【计算机网络-应用层】万维网
1 统一资源定位符 URL
统一资源定位符(Uniform Resource Locator,URL)
格式:<协议>://<主机>:<端口>/<路径>(端口和路径有时可省略,URL 不区分大小写)
例如:
- 使用 HTTP 协议访问 Web 服务器:
http://www.abc.com:80/dir/file1.htm - 使用 FTP 协议下载和上传文件:
ftp://ftp.abc.com:21/dir/file1.htm - 读取计算机本地文件:
file://localhost/d:/mydir/file1.zip
省略文件名的情况:
http://www.abc.com/dir/:服务器会预先设置好文件名省略时要访问的默认文件。该 URL 实质是访问了/dir/index.html或/dir/default.htmhttp://www.abc.com/:该 URL 实质是访问了/index.html或/default.htmhttp://www.abc.com:该 URL 实质也是访问了/index.html或/default.htm
2 万维网文档
万维网文档分为三种:
- 超文本标记语言(HyperText Markup Language,HTML):使用多种“标签”来描述网页的结构和内容
- 层叠样式表(Cascading Style Sheets,CSS):从审美的角度来描述网页的样式
- JavaScript:一种脚本语言,控制网页的行为
2.1 超文本标记语言 HTML
demo.html:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>最简单的网页</title>
</head>
<body>
<p>Hello world</p >
</body>
</html>
2.2 层叠样式表 CSS
demo.html:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>最简单的网页</title>
<link rel="stylesheet" type="text/css" href="demo.css" />
</head>
<body>
<p class="pink">Hello world</p>
</body>
</html>
demo.css:
.pink {
color: deeppink;
font-size: 36px;
}
2.3 JavaScript
demo.html:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>最简单的网页</title>
<link rel="stylesheet" type="text/css" href="demo.css" />
<script type="text/javascript" src="demo.js"></script>
</head>
<body>
<p class="pink" id="myId">Hello world</p >
<button type="button" onclick="myFunction()">点个赞吧</button>
</body>
</html>
demo.js:
function myFunction() {
document.getElementById("myId").innerHTML="谢谢你的赞”;
}
3 超文本传输协议 HTTP
超文本传输协议(HyperText Transfer Protocol,HTTP):定义浏览器(即万维网客户进程)怎样向万维网服务器请求万维网文档,以及万维网服务器怎样把万维网文档传送给浏览器。它基于 TCP 协议,端口号为 80。
3.1 HTTP 报文格式
HTTP 是面向文本的,其报文中的每一个字段都是一些 ASCII 码串,并且每个字段的长度都是不确定的。
统一资源定位符(Uniform Resource Identifier):一个存放网页数据的文件名或一个 CGI 程序的文件名,例如/dir1/file1.html和/dir1/program1.cgi。
3.1.1 HTTP 请求报文
- 请求报文格式:
<方法><空格><URI><空格><HTTP版本> // 请求行:可大致了解请求的内容
<首部字段名>:<字段值> // 消息头:请求的附加消息
...
...
<首部字段名>:<字段值>
<消息主体> // 消息体:包含客户端向服务端发送的数据,请求报文不一定存在该字段
【注】每条请求消息只能写 1 个 URI,所以每次只能获取 1 个文件,如果需要多次获取文件,必须对每个文件单独发送 1 条请求。比如 1 个网页包含 3 张图片,那么获取网页加上获取图片,一共需要向服务器发送 4 次请求。
- HTTP 的主要方法:
| 方法 | 含义 |
|---|---|
| GET | 请求 URI 指定的信息。如果 URI 指定的是文件,则返回文件的内容;如果指定的是 CGI 程序,则返回该程序输出的数据 |
| POST | 从客户端向服务器发送数据。一般用于发送表单中填写数据等情况 |
| HEAD | 只返回 HTTP 的消息头,并不返回数据内容。用于获取文件最后更新时间等属性信息 |
| CONNECT | 用于代理服务器 |
3.1.2 HTTP 响应报文
- 响应报文格式:
<HTTP版本><空格><状态码><空格><响应短语> // 状态行
<首部字段名>:<字段值> // 消息头
...
...
