Introduction of RL(DRL)
What is RL?
Alpha Go
在棋谱中记录的是不是最优答案,我们如何获得呢?
supervise learing做不到(CNN可以得到目前棋局局势)
RL--人类也不知道答案是什么
Machine Learing ~ Looking for Function
ML has three steps:
1.function with unknown
2.define loss from training data
3.optimization
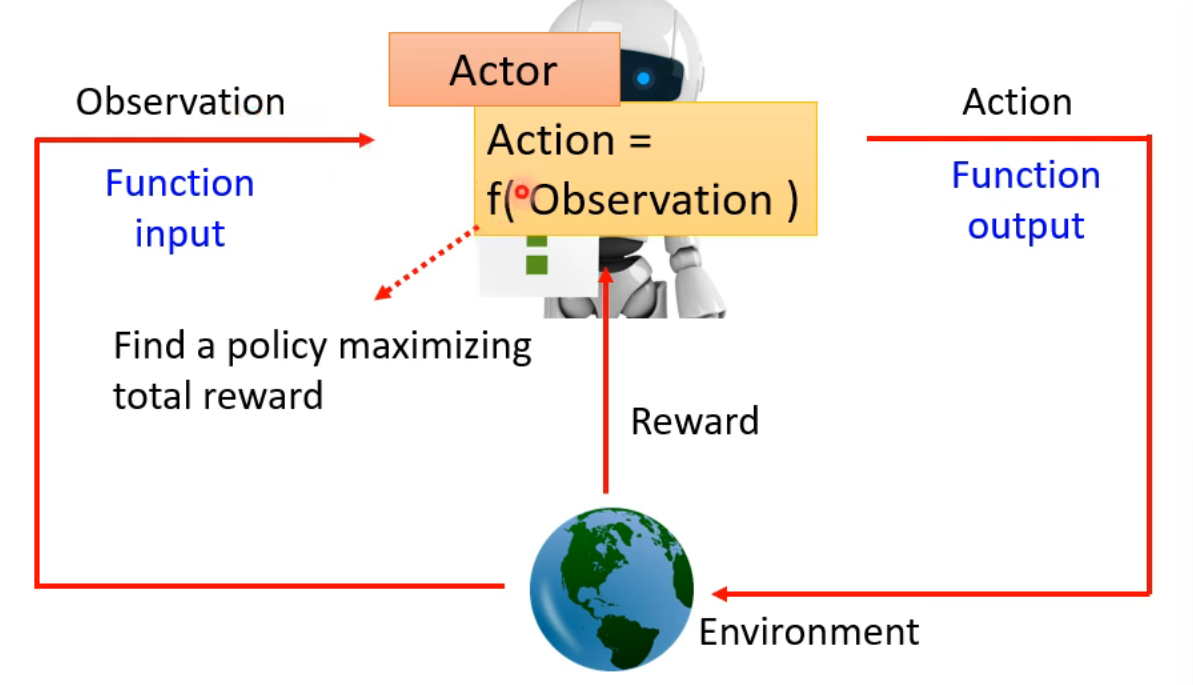
Observation是state
Actor是policy pai 一个决策函数
Action就是函数输出
Environment更像你的对手
