Hadoop综合大作业&补交4次作业:获取全部校园新闻,网络爬虫基础练习,中文词频统计,熟悉常用的Linux操作
2018-05-25 19:42 Molemole 阅读(394) 评论(0) 收藏 举报1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)进行词频统计。
(1)开启所有的服务,并创建文件夹wwc
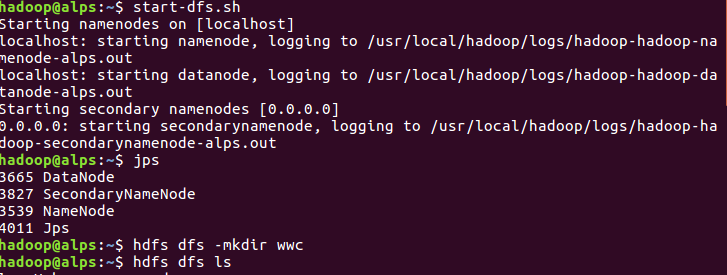
(2)查看目录下所有文件
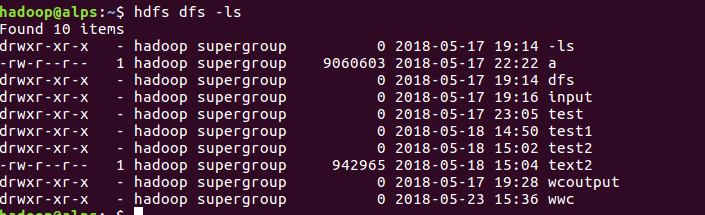
(3)把hdfs文件系统中文件夹里的文本文件load进去。

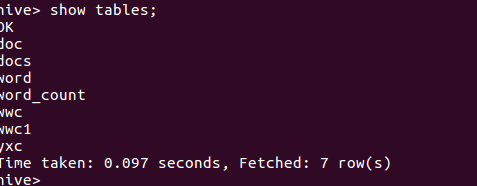
(4)进入hive,并查看所有的表
(5)创建表word,,写hiveQL命令统计
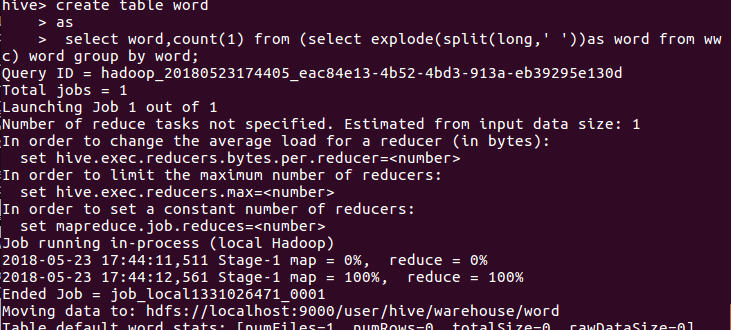
(6)运行结果
获取全部校园新闻
1.取出一个新闻列表页的全部新闻 包装成函数。
2.获取总的新闻篇数,算出新闻总页数。
3.获取全部新闻列表页的全部新闻详情。

import requests
from bs4 import BeautifulSoup
from datetime import datetime
import re
# 获取新闻点击次数
def getNewsId(url):
newsId = re.search(r'\_\d{4}\/((.*)).html', url).group(1)
clickUrl = 'http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80'.format(newsId)
clickRes = requests.get(clickUrl)
# 利用正则表达式获取新闻点击次数
clickCount = int(re.search("hits'\).html\('(.*)'\);", clickRes.text).group(1))
return clickCount
# 获取新闻细节
def getNewsDetail(newsUrl):
resd = requests.get(newsUrl)
resd.encoding = 'utf-8'
soupd = BeautifulSoup(resd.text, 'html.parser')
content = soupd.select('#content')[0].text
info = soupd.select('.show-info')[0].text
# 调用getNewsId()获取点击次数
count = getNewsId(newsUrl)
# 识别时间格式
date = re.search('(\d{4}.\d{2}.\d{2}\s\d{2}.\d{2}.\d{2})', info).group(1)
# 识别一个至三个数据
if(info.find('作者:')>0):
author = re.search('作者:((.{2,4}\s|.{2,4}、|\w*\s){1,3})', info).group(1)
else:
author = '无'
if(info.find('审核:')>0):
check = re.search('审核:((.{2,4}\s){1,3})', info).group(1)
else:
check = '无'
if(info.find('来源:')>0):
sources = re.search('来源:(.*)\s*摄|点', info).group(1)
else:
sources = '无'
if (info.find('摄影:') > 0):
photo = re.search('摄影:(.*)\s*点', info).group(1)
else:
photo = '无'
# 用datetime将时间字符串转换为datetime类型
dateTime = datetime.strptime(date, '%Y-%m-%d %H:%M:%S')
# 利用format对字符串进行操作
print('发布时间:{0}\n作者:{1}\n审核:{2}\n来源:{3}\n摄影:{4}\n点击次数:{5}'.format(dateTime, author, check, sources, photo, count))
print(content)
def getListPage(listUrl):
res = requests.get(listUrl)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
for new in soup.select('li'):
if len(new.select('.news-list-title')) > 0:
title = new.select('.news-list-title')[0].text
description = new.select('.news-list-description')[0].text
newsUrl = new.select('a')[0]['href']
print('标题:{0}\n内容:{1}\n链接:{2}'.format(title, description, newsUrl))
# 调用getNewsDetail()获取新闻详情
getNewsDetail(newsUrl)
break
listUrl = 'http://news.gzcc.cn/html/xiaoyuanxinwen/'
getListPage(listUrl)
res = requests.get(listUrl)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
listCount = int(soup.select('.a1')[0].text.rstrip('条'))//10+1
for i in range(2,listCount):
listUrl= 'http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i)
getListPage(listUrl)
4.找一个自己感兴趣的主题,进行数据爬取,并进行分词分析。不能与其它同学雷同。
import requests, re, jieba
from bs4 import BeautifulSoup
from datetime import datetime
def getNewsDetail(newsUrl):
resd = requests.get(newsUrl)
resd.encoding = 'gb2312'
