特征组合之 XGBoost + LR
2019-05-21 09:35 Ming_H 阅读(8099) 评论(0) 收藏 举报一、特征组合
广告点击率预估、推荐系统等业务场景涉及到的特征通常都是高维、稀疏的,并且样本量巨大,模型通常采用速度较快的LR,然而LR算法学习能力有限,因此要想得到好的预测结果,需要前期做大量的特征工程,工程师通常需要花费大量精力去筛选特征、做特征与处理,即便这样,最终的效果提升可能非常有限。
树模型算法天然具有特征筛选的功能,其通过熵、信息增益、基尼指数等方法,在每次分裂时选取最优的分裂节点。因此,当树模型训练完毕后,从树的根节点到叶子节点都是筛选出来的局部最优特征。
于是很自然的想法就是,通过树模型的特征筛选功能筛选一些局部最优的特征组合,然后将组合特征输入到LR算法,这样就可以提升LR算法的拟合能力。
二、树模型+LR
2014年Facebook 发表论文 Practical Lessons from Predicting Clicks on Ads at Facebook,这篇文章介绍了通过GBDT构造组合特征,然后通过LR对组合特征进行训练,从而达到对预测样本进行分类的目的。随后在Kaggle竞赛中该方法得到验证 ,GBDT与LR也引起了人们的广泛关注。
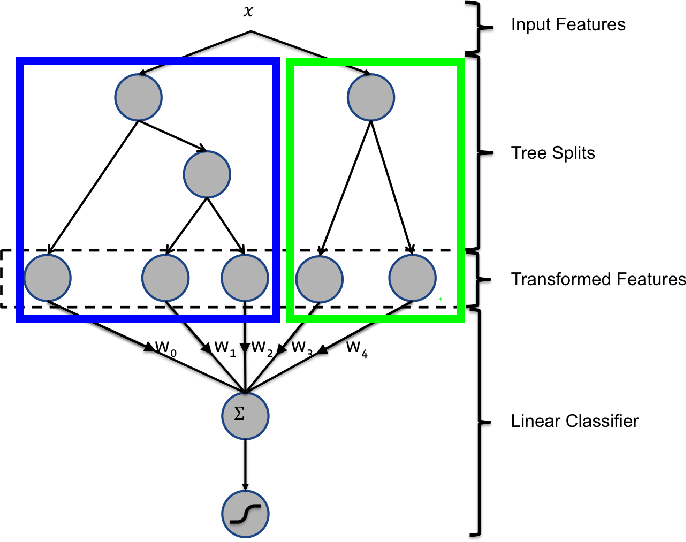
图1 GBDT+LR组合方法图
图1所示为FaceBook的paper中GBDT与LR融合的方法,图中x为输入特征,经过两棵树后走到叶子节点。图中左边的树有三个叶子节点,右边的树有两个叶子节点,因此对于输入x,假设其在左子树落在第一个节点,在右子树落在第二个节点,那么在左子树的one-hot编码为[1,0,0],在右子树的one-hot编码为[0,1],最终的特征为两个one-hot编码的组合[1,0,0,0,1]。最后将转化后的特征输入到线性分类器,即可训练的到一个基于组合特征的线性模型。
在进行特征转化的时候,GBDT模型中所包含的树的棵树即为后面组合特征的数量,每一个组合特征的向量长度不等,该长度取决于所在树的叶子节点数量。举例来说,假设训练得到100棵树之后,就可以得到100个组合特征。
三、XGBoost+LR
XGBoost是一个高效的梯度提升树的实现框架,并且广泛用于工业界及各种比赛。XGBoost提供了一个借口,如图2所示,其中输入X为样本特征,ntree_limit为用于预测的树的棵树。其返回值为[n_sample, n_trees]的矩阵,每一行代表一个样本,每一列代表一棵树,矩阵的值代表相应样本在相应树的所在节点的编号,举例来说,假设模型共有四棵树,返回值第一列为[1,0,3,2],则“1”代表该样本在第一颗树的第一个叶子节点,在第三棵树的的第三个叶子节点,在第四棵树的第二个叶子节点。