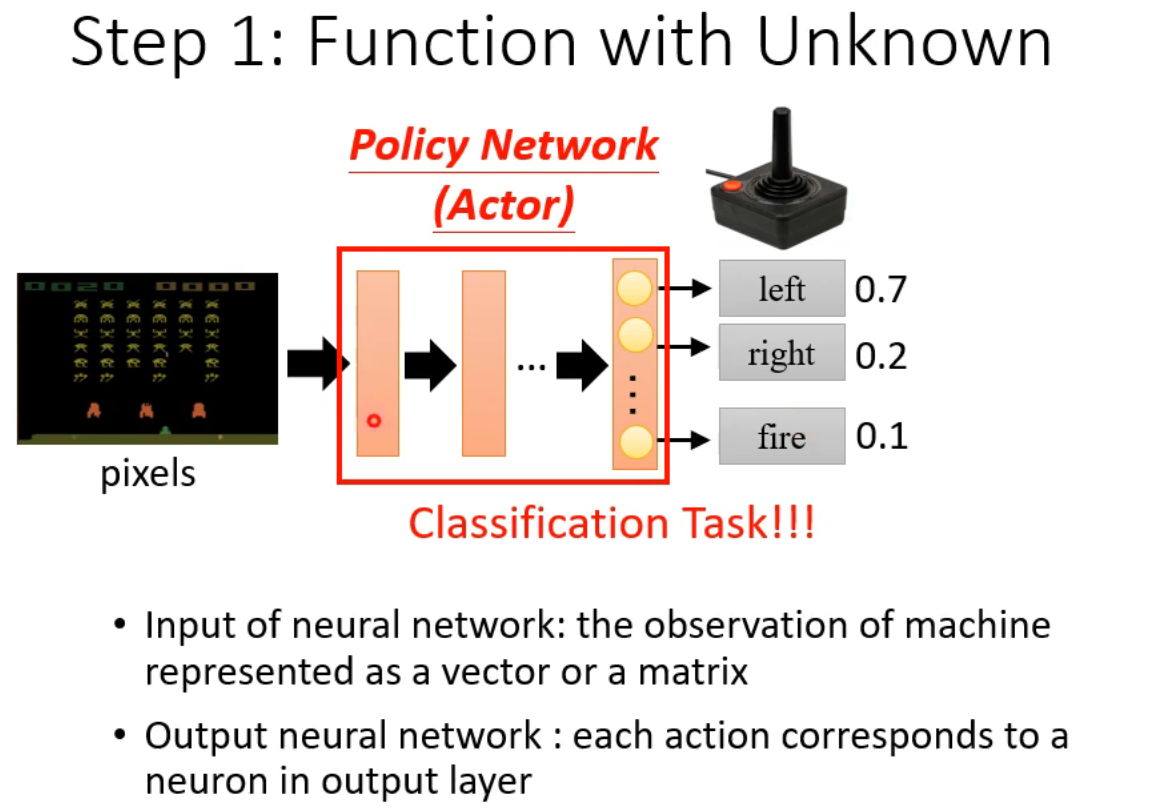
本质的还是分类
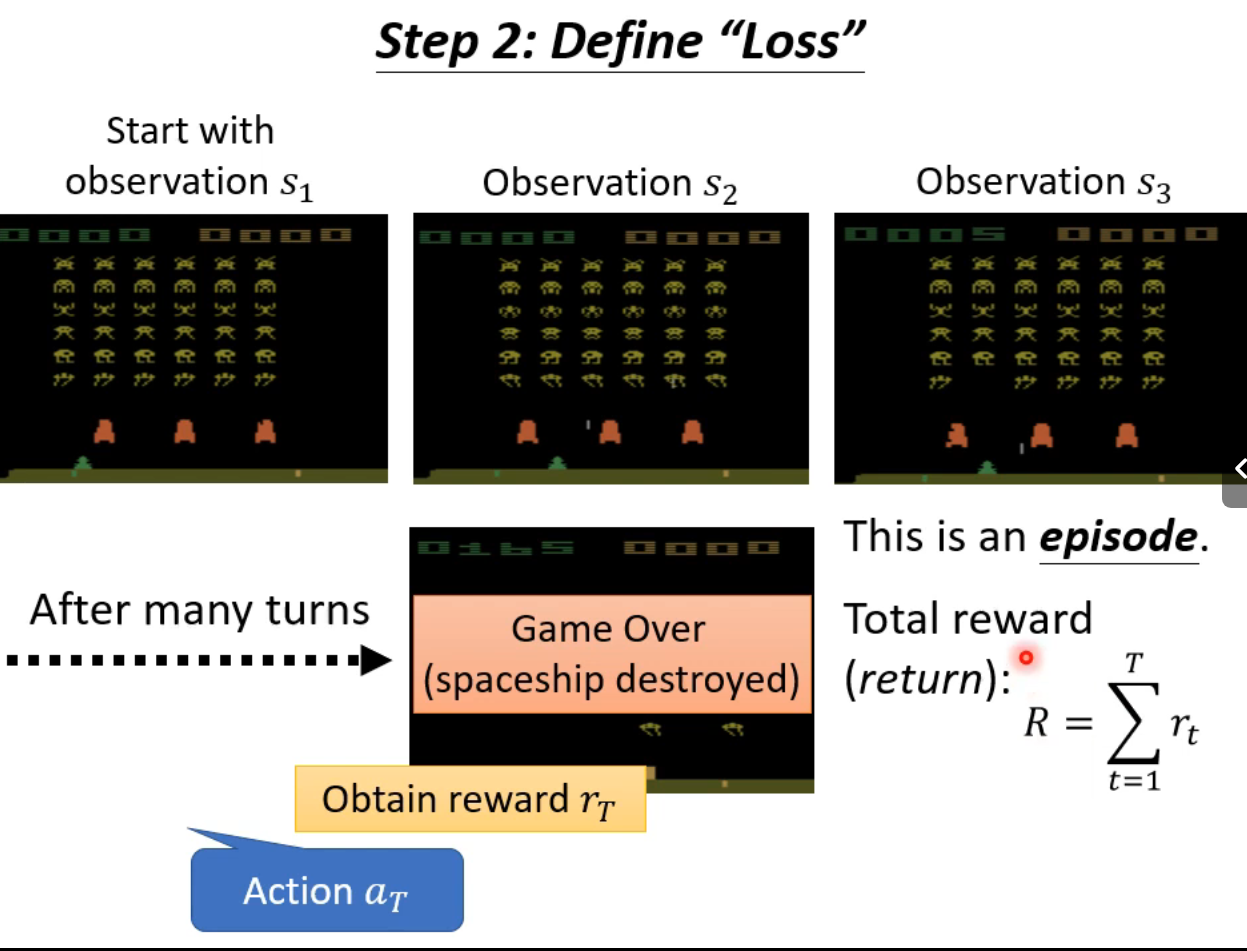
trajectory:轨迹
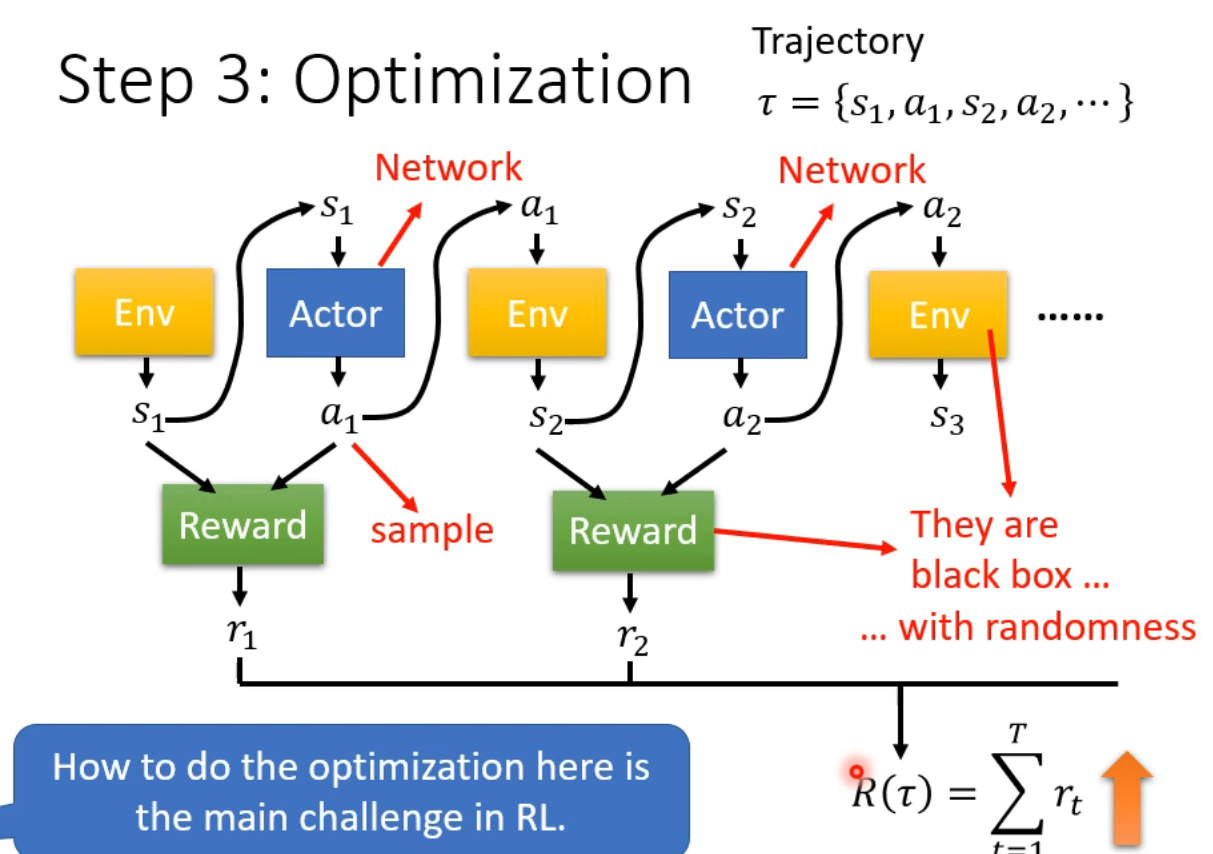
sample:抽样,说明在Network里,有至少一个层是每次输出不一样的(引入随机)
