python基础速成指南(列表,字典,循环,函数,类,文件读写)
os:文章有点乱,考虑整个目录索引啥的。
目前更新进度:文件读写
python中,列表的下标可以为负数(-1的意思为倒数第一个元素)
二元列表:(列表套列表)格式:
# 创建一个 pen_bag 列表,代表笔袋
pen_bag = ['笔', '尺子', '涂改液']
# 创建一个 bag 列表,代表书包,并把笔袋 pen_bag 列表作为其中的元素。
bag = ['电脑', '雨伞', pen_bag]
# 在取得 pen_bag 以后,打印 pen_bag 中索引为0的元素。
# 其中 bag[2] 即为 pen_bag
print(bag[2][0])
# 打印 pen_bag 中索引为 0 的元素.
print(pen_bag[0])
列表的切片:
-
切片即在列表中切取一段数据,生成一个新的列表。
-
在切片时,索引 [a:b] 的切取范围是:a <= X < b(左闭右开)
-
冒号左右的值可以不填,不填的时候则代表一取到底。(冒号左边不填相当于等于填了 0,右边不填相当于取到底)。作用:取到+∞/-∞
# 补充第八行的注释,猜猜看会打印出什么列表。 foods = ['虾饺', '龟苓膏', '薄荷冰粉', '四川凉面', '草莓圣代'] # 示例:打印 ['虾饺'],这是由一个元素组成的列表 print(foods[:1]) # 下一行代码会打印出: ['龟苓膏','薄荷冰粉'] print(foods[1:3])同理,元组也如此,可以通过区间切片来查询元素,唯一不同就是不支持append()这样的修改
字符串的修改:
- 在字符串的后面加上 .replace(旧字符串,新字符串) 就可以以新换旧了。
检查序列中的元素:
结合 if 来判断某个元素是否在序列内时,常见写法是:if 元素 in 序列,可以理解为如果某个元素在列表内,就执行一些代码。
skills = ['英语六级', '吉他']
# 吉他在技能列表里吗
if '吉他' in skills:
print('我会吉他。')
# 英语六级在技能列表里吗
if '英语六级' in skills:
print('我英语水平有六级。')
# Python在技能列表里吗
if 'Python' in skills:
print('我还学会了Python。')
统计元素的个数:len()
tup = ('a','b','c')
print(len(tup))
# 输出值为3
计算重复的元素个数:count()
# 创建元组 rabbits
rabbits = ('兔','兔','兔','兔','兔','兔','兔','兔','免','兔','兔','兔','兔','免','兔','兔','兔','兔','兔','兔','兔','兔','兔','兔','兔','兔','兔','兔','免')
# 使用count()计算元组 rabbits 中有多少个'免',并打印
print(rabbits.count('免'))
#输出结果:3
将元组转换为列表:list()
# 创建元组 tup
tup = ('a', 'b', 'c')
# 用list() 将元组 tup 转换为列表,并打印查看结果
print(list(tup))
# 结果:['a','b','c']
当元组中只包含一个元素时,Python 会在元素后面保留一个逗号,这是为了明确区分单个元素的元组和普通的值。
for循环的range()函数:左闭右开
for i in range( 1, 9 ):
print(i)
#输出为1 2 3 4 5 6 7 8,不包含9
format()的应用:跟c++的printf有点像?
print('{}大于{}'.format(n, num))
字典:一种映射,储存键值对

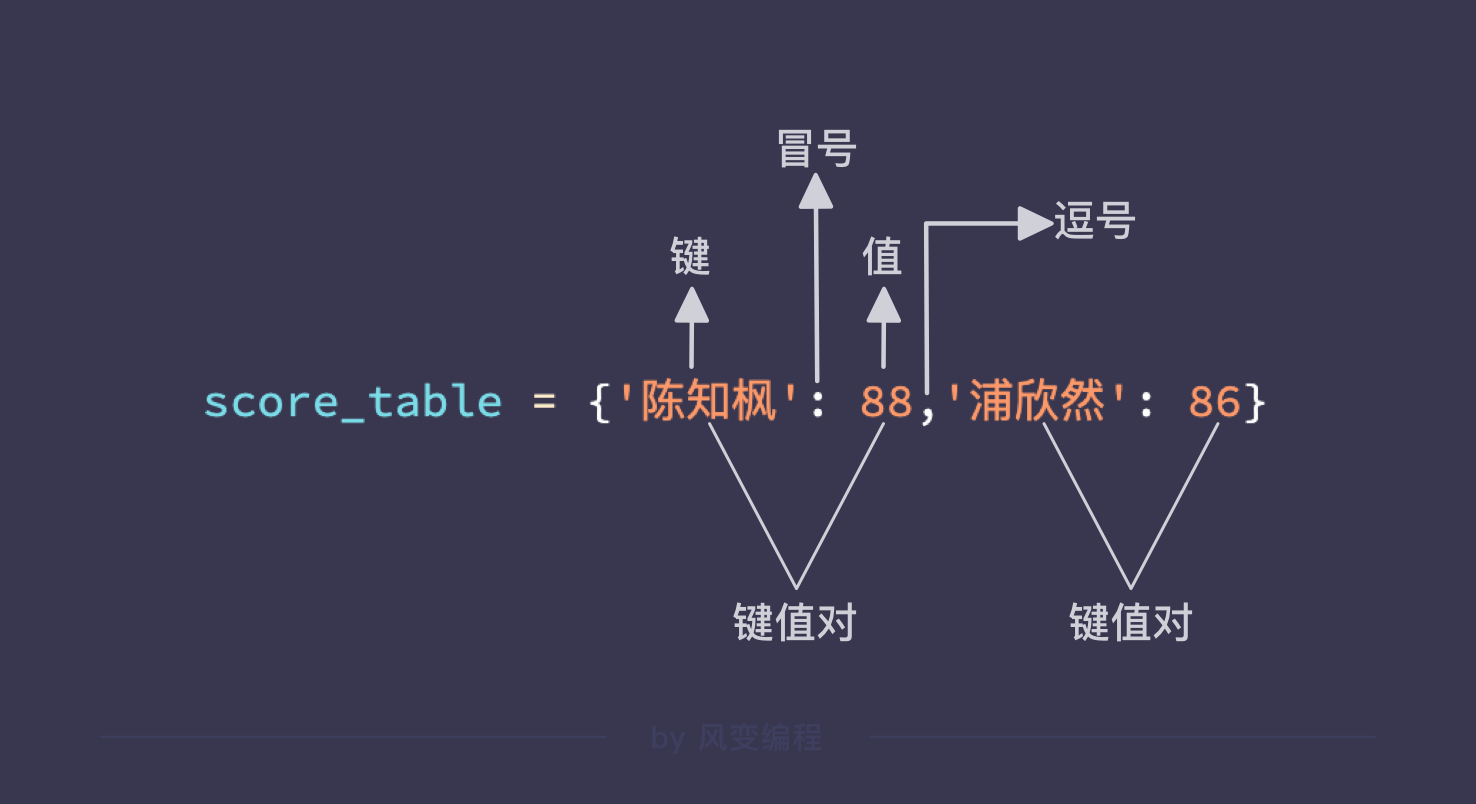
注意:只有字符串、整数、浮点型、元组这些不可变的数据类型才能作为键,而值可以是任何数据类型
总结:字典的调用有两种方式
1.通过键来找值。(如果未找到键会报错)

例子:
print(score_table['陈知枫'])
2.get()函数(如果未找到键会输出None)**
当我们使用 get() 方法来取值时,不管键是否在字典中,程序都不会报错。语法是这样的:
字典.get(键名),例如:score_table.get('小明')。
如果键在字典里:score_table.get('陈知枫')就可以取出对应的值:88。
如果键不在字典:score_table.get('小明')运行的结果就会是 None。
None 是 Python 中一个特殊的值,代表“无”的意思。
get()的用法如下:
score_table = {'陈知枫': 88, '浦欣然': 86}
name = input('请输入学生姓名:')
print(score_table.get(name))

多维字典的查找方式(类似cpp中的多维数组)
num[键1][键2]
给字典中增加新的键值对:
语法格式是:字典[新键名] = 新值
键值对的删除:del 字典[‘键值’]
info = {'性别':'男', '年龄':21, '身高':175.5, '特长':'吉他'}
# 删除键值对:特长是吉他
del info['特长']
