🎯 设计模式优化 - 极致的抽象
🎯 阶段3:设计模式优化 - 极致的抽象
优化需求分析:
在流式改造后发现大量重复代码,作为有追求的程序员,需要通过设计模式来优化代码结构,提升可维护性和扩展性。
痛点识别:
-
解析器重复:每种类型都有相似的解析逻辑
-
保存器重复:文件保存流程基本相同,只是细节不同
-
流式处理重复:每种生成模式都写了一套相同的流式处理代码
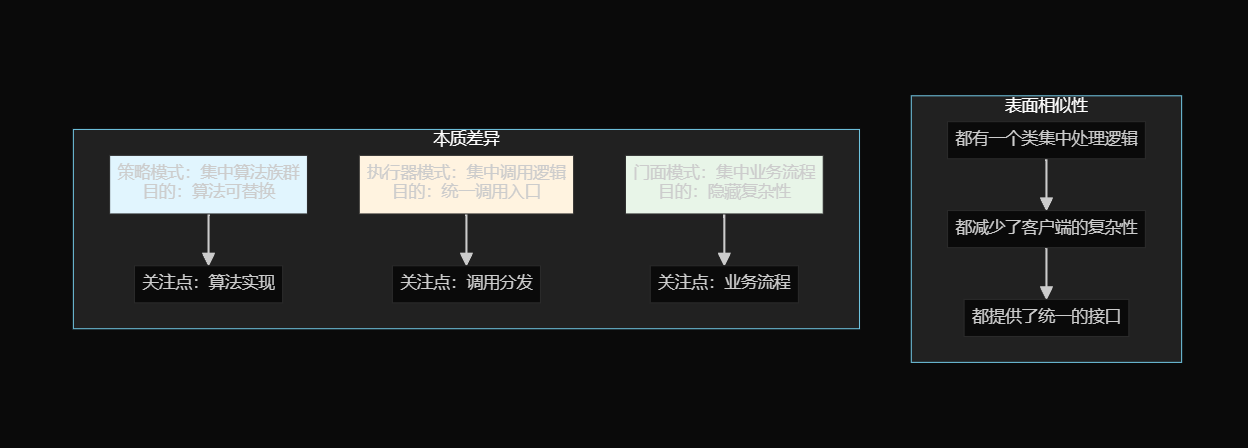
设计模式选择分析:
核心挑战: 不同类型的返回值不同(HtmlCodeResult vs MultiFileCodeResult),传统工厂模式难以处理
解决方案组合:
-
策略模式 - 解决解析算法的封装和替换
-
模板方法模式 - 解决保存流程的统一和定制
-
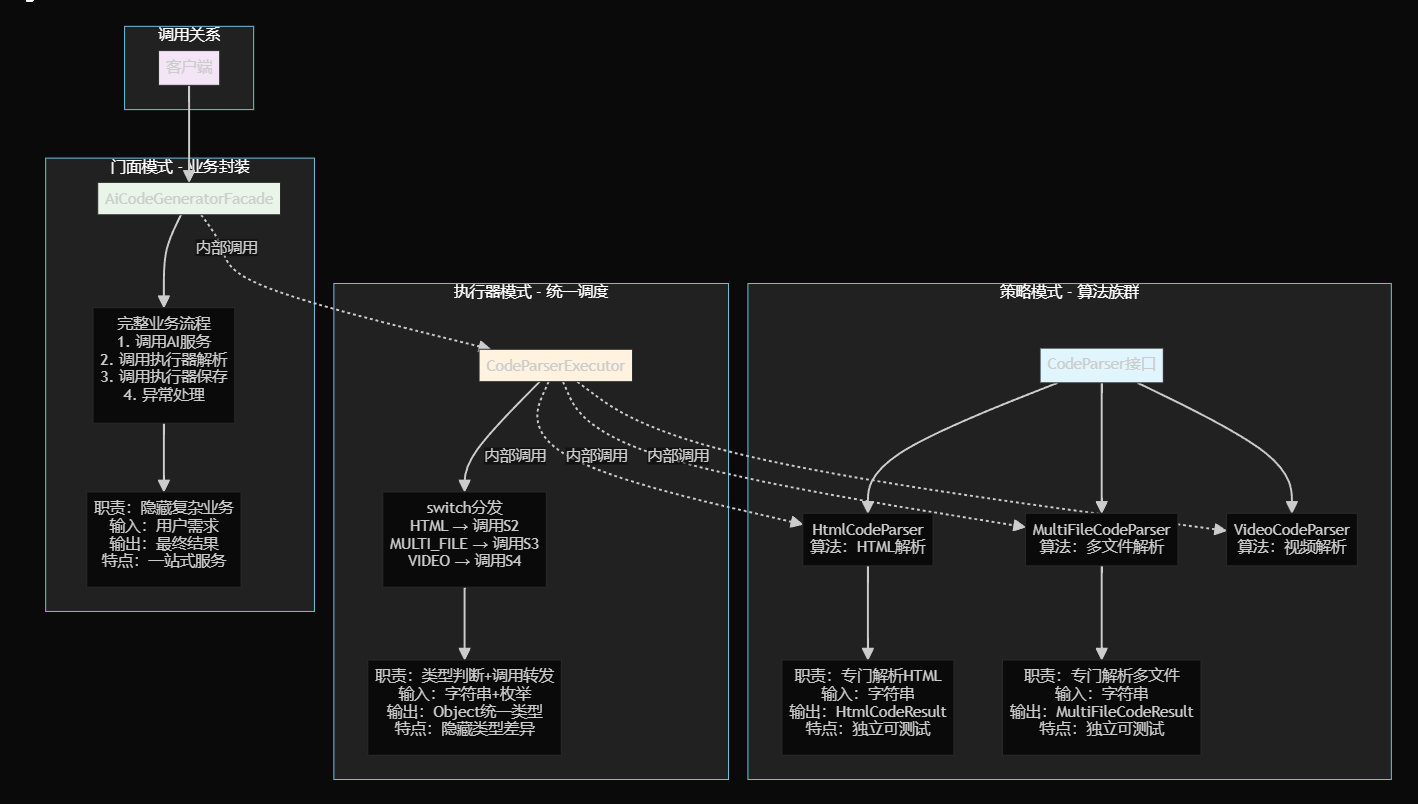
执行器模式 - 解决不同参数类型的统一调用
🏗️ 架构设计思路:
0.各种设计模式的理解
策略模式:一个目标,多种方法。