Policy descent
假设我们知道在s情况下做什么行动最好(a_hat已知)(实际中这些资料都是要通过训练得到的,初始化让所有动作都能进行,便于更新)
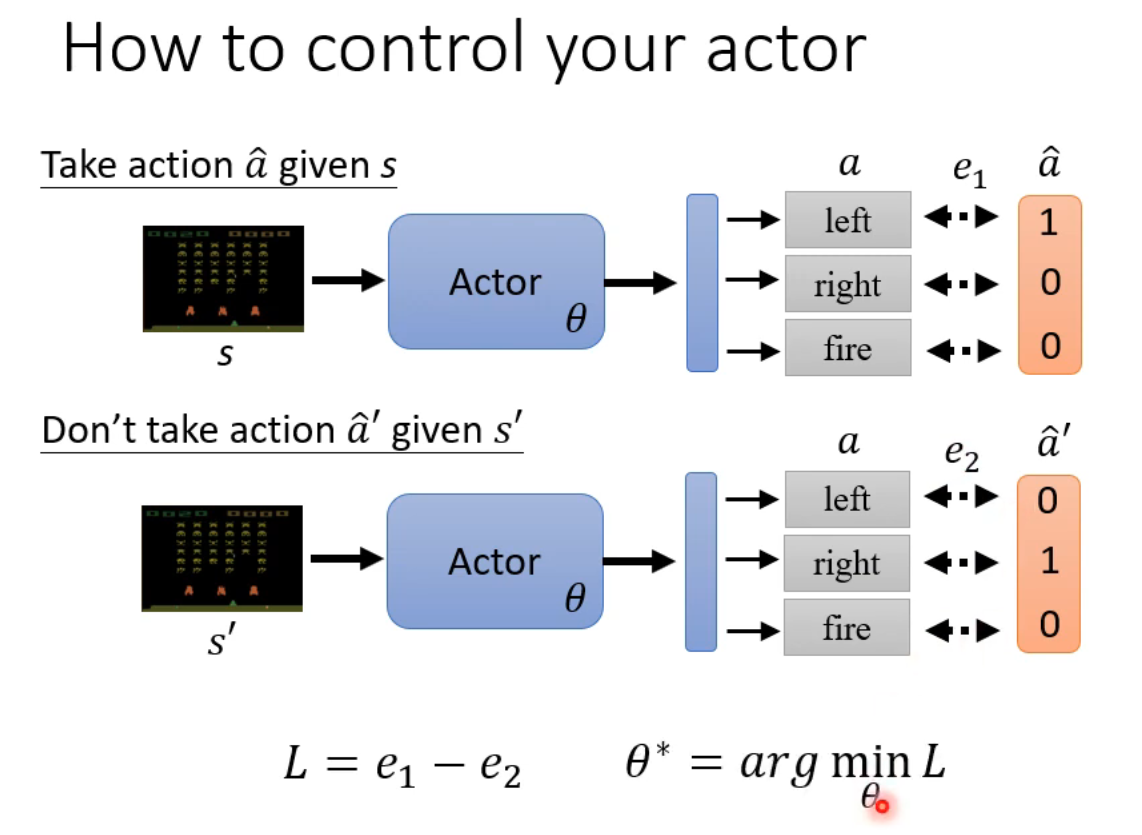
相当于a_hat是label了,最大/最小化交叉熵,似乎回到了supervised learning