# 检查一下,是否删除成功了!
print(info)
函数:
def 函数名(参数):
代码块

多个位置参数:(同cpp)
# 定义函数名为 cloth_machine,参数名为 color, cloth
def cloth_machine(color, cloth):
# 代码块
product = color + cloth
print('轰隆隆,制造' + product)
# 调用函数,按照定义的参数
cloth_machine('黑色', '西服')
默认参数:提前在def 中设置
# 参数 color 在定义函数时直接赋值为'白色'
def cloth_machine(cloth, color='白色'):
# 代码块
product = color + cloth
print('制造一件' + product)
# 调用函数,并传入参数值
cloth_machine('羽绒服')
在使用默认参数时,默认参数的位置必须要在位置参数后面,不然就会报错。
返回值:return
# 定义函数 cloth_machine
def cloth_machine():
product = '一件衣服'
return product
# 调用函数,并将返回值赋值给变量 product
print('你得到了' + cloth_machine())
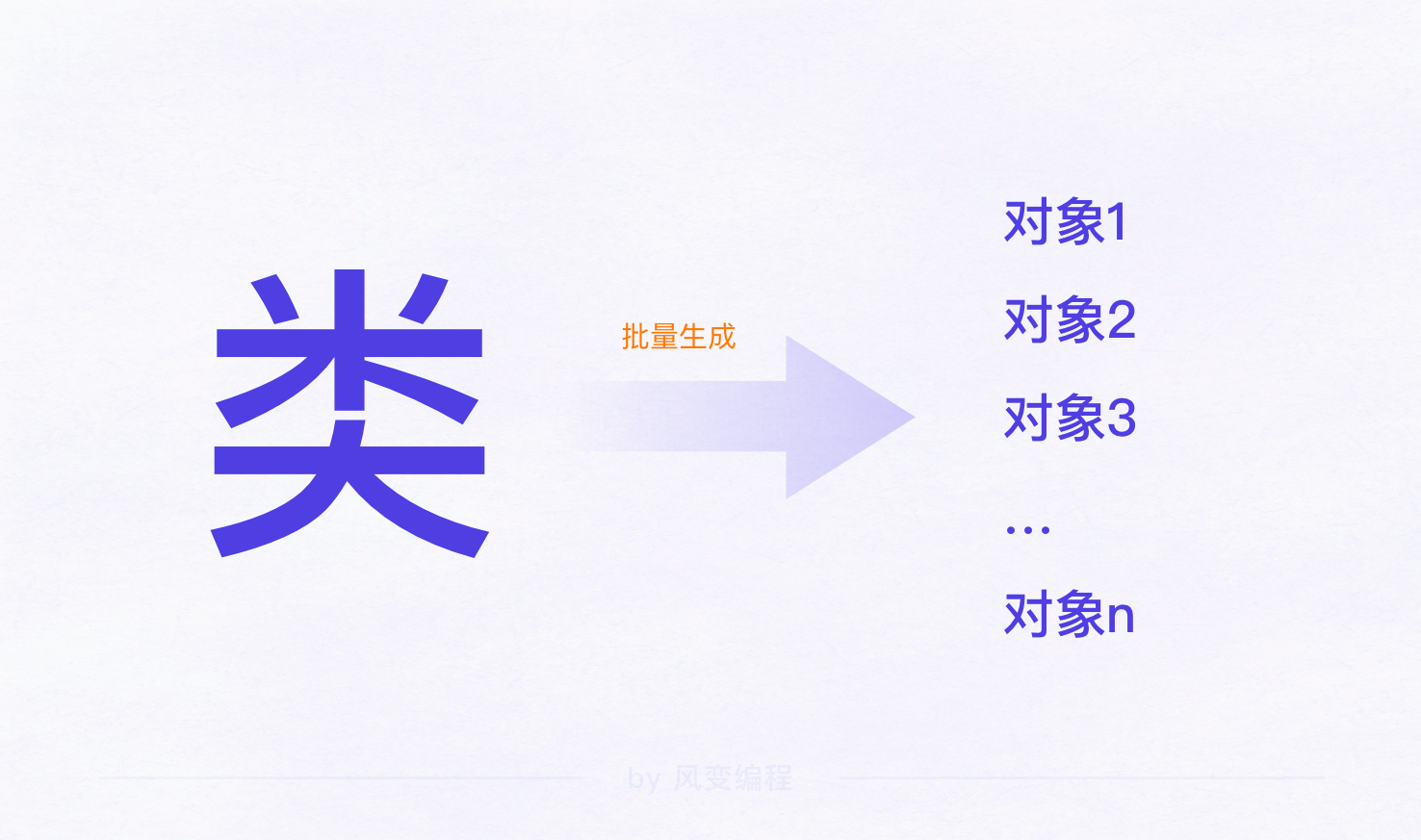
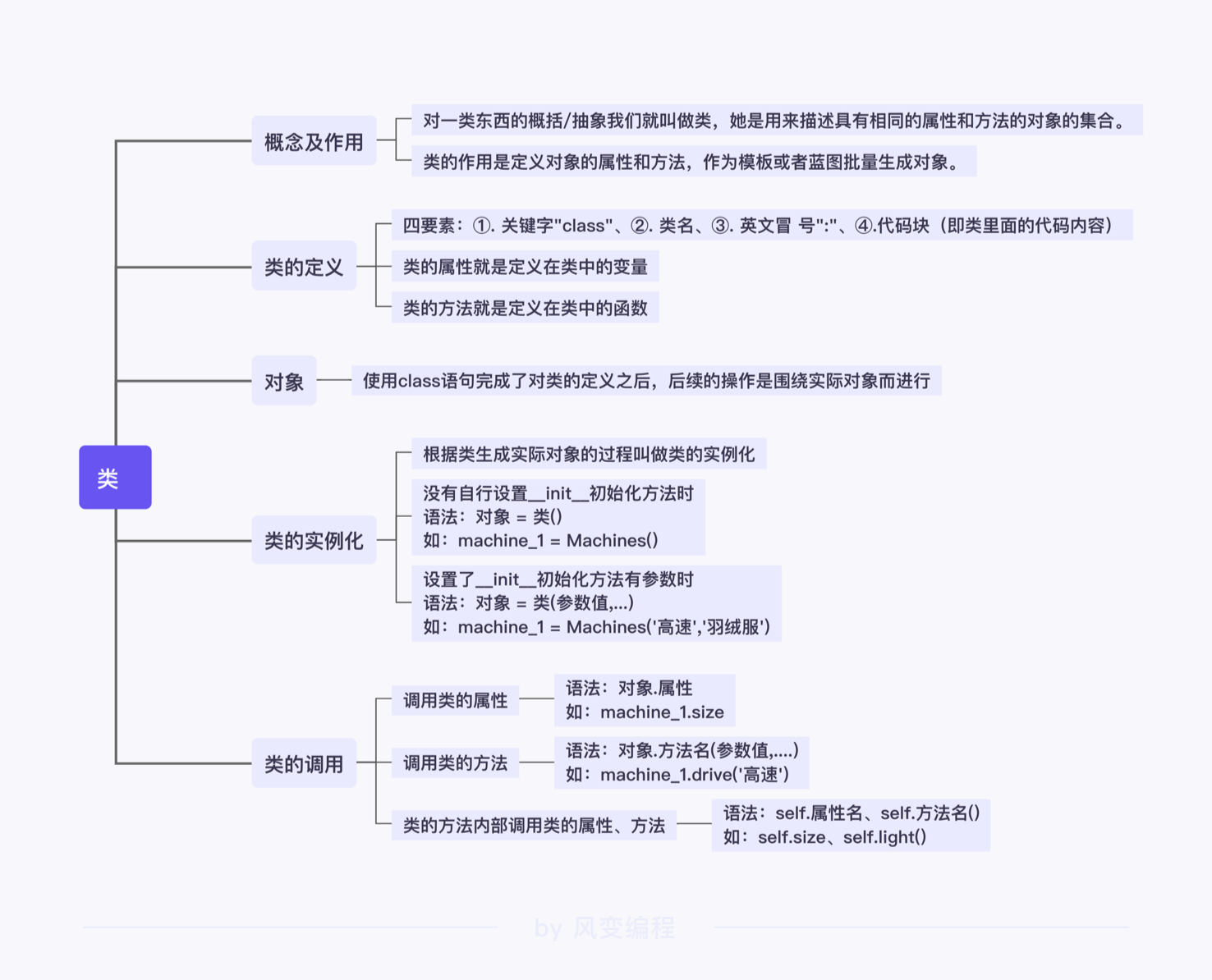
类:具有相同的属性和方法的对象的集合
类能指导对象的批量生成,并且让生成的对象能够具有类中定义的属性和方法。
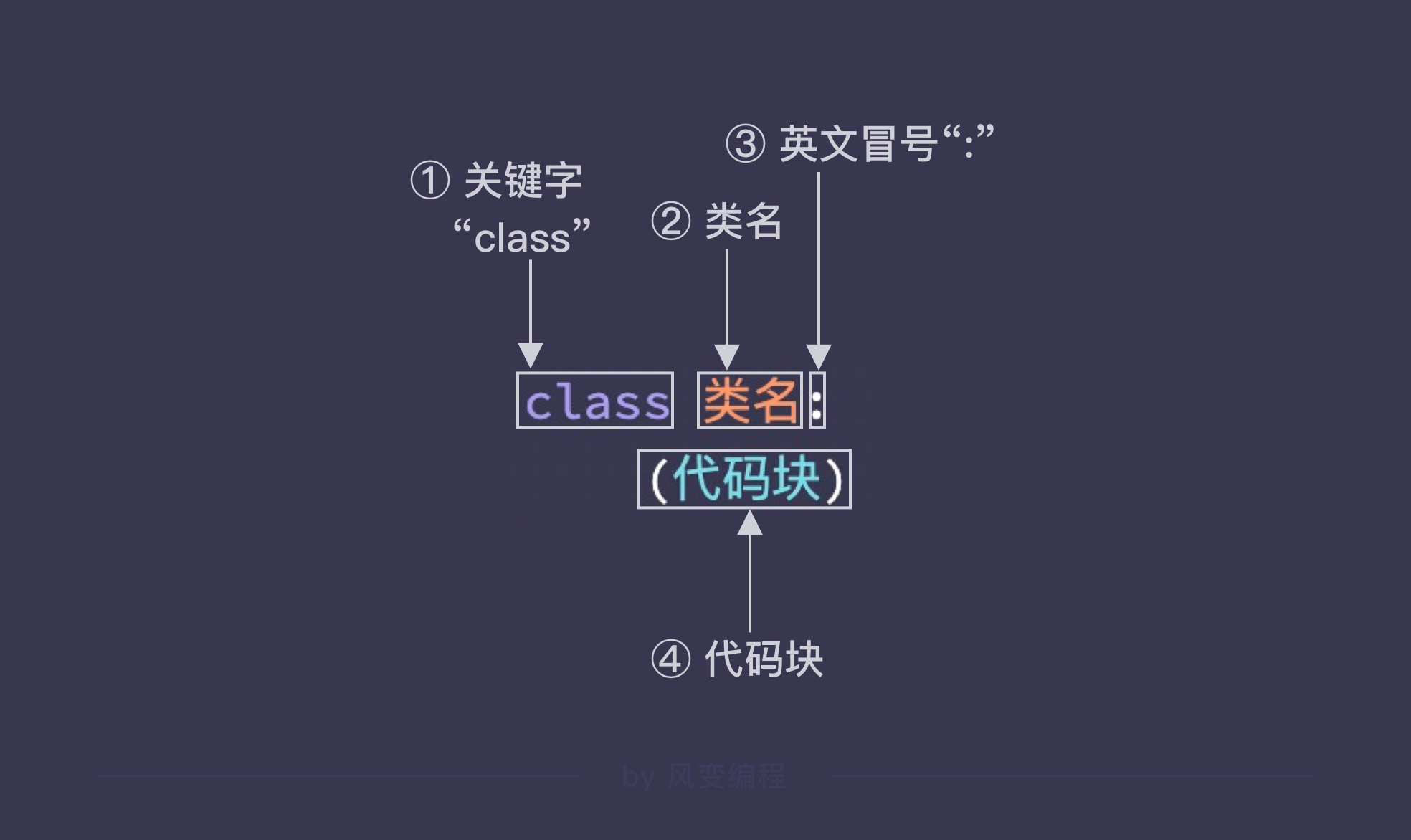
⚠️注意:类名有自己的命名规范,就是首字母一定要大写。
