一个试图了解JVM内存模型的两年经验的初级程序员,透彻!
所有的编程语言中都有内存模型这个概念,区别于微架构的内存模型,高级语言的内存模型包括了编译器和微架构两部分。我试图了解了Java、C#和Go语言的内存模型,发现内容基本大同小异,只是这些语言在具体实现的时候略有不同。
我们来看看Java内存模型吧,提到Java内存模型大家对这个图一定非常熟悉:
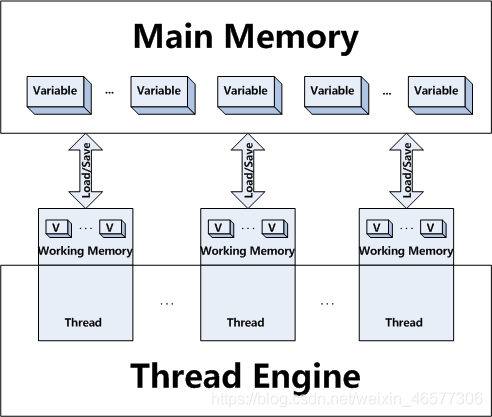
这张图告诉我们在线程运行的时候有一个内存专用的一小块内存,当Java程序会将变量同步到线程所在的内存,这时候会操作工作内存中的变量,而线程中变量的值何时同步回主内存是不可预期的。但同时Java内存模型又告诉我们通过使用关键词“synchronized”或“volatile”可以让Java保证某些约束:
“volatile” — 保证读写的都是主内存的变量
“synchronized” —保证在块开始时都同步主内存的值到工作内存,而块结束时将变量同步回主内存
通过以上描述我们就可以写出线程安全的Java程序,JDK也同时帮我们屏蔽了很多底层的东西。
但当你深入了解JVM的时候你会发现根本就没有工作内存这个东西,即内存中根本不会分配这么一块空间来运行你的Java程序,那么工作内存到底是什么东西呢?
这个问题也曾经困扰了我很长时间,因为我从来没有从JVM的实现中找到过和主内存同步的代码,因为当使用“volatile”时我仅仅能从源代码中调用了这行语句:
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
而这个指令在部分微架构上的主要功能就是防止指令重排,即这条指令前后的其它指令不会越过这个界限执行[注1]。
在现在的x86/x64微架构中读写内存的一致性都是通过MESI(Intel使用MESI-F,AMD使用MOESI)协议保证[注2],MESI的状态转换图如下:
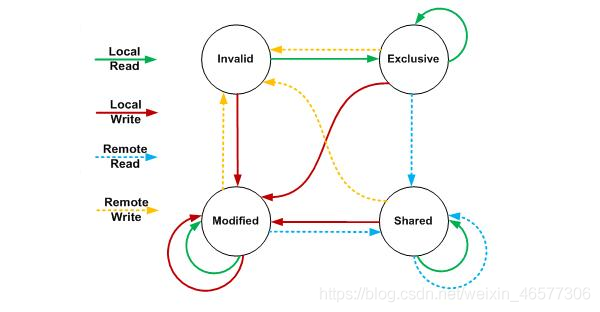
那Java内存模型中所说的工作内存是什么呢?
我的理解是,首先“工作内存”是一个虚拟的概念,而承载这个概念主要是两部分:
1. 编译器
2. 微架构
作为编译器肯定是执行速度越快越好,所以作为编译器应当尽量减少从内存读数据,如果一个数据在寄存器中,那么直接使用寄存器中的值无疑性能是最高的,但同时这也会导致可能读不到最新的值,这里我们通过在Java语言中为变量加上“volatile”强制告诉编译器这个变量一定要从内存获得,这时编译器即不会做此类优化【案例见参考资料5(是一个.Net的例子)】。
对于微架构来说,在x86/x64下,CPU会在执行指令时做指令重排,即编译器生成的指令顺序和真正在CPU执行的顺序可能是不一致的。当我们用一个变量做信号的时候这种指令重排会带来悲剧,即如果有如下代码:
x = 0;
y = 0;
i = 0;
j = 0;
// thread A
y = 1;
x = 1;
// thread B
i = x;
j = y;
上面的代码i和j的值会是多少呢?答案是:“00, 01, 10, 11”都是有可能的。
对于这种情况,如果我们想得到确定的结果则需要通过“synchronized”(或者j.c.u.locks)来做线程间同步。
所以,我个人对Java内存模型的理解是:在编译器各种优化及多种类型的微架构平台上,Java语言规范制定者试图创建一个虚拟的概念并传递到Java程序员,让他们能够在这个虚拟的概念上写出线程安全的程序来,而编译器实现者会根据Java语言规范中的各种约束在不同的平台上达到Java程序员所需要的线程安全这个目的。
最后
私信回复 资料 领取一线大厂Java面试题总结+阿里巴巴泰山手册+各知识点学习思维导+一份300页pdf文档的Java核心知识点总结!
这些资料的内容都是面试时面试官必问的知识点,篇章包括了很多知识点,其中包括了有基础知识、Java集合、JVM、多线程并发、spring原理、微服务、Netty 与RPC 、Kafka、日记、设计模式、Java算法、数据库、Zookeeper、分布式缓存、数据结构等等。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号