现实生活的例子:
场景: 你要从北京到上海
不同策略:
-
飞机策略 - 快但贵
-
火车策略 - 中等速度中等价格
-
汽车策略 - 慢但便宜
-
步行策略 - 免费但超慢
关键点: 目标都是"到上海",但方法完全不同
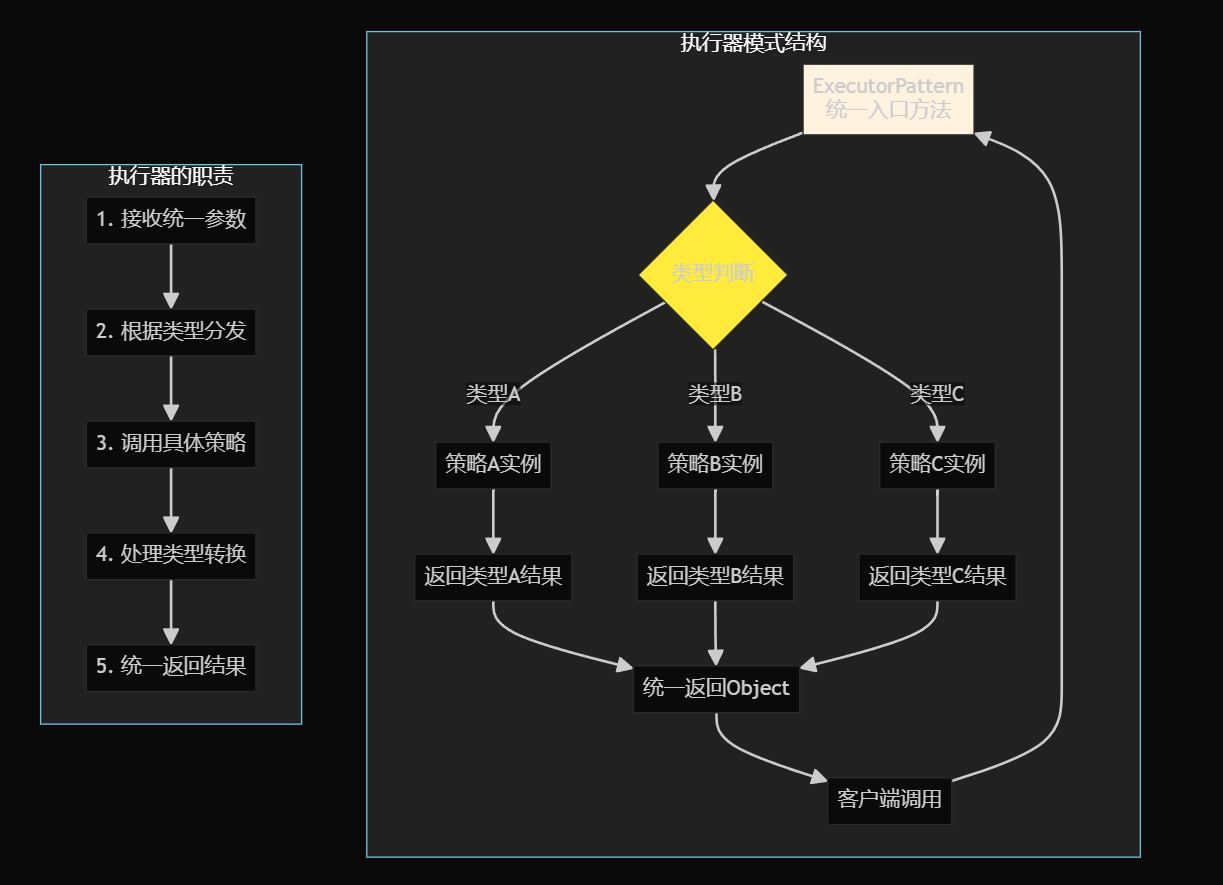
执行器模式:统一接口,内部分化,像医院挂号
一种提供统一执行入口来协调不同策略和模板调用的设计模式,特别适合处理参数类型不同但业务逻辑相似的场景。
1. 策略模式重构解析器
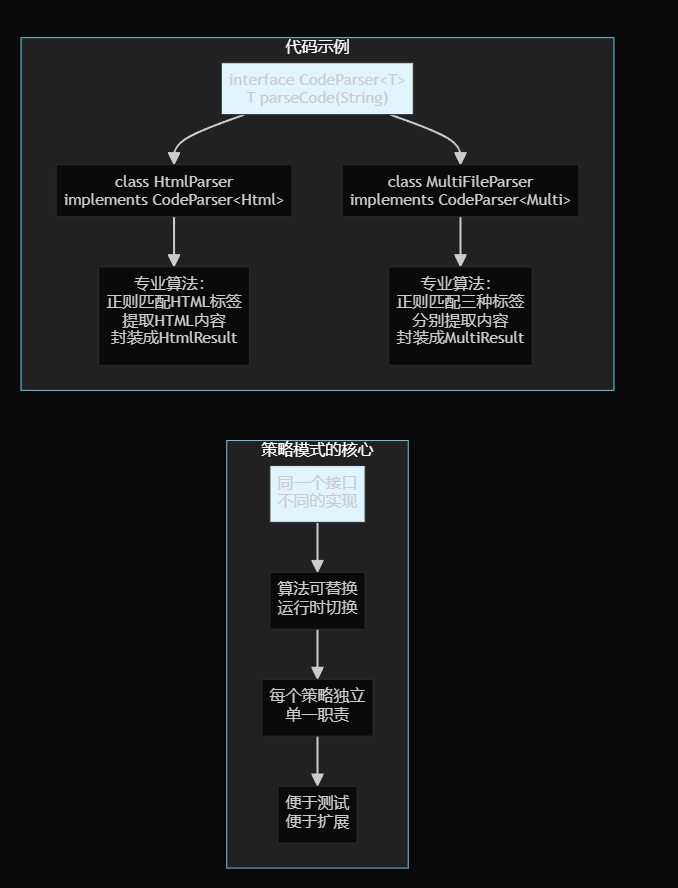
设计理念: 每种解析策略独立维护,职责单一。通过接口统一调用
核心技巧: 使用泛型统一返回值类型
public interface CodeParser<T> {
T parseCode(String *codeContent*);
}
实现分离:
-
HtmlCodeParser - 专门处理HTML单文件解析
-