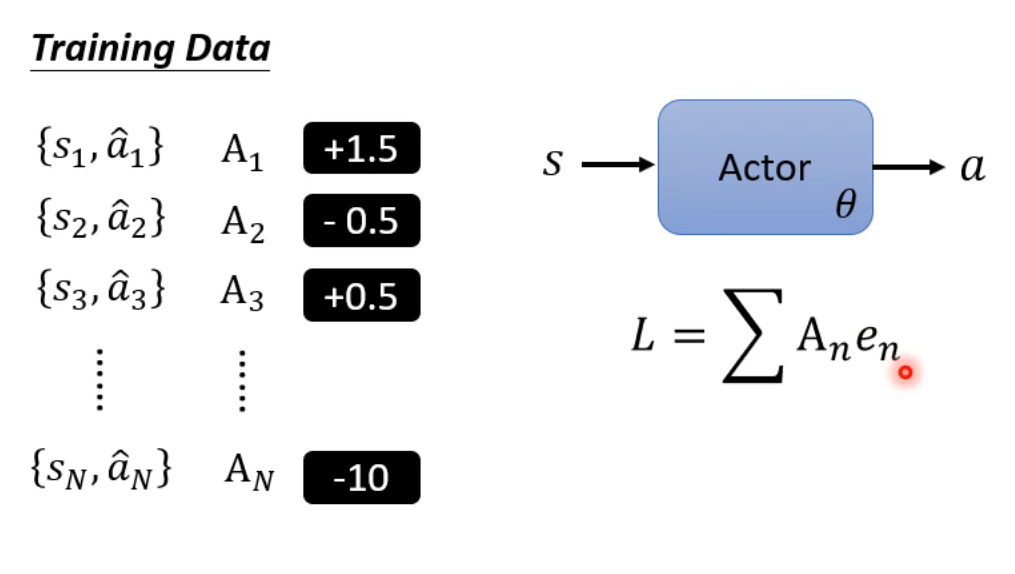
我们要找到在s环境做出a行为的奖赏,然后最大化
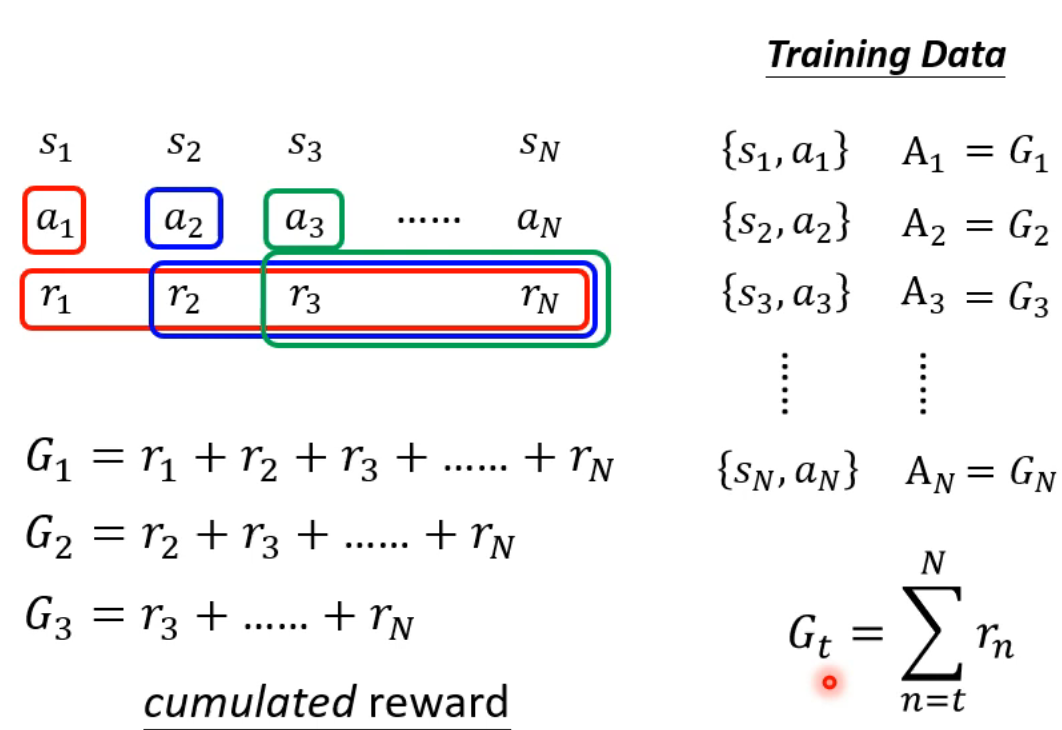
Reward delay:现在的行为在之后才会得到reward
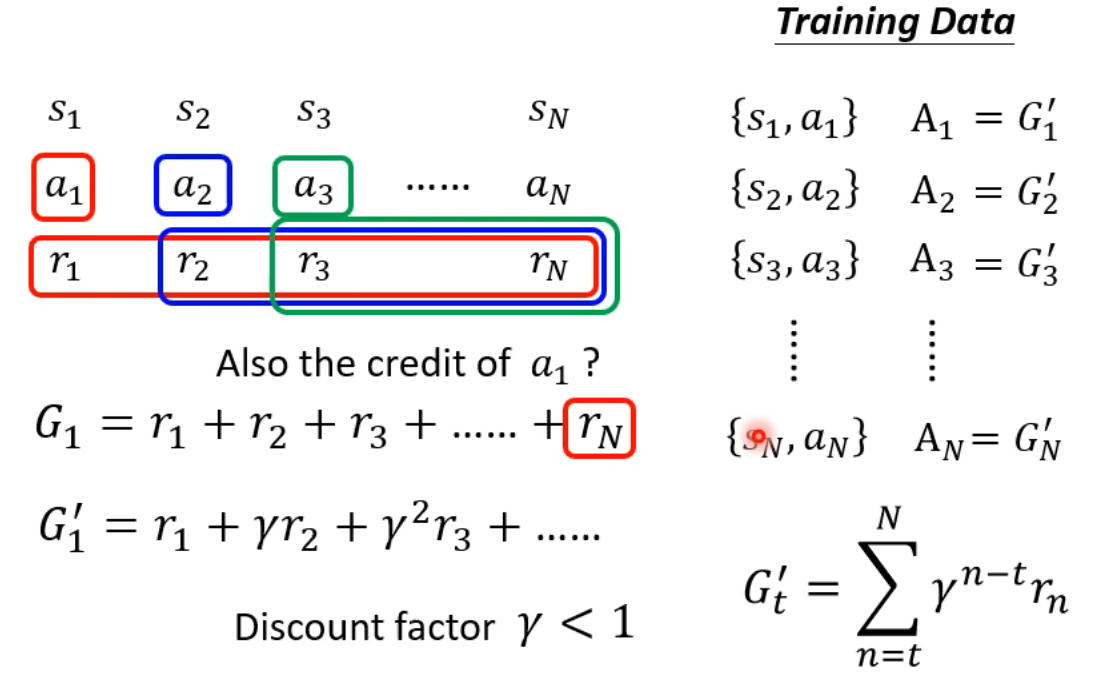
