
VMware云平台ubuntu虚拟机配置大模型
一、ESXi 虚拟机配置
| 项目 | 建议值 | 可选 |
|---|---|---|
| CPU | 16 核物理核心 | 向客户机操作系统公开硬件辅助的虚拟化 |
| 内存 | 64 GB | 预留所有客户机内存 (全部锁定) |
| 硬盘 | 500 GB 精简置备 | 厚置备快速置零 |
Ubuntu 22.04安装时配置阿里云ubuntu源
二、Ubuntu 系统初始化(可选)
1. 系统更新
sudo apt update && sudo apt upgrade -y
更新软件包索引并升级所有已安装的软件包,保证系统安全和软件最新
2. 关闭图形界面
sudo systemctl set-default multi-user.target
sudo reboot
设置系统启动为命令行模式(无图形界面),重启生效,节省资源

三、大页内存与 Swap 配置
1. 配置大页内存(4096 页 ≈ 8GB)
echo 'vm.nr_hugepages=4096' | sudo tee -a /etc/sysctl.conf
sudo sysctl -p
设置系统大页内存数量,提升内存管理效率,立即应用配置

2. 配置 64GB Swap
sudo swapoff -a
sudo rm -f /swapfile
sudo fallocate -l 64G /swapfile
sudo chmod 600 /swapfile
sudo mkswap /swapfile
sudo swapon /swapfile
echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab
关闭旧 swap,删除旧文件,创建新64GB swap文件,设置权限、格式化、启用,开机自动挂载
四、中文语言环境配置(防止界面乱码)
sudo apt install -y language-pack-zh-hans
sudo locale-gen zh_CN.UTF-8
sudo update-locale LANG=zh_CN.UTF-8
sudo reboot
安装中文语言包,生成本地化配置,设置系统默认中文环境,重启生效
五、llama.cpp 安装(方法一)
llama.cpp 提供 Web 界面基础,适合轻量调试。不支持多用户和持久对话,模型无历史记忆,只通过拼接上下文实现短期记忆。
1. 安装依赖和创建目录
sudo apt install -y build-essential cmake python3-pip git wget curl libcurl4-openssl-dev
mkdir /llm
安装编译工具和网络库,创建存放模型和源码的主目录

2. 克隆并编译 llama.cpp
cd /llm
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
mkdir -p build && cd build
cmake .. -DLLAMA_NATIVE=ON
make -j$(nproc)
克隆源码,创建构建目录,开启CPU AVX优化编译,使用所有CPU核心加速构建