soupd = BeautifulSoup(resd.text, 'html.parser')
content = soupd.select('#endText')[0].text
info = soupd.select('.post_time_source')[0].text
date = re.search('(\d{4}.\d{2}.\d{2}\s\d{2}.\d{2}.\d{2})', info).group(1)
dateTime = datetime.strptime(date, '%Y-%m-%d %H:%M:%S')
sources = re.search('来源:\s*(.*)', info).group(1)
keyWords = getKeyWords(content)
print('发布时间:{0}\n来源:{1}'.format(dateTime, sources))
print('关键词:{}、{}、{}'.format(keyWords[0], keyWords[1], keyWords[2]))
print(content)
def getKeyWords(content):
content = ''.join(re.findall('[\u4e00-\u9fa5]', content))
wordSet = set(jieba._lcut(content))
wordDict = {}
for i in wordSet:
wordDict[i] = content.count(i)
deleteList, keyWords = [], []
for i in wordDict.keys():
if len(i) < 2:
deleteList.append(i)
for i in deleteList:
del wordDict[i]
dictList = list(wordDict.items())
dictList.sort(key=lambda item: item[1], reverse=True)
for i in range(3):
keyWords.append(dictList[i][0])
return keyWords
def getListPage(listUrl):
res = requests.get(listUrl)
res.encoding = 'gbk'
soup = BeautifulSoup(res.text, 'html.parser')
for new in soup.select('.news_item'):
newsUrl = new.select('a')[0]['href']
title = new.select('a')[0].text
print('标题:{0}\n链接:{1}'.format(title, newsUrl))
getNewsDetail(newsUrl)
break
listUrl = 'http://sports.163.com/zc/'
getListPage(listUrl)
for i in range(2, 20):
listUrl = 'http://tech.163.com/special/it_2016_%02d/' % i
getListPage(listUrl)
网络爬虫基础练习
import requests from bs4 import BeautifulSoup res = requests.get('http://news.qq.com/') res.encoding = 'UTF-8' soup = BeautifulSoup(res.text, 'html.parser') # 取出h1标签的文本 for h1 in soup.find_all('h1'): print(h1.text) # 取出a标签的链接 for a in soup.find_all('a'): print(a.attrs.get('href')) # 取出所有li标签的所有内容 for li in soup.find_all('li'): print(li.contents) # 取出第2个li标签的a标签的第3个div标签的属性 print(soup.find_all('li')[1].a.find_all('div')[2].attrs) # 取出一条新闻的标题、链接、发布时间、来源 print(soup.select('div .news-list-title')[0].text) print(soup.select('div .news-list-thumb')[0].parent.attrs.get('href')) print(soup.select('div .news-list-info > span')[0].text) print(soup.select('div .news-list-info > span')[1].text)
中文词频统计
从文件读取待分析文本。
news = open('gzccnews.txt','r',encoding = 'utf-8')
安装与使用jieba进行中文分词。
pip install jieba
import jieba
list(jieba.lcut(news))
生成词频统计
排序
排除语法型词汇,代词、冠词、连词
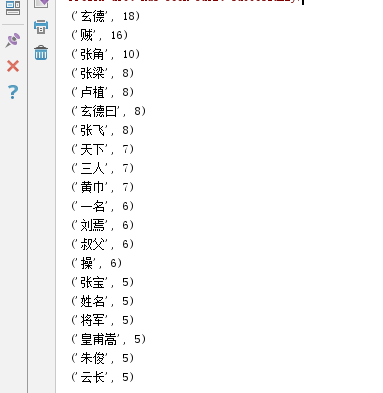
输出词频最大TOP20
import jieba
fo=open('test.txt','r',encoding='utf-8')
text=fo.read()
textlist=list(jieba.lcut(text))
Dworlds=[',','也','。','若','亦','宜','、','之','于','“','”',':','曰',';','\u3000'
,'\n','了','与','中','有','而','人','不','我','在','来','!','遂','?','为','又','被','皆','问','至','言','众','吾','等','见','将']
textdic={}
for t in textlist:
textdic[t]=textdic.get(t,0)+1
for i in Dworlds:
if i in textdic:
del textdic[i]
newtext=sorted(textdic.items(),key=lambda x:x[1],reverse=True)
for i in range(20):
print(newtext[i])
运行截图:
熟悉常用的Linux操作
请按要求上机实践如下linux基本命令。
cd命令:切换目录
(1)切换到目录 /usr/local
cd /usr/local
(2)去到目前的上层目录
cd ..