另外在代码块部分的格式上, class 语句和 if 条件判断语句一样,代码块前方要注意缩进。
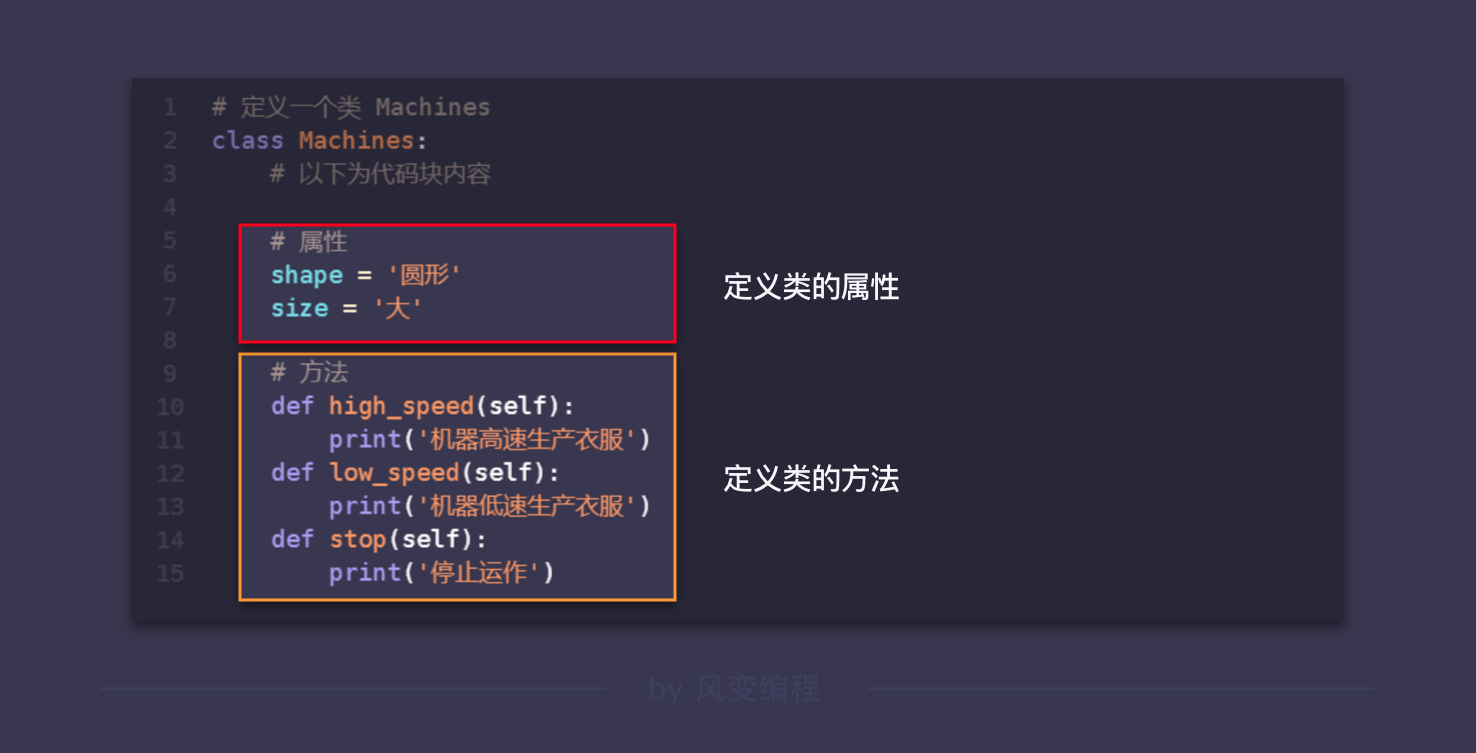
- 属性:类中的变量
- 方法:类中的函数
类的实例化:
对象=类()
类的属性调用:
对象.属性名
eg:
class Machines():
# 属性
shape = '圆形'
size = '大'
# 方法
def high_speed(self):
print('机器高速生产衣服')
def low_speed(self):
print('机器低速生产衣服')
def stop(self):
print('停止运作')
# 实例化
machine_1 = Machines()
# 调用属性并且打印查看
print(machine_1.size)
print(machine_1.shape)
类的方法调用:
- 对象.方法名()
- 对象.方法名(参数值,···)
self参数:
生成的对象在调用类方法时,会把自身的信息传递给方法里的参数 self。
因此,在进行类的方法定义时,会默认在括号里加上 self 参数。
而 self参数 代表的就是生成的对象本身,所以不需要给其额外传参。

可以在类的方法中引用所在类的属性和函数,格式是self.属性名|self.方法名()
class Machines():
#属性
shape = '圆形'
size = '大'
# 定义方法名为 drive
def drive(self):
print('装载了{}发动机的{}制造机轰隆隆,生产衣服'.format(self.shape,self.size))
# 实例化名为 machine_1 的对象
machine_1 = Machines()
# 调用方法,按照定义的参数
machine_1.drive()
重要:
__init__()初始化
init的作用:不用调用,在实例化之后就之间开始运行。
初始化的设置语句:
def __init__(self, size, shape):
xxxx
init中所需要的参数在实例化的时候填入空格之中
文件的读写(重要)
csv文件:excel的变形。
csv 是 “Comma-Separated Values(逗号分割的值)” 的首字母缩写。
当你对于表格样式没有要求时,可以使用 csv 文件来存储数据,相比 Excel,读写速度会快上许多。
直接打开是纯文本,用excel打开是表格。被视为简化版的电子表格。
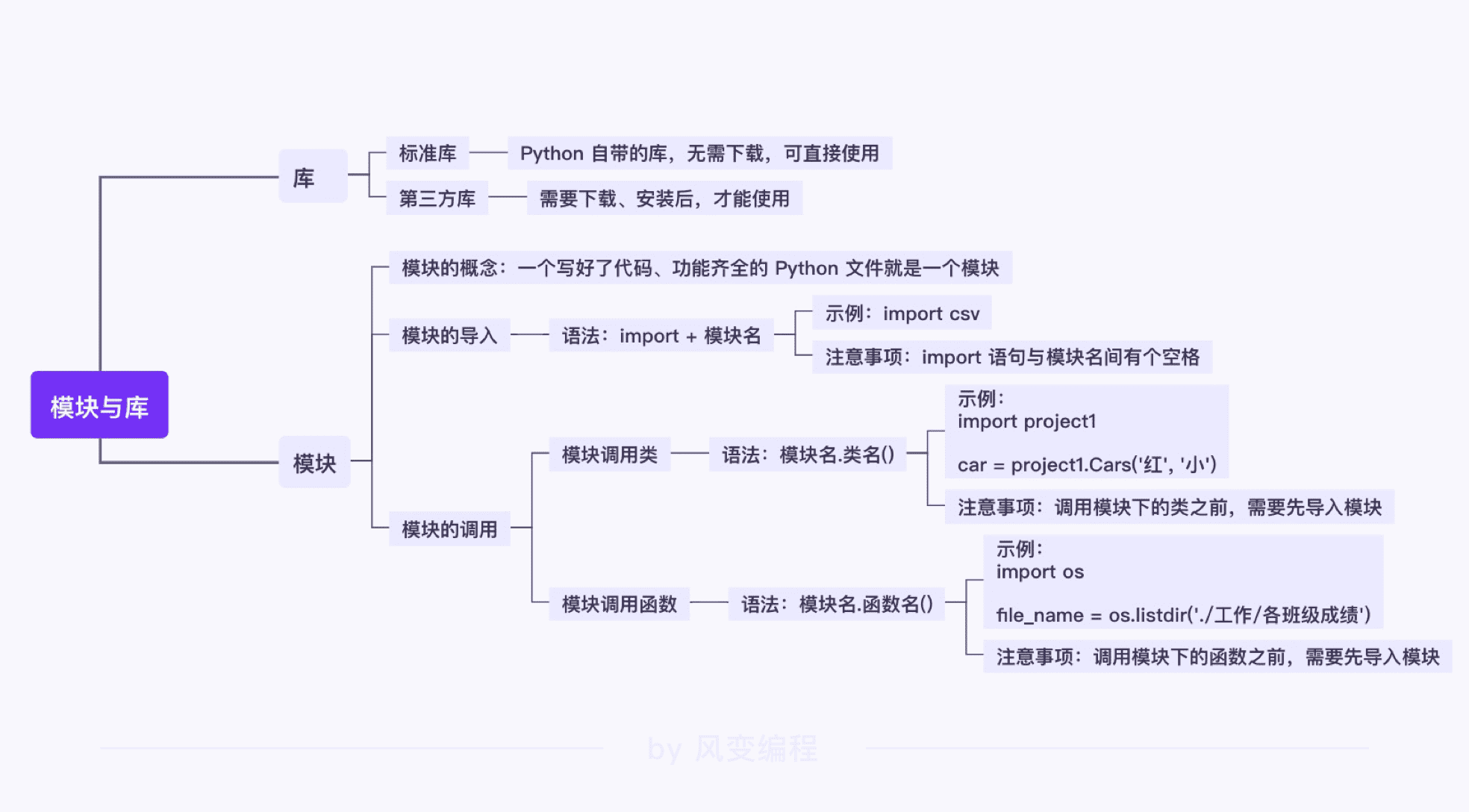
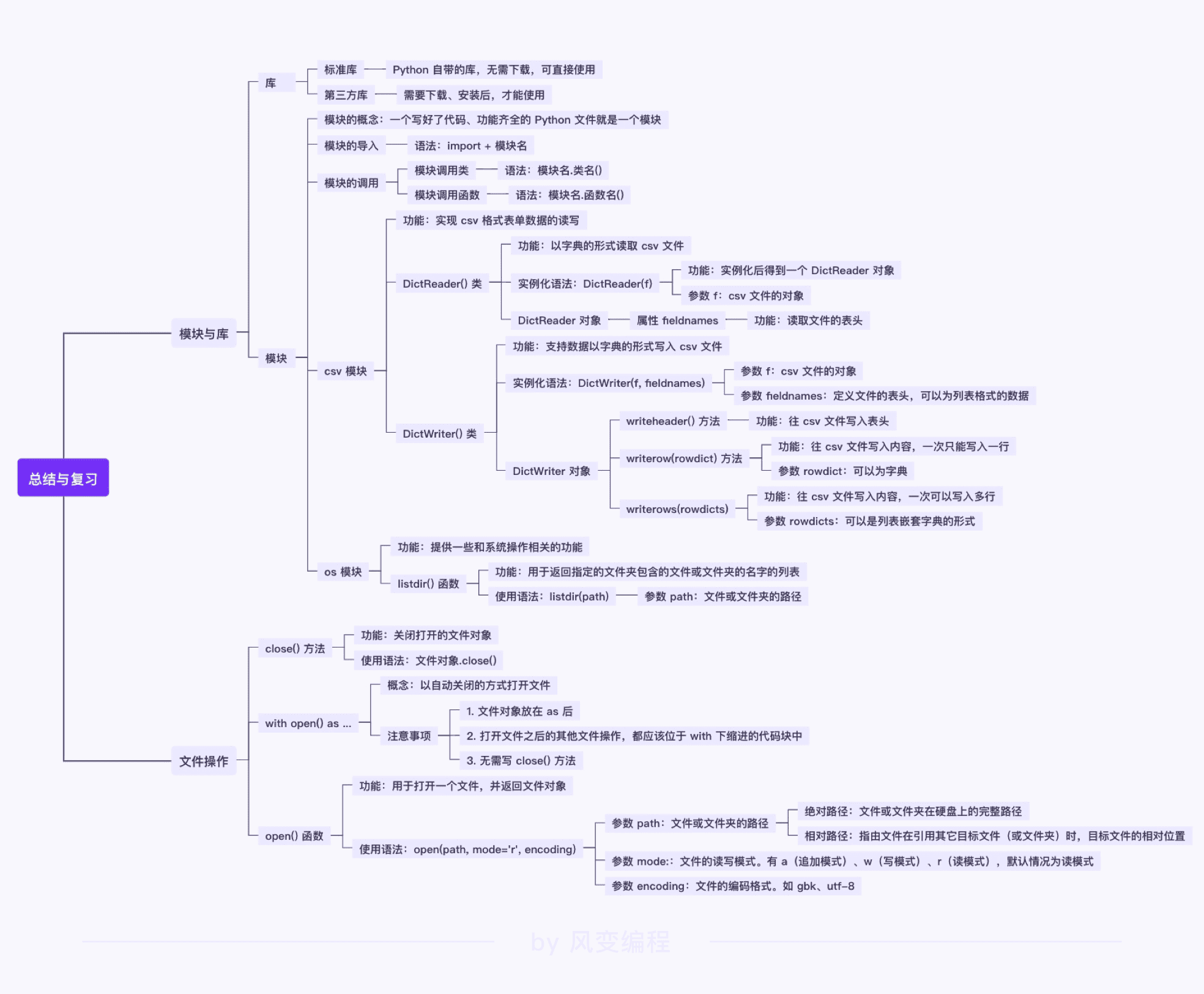
库的类型:标准库,第三方库
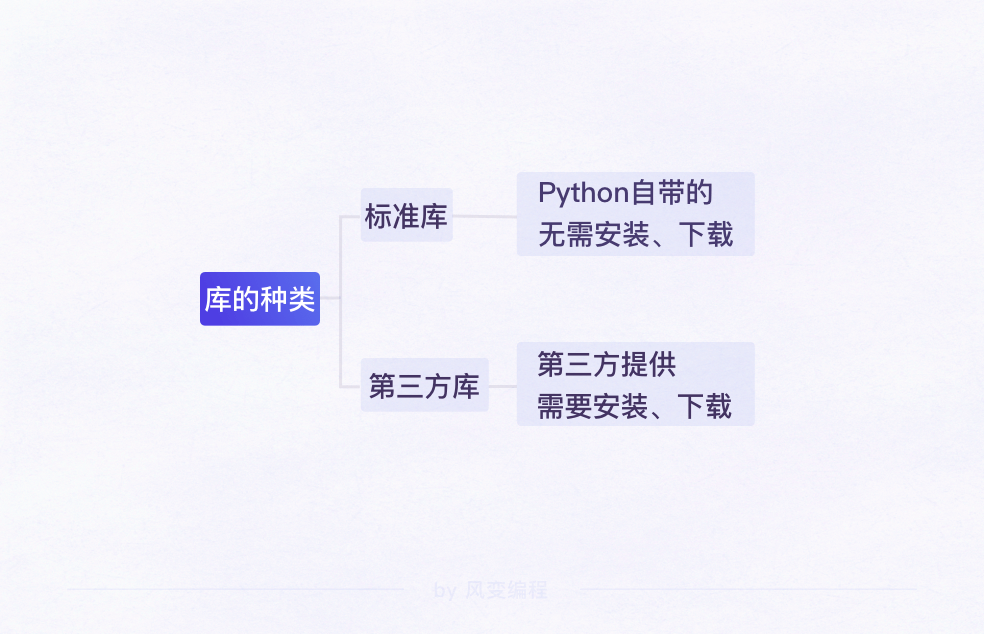
csv 模块由一个 Python 文件组成,是 Python 标准库的内置模块
模块:一个 Python 文件,一个写好了代码、功能齐全的 Python 文件。

导入模块:import+函数名
import csv
调用模块中的某一个类、函数或变量的语法如下:
1)调用模块下的类:模块名.类名(),如 csv.DictReader();
2)调用模块下的函数:模块名.函数名(),如 os.listdir();
3)调用模块下的变量:模块名.变量名,如 os.SEEK_SET。
os模块:读写相关
os 模块提供了一些和系统操作相关的功能。模块下的 listdir() 函数用于返回指定文件夹下,文件或文件夹名字的列表。
导入模块中的类语法:from 模块名 import 类名
类的实例化语法:对象 = 类名()
open函数:打开文件
open() 函数用于打开一个文件,并返回一个 file 对象(即文件对象),后面,我们将调用文件对象的相关方法进行读写。