Discount factor 伽马: 从a1得到rn很远,不能保证得到,所以距离越远的奖励衰减越大
奖赏是相对的,如果奖赏都是正数的话全部鼓励,所以引入标准化处理(保证正负都有)baseline
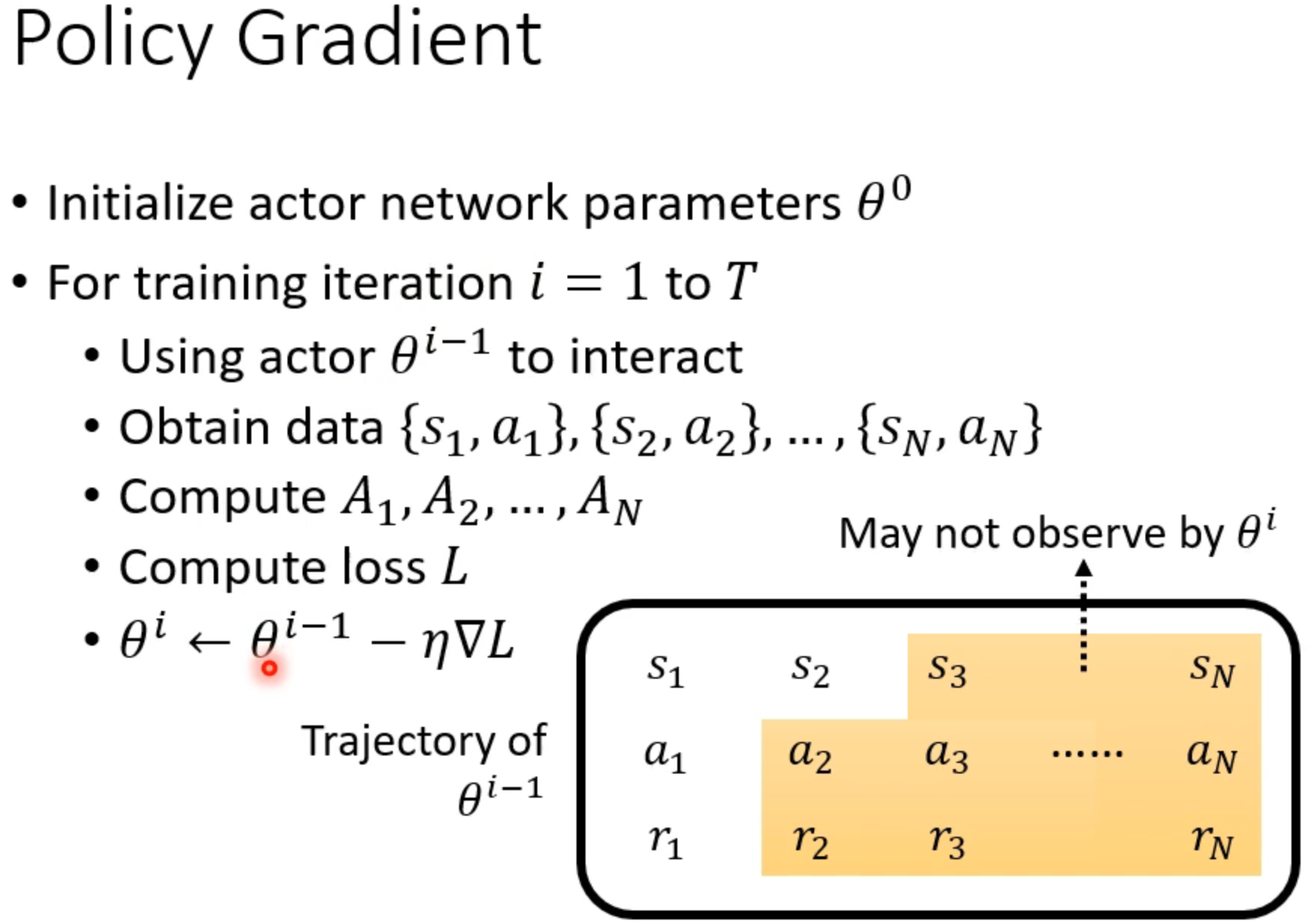
收集资料在loop里面,每次训练都要重新收集资料
On policy & Off policy -> PPO