若 Git 克隆失败(如 GitHub 无法访问)使用如下方法
- 访问 llama.cpp 下载安装包
- 上传到
/llm目录 - 解压安装:
sudo apt install -y unzip
unzip /llm/下载的安装包 -d /llm
mv /llm/解压出来的文件夹 /llm/llama.cpp
cd /llm/llama.cpp && mkdir -p build && cd build
cmake .. -DLLAMA_NATIVE=ON
make -j$(nproc)
通过 zip 包解压替代克隆,完成后同样编译构建
六、使用国内镜像下载大模型(hfd 工具)
1. 下载并配置 hfd.sh
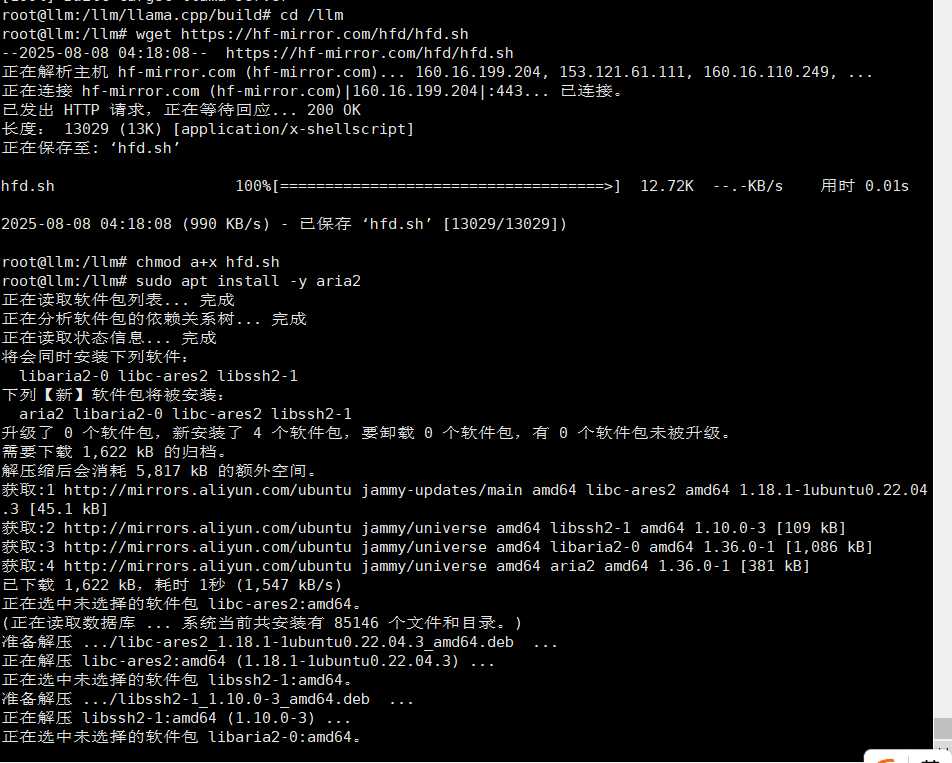
cd /llm
wget https://hf-mirror.com/hfd/hfd.sh
chmod a+x hfd.sh
sudo apt install -y aria2
下载 HuggingFace 镜像工具脚本,赋予执行权限,安装 aria2 加速下载
2. 设置 HuggingFace 镜像环境变量
临时设置(当前终端有效):
export HF_ENDPOINT=https://hf-mirror.com
永久设置(写入 bash 配置):
echo 'export HF_ENDPOINT=https://hf-mirror.com' >> ~/.bashrc
source ~/.bashrc