调用 open() 函数的常用语法为:f = open(file, mode, encoding)。

-
file :需要打开的文件路线

路径的写法有两种:绝对路径和相对路径。
绝对路径是文件或文件夹在硬盘上的完整路径,永远都是根目录开头,具体的文件或文件夹名称做结尾。
在 Windows 系统中,绝对路径的开头是磁盘名称,如 C: 或者 D:,而在 Mac 系统中,绝对路径会使用"/"作为开头。
相对是指相对于当前目录,“相对路径”就是针对“当前目录”这一参考对象,描述文件路径的形式。相对路径使用两个特殊符号:点(.)和双点(..)。
点(.)表示文件或文件夹所在的当前目录,双点(..)表示当前目录的上一级目录。
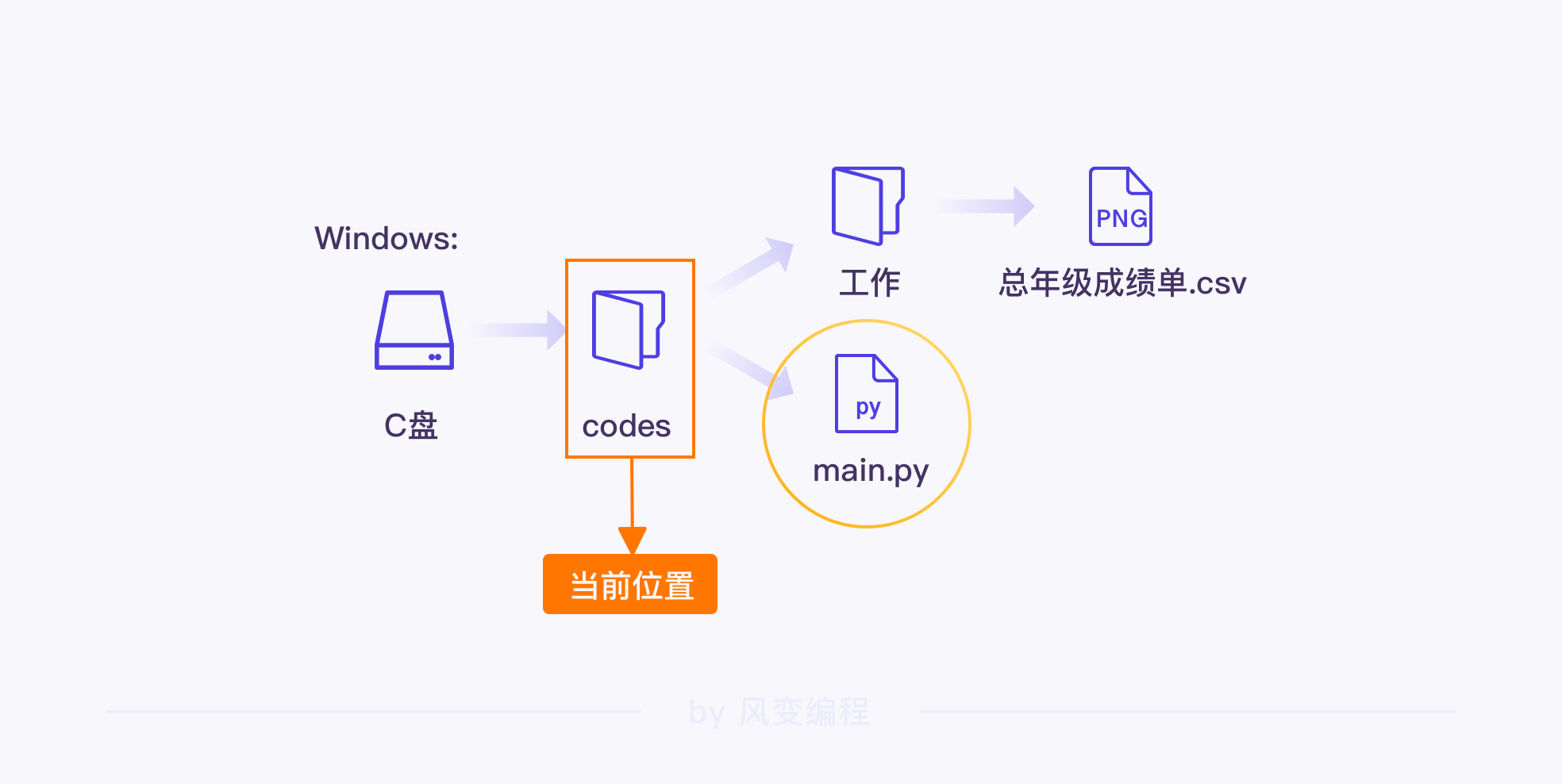
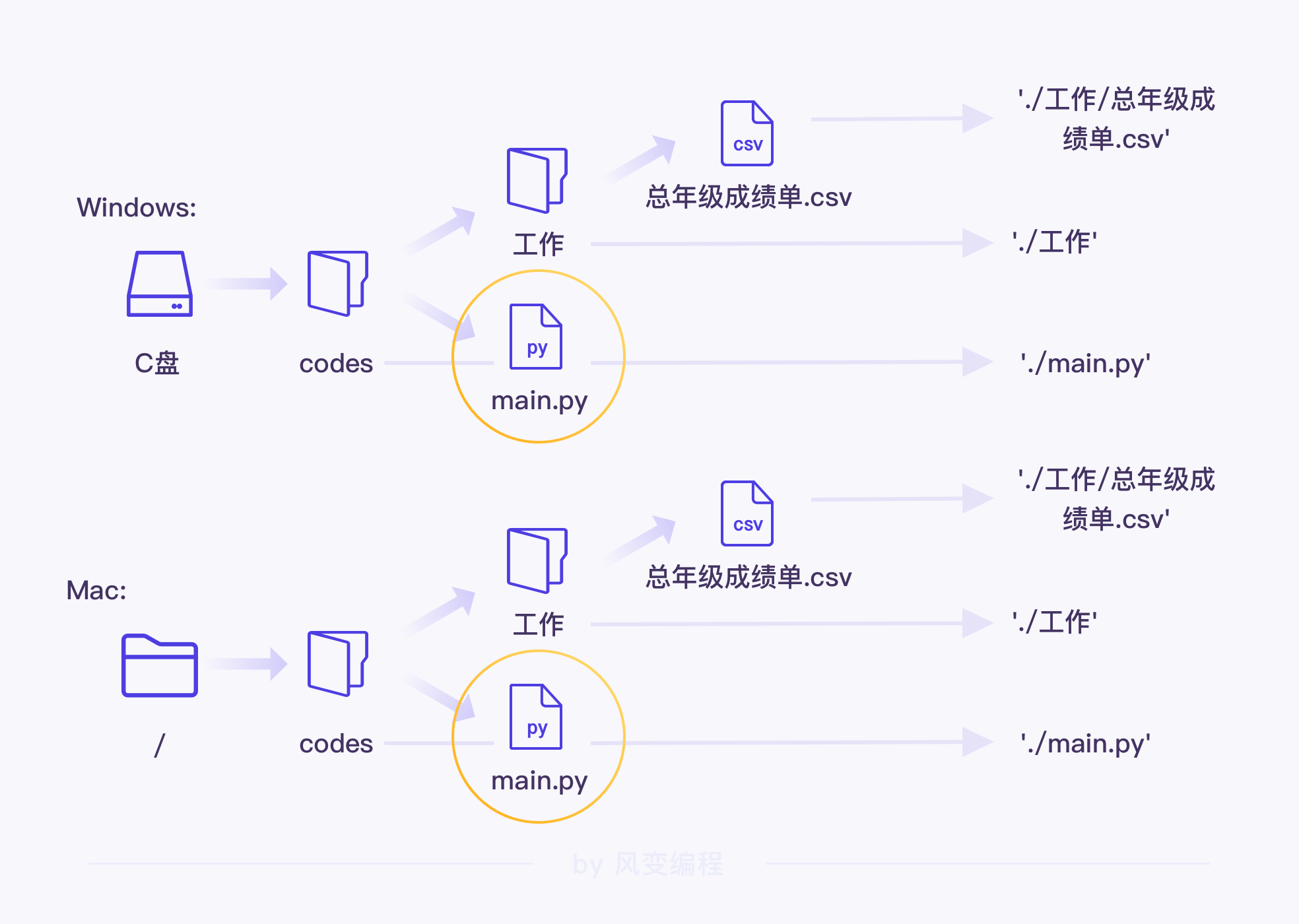
相对路径这一块我有点晕,问了一下豆包:
简单说:
.就是 “当前站的地方”,找当前文件夹里的东西用它开头;..就是 “回到上一层楼”,想访问上层文件夹的内容时用它~
参数mode:打开文件的模式
最主要的模式有:只读(r),写(w),追加(a)等。
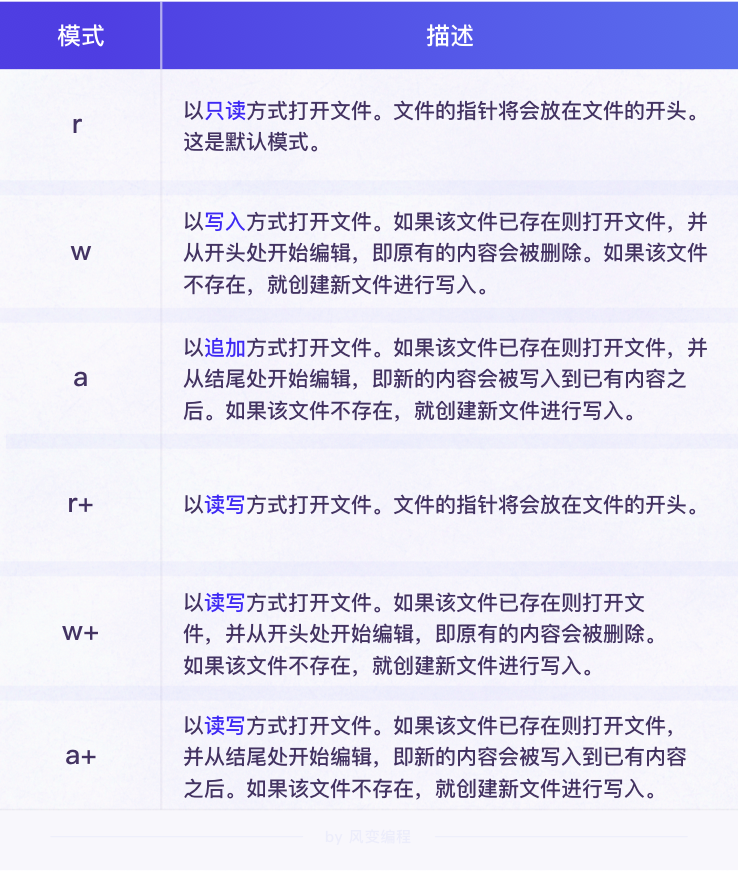
1)参数 mode 的
默认值为 'r'。也就是说,当不设置参数 mode 时,打开文件会默认只读模式。2)当
mode='w',即写模式时,open() 函数会打开一个文件只用于写入,如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被清空。如果该文件不存在,创建新文件。3)当
