|ens33|ens37"}[1m]))
labels:
job: "nodes"
unit: "个/秒"
desc: "节点网卡1m内 每秒发送的数据包个数"
- record: node:network:netin:packet:error:rate
expr: avg by (instance) (irate(node_network_receive_errs_total{device=~"eth0|eth1|ens33|ens37"}[1m]))
labels:
job: "nodes"
unit: "个/秒"
desc: "节点设备驱动器1m内 检测到的接收错误包的数量"
- record: node:network:netout:packet:error:rate
expr: avg by (instance) (irate(node_network_transmit_errs_total{device=~"eth0|eth1|ens33|ens37"}[1m]))
labels:
job: "nodes"
unit: "个/秒"
desc: "节点设备驱动器1m内 检测到的发送错误包的数量"
#tcp
- record: node:tcp:established
expr: node_netstat_Tcp_CurrEstab{job="nodes"}
labels:
job: "nodes"
unit: "个"
desc: "节点当前状态为 ESTABLISHED 或 CLOSE-WAIT 的 tcp 连接数"
- record: node:tcp:active
expr: node_netstat_Tcp_ActiveOpens{job="nodes"}
labels:
job: "nodes"
unit: "个"
desc: "节点从 CLOSED 状态直接转换到 SYN-SENT 状态的 tcp 连接数"
- record: node:tcp:passive
expr: node_netstat_Tcp_PassiveOpens{job="nodes"}
labels:
job: "nodes"
unit: "个"
desc: "节点从 LISTEN 状态直接转换到 SYN-RCVD 状态的 tcp 连接数"
- record: node:tcp:in
expr: node_netstat_Tcp_InSegs{job="nodes"}
labels:
job: "nodes"
unit: "个"
desc: "节点tcp 接收的报文数"
- record: node:tcp:out
expr: node_netstat_Tcp_OutSegs{job="nodes"}
labels:
job: "nodes"
unit: "个"
desc: "节点tcp 发送的报文数"
- record: node:tcp:inerrs
expr: node_netstat_Tcp_InErrs{job="nodes"}
labels:
job: "nodes"
unit: "个"
desc: "节点tcp 接收的错误报文数"
- record: node:tcp:retrans
expr: node_netstat_Tcp_RetransSegs{job="nodes"}
labels:
job: "nodes"
unit: "个"
desc: "节点tcp 重传的报文数"
- record: node:tcp:timewait
expr: node_sockstat_TCP_tw{job="nodes"}
labels:
job: "nodes"
unit: "个"
desc: "节点tcp 等待关闭的连接数"
- record: node:tcp:used
expr: node_sockstat_sockets_used{job="nodes"}
labels:
job: "nodes"
unit: "个"
desc: "节点已使用的所有协议套接字总量"
- record: node:tcp:alloc
expr: node_sockstat_TCP_alloc{job="nodes"}
labels:
job: "nodes"
unit: "个"
desc: "节点已分配的tcp套接字数量"
#process
- record: node:process:running
expr: node_procs_running{job="nodes"}
labels:
job: "nodes"
unit: "个"
desc: "节点当前运行队列的任务的数量"
- record: node:process:blocked
expr: node_procs_blocked{job="nodes"}
labels:
job: "nodes"
unit: "个"
desc: "节点当前被阻塞的任务的数量"
#other
- record: node:time:offset
expr: abs(node_timex_offset_seconds{job="nodes"})
labels:
job: "nodes"
unit: s
desc: "节点的时间偏差"
/usr/local/prometheus/promtool check rules /usr/local/prometheus/rules/node-record-rules.yml #检查规则文件语法