(3)回到自己的主文件夹
cd ~
ls命令:查看文件与目录
(4)查看目录/usr下所有的文件
ls /usr
mkdir命令:新建新目录
(5)进入/tmp目录,创建一个名为a的目录,并查看有多少目录存在
cd /tmp
mkdir a
ls -l
(6)创建目录a1/a2/a3/a4
mkdir -p a1/a2/a3/a4
rmdir命令:删除空的目录
(7)将上例创建的目录a(/tmp下面)删除
rmdir a
(8)删除目录a1/a2/a3/a4,查看有多少目录存在
rmdir -p a1/a2/a3/a4
ls -l
cp命令:复制文件或目录
(9)将主文件夹下的.bashrc复制到/usr下,命名为bashrc1
sudo cp ~./bashrc /tmp/banshrc1
(10)在/tmp下新建目录test,再复制这个目录内容到/usr
sudo cp -r /tmp/test /usr/test
mv命令:移动文件与目录,或更名
(11)将上例文件bashrc1移动到目录/usr/test
sudo mv bashrc1 /usr/test
(12)将上例test目录重命名为test2
sudo mv test test2
rm命令:移除文件或目录
(13)将上例复制的bashrc1文件删除
sudo rm -f bashrc1
(14)将上例的test2目录删除
u
cat命令:查看文件内容
(15)查看主文件夹下的.bashrc文件内容
cat .bashrc
tac命令:反向列示
(16)反向查看主文件夹下.bashrc文件内容
tac .bashrc
more命令:一页一页翻动查看
(17)翻页查看主文件夹下.bashrc文件内容
more .bashrc
head命令:取出前面几行
(18)查看主文件夹下.bashrc文件内容前20行
head -n 20 .bashrc
(19)查看主文件夹下.bashrc文件内容,后面50行不显示,只显示前面几行
head -n 46 .bashrc
tail命令:取出后面几行
(20)查看主文件夹下.bashrc文件内容最后20行
tail -n 20 .bashrc
(21) 查看主文件夹下.bashrc文件内容,只列出50行以后的数据
tail -n 51 .bashrc
touch命令:修改文件时间或创建新文件
(22)在/tmp下创建一个空文件hello并查看时间
cd /tmp
touch hello
(23)修改hello文件,将日期调整为5天前
touch -d "5 days ago" hello
或者 touch -t "03091204" hello //3月9号12:04
([[CC]YY]MMDDhhmm[.ss])格式
CC 指定年份的前两位数字。
YY 指定年份的后两位数字。
MM 指定一年的哪一月, 1-12。
DD 指定一年的哪一天, 1-31。
hh 指定一天中的哪一个小时, 0-23。
mm 指定一小时的哪一分钟, 0-59。
chown命令:修改文件所有者权限
(24)将hello文件所有者改为root帐号,并查看属性
sudo chown root hello
ls -l
find命令:文件查找
(25)找出主文件夹下文件名为.bashrc的文件
fing ~ -name .bashrc
tar命令:压缩命令
(26)在/目录下新建文件夹test,然后在/目录下打包成test.tar.gz
sudo tar -cvf test.ter.gz test
(27)解压缩到/tmp目录
sudo tar -xzvf test,tar.gz
grep命令:查找字符串
(28)从~/.bashrc文件中查找字符串'examples'
grep examples ~/.bashrc
(29)配置Java环境变量,在~/.bashrc中设置
(30)查看JAVA_HOME变量的值
gedit ~/.bashrc 在文件中加入Java路径(export JAVA_HOME=/usr/lib/jvm/default-java)
source ~/.bashrc
echo $JAVA_HOME

 浙公网安备 33010602011771号
浙公网安备 33010602011771号