mode='a',即追加模式时,open() 函数会打开文件并追加写入内容。如果该文件已存在,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。mode 为 'w' 和 'a' 模式的功能可能有点不好理解。没关系,后面学习文件写入时,我会给你展示两种模式带来的效果。
你需要记住的是,当我们要对文件进行读取时,需要使用到
mode='r',即只读模式打开文件。当需要对文件进行写入时,需要使用到mode='w'或mode='a'的模式打开文件。上面的文字可能感觉有点晕,让我们用下面的逻辑图来展示一下这几种模式的关系会更加直观一些。
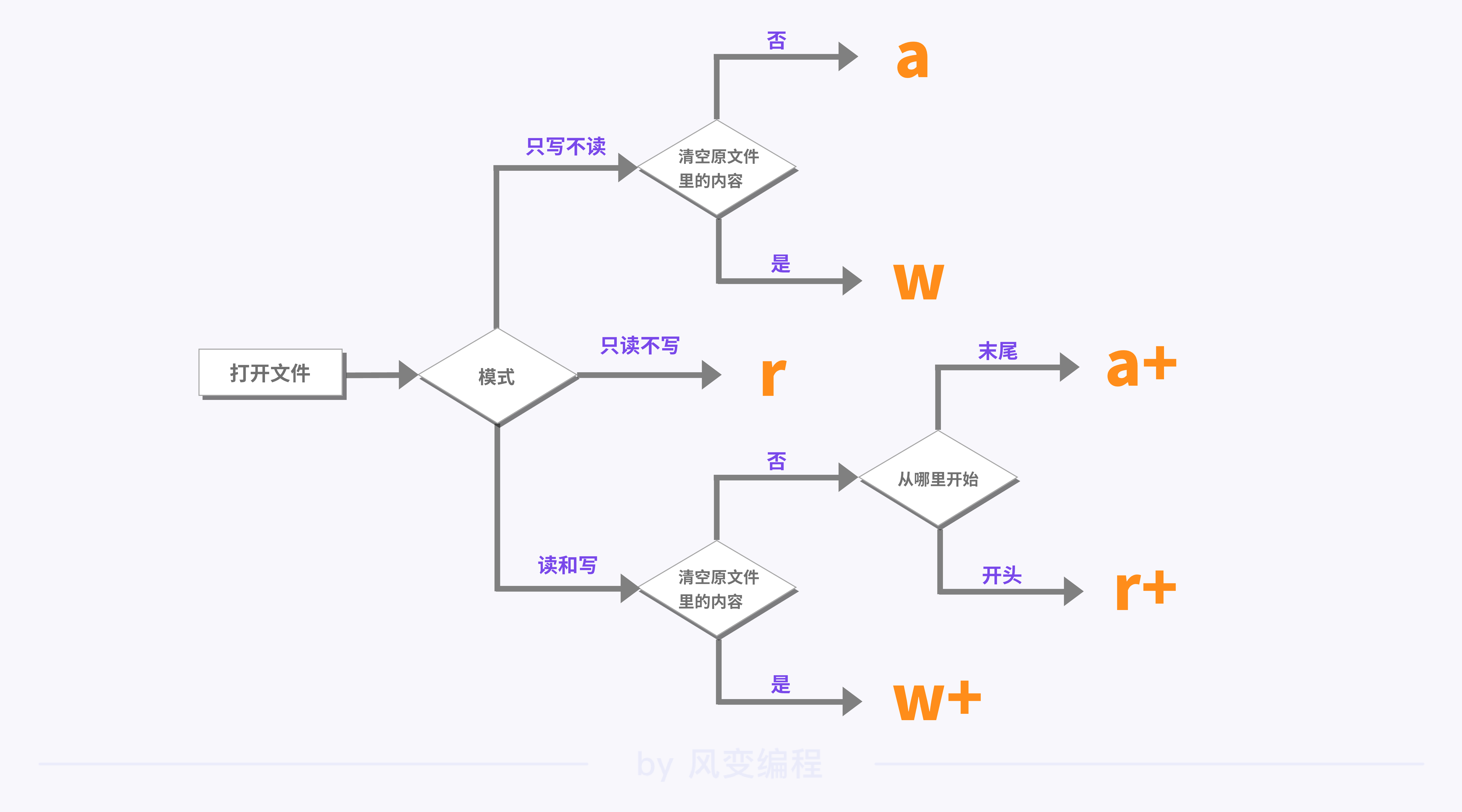
b:转数据的权限
encoding:open()的参数
参数 encoding 表示文件的编码方式,课程中使用到的文件编码方式一般为 'utf-8'。为了避免程序报错或者读取到的内容出现乱码,需要把 encoding 设置为 'utf-8',即写为 encoding='utf-8'。
# 设置【1班成绩单.csv】文件的路径
file_path = './工作/各班级成绩/1班成绩单.csv'
# 使用 open() 函数打开 【1班成绩单.csv】 文件
source_path = open(file_path, 'r', encoding='utf-8')
# 打印变量 source_path
print(source_path)
DictReader() 类:可以以字典的形式读取 csv 文件。
实例化 DictReader() 后,会得到一个 DictReader 对象。
# 导入 csv 模块
import csv
# 设置【1班成绩单.csv】文件的路径
file_path = '../工作/各班级成绩/1班成绩单.csv'
# 以只读模式打开 csv 文件,文件编码为 utf-8
source_path = open(file_path, 'r', encoding='utf-8')