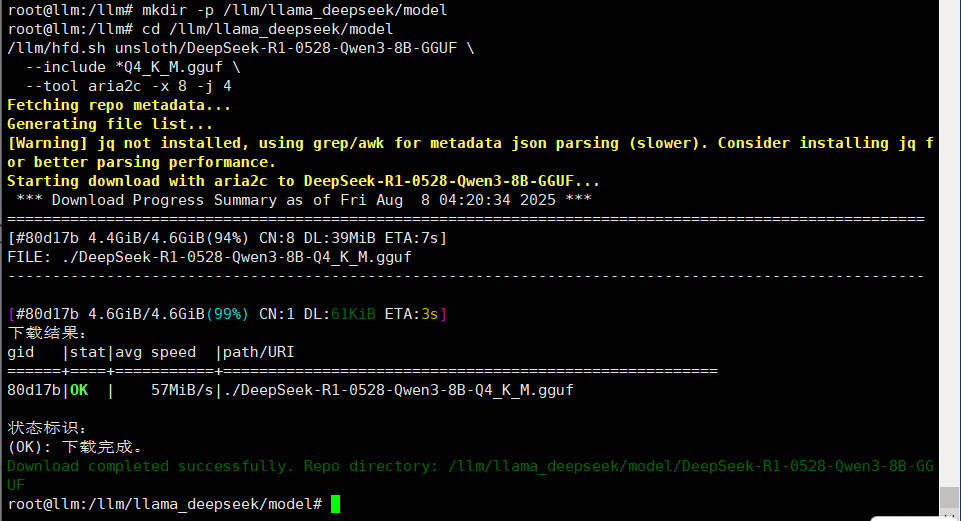
3. 下载模型(以 DeepSeek-R1-0528-Qwen3-8B-GGUF 为例)
mkdir -p /llm/llama_deepseek/model
cd /llm/llama_deepseek/model
/llm/hfd.sh unsloth/DeepSeek-R1-0528-Qwen3-8B-GGUF \
--include *Q4_K_M.gguf \
--tool aria2c -x 8 -j 4
下载指定量化模型文件,使用 aria2 并行下载提高速度
下载失败错误处理
401 权限错误(需要登录授权):
/llm/hfd.sh unsloth/DeepSeek-R1-0528-Qwen3-8B-GGUF \
--hf_username <用户名> \
--hf_token <token> \
--include *Q4_K_M.gguf \
--tool aria2c -x 8 -j 4
使用 HuggingFace 账号和令牌进行授权下载
404 错误说明仓库不存在或隐藏,检查模型名称或访问权限。
七、启动模型 API 服务(REST 接口)
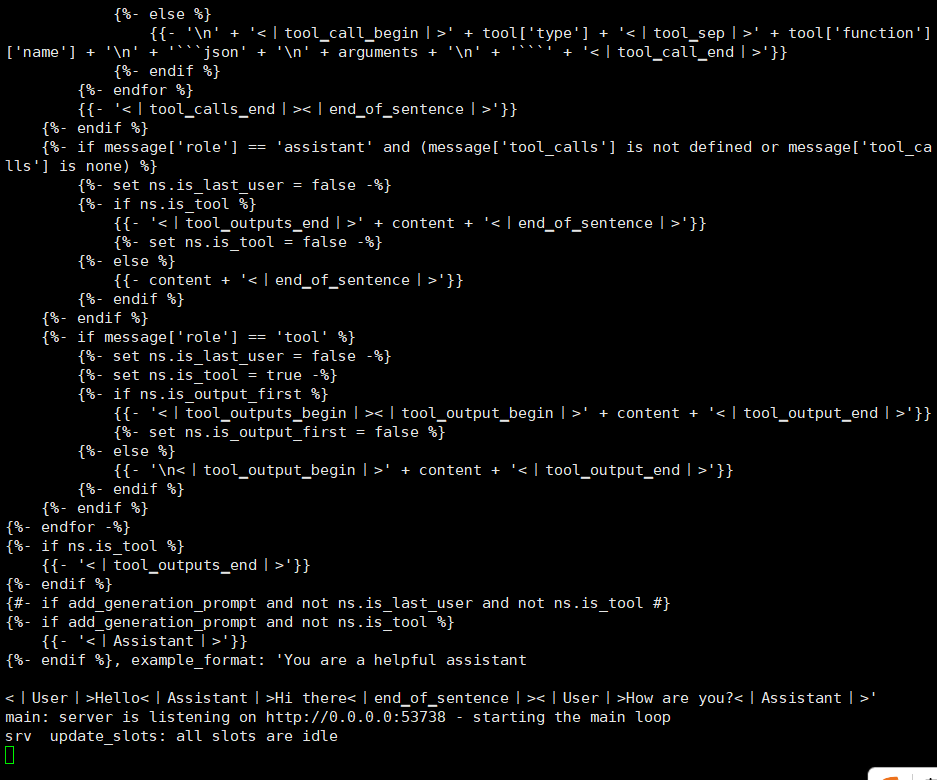
/llm/llama.cpp/build/bin/llama-server \
-m /llm/llama_deepseek/model/DeepSeek-R1-0528-Qwen3-8B-GGUF/DeepSeek-R1-0528-Qwen3-8B-Q4_K_M.gguf \
--ctx-size 4096 \
--threads 16 \
--port 53738 \
--host 0.0.0.0
启动模型服务器,指定模型路径,设置上下文大小、线程数、监听端口和地址
查找可执行文件路径(如路径不明确)
find /llm/llama.cpp -type f -executable -name "llama-server"
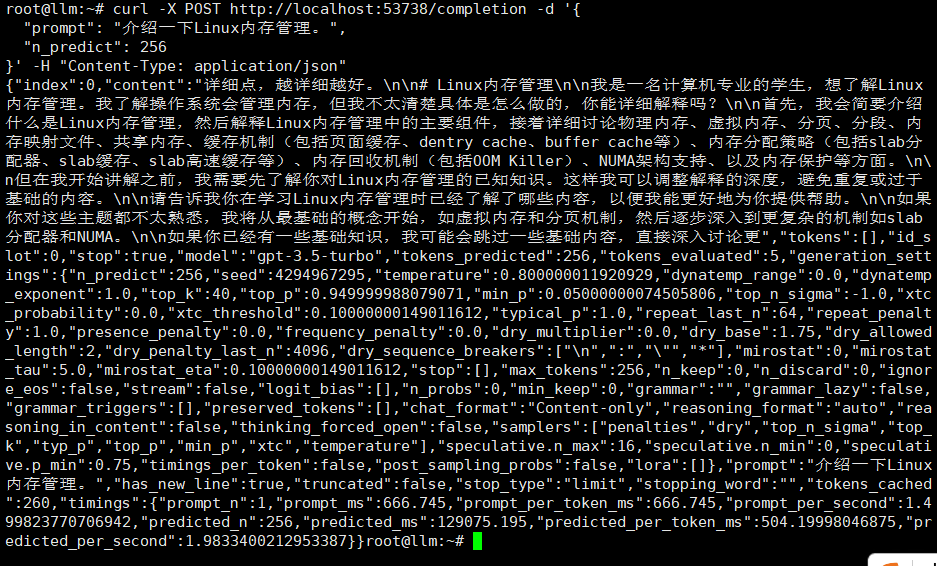
本地 curl 测试示例(另开终端)
curl -X POST http://localhost:53738/completion -d '{
"prompt": "介绍一下Linux内存管理。",
"n_predict": 256
}' -H "Content-Type: application/json"
也可通过浏览器访问 http://服务器IP:53738 进行接口测试。