Checking /usr/local/prometheus/rules/node-record-rules.yml
SUCCESS: 71 rules found1.3 告警规则配置:
告警规则可以基于PromQL表达式定义告警条件,并将有关激发告警的通知发送到外部服务。只要告警表达式在给定的时间点产生一个或多个向量元素,告警就被视为对这些元素的标签集有效。
告警规则在Prometheus中的配置方式与记录规则相同
vim /usr/local/prometheus/rules/node-alert-rules.yml
groups:
- name: node-alert
rules:
- alert: NodeDown
expr: up{job="nodes"} == 0
for: 5m
labels:
severity: critical
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} down"
description: "Instance: {{ $labels.instance }} 已经宕机 5分钟"
value: "{{ $value }}"
- alert: NodeCpuHigh
expr: (1 - avg by (instance) (irate(node_cpu_seconds_total{job="nodes",mode="idle"}[5m]))) * 100 > 80
for: 5m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} cpu使用率过高"
description: "CPU 使用率超过 80%"
value: "{{ $value }}"
- alert: NodeCpuIowaitHigh
expr: avg by (instance) (irate(node_cpu_seconds_total{job="nodes",mode="iowait"}[5m])) * 100 > 50
for: 5m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} cpu iowait 使用率过高"
description: "CPU iowait 使用率超过 50%"
value: "{{ $value }}"
- alert: NodeLoad5High
expr: node_load5 > (node:cpu:num) * 1.2
for: 5m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} load(5m) 过高"
description: "Load(5m) 过高,超出cpu核数 1.2倍"
value: "{{ $value }}"
- alert: NodeMemoryHigh
expr: (1 - node_memory_MemAvailable_bytes{job="nodes"} / node_memory_MemTotal_bytes{job="nodes"}) * 100 > 90
for: 5m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} memory 使用率过高"
description: "Memory 使用率超过 90%"
value: "{{ $value }}"
- alert: NodeDiskRootHigh
expr: (1 - node_filesystem_avail_bytes{job="nodes",fstype=~"ext.*|xfs",mountpoint ="/"} / node_filesystem_size_bytes{job="nodes",fstype=~"ext.*|xfs",mountpoint ="/"}) * 100 > 90
for: 10m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk(/ 分区) 使用率过高"
description: "Disk(/ 分区) 使用率超过 90%"
value: "{{ $value }}"
- alert: NodeDiskBootHigh
expr: (1 - node_filesystem_avail_bytes{job="nodes",fstype=~"ext.*|xfs",mountpoint ="/boot"} / node_filesystem_size_bytes{job="nodes",fstype=~"ext.*|xfs",mountpoint ="/boot"}) * 100 > 80
for: 10m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk(/boot 分区) 使用率过高"
description: "Disk(/boot 分区) 使用率超过 80%"
value: "{{ $value }}"
- alert: NodeDiskReadHigh
expr: irate(node_disk_read_bytes_total{job="nodes"}[5m]) > 20 * (1024 ^ 2)