# 以字典的形式获取 csv 文件信息
file_dict = csv.DictReader(source_path)
# 打印字典的数据
for row in file_dict:
print(row)
# 关闭文件
source_path.close()
类 DictReader() 的实例化语法为:DictReader(f)。其中参数 f 为 csv 文件的对象。
使用 open() 函数打开 csv 文件后,函数会返回一个文件对象。
从右方代码的第 8 行可以看到,返回的文件对象赋给了变量 source_path。
第 11 行,将文件对象 source_path 传给 DictReader() 的参数 f,完成类 DictReader() 的实例化。
PS:DictReader的fieldnames属性,可以读取到文件的表头
close():关闭文件
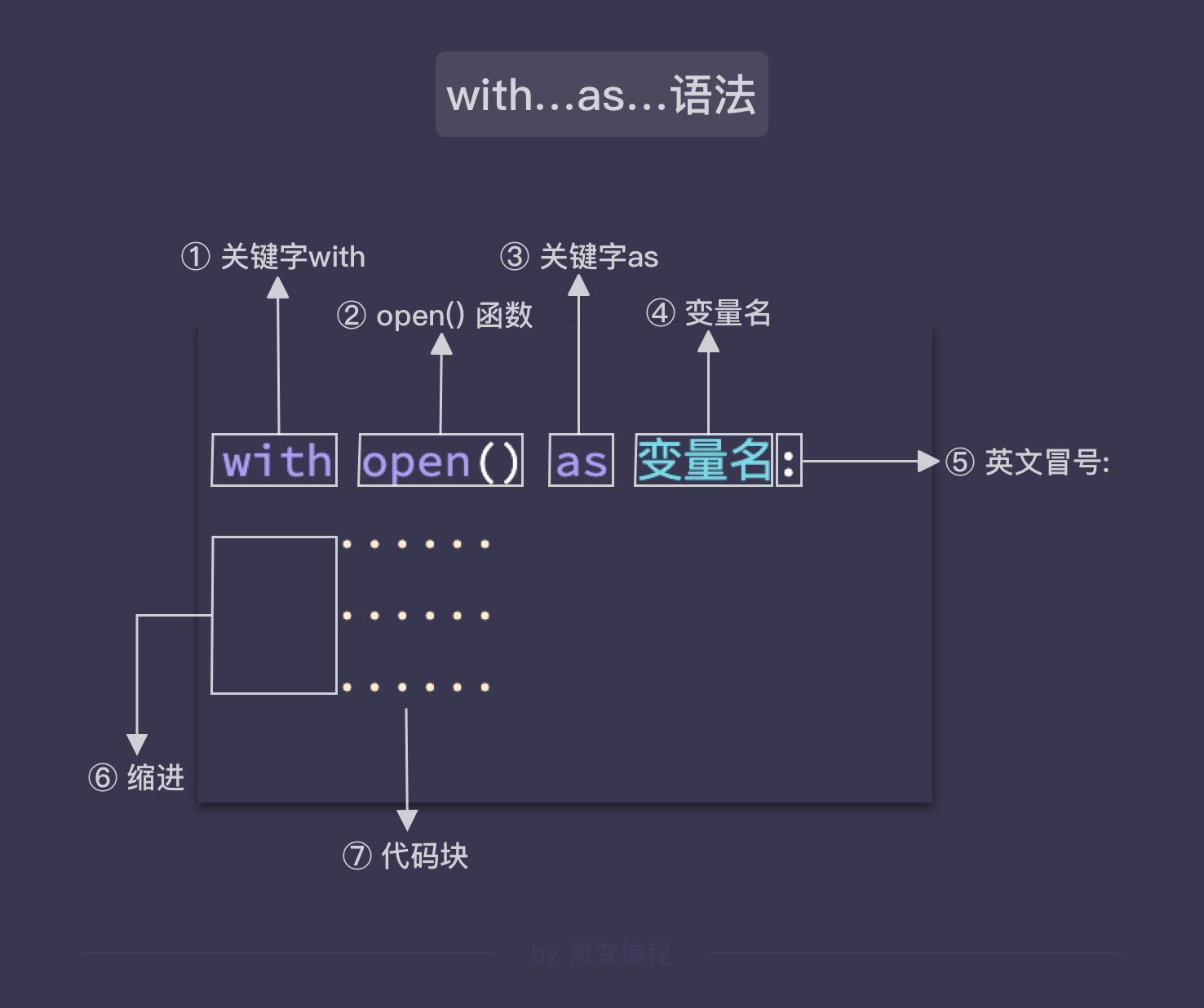
with open() as ... 是对原有 open() 和 close() 的优化。
使用 with open() as ... 语句后,在 with 下面的代码块结束时,会自动执行 close() 关闭文件。
用法是把 open() 函数放在 with 后面,把变量名放在 as 后面,结束时要加冒号 :,然后把要执行的文件处理语句缩进到 with open() as ... 下方的代码块中。
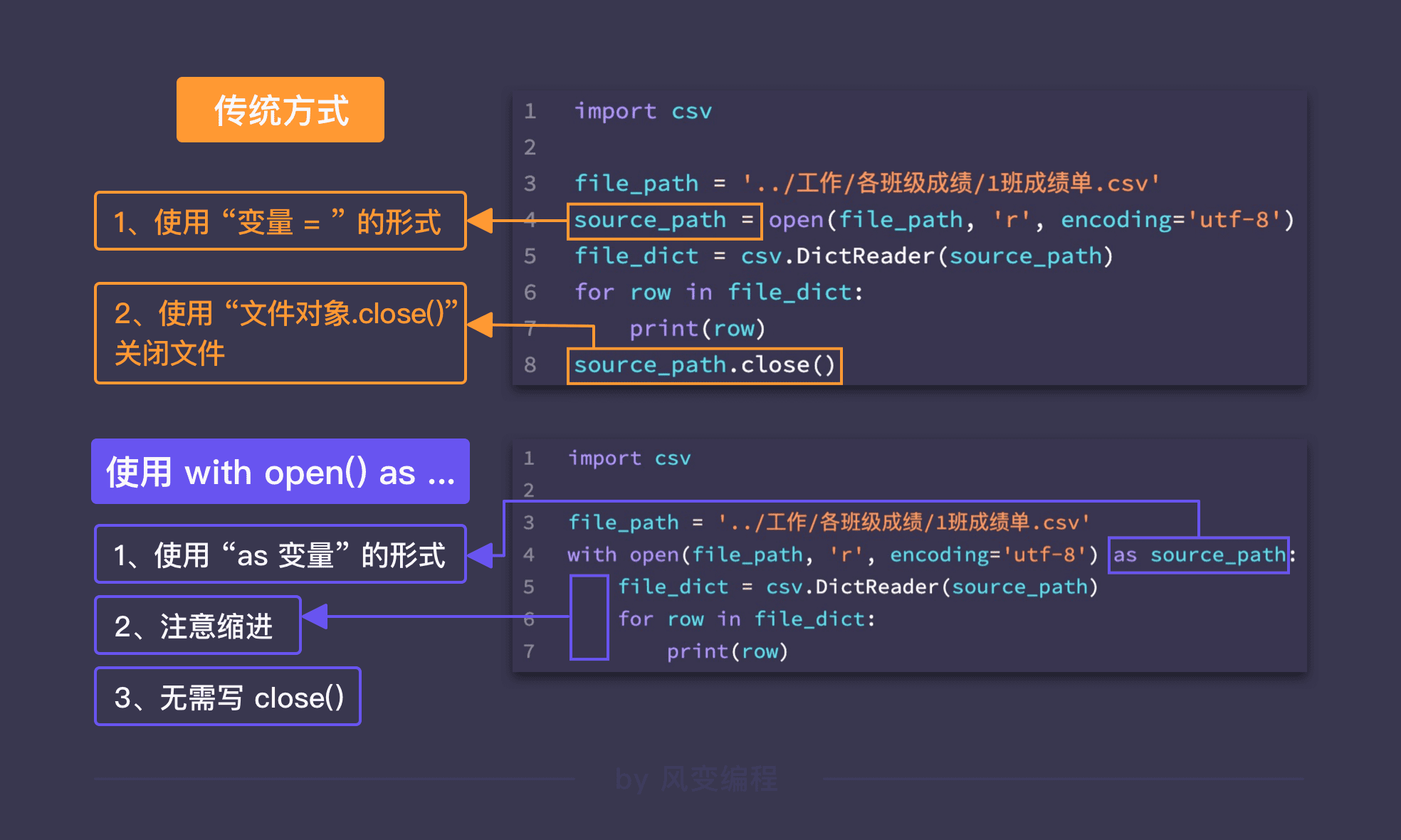
文件的写入:mode=‘w’
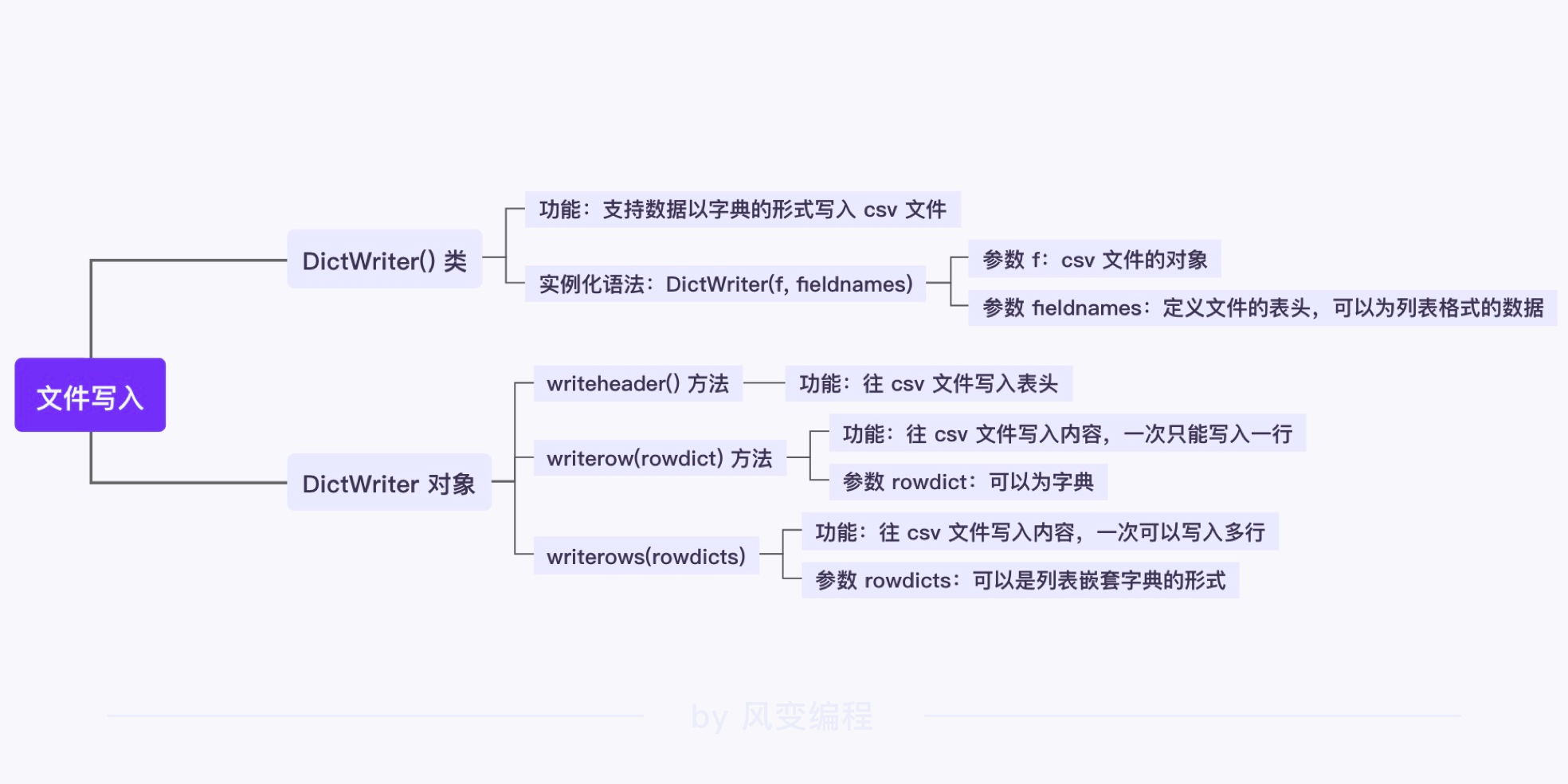
- DictWriter(xxx,fieldnames=head):实例化,载入表头。