MultiFileCodeParser - 专门处理多文件解析
-
CodeParserExecutor - 统一调用入口
2. 模板方法模式重构保存器
设计理念: 抽象父类定义保存流程,子类实现具体细节
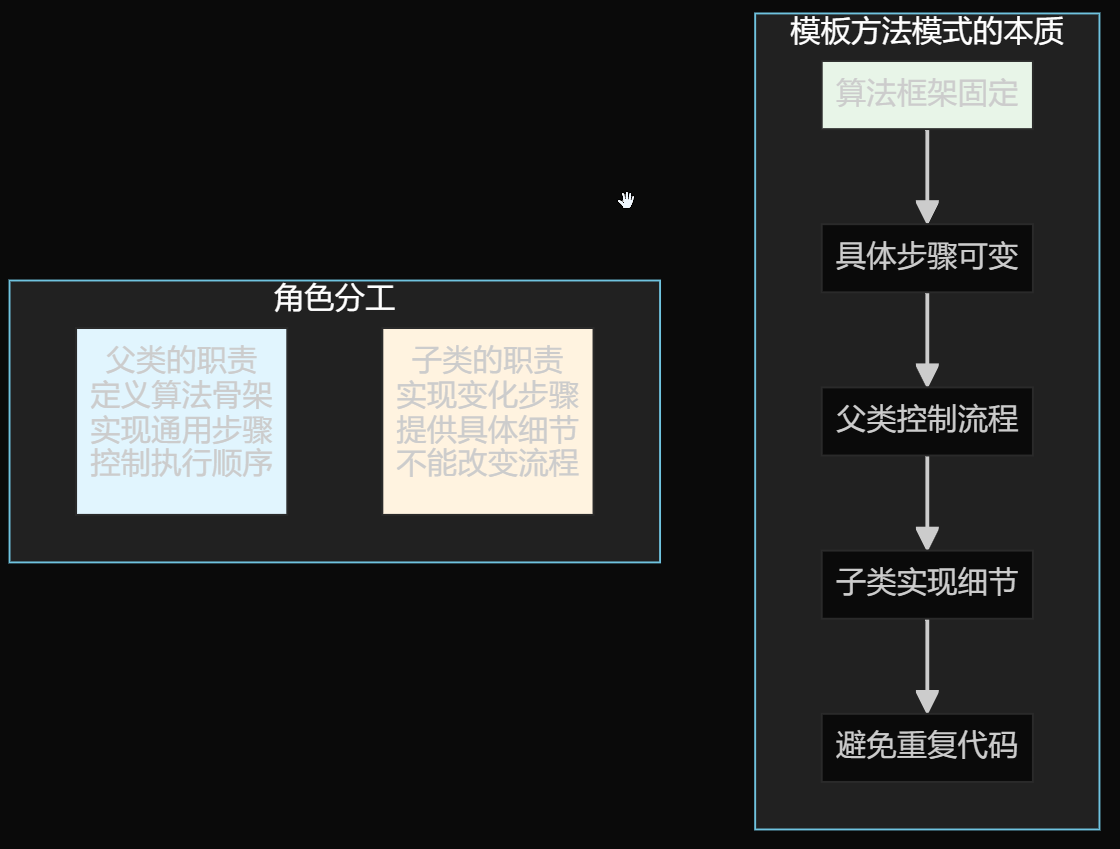
标准流程定义:
public final File saveCode(T result) {
validateInput(result); *// 1. 验证输入*
buildUniqueDir(); *// 2. 构建目录*
saveFiles(result, path); *// 3. 保存文件(子类实现)*
return new File(path); *// 4. 返回结果*
}
差异化实现:
-
HtmlCodeFileSaverTemplate - 保存1个HTML文件
-
MultiFileCodeFileSaverTemplate - 保存3个文件(HTML+CSS+JS)