for: 5m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk 读取字节数 速率过高"
description: "Disk 读取字节数 速率超过 20 MB/s"
value: "{{ $value }}"
- alert: NodeDiskWriteHigh
expr: irate(node_disk_written_bytes_total{job="nodes"}[5m]) > 20 * (1024 ^ 2)
for: 5m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk 写入字节数 速率过高"
description: "Disk 写入字节数 速率超过 20 MB/s"
value: "{{ $value }}"
- alert: NodeDiskReadRateCountHigh
expr: irate(node_disk_reads_completed_total{job="nodes"}[5m]) > 3000
for: 5m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk iops 每秒读取速率过高"
description: "Disk iops 每秒读取速率超过 3000 iops"
value: "{{ $value }}"
- alert: NodeDiskWriteRateCountHigh
expr: irate(node_disk_writes_completed_total{job="nodes"}[5m]) > 3000
for: 5m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk iops 每秒写入速率过高"
description: "Disk iops 每秒写入速率超过 3000 iops"
value: "{{ $value }}"
- alert: NodeInodeRootUsedPercentHigh
expr: (1 - node_filesystem_files_free{job="nodes",fstype=~"ext4|xfs",mountpoint="/"} / node_filesystem_files{job="nodes",fstype=~"ext4|xfs",mountpoint="/"}) * 100 > 80
for: 10m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk(/ 分区) inode 使用率过高"
description: "Disk (/ 分区) inode 使用率超过 80%"
value: "{{ $value }}"
- alert: NodeInodeBootUsedPercentHigh
expr: (1 - node_filesystem_files_free{job="nodes",fstype=~"ext4|xfs",mountpoint="/boot"} / node_filesystem_files{job="nodes",fstype=~"ext4|xfs",mountpoint="/boot"}) * 100 > 80
for: 10m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk(/boot 分区) inode 使用率过高"
description: "Disk (/boot 分区) inode 使用率超过 80%"
value: "{{ $value }}"
- alert: NodeFilefdAllocatedPercentHigh
expr: node_filefd_allocated{job="nodes"} / node_filefd_maximum{job="nodes"} * 100 > 80
for: 10m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} filefd 打开百分比过高"
description: "Filefd 打开百分比 超过 80%"
value: "{{ $value }}"
- alert: NodeNetworkNetinBitRateHigh
expr: avg by (instance) (irate(node_network_receive_bytes_total{device=~"eth0|eth1|ens33|ens37"}[1m]) * 8) > 20 * (1024 ^ 2) * 8
for: 3m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} network 接收比特数 速率过高"
description: "Network 接收比特数 速率超过 20MB/s"
value: "{{ $value }}"
- alert: NodeNetworkNetoutBitRateHigh
expr: avg by (instance) (irate(node_network_transmit_bytes_total{device=~"eth0|eth1|ens33|ens37"}[1m]) * 8) > 20 * (1024 ^ 2) * 8