<首部字段名>:<字段值>
<消息主体> // 消息体:包含服务端向客户端发送的数据,响应报文不一定存在该字段
- HTTP 状态码:
| 状态码(共 33 种) | 含义 |
|---|---|
| 1xx | 告知请求的处理进度和情况 |
| 2xx | 表示成功,如接受或表示知道了 |
| 3xx | 重定向,表示需要进一步操作 |
| 4xx | 客户端错误,如请求中有错误的语法 |
| 5xx | 服务器错误,如服务器失效无法完成请求 |
3.2 HTTP 的工作过程
3.2.1 HTTP/1.0
HTTP/1.0 采用非持续连接方式。在该方式下,每次浏览器要请求一个文件都要与服务器建立 TCP 连接,当收到响应后就立即关闭连接。
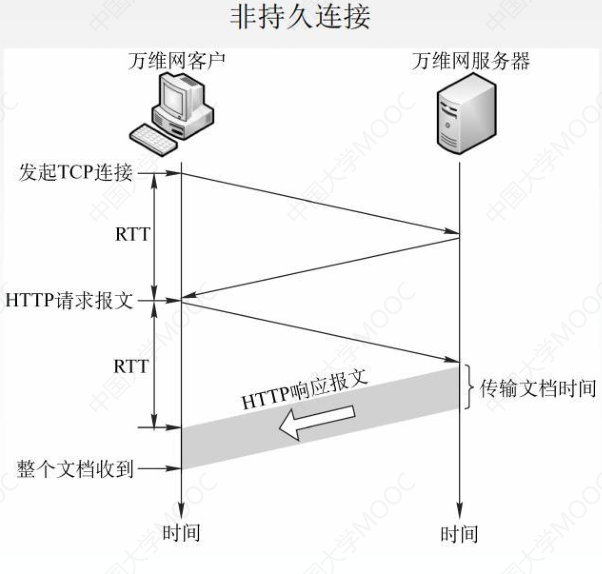
- 每请求一个文档就要有两倍的 RTT 的开销。若一个网页上有很多引用对象(例如图片等),那么请求每一个对象都需要花费 2RTT 的时间。
- 为了减小时延,浏览器通常会建立多个并行的 TCP 连接同时请求多个对象。但是,这会大量占用万维网服务器的资源,特别是万维网服务器往往要同时服务于大量客户的请求,这会使其负担很重。
3.2.2 HTTP/1.1
HTTP/1.1 采用持续连接方式。在该方式下,万维网服务器在发送响应后仍然保持这条连接,使同一个客户(浏览器)和该服务器可以继续在这条连接上传送后续的 HTTP 请求报文和响应报文。这并不局限于传送同一个页面上引用的对象,而是只要这些文档都在同一个服务器上就行。

持续连接方式还分为两种:
- 非流水线(即上图):客户端在收到前一个响应后才能发出下一个请求。
- 流水线:HTTP/1.1 的默认方式。客户端可以连续发送多个请求而不必等待响应。
以下例子说明持续连接方式的工作过程(图片源自《网络是怎样连接的》)。
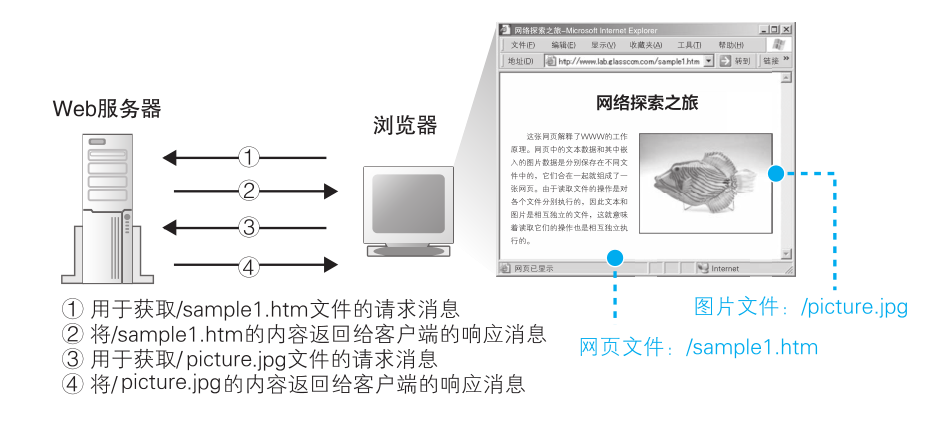
在双方进行 TCP 连接后,进行如下通讯过程:
- 浏览器向 Web 服务器发送请求报文,用于获取 /sample.htm 文件:
GET /sample1.htm HTTP/1.1 // 表示向服务器发送的请求内容的请求行
Accept: */*
Accept-Language: zh