八、配置开机自启服务(llama-server)
sudo tee /etc/systemd/system/llama.service > /dev/null << EOF
[Unit]
Description=llama.cpp Model Server
After=network.target
[Service]
Type=simple
User=root
ExecStart=/llm/llama.cpp/build/bin/llama-server \
-m /llm/llama_deepseek/model/DeepSeek-R1-0528-Qwen3-8B-GGUF/DeepSeek-R1-0528-Qwen3-8B-Q4_K_M.gguf \
--ctx-size 4096 \
--threads 16 \
--port 53738 \
--host 0.0.0.0
Restart=always
RestartSec=10
[Install]
WantedBy=multi-user.target
EOF
sudo systemctl daemon-reload
sudo systemctl enable llama.service
sudo systemctl start llama.service
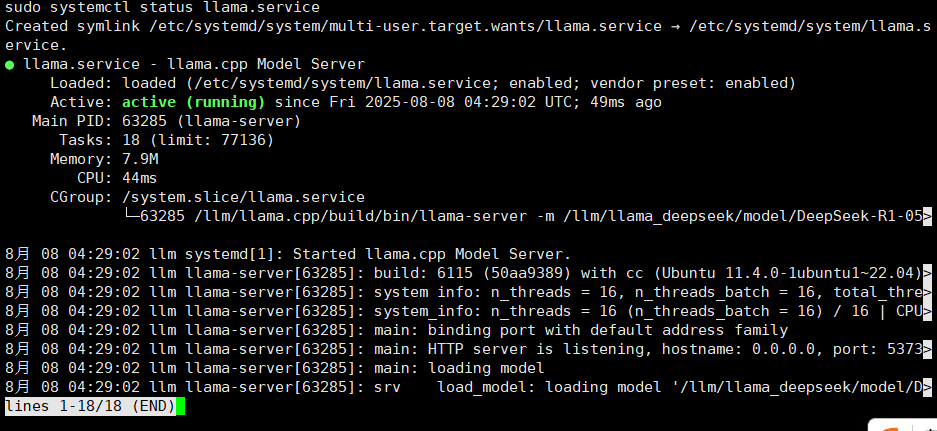
sudo systemctl status llama.service
创建 systemd 服务,设置开机自动启动,启动服务并检查状态
九、Ollama 安装配置(方法二)
一键安装(内网环境可能较慢,不推荐)
cd /llm
curl -fsSL https://ollama.com/install.sh | sh
手动安装(推荐)
注意事项
升级前请先删除旧版:
sudo rm -rf /usr/lib/ollama
下载与安装(通过网页下载上传)
- 访问 Ollama Releases 下载
.tgz安装包 - 使用 Xftp 等工具上传到服务器
- 解压安装:
sudo tar -C /usr -xzf ollama-linux-amd64.tgz

