

filebeat+kafka+logstash+Elasticsearch+Kibana日志收集系统搭建
原理架构图:
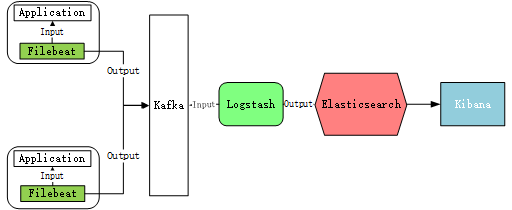
JDK下载:https://www.oracle.com/java/technologies/java-se-glance.html
ES下载:https://www.elastic.co/cn/downloads/elasticsearch
使用规则:
1、不同的业务用不同的topi
2、不同的环境用不通的index-pattern
一、Elasticsearch单机部署
创建elastic用户组及elastic用户
# 注意:elasticsearch不能使用root启动,不然会报错!
]# groupadd elastic
]# useradd elastic -g elastic -p 123456
# 更改elk文件夹及内部文件的所属用户及组为elastic:elastic
]# chown -R elastic:elastic /home/soft/elastic
修改配置:
]# vi elasticsearch.yml
]# network.host: 10.193.196.57
]# discovery.seed_hosts: ["10.193.196.57", "127.0.0.1"]
]# -Xms8g #根据自己服务器环境来配置
]# -Xmx8g
# 新增配置:属于gateway属性,解决跨域问题
http.cors.enabled: true
http.cors.allow-origin: "*"
# 新增配置:(属于Memory属性)
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
# 切换到elastic用户再启动
]# su elastic
]# ./bin/elasticsearch -d ## -d 后台启动
# 虚拟内存数量超标,Linux限制一个进程可访问的VMA(虚拟内存)数量。虚拟内存区域是一个连续的虚拟地址空间区域。在进程的生命周期中,每当程序尝试在内存中映射文件,链接到共享内存段,或者分配堆空间的时候,这些区域将被创建。调优这个值将限制进程可拥有VMA的数量。
# 使用root用户修改/etc/sysctl.conf文件
# 添加内容
]# vim /etc/sysctl.conf
vm.max_map_count = 262144
检查查看
sysctl -p # 配置验证
不添加vm.max_map_count报错如下:

调整ES日志模板
curl -H "Content-Type:application/json" -XPUT http://10.4.xx.xx:9200/_template/k8s -d '{
"template" : "k8s*",
"index_patterns": ["k8s*"],
"settings": {
"number_of_shards": 5,
"number_of_replicas": 0
}
}'
elasticsearch-head
1)源码安装,通过npm run start 启动(不推荐)
2)通过docker安装(推荐)
3)通过chrome插件安装(推荐)
4)通过es的plugin方式安装(不推荐)
二、Logstash单机部署
2.1 下载并解压
~]# wget https://artifacts.elastic.co/downloads/logstash/logstash-7.6.2.tar.gz
~]# tar xf logstash-7.6.2.tar.gz -C /opt/
~]# ln -s logstash-7.6.2 logstash ## 做软链方便后期升级
2.2 配置logstash
~]# vi logstash.conf
input {
kafka {
bootstrap_servers => ["10.193.xx.xx:9098"] ## 填写kafka地址
topics => "filebeat"
group_id => "es"
codec => json
}
}
filter {
grok {
match => {
"message" => "^\[(?<createtime>%{YEAR}[./-]%{MONTHNUM}[./-]%{MONTHDAY}[- ]%{TIME}?)\]\|(?<appname>[-%{WORD}]+?)\|(?<thread>[\w-]+?)\|%{LOGLEVEL:loglevel}"
}
}
date {
match => ["createtime", "yyyy-MM-dd HH:mm:ss"]
target => "@timestamp"
}
mutate{
remove_field => ["beat.name"]
}
}
output {
elasticsearch {
hosts => ["http://10.193.xx.xx:9200"] ##填写es地址
}
}
2.3 启动logstash
nohup ./bin/logstash -f config/logstash.conf & ##后台启动
2.4 logstash数据接受测试:
数据输出到控制台是否正常配置文件中修改ouput部分
#output {
# stdout { codec => rubydebug }
#}
三、zookeeper单机部署
3.1 下载并解压至指定目录
~]# wget http://mirrors.cnnic.cn/apache/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
~]# tar xf zookeeper-3.4.14.tar.gz -C /opt/
~]# ln -s zookeeper-3.4.14 zookeeper
3.2 修改配置文件
~]# cp zoo_sample.cfg zoo.cfg
3.3 启动es
./bin/zkServer.sh start ## 自带启动脚本
四、kafka单机部署
4.1 下载并解压指定目录
~]# wget http://mirror.apache-kr.org/kafka/2.1.0/kafka_2.13-2.4.1.tgz
~]# tar xf kafka_2.13-2.4.1.tar.gz -C /opt/
~]# ln -s kafka_2.13-2.4.1 kafka
4.2 修改配置
listeners=PLAINTEXT://:9098 ##修改端口
zookeeper.connect=10.193.196.57:2188 ## 指定zk地址
log.dirs=/opt/soft/logs/kafka/kafka-logs ## 修改日志路径
4.3 启动kafka
./bin/kafka-server-start.sh ## 自带启动脚本
4.4 创建topic
~]# ./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic topic_name
## 通过zk客户端连接验证
~]# ./bin/zkCli.sh -server 10.193.xx.xx:2188
[zk: 10.193.xx.xx:2188(CONNECTED) 3] ls /brokers/topics
五、kibana单机部署
5.1 下载并解压至指定目录
~]# wget https://artifacts.elastic.co/downloads/kibana/kibana-7.6.2-linux-x86_64.tar.gz
~]# tar -zxvf kibana-6.4.0-linux-x86_64.tar.gz -C /opt/
~]# ln -s kibana-6.4.0-linux-x86_64 kibana
5.2 修改主配置文件
~]# vim config/kibana.yml ## 修改内容如下
server.port: 5601
server.host: "192.168.xx.xx"
server.name: "kibana94"
elasticsearch.url: "http://192.168.0.94:9200" ## 指定es地址
5.3 启动kibana
~]# nohup ./bin/kibana & ## 后台启动
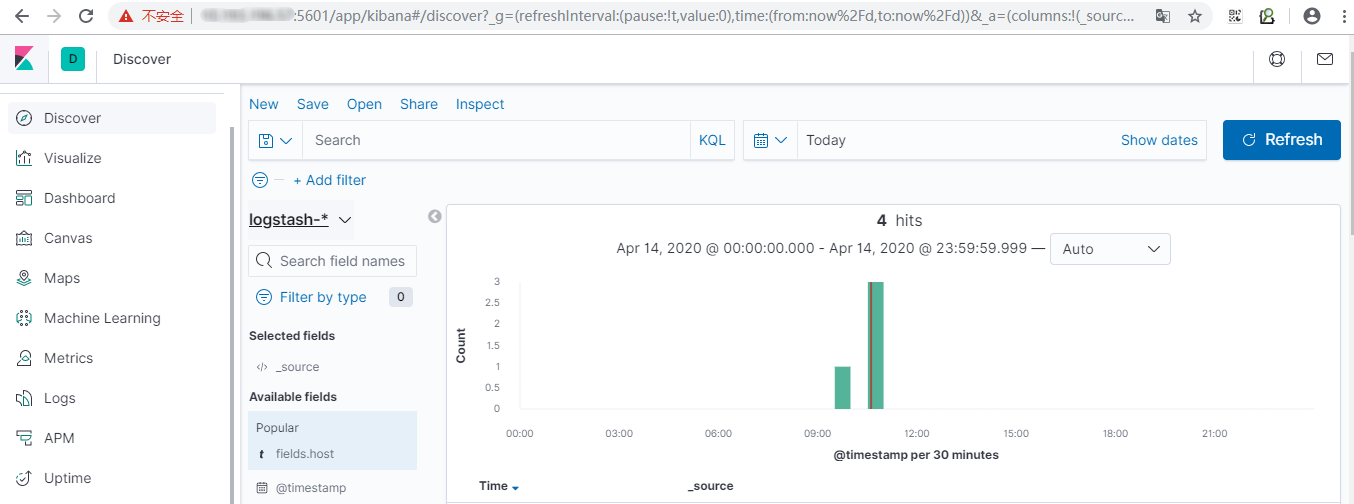
5.4 验证访问

 浙公网安备 33010602011771号
浙公网安备 33010602011771号