for: 3m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} network 发送比特数 速率过高"
description: "Network 发送比特数 速率超过 20MB/s"
value: "{{ $value }}"
- alert: NodeNetworkNetinPacketErrorRateHigh
expr: avg by (instance) (irate(node_network_receive_errs_total{device=~"eth0|eth1|ens33|ens37"}[1m])) > 15
for: 3m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} 接收错误包 速率过高"
description: "Network 接收错误包 速率超过 15个/秒"
value: "{{ $value }}"
- alert: NodeNetworkNetoutPacketErrorRateHigh
expr: avg by (instance) (irate(node_network_transmit_packets_total{device=~"eth0|eth1|ens33|ens37"}[1m])) > 15
for: 3m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} 发送错误包 速率过高"
description: "Network 发送错误包 速率超过 15个/秒"
value: "{{ $value }}"
- alert: NodeProcessBlockedHigh
expr: node_procs_blocked{job="nodes"} > 10
for: 10m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} 当前被阻塞的任务的数量过多"
description: "Process 当前被阻塞的任务的数量超过 10个"
value: "{{ $value }}"
- alert: NodeTimeOffsetHigh
expr: abs(node_timex_offset_seconds{job="nodes"}) > 3 * 60
for: 2m
labels:
severity: info
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} 时间偏差过大"
description: "Time 节点的时间偏差超过 3m"
value: "{{ $value }}"
/usr/local/prometheus/promtool check rules /usr/local/prometheus/rules/node-alert-rules.yml #检查规则文件语法
Checking /usr/local/prometheus/rules/node-alert-rules.yml
SUCCESS: 20 rules found1.4 将规则文件加入配置:
vim /usr/local/prometheus/prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- "10.0.0.15:9093"
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "rules/*rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['10.0.0.14:9090']
- job_name: 'nodes'
static_configs:
- targets:
- "10.0.0.14:9100"
- "10.0.0.15:9100"
- "10.0.0.16:9100"
- job_name: 'alertmanagers'
static_configs:
- targets:
- "10.0.0.15:9100"
# 授权
chown -R prometheus:prometheus /usr/local/prometheus
# 再次检查配置
[root@prometheus-server prometheus]# promtool check config prometheus.yml
Checking prometheus.yml
SUCCESS: 2 rule files found
Checking rules/node-alert-rules.yml
SUCCESS: 20 rules found
Checking rules/node-record-rules.yml
SUCCESS: 71 rules found
# 重启prometheus
systemctl restart prometheus访问prometheus页面,Status → Rules,
可以看到,上面配置的规则已经生效,状态是OK,说明规则正常。
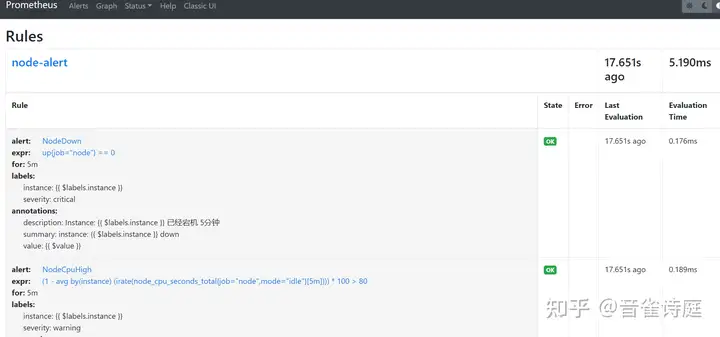
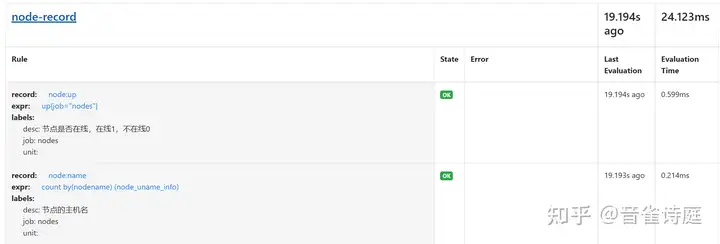
二、告警测试
规则配置完成之后,可以进行告警测试,进而修改规则,最终达到想要的监控告警效果。