Actor Critic
计算在当前s为起始下用策略塞塔之后的reward总和
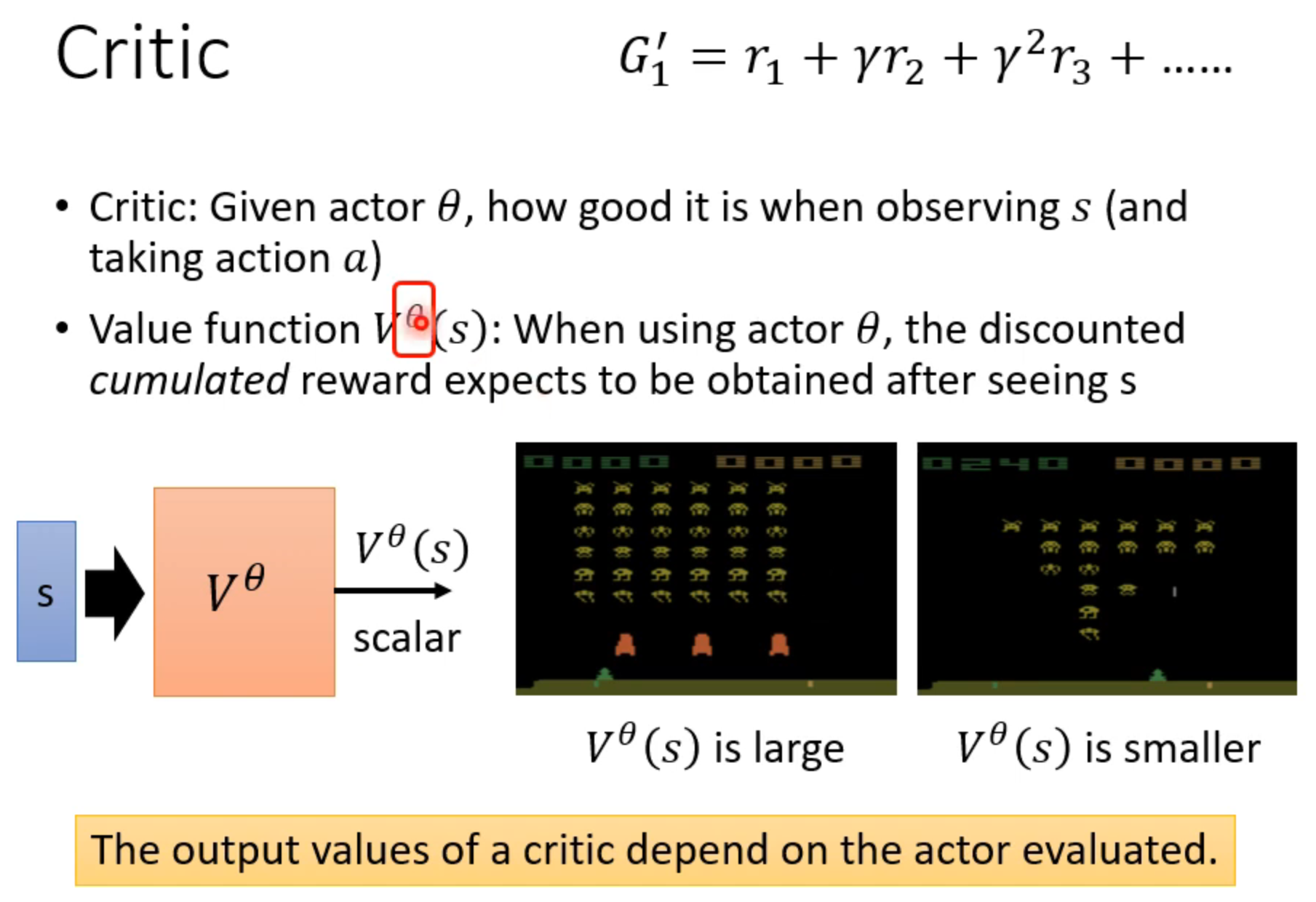
way1:MC蒙特卡洛(跑几局游戏得到结果,只关心结果)
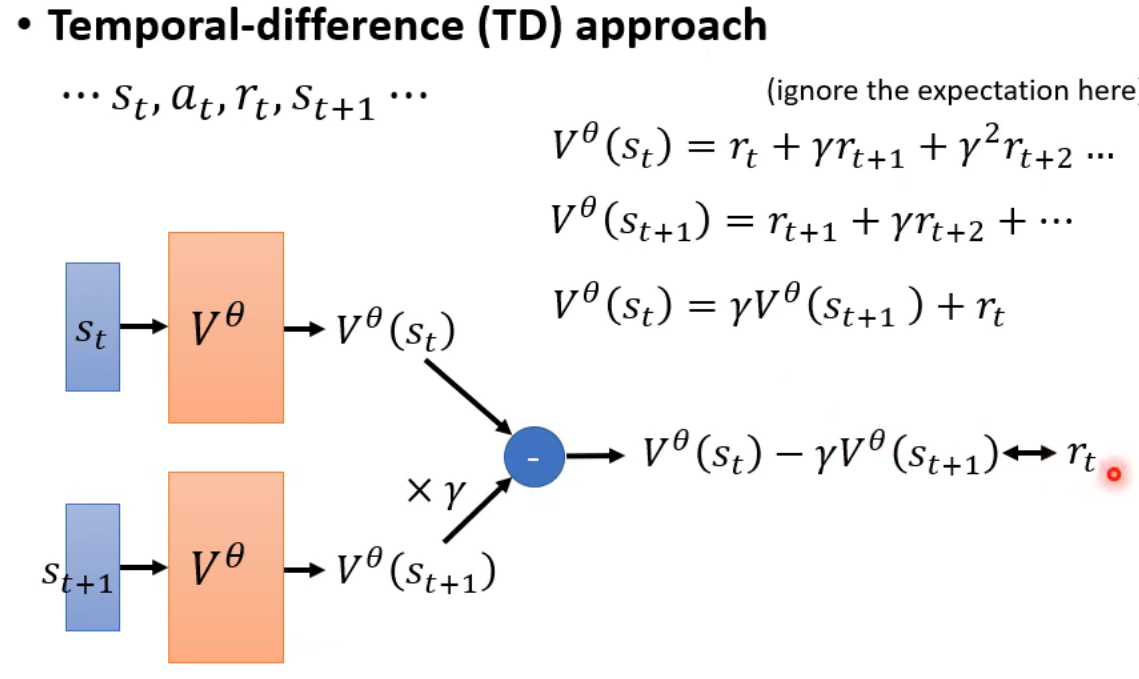
way2:TD(过程递推)