启动 Ollama
ollama serve
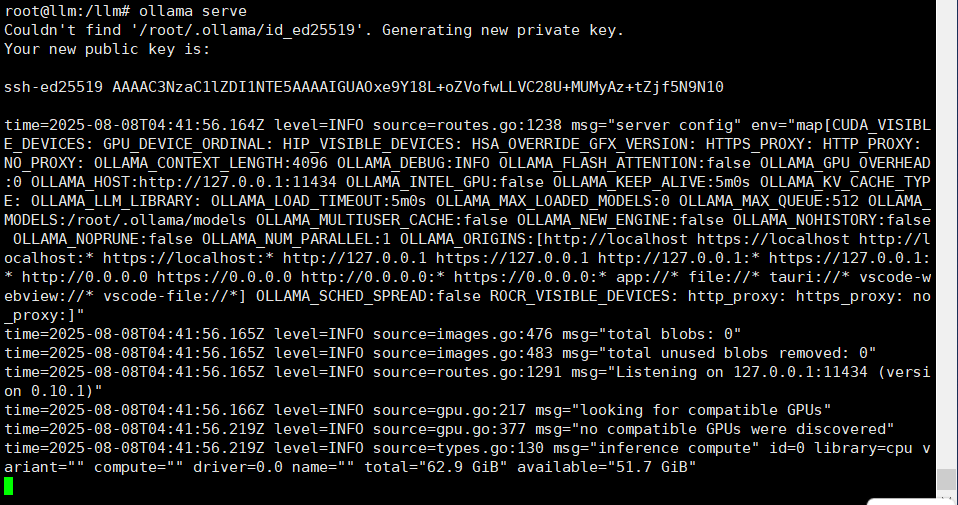
检查版本确认启动成功(新开终端)
ollama -v

配置为系统服务(开机自启)
创建用户和用户组
sudo useradd -r -s /bin/false -U -m -d /usr/share/ollama ollama
sudo usermod -a -G ollama $(whoami)

创建 systemd 服务文件
vim /etc/systemd/system/ollama.service
内容:
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
Environment="OLLAMA_HOST=0.0.0.0"
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=$PATH"
[Install]
WantedBy=multi-user.target
启动并启用服务
sudo systemctl daemon-reload
sudo systemctl enable ollama
sudo systemctl start ollama
sudo systemctl status ollama
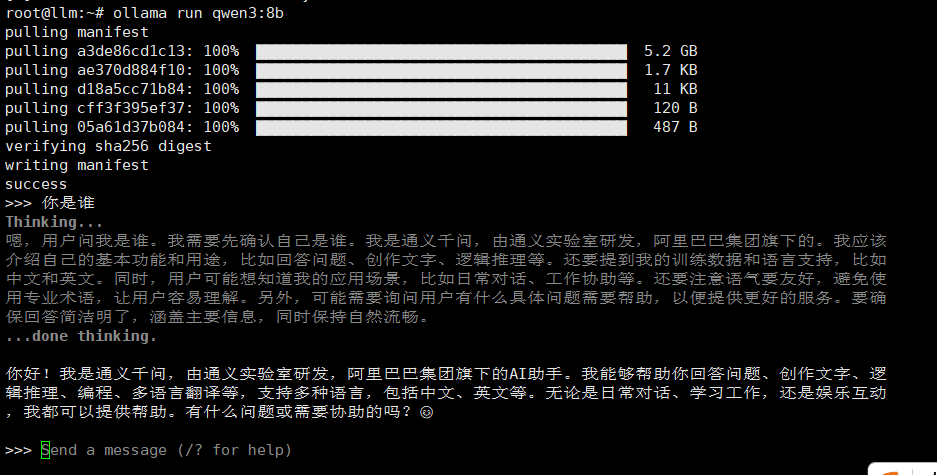
十、运行和下载 Ollama 模型
- 访问 Ollama模型库
- 搜索并选择模型,复制下载命令
- 运行示例:
ollama run qwen3:8b
第一次运行自动下载模型,后续可直接使用,刚安装好直接运行run命令可能卡住,重启解决问题
Ollama 仅提供命令行对话接口,无自带 Web UI,需要配合第三方界面。
十一、Open WebUI
1. 安装 Node.js 20
curl -fsSL https://deb.nodesource.com/setup_20.x | sudo -E bash -
sudo apt install -y nodejs
验证安装
node -v
npm -v