- xxx.writeheader() :写入表头
- xxx.writerow(???):按照字典,写入每行内容。row的意思是行。
# 导入 csv 模块
import csv
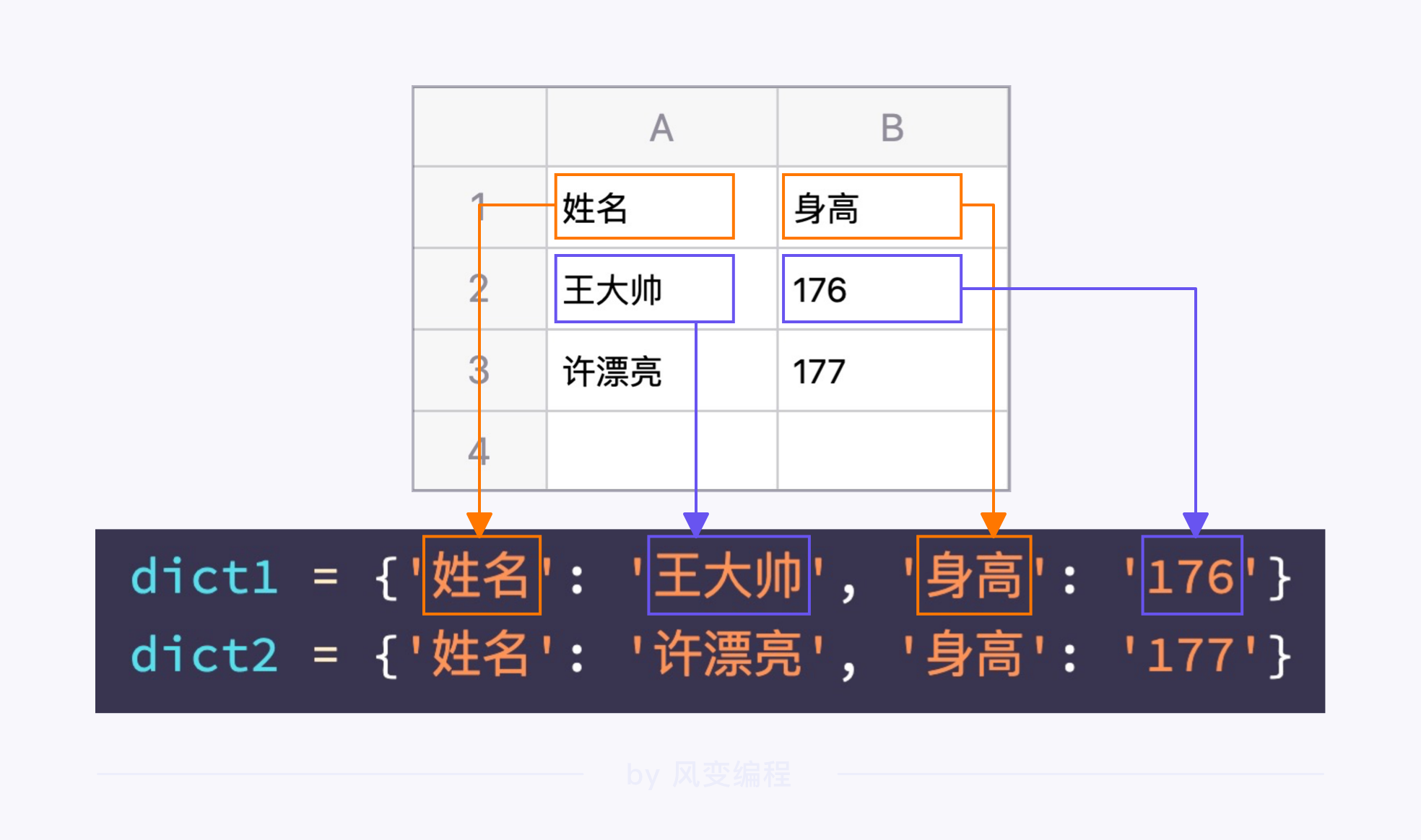
# 新建两个字典
dict1 = {'姓名': '王大帅', '身高': '176'}
dict2 = {'姓名': '许漂亮', '身高': '177'}
# 设置文件的表头
head = ['姓名', '身高']
# 设置总文件路径
file_path = '../工作/学生体检表.csv'
# 以自动关闭的方式打开文件
with open(file_path, 'w', encoding='utf-8') as f:
# 实例化类 DictWriter(),得到 DictWriter 对象
dict_write = csv.DictWriter(f, fieldnames=head)
# 写入文件的表头
dict_write.writeheader()
# 写入文件的单行内容
dict_write.writerow(dict1)
dict_write.writerow(dict2)
优化版:writerows(rowdicts),可以避免重复的插入每行内容的writerow()
上述代码最后两行改为如下:
dict_write.writerows([dict1, dict2])
代码将两个字典通过 [] 放在一个列表中,再传给方法 writerows()。无需我们将多个字典传给多个 writerow() 方法。
文件的读取与写入:
os模块中的listdir()函数可以返回文件夹包含的文件或文件夹名的列表。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号