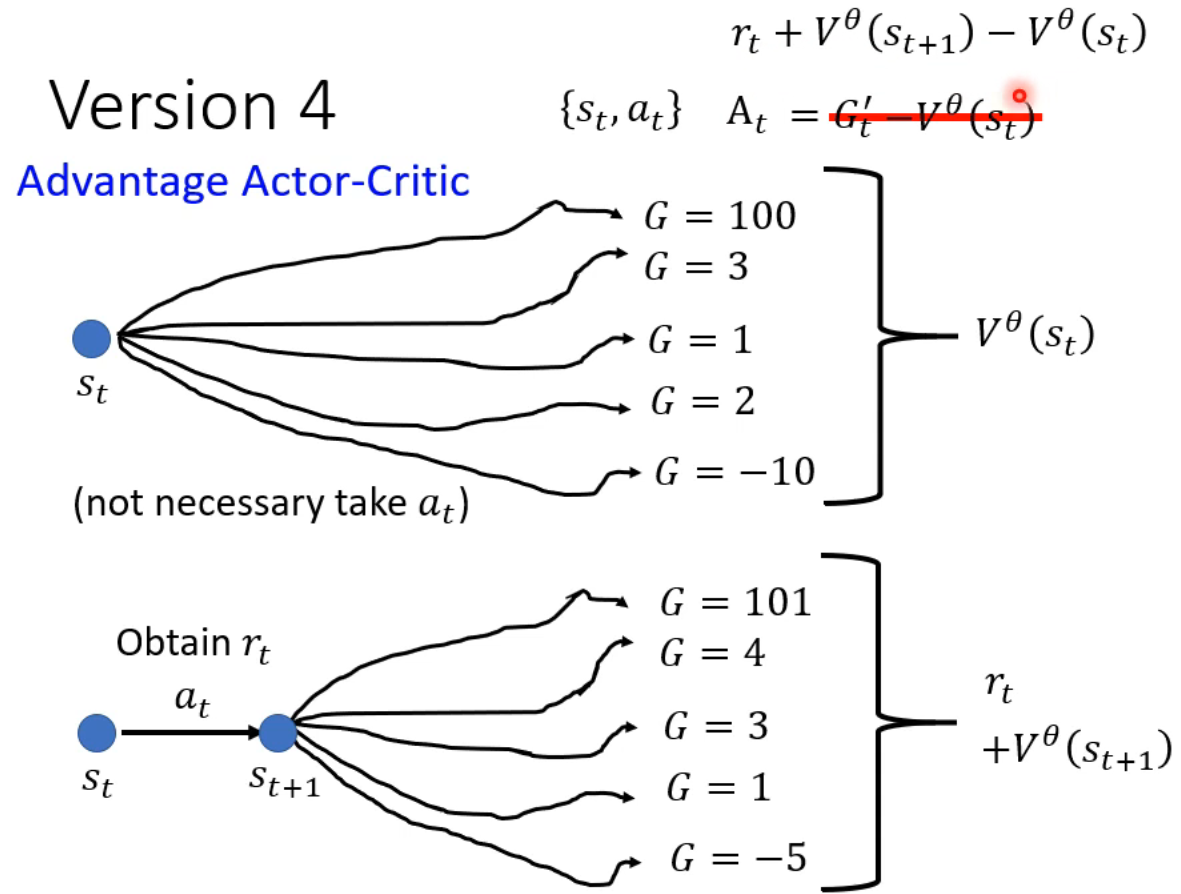
得到A
王树森
Randomness in Reinforcement Learning
1.Actions
2.State transitions

Qpai由策略pai st at决定


 浙公网安备 33010602011771号
浙公网安备 33010602011771号