2.1 邮件告警配置:
vim /usr/local/alertmanager/alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.163.com:465' # 邮箱smtp服务器代理,启用SSL发信, 端口一般是465
smtp_from: 'alert@163.com' # 发送邮箱名称
smtp_auth_username: 'alert@163.com' # 邮箱名称
smtp_auth_password: 'password' # 邮箱密码或授权码
smtp_require_tls: false
route:
receiver: 'default'
group_wait: 10s
group_interval: 1m
repeat_interval: 1h
group_by: ['alertname']
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'instance']
receivers:
- name: 'default'
email_configs:
- to: 'receiver@163.com'
send_resolved: true #告警恢复时发送通知
# 重启alertmanager
systemctl restart alertmanager2.1.1 测试节点down:
这里选择grafana节点10.0.0.16,关闭其上的node_exporter,模拟宕机。
netstat -lntp | grep node_exporter
tcp6 0 0 :::9100 :::* LISTEN 13505/node_exporter
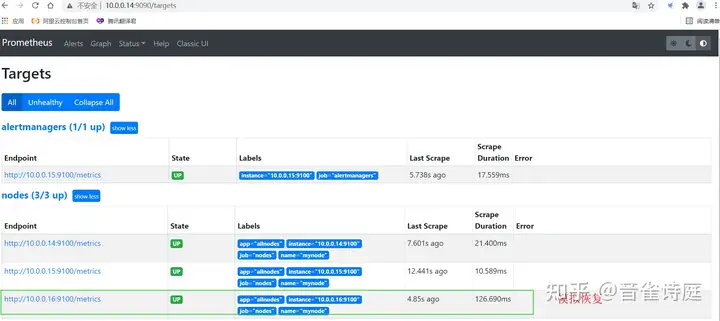
systemctl stop node_exporter访问prometheus页面,Status → Targets,
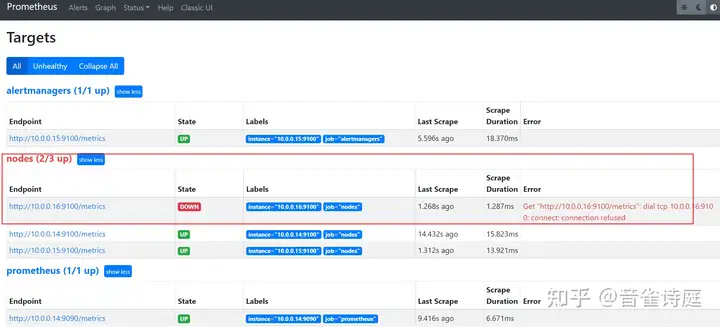
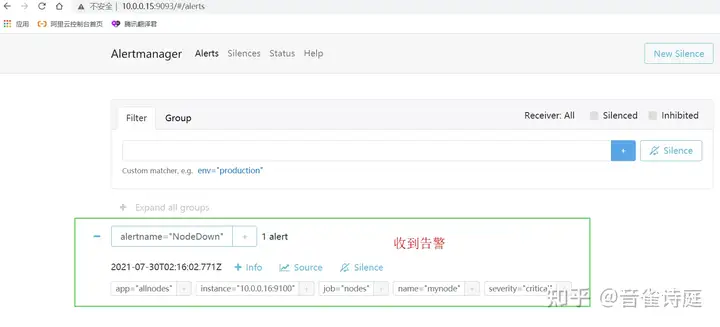
访问altermanager页面,查看当前存在的告警,
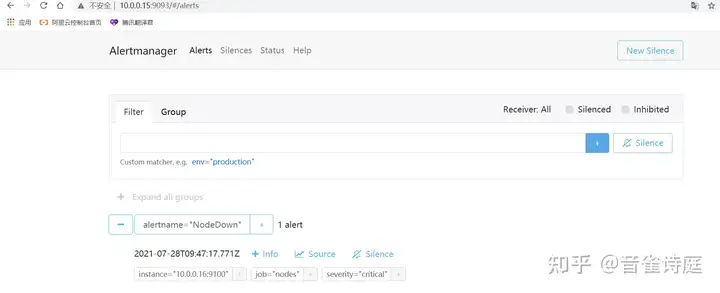
等待5分钟,查看邮件,

重启node_exporter,模拟机器重启,
systemctl start node_exporter
netstat -lntp | grep node_exporter
tcp6 0 0 :::9100 :::* LISTEN 25181/node_exporter访问prometheus页面,Status → Targets,
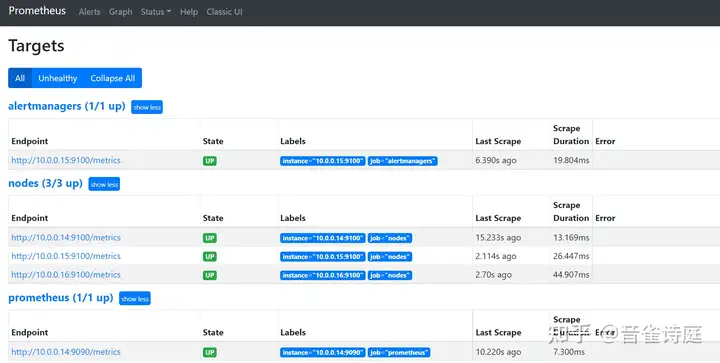
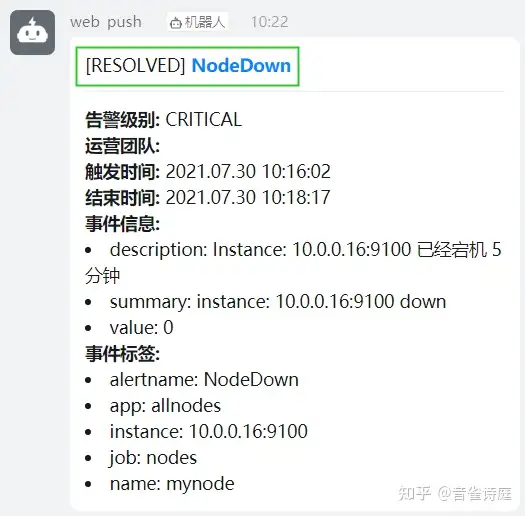
收到恢复邮件,
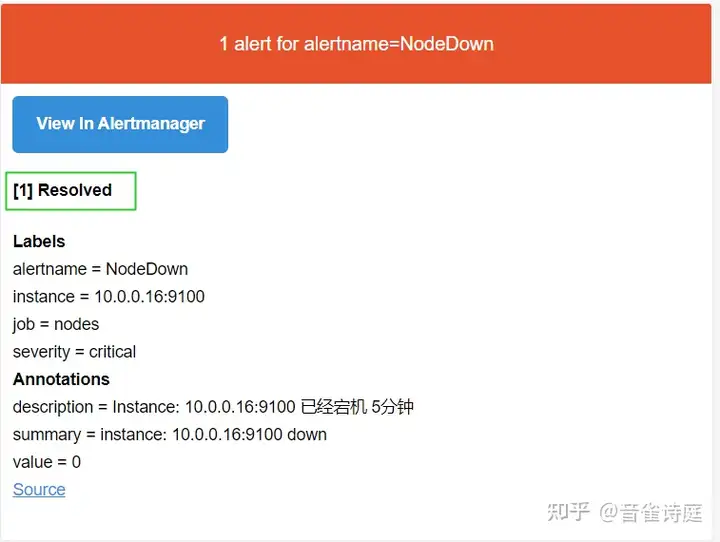
可以看到,整个邮件告警正常,测试节点down完成。
2.2 配置钉钉告警
仅仅是邮件告警还不够,重要信息应由钉钉告警。
2.2.1 安装prometheus-webhook-dingtalk插件并设置配置文件
# 下载插件
wget https://github.com/timonwong/prometheus-webhook-dingtalk/releases/download/v1.4.0/prometheus-webhook-dingtalk-1.4.0.linux-amd64.tar.gz
# 解压
tar -xf prometheus-webhook-dingtalk-1.4.0.linux-amd64.tar.gz -C /usr/local/
# 重命名
cd /usr/local/ && mv prometheus-webhook-dingtalk-1.4.0.linux-amd64 dingtalk
# 修改配置文件
cd dingtalk && mv config.example.yml config.yml
vim config.yml
# 目录位置 /usr/local/
# 整理目录结构
dingtalk
├── config.yml
├── LICENSE
├── prometheus-webhook-dingtalk
└── templates
└── ding.tmplconfig.yml
## Request timeout
# timeout: 5s
## Customizable templates path
templates:
- templates/ding.tmpl
## You can also override default template using `default_message`
## The following example to use the 'legacy' template from v0.3.0
# default_message:
# title: '{{ template "legacy.title" . }}'
# text: '{{ template "legacy.content" . }}'
## Targets, previously was known as "profiles"
targets:
webhook1:
url: https://oapi.dingtalk.com/robot/send?access_token=xxxxx
# secret for signature
secret: SEC3XXXXX
# webhook2:
# url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxx
# webhook_legacy:
# url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxx
# Customize template content
message:
# Use legacy template
title: '{{ template "ding.link.title" . }}'
text: '{{ template "ding.link.content" . }}'
# webhook_mention_all:
# url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxx
# mention:
# all: true
# webhook_mention_users:
# url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxx
# mention:
# mobiles: ['156xxxx8827', '189xxxx8325']
# 说明,这里测试只配置了一个webhook
# 实际生活环境需要配置多个ding.tmpl
{{ define "__subject" }}[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}] {{ .GroupLabels.SortedPairs.Values | join " " }} {{ if gt (len .CommonLabels) (len .GroupLabels) }}({{ with .CommonLabels.Remove .GroupLabels.Names }}{{ .Values | join " " }}{{ end }}){{ end }}{{ end }}
{{ define "__alertmanagerURL" }}{{ .ExternalURL }}/#/alerts?receiver={{ .Receiver }}{{ end }}
{{ define "__text_alert_list" }}{{ range . }}
**Labels**
{{ range .Labels.SortedPairs }} - {{ .Name }}: {{ .Value | markdown | html }}
{{ end }}
**Annotations**
{{ range .Annotations.SortedPairs }} - {{ .Name }}: {{ .Value | markdown | html }}
{{ end }}
**Source:** [{{ .GeneratorURL }}]({{ .GeneratorURL }})
{{ end }}{{ end }}
{{ define "default.__text_alert_list" }}{{ range . }}
---
**告警级别:** {{ .Labels.severity | upper }}
**运营团队:** {{ .Labels.team | upper }}
**触发时间:** {{ dateInZone "2006.01.02 15:04:05" (.StartsAt) "Asia/Shanghai" }}
**事件信息:**
{{ range .Annotations.SortedPairs }} - {{ .Name }}: {{ .Value | markdown | html }}
{{ end }}
**事件标签:**
{{ range .Labels.SortedPairs }}{{ if and (ne (.Name) "severity") (ne (.Name) "summary") (ne (.Name) "team") }} - {{ .Name }}: {{ .Value | markdown | html }}
{{ end }}{{ end }}
{{ end }}
{{ end }}
{{ define "default.__text_alertresovle_list" }}{{ range . }}
---
**告警级别:** {{ .Labels.severity | upper }}
**运营团队:** {{ .Labels.team | upper }}
**触发时间:** {{ dateInZone "2006.01.02 15:04:05" (.StartsAt) "Asia/Shanghai" }}
**结束时间:** {{ dateInZone "2006.01.02 15:04:05" (.EndsAt) "Asia/Shanghai" }}
**事件信息:**
{{ range .Annotations.SortedPairs }} - {{ .Name }}: {{ .Value | markdown | html }}