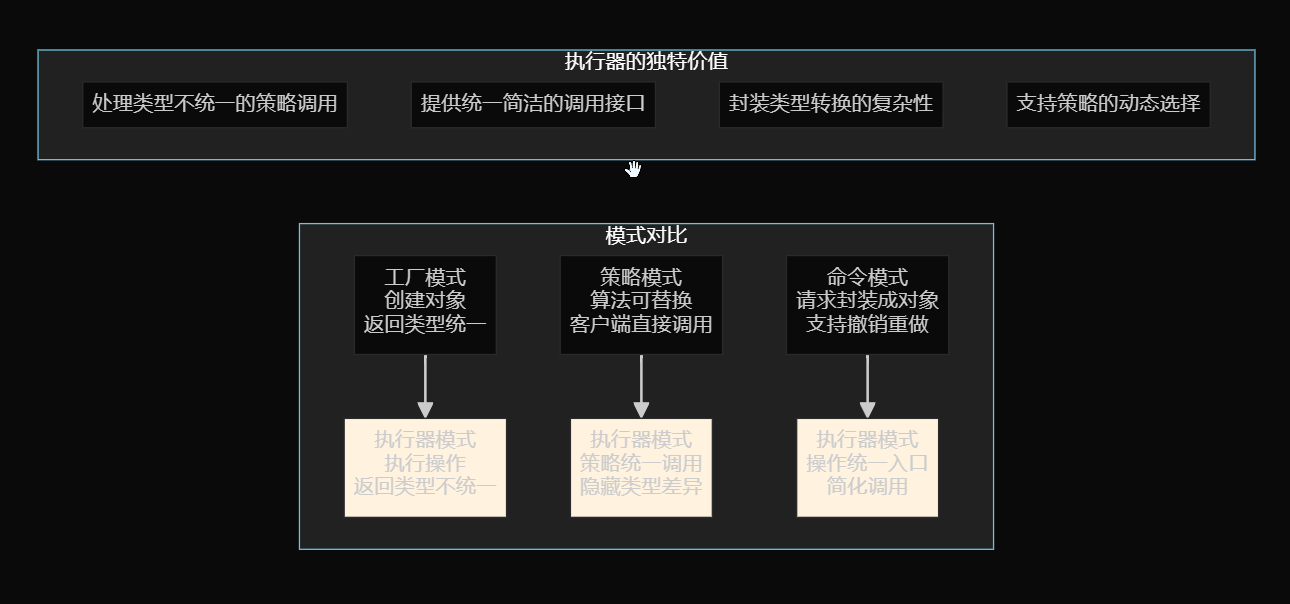
3. 执行器模式统一调用
问题解决: 参数类型不同导致的调用困难,像医院挂号。
统一接口:
*// 统一的调用方式,内部处理类型转换*
Object parsedResult = CodeParserExecutor.executeParser(codeContent, codeGenType);
File savedDir = CodeFileSaverExecutor.executeSaver(parsedResult, codeGenType);
💡 执行器模式的适用场景
✅ 适合使用执行器模式:
-
多种策略返回不同类型
-
策略参数类型不统一
-
需要统一的调用入口
-
希望隐藏类型转换复杂性
❌ 不适合使用执行器模式:
-
策略返回类型统一 → 用工厂模式
-
只有一种策略 → 直接调用
-
策略很少变化 → 简单的if-else即可
🎯 执行器模式的优缺点
优点:
-
✅ 调用简洁:一行代码搞定复杂调用
-