图2 XGBoost apply函数借口
代码:
import numpy as np import pandas as pd from sklearn.linear_model import LogisticRegression from sklearn.preprocessing import OneHotEncoder from sklearn.model_selection import train_test_split from sklearn import metrics import logging import xgboost as xgb import time from sklearn.datasets import load_iris logging.basicConfig(format='%(asctime)s : %(levelname)s: %(message)s', level=logging.INFO) def XGBoost_LR(df_train): X_train = df_train.values[:, :-1] y_train = df_train.values[:, -1] X_train_xgb, X_train_lr, y_train_xgb, y_train_lr = train_test_split(X_train, y_train, test_size=0.75) XGB = xgb.XGBClassifier(n_estimators = 6) XGB.fit(X_train_xgb, y_train_xgb) logging.info("训练集特征数据为: \n%s" % X_train_xgb) logging.info("训练集标签数据为: \n%s" % y_train_xgb) logging.info("转化为叶子节点后的特征为:\n%s" % XGB.apply(X_train_xgb, ntree_limit=0)) XGB_enc = OneHotEncoder() XGB_enc.fit(XGB.apply(X_train_xgb, ntree_limit=0)) # ntree_limit 预测时使用的树的数量 XGB_LR = LogisticRegression() XGB_LR.fit(XGB_enc.transform(XGB.apply(X_train_lr)), y_train_lr.astype('int')) X_predict = XGB_LR.predict_proba(XGB_enc.transform(XGB.apply(X_train)))[:, 1] AUC_train = metrics.roc_auc_score(y_train.astype('int'), X_predict) logging.info("AUC of train data is %f" % AUC_train) if __name__ == "__main__": start = time.clock() #加载数据集 iris=load_iris() df_data = pd.concat([pd.DataFrame(iris.data), pd.DataFrame(iris.target)], axis=1) df_data.columns = ["x1","x2", "x3","x4", "y"] df_new = df_data[df_data["y"]<2] logging.info("Train model begine...") XGBoost_LR(df_new) end = time.clock() logging.info("Program over, time cost is %s" % (end-start))
这里使用iris数据集,特征及标签如下图所示,这里选取两类数据用于训练模型,因此标签只有0和1。

图3 训练样本示例
调用apply函数后,打印出转化为叶子节点的特征:

图4 apply函数结果示例
四、项目案例
这里是我在一个营销项目中的案例,背景是重疾险潜客识别,利用客户的多维度特征预测客户是否会购买重疾险。项目中尝试了多种算法,包括XGBoost、XGBoost+LR、GBDT、RF+LR,不同算法在数据的表现如下图所示。图中横坐标代表样本的得分分布,共有10个分段区间,纵坐标代表正样本(已购重疾险的客户)在相应区间的数量。该项目本身对样本的区分度并不高,但是从图中可以看出,使用XGBoost+LR模型的结果表现明显优于其他三种方法,其在得分较高的区间的样本数量较其他方法多,例如[0.9,1.0]这个区间;而在得分较低的区间的样本数量较少,例如[0.0,0.1]这个区间。直观上看,XGBoost+LR具有将正样本向得分高的方向“移动”的作用。

图4 不同算法的表现
五、写在最后
我个人在工作中的感受是树模型+LR的方法最适用于高纬稀疏数据。树模型对这样的稀疏数据容易导致过拟合,举例来说,假设预测用户是否会购买苹果手机,那么“近一周浏览苹果手机的次数”这个特征对于模型的贡献度极高,大量的正样本都有浏览或者浏览次数很多,而未购买的用户在这个特征上的表现则可能数值极小甚至为0。此时,树模型只需要将该特征作为一个分叉就可以得到很好的效果,然而当上线使用时发现可能效果并不是那么好,因为有些客户可能在这个特征表现不明显,但依然购买了商品。
原因是什么呢?因为树模型的正则项是树的深度和叶子节点的数量,上述情况树模型的深度非常浅,叶子节点相应少,因此树模型认为自身很完美,但其实已经过拟合了。对于这样的特征,如果输入到LR这样的线性模型,正则项会对贡献度高的特征的权重进行惩罚,以此来避免过拟合,但是LR的学习能力较差,可能难以达到期望的效果。
综上,可以结合树模型的特征组合能力和LR的正则项来处理高维稀疏数据,既可以提高模型的拟合能力,又可以防止过拟合。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号