{{ end }}
**事件标签:**
{{ range .Labels.SortedPairs }}{{ if and (ne (.Name) "severity") (ne (.Name) "summary") (ne (.Name) "team") }} - {{ .Name }}: {{ .Value | markdown | html }}
{{ end }}{{ end }}
{{ end }}
{{ end }}
{{/* Default */}}
{{ define "default.title" }}{{ template "__subject" . }}{{ end }}
{{ define "default.content" }}#### \[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}\] **[{{ index .GroupLabels "alertname" }}]({{ template "__alertmanagerURL" . }})**
{{ if gt (len .Alerts.Firing) 0 -}}
{{ template "default.__text_alert_list" .Alerts.Firing }}
{{- end }}
{{ if gt (len .Alerts.Resolved) 0 -}}
{{ template "default.__text_alertresovle_list" .Alerts.Resolved }}
{{- end }}
{{- end }}
{{/* Legacy */}}
{{ define "legacy.title" }}{{ template "__subject" . }}{{ end }}
{{ define "legacy.content" }}#### \[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}\] **[{{ index .GroupLabels "alertname" }}]({{ template "__alertmanagerURL" . }})**
{{ template "__text_alert_list" .Alerts.Firing }}
{{- end }}
{{/* Following names for compatibility */}}
{{ define "ding.link.title" }}{{ template "default.title" . }}{{ end }}
{{ define "ding.link.content" }}{{ template "default.content" . }}{{ end }}编辑systemd文件管理prometheus-webhook-dingtalk
[Unit]
Description=Prometheus-webhook-dingtalk
Documentation=https://github.com/timonwong/prometheus-webhook-dingtalk/
After=network.target
[Service]
WorkingDirectory=/usr/local/dingtalk/
ExecStart=/usr/local/dingtalk/prometheus-webhook-dingtalk --config.file=config.yml --web.enable-ui
ExecReload=/bin/kill -HUP $MAINPID
ExecStop=/bin/kill -KILL $MAINPID
Type=simple
KillMode=control-group
Restart=on-failure
RestartSec=15s
[Install]
WantedBy=multi-user.target
# 1 设置软链接
ln -s /usr/local/dingtalk/prometheus-webhook-dingtalk /usr/bin/prometheus-webhook-dingtalk
# 2 重载配置文件
systemctl daemon-reload
# 设置开机启动并启动prometheus-webhook-dingtalk
systemctl enable prometheus-webhook-dingtalk && systemctl start prometheus-webhook-dingtalk
# 3 查看运行状态
[root@altermanager dingtalk]# systemctl status prometheus-webhook-dingtalk
● prometheus-webhook-dingtalk.service - Prometheus-webhook-dingtalk
Loaded: loaded (/usr/lib/systemd/system/prometheus-webhook-dingtalk.service; enabled; vendor preset: disabled)
Active: active (running) since 五 2021-07-30 09:50:23 CST; 6s ago