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/4.0 (compatible;【右侧省略】
Host: www.lab.glasscom.com
Connection: Keep-Alive // 持续连接方式
- 服务器将 /sample.htm 的内容返回给客户端,使用响应报文:
HTTP/1.1 200 OK // 状态行,200表示请求成功完成
Date: Wed, 21 Feb 2007 09:19:14 GMT
Server: Apache // 服务程序类型
Last-Modified: Mon, 19 Feb 2007 12:24:51 GMT
ETag: "5a9da-279-3c726b61"
Accept-Ranges: bytes
Content-Length: 632 // 数据长度
Connection: close // 连接关闭
Content-Type: text/html // 以MIME规格表示的数据格式。text/html表示HTML文档。如果是JPEG格式的图片,这里应该是image/jpeg
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<title>网络探索之旅</title>
</head>
<body>
<h1 align="center">网络探索之旅</h1>
<img border="1" src="picture.jpg" align="right" width="200" height="150">
这张网页解释了WWW的工作原理。网页中的文本数据和其中嵌入的图片数据是分别
保存在不同文件中的,它们合在一起就组成了一张网页。由于读取文件的操作是对各
个文件分别执行的,因此文本和图片是相互独立的文件,这就意味着读取它们的操作
也是相互独立执行的。
</body>
</html>
- 浏览器向 Web 服务器发送请求报文,用于获取 /picture.jpg 文件:
GET /picture.jpg HTTP/1.1
Accept: */*
Referer: http://www.lab.glasscom.com/sample1.htm
Accept-Language: zh