✅ 类型统一:对外提供统一接口
-
✅ 易于扩展:新增类型只需修改执行器
-
✅ 降低耦合:客户端不依赖具体策略
缺点:
-
❌ 类型安全弱化:运行时类型转换有风险
-
❌ 执行器膨胀:随着类型增加,switch变复杂
-
❌ 调试困难:错误可能发生在类型转换阶段
4. 流式处理抽象化
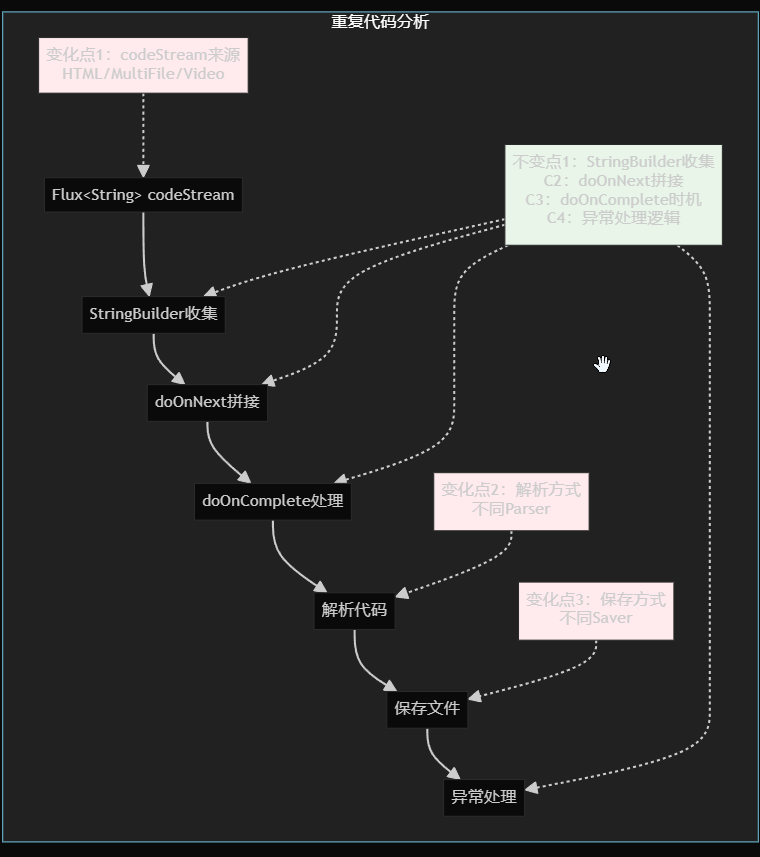
重复代码消除: 抽取通用的processCodeStream()方法
统一处理逻辑:
-
字符串拼接收集
-
执行器解析代码
-
执行器保存文件
-
异常处理和日志
🔄 架构演进对比:
优化前(阶段2):text每种类型 → 独立解析方法 → 独立保存方法 → 独立流式处理
问题: 代码重复,难以维护
优化后(阶段3):
优势: 高内聚、低耦合、易扩展
💡 设计模式组合的精妙之处:
单一职责:
-
策略模式:每个解析器只负责一种类型
-
模板方法:每个保存器只负责一种保存方式
-
执行器模式:只负责统一调用和类型转换
开闭原则:
新增类型时只需要:
-
添加枚举值
-
新增解析策略类
-
新增保存模板类
-
在执行器中添加case分支
不需要修改: 门面类、流式处理逻辑、核心业务流程
泛型的巧妙运用:
-
解决了不同返回类型的统一接口问题
-
保持了类型安全
-
避免了强制类型转换
🎯 最终成果:
门面类的简洁性:
从复杂的条件判断和重复逻辑,变成了简洁的执行器调用
可维护性提升:
-
新增类型:只需扩展,不需修改现有代码
-
修改逻辑:职责明确,影响范围可控
-
代码复用:通用逻辑抽象,特殊逻辑隔离
测试验证:
通过单元测试确保重构后功能完全正常,没有引入新的bug
🚀 技术价值总结:
这次优化体现了渐进式重构的思想:
-
先实现功能(阶段1-2)
-
再优化架构(阶段3)
-
保持功能不变(重构安全性)
通过三种设计模式的组合运用,成功将复杂的业务逻辑抽象成了清晰、可维护、可扩展的架构,为后续的功能扩展奠定了坚实的基础!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号