《Dive Into Deep Learning》学习笔记
已搬迁至:https://umcw0q7m4r.larksuite.com/docs/docusbFbDVJeYUfbwtTGkcABagg
深度模型:一个网络多个层
(和其他学习有啥区别,再看)
一、序言
1.结构
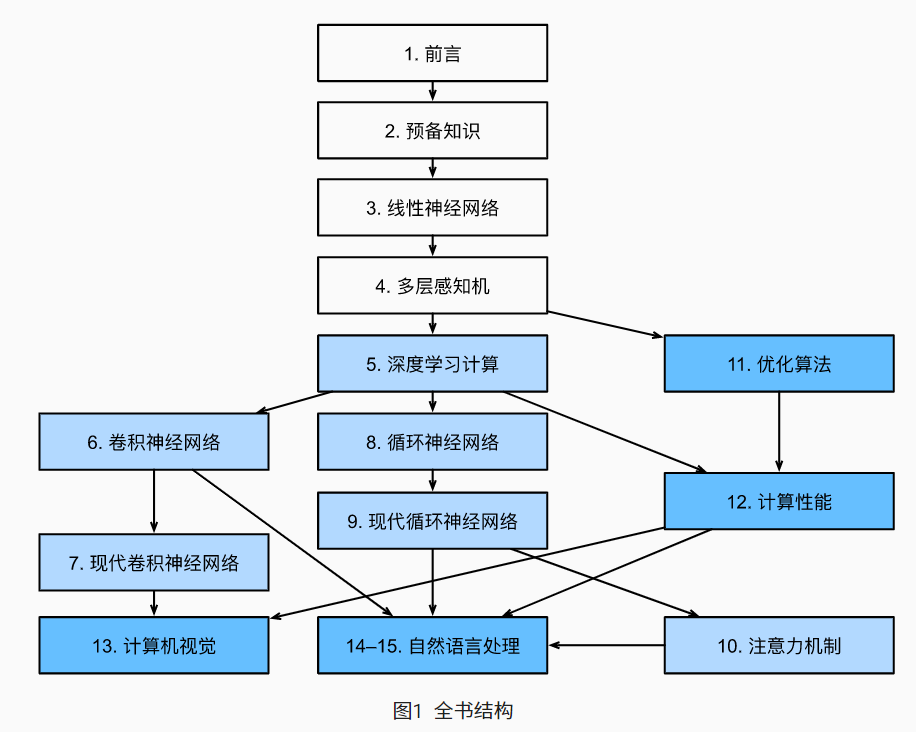
2.小结:
-
深度学习已经彻底改变了模式识别,引入了一系列技术,包括计算机视觉、自然语言处理、自动语音识别。
-
要成功地应用深度学习,你必须知道如何抛出一个问题、建模的数学方法、将模型与数据拟合的算法,以及实现所有这些的工程技术。
二、预备知识
1.安装与环境配置
按照书上的步骤来即可。
安装Miniconda
安装Jupyter Notebook
安装MXNet的GPU版本
一切顺利
(只是还没搞懂这些东西有啥用)
2.数据操作
(1)定义与基本操作:
基本变量是NDArray
x=nd.arange(12)
x.shape ->(12,)
x.size -> 12
x.reshape((3,4))
nd.zeros((2,3,4))
(2)运算:
注意,直接写的都是按元素
特殊的
X.exp() //按元素指数运算
nd.dot(X,Y.T) //矩阵乘法
条件判别式得到的也是矩阵。X>Y X<Y X==Y
*(3)广播机制
自动增加行或者列,使得运算可以进行
(4)索引
0开始编号,左闭右开
X[1:3]
X[1,2]
X[1:2,:]=12
(5)关于运算内存开销
用id查指向的内存
避免临时内存开销:
Z=Y.zeros_like()
nd.elemwise_add(X,Y,out=Z)
(6)NDArray和NumPy相互转换
3.自动求梯度
梯度定义同高等数学
求梯度一般是标量对向量求梯度,得到的也是向量,该向量某个位置的值,为标量对其求偏导后带入原值的结果
对于带while,if的语句也可以求梯度,本质上就是多了几条语句而已。
三、线性回归
是关于预测的模型
1.引出了深度学习的基本要素:
模型

训练数据

损失函数
为了保证十个非负数,这里采用平方
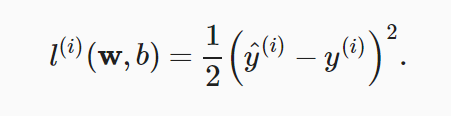
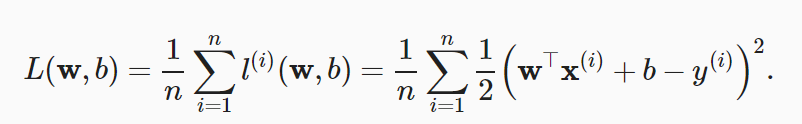
要找的是:
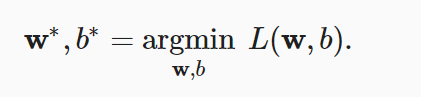
优化算法
首先,这个问题可以找到解析解。类似最小二乘法求偏导然后等于0即可
小批量随机梯度下降:
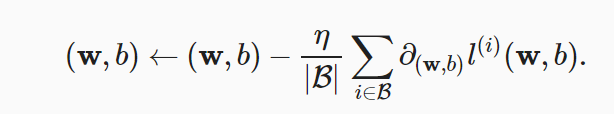
具体地,就是:

迭代一些次数即可。
大致思路就是往低处走。
比模拟退火看起来靠谱一些。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号