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/4.0 (compatible;【右侧省略】
Host: www.lab.glasscom.com
Connection: Keep-Alive // 持续连接方式
- 服务器继续将 /picture.jpg 的内容返回给客户端,使用响应报文:
HTTP/1.1 200 OK
Date: Wed, 21 Feb 2007 09:19:14 GMT
Server: Apache
Last-Modified: Mon, 19 Feb 2007 13:50:32 GMT
ETag: "5a9d1-1913-3aefa236"
Accept-Ranges: bytes
Content-Length: 6419
Connection: close // 连接关闭
Content-Type: image/jpeg
【下面就是图片数据,因为这些数据都是二进制的,所以我们在此省略】
3.2.3 相关例题
【例 1】假设 HTTP1.1 协议以持续的非流水线方式工作,一次请求-响应的时间为 RTT,rfc.html 页面引用了 2 个 JPEG 小图像,则浏览器从开始建立 TCP 连接到收到全部内容为止,需要(4)个 RTT。
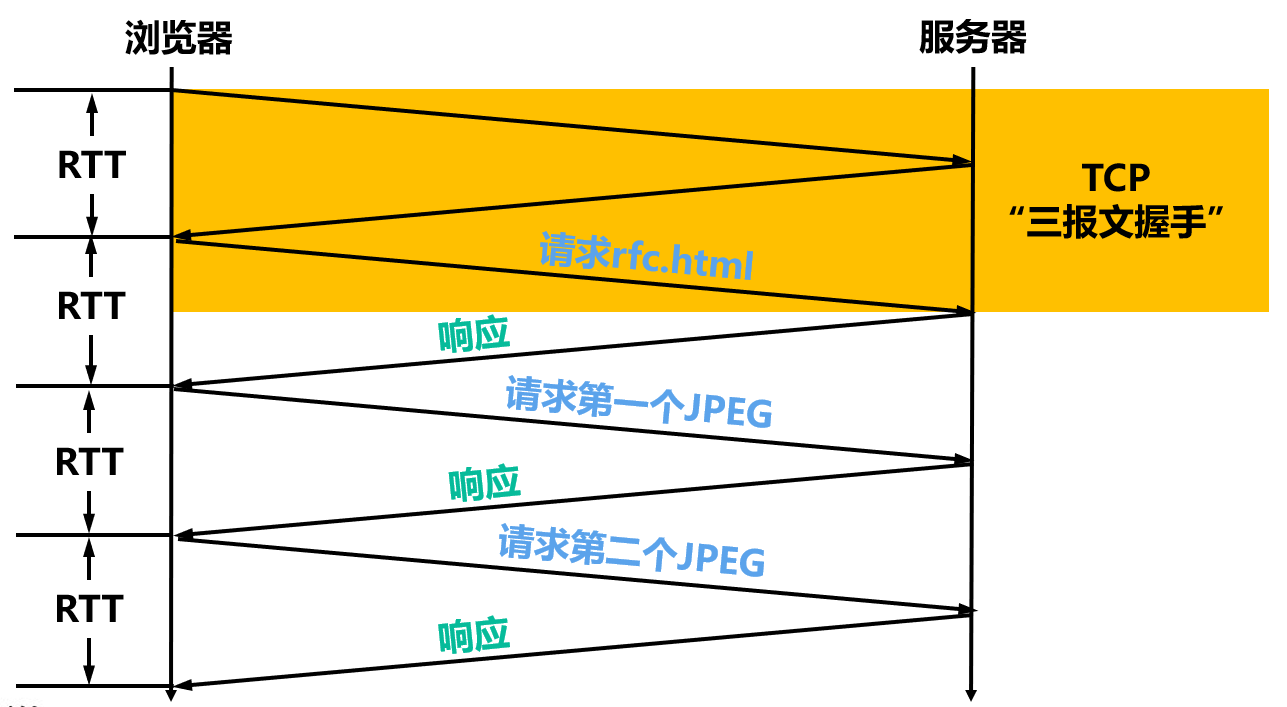
【例 2】假设主机中的浏览器使用 HTTP/1.1 协议以持续的非流水线方式工作,向 Web 服务器请求包含有 3 个 JPEG 小图像的 demo.html 页面,一次请求-响应时间为 RTT,则从发起第一个 Web 请求开始到收到全部内容为止,经过 RTT 的数量为(4)。
4 Cookie
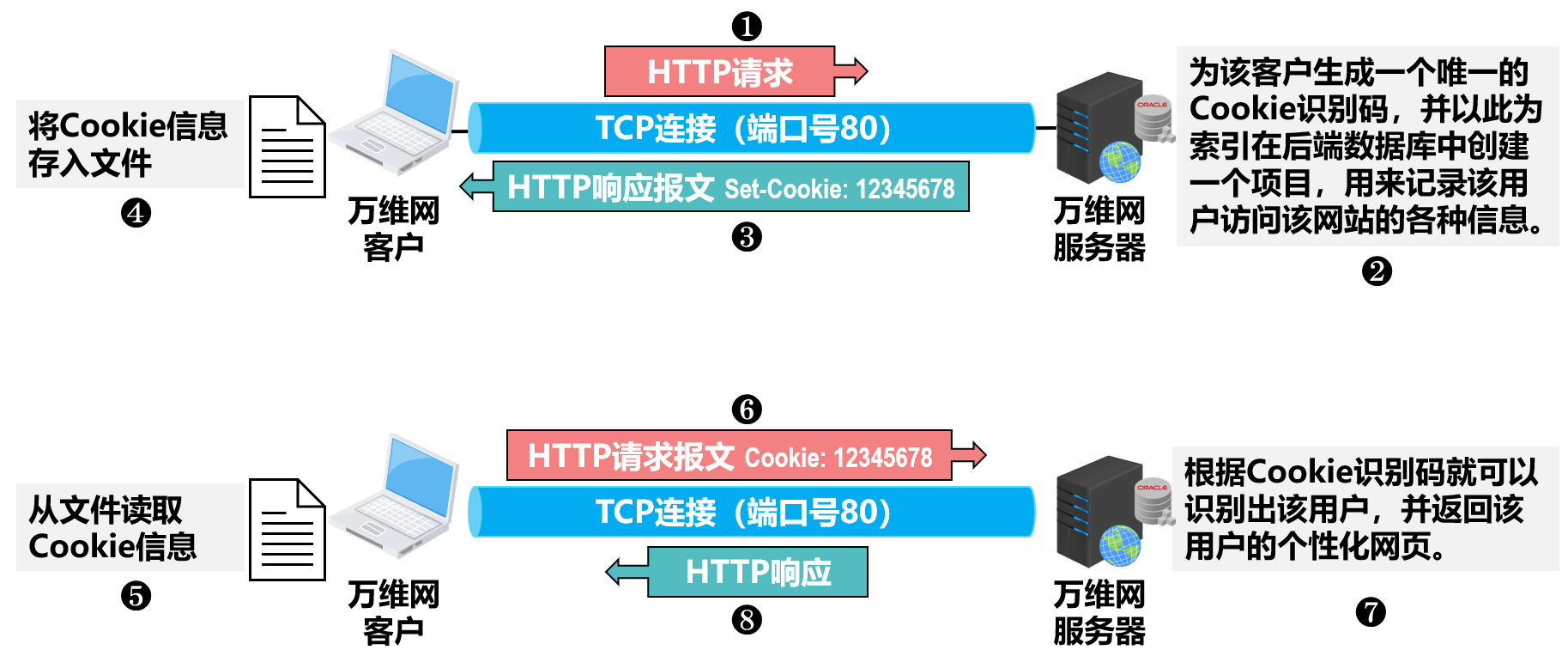
- 早期的万维网应用非常简单,仅仅是用户查看存放在不同服务器上的各种静态的文档。因此 HTTP 被设计为一种无状态的协议。这样可以简化服务器的设计。
- Cookie 提供了一种机制使得万维网服务器能够“记住”用户,而无需用户主动提供用户标识信息。也就是说,Cookie 是一种对无状态的 HTTP 进行状态化的技术。
- Cookie 的工作原理如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号