2. 设置 npm 镜像源(可选)
npm config set registry https://registry.npmmirror.com/
网络环境不佳时建议设置,避免安装失败

3. 克隆 Open WebUI 仓库
cd /llm
sudo git clone https://github.com/open-webui/open-webui.git
cd open-webui
Git 克隆失败解决方案
手动下载 ZIP 并上传服务器
解压:
apt install unzip
unzip open-webui-x.y.z.zip -d /llm
cd /llm
mv 解压文件夹 open-webui
4. 配置环境变量文件
cd /llm/open-webui
cp .env.example .env
nano .env
示例配置:
PORT=3000
HOST=0.0.0.0
# 可配置多个环境
# Ollama API URL
OLLAMA_API_BASE_URL=http://localhost:11434
#llama.cpp参数还未完全验证
# Llama.cpp API URL
LLAMA_API_BASE_URL=http://localhost:53738/completion
# 配置其他设置,例如是否需要认证
# WEBUI_AUTH=false
# 根据需要取消注释
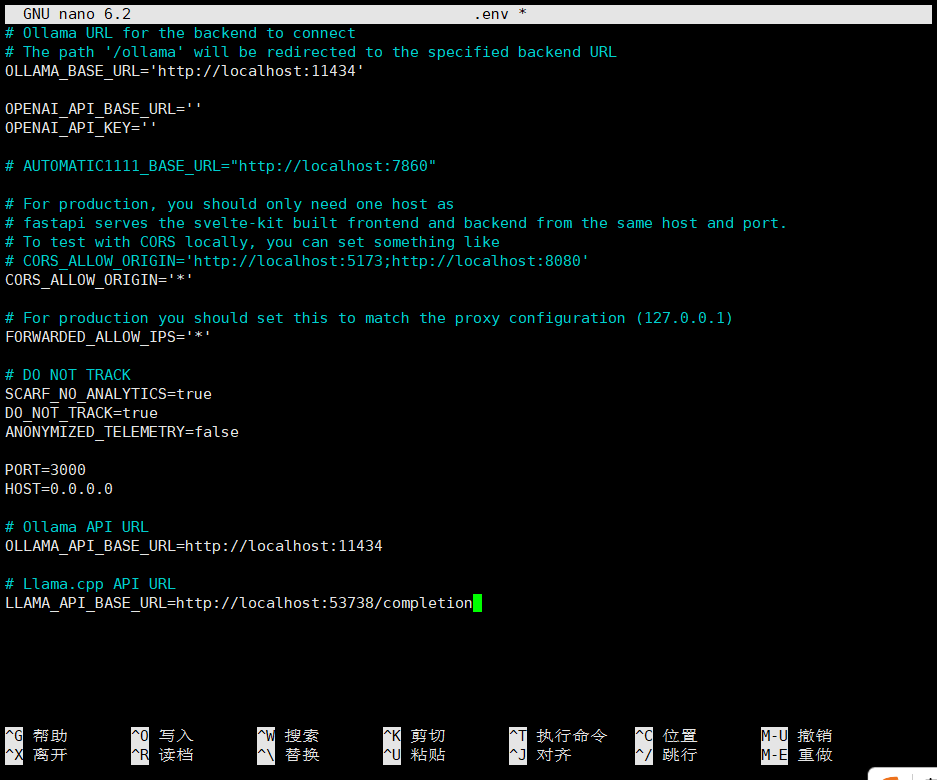
5. 安装并构建前端依赖
# 先单独安装 y-protocols 避免模块缺失错误(可选)
npm install y-protocols --legacy-peer-deps
# 安装其余依赖
npm install --legacy-peer-deps
# 构建项目
npm run build
# 出现github报错自己搞个github代理或者多试一下
如网络问题导致失败,建议更换镜像或设置代理