Docs: https://github.com/timonwong/prometheus-webhook-dingtalk/
Main PID: 11923 (prometheus-webh)
Tasks: 8
Memory: 6.6M
CGroup: /system.slice/prometheus-webhook-dingtalk.service
└─11923 /usr/local/dingtalk/prometheus-webhook-dingtalk --config.file=config.yml --web.enable-ui
# 4 查看端口
[root@altermanager dingtalk]# netstat -tnlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp6 0 0 :::8060 :::* LISTEN 11923/prometheus-we
# 5 命令行测试--注意链接里的webhook1 如果配置文件里的是webhook2则这里必须是webhook2
curl http://localhost:8060/dingtalk/webhook1/send -H 'Content-Type: application/json' -d '{"msgtype": "text","text": {"content": "监控告警"}}'
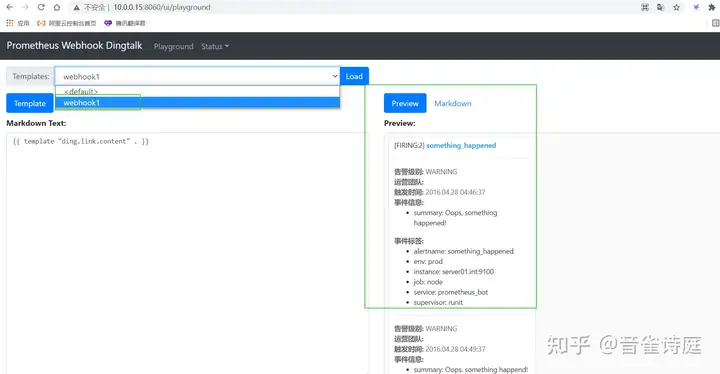
OK浏览器访问hostip:8060/ui 看到如下截图则配置成功
2.2.2 修改alertmanager配置文件
alertmanager.yml
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 10m
receiver: 'webhook1'
receivers:
- name: 'webhook1'
webhook_configs:
# 注意,这里的URL链接里的webhook1必须与上面config.yml里的webhook1名称相同否则无法发送报警
- url: 'http://10.0.0.15:8060/dingtalk/webhook1/send'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
# 重启alertmanager
systemctl restart alertmanager
# 停掉一个node_exporter模拟主机宕机
systemctl stop node_exporter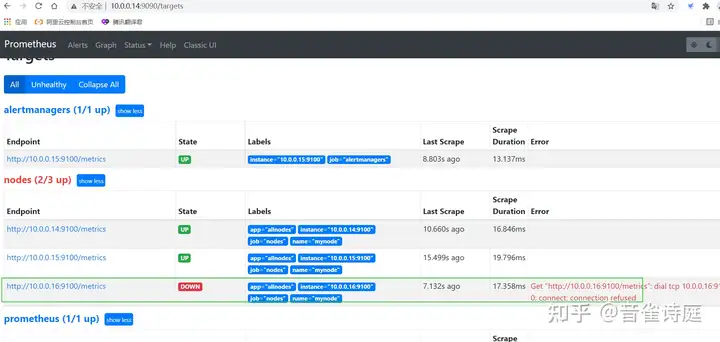
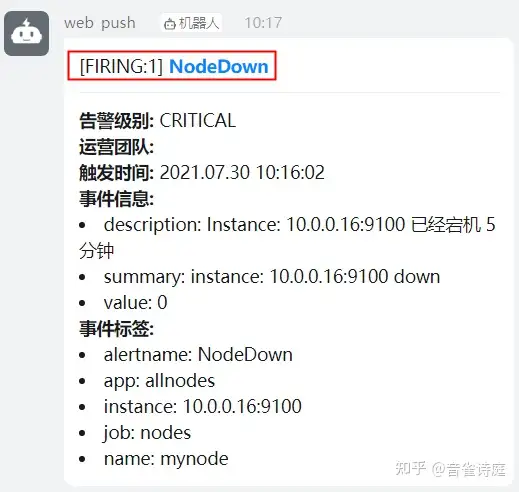
收到恢复警告,因为前面配置文件里设置了 send_resolved: true 如果设置false则不会收到警告
至此,钉钉告警配置完毕
2.3 配置企业微信告警
修改alertmanager.yml文件,配置报警信息,alertmanager.yml 内容如下:
global:
resolve_timeout: 5m
templates: #告警模板
- './template/wechat.tmpl'
route: # 设置报警分发策略
group_by: ['alertname'] # 分组标签
group_wait: 10s # 告警等待时间。告警产生后等待10s,如果有同组告警一起发出
group_interval: 10s # 两组告警的间隔时间
repeat_interval: 1m # 重复告警的间隔时间,减少相同右键的发送频率 此处为测试设置为1分钟
receiver: 'wechat' # 默认接收者
receivers:
- name: 'wechat'
wechat_configs:
- send_resolved: true
agent_id: '1000002' # 自建应用的agentId
to_user: '*****' # 接收告警消息的人员Id
api_secret: '******' # 自建应用的secret
corp_id: '******' # 企业ID
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']wechat.tmpl
{{ define "wechat.default.message" }}
{{ range .Alerts }}
========监控报警==========
告警状态:{{ .Status }}
告警级别:{{ .Labels.severity }}
告警类型:{{ .Labels.alertname }}
告警应用:{{ .Annotations.summary }}
告警主机:{{ .Labels.instance }}
告警详情:{{ .Annotations.description }}
触发阀值:{{ .Annotations.value }}
告警时间:{{ .StartsAt.Format "2006-01-02 15:04:05" }}
========end=============
{{ end }} {{ end }}
 浙公网安备 33010602011771号
浙公网安备 33010602011771号