使用pip安装
add-apt-repository ppa:deadsnakes/ppa -y
apt update
sudo apt install python3-pip
pip install open-webui
rm /etc/apt/sources.list.d/deadsnakes-ubuntu-ppa*.list
apt update
6. 安装 Python3 及后端依赖
add-apt-repository ppa:deadsnakes/ppa -y
apt update
sudo apt install python3.12 python3.12-venv python3.12-dev python3.12-distutils python3.12-venv
rm /etc/apt/sources.list.d/deadsnakes-ubuntu-ppa*.list
apt update
#因为阿里源没有3.12版本所以临时使用官方源,安装完之后恢复阿里源
#当前环境因为是22.04.5 LTS (Jammy Jellyfish)所以自带python3.10.12,若不想安装需要更换系统到Ubuntu 24.04
推荐使用 Python 3.12,避免后端因版本过低报错
创建并激活虚拟环境(推荐)
因为自带的python3.10.12因此更推荐使用虚拟环境配置3.12
cd /llm/open-webui/backend
python3.12 -m venv venv
source venv/bin/activate
pip install -r requirements.txt
# 下载慢时可用国内镜像加速
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple
pip “Can't uninstall 'importlib-metadata'” 警告可忽略

物理环境(不推荐)
pip install -r requirements.txt
可加 -i 参数加速下载
7. 启动服务
启动前端服务(仅限测试)
cd /llm/open-webui
npm run preview -- --host 0.0.0.0
运行后会显示访问端口,也可用 --port 指定固定端口
虚拟环境启动后端(推荐)
cd /llm/open-webui/backend
source venv/bin/activate
bash start.sh
#访问ip地址:8080
#他会访问hg下载模型,这个报错可以不管
#进入web会让你注册管理员账号,注册后进入web


物理环境启动后端(不推荐)
cd /llm/open-webui/backend
bash start.sh
9. systemd 后台服务配置
后端服务(虚拟环境)
vim /etc/systemd/system/openwebui-backend.service
内容:
[Unit]
Description=Open WebUI Backend Service (with Python venv)
After=network.target
[Service]
Type=simple
WorkingDirectory=/llm/open-webui/backend
ExecStart=/bin/bash -c "source /llm/open-webui/backend/venv/bin/activate && exec bash /llm/open-webui/backend/start.sh"
Restart=always
User=root
[Install]
WantedBy=multi-user.target
后端服务(物理环境)
vim /etc/systemd/system/openwebui-backend.service
内容:
[Unit]
Description=Open WebUI Backend Service
After=network.target
[Service]
WorkingDirectory=/llm/open-webui/backend
ExecStart=/bin/bash start.sh
Restart=always
User=root
[Install]
WantedBy=multi-user.target
启用启动后端服务
sudo systemctl daemon-reload
sudo systemctl enable openwebui-backend
sudo systemctl start openwebui-backend
sudo systemctl status openwebui-backend
前端服务(若无必要不用设置,正常使用调用后端即可)
vim /etc/systemd/system/openwebui-frontend.service
内容:
[Unit]
Description=Open WebUI Frontend Service
After=network.target
[Service]
WorkingDirectory=/llm/open-webui
ExecStart=/usr/bin/npm run preview
Restart=always
User=root
Environment=PORT=3000
Environment=HOST=0.0.0.0
[Install]
WantedBy=multi-user.target
启动并启用前端服务:
sudo systemctl daemon-reload
sudo systemctl enable openwebui-frontend
sudo systemctl start openwebui-frontend
sudo systemctl status openwebui-frontend
10. 访问验证
浏览器访问:
http://服务器IP:8080



 浙公网安备 33010602011771号
浙公网安备 33010602011771号