
第三章——资源核算(笔记)
3.1 第二章的复习
3.1.1 预期在第二章中学习培养的能力
希望你在阅读完第二章后,能获得以下能力中的某些或全部能力:
- 了解大模型语料准备的流程
- 了解大模型语料准备流程中各个环节的作用
- 了解分词器的不同方案
- 了解分词器的不同方案的实现策略
- 自己手动实现分词器
3.1.1 第二章中回答的问题
根据3.1.1的能力要求,学习第二章内容的目的是为了回答以下这些问题:
- 什么是语料准备?
- 语料准备的环节有哪些?
- 什么是语料脱敏?
- 什么是分词器?
- 分词器的作用是什么?
- 评估分词器的指标有哪些?
- 常见的分词器类型有哪些?
- 不同的分词器的实现思想是什么?
- 如何在工程层面上构建不同的分词器?
- 常见的大模型分词器是什么样子的?
这些问题的衍生路径是这样的:
问题1|——> 问题2 |——>问题3
|——>问题4 |——>问题5
|——> 问题6
|——> 问题7 |——>问题8
|——>问题9
|——>问题10
3.1.2 能力分层一级对于不同能力需求的人的阅读建议
不是所有同学都有相同的学习目标和对自己的能力要求。
不同能力所需要回答的问题难度不一,以下是基于不同能力要求所建议的阅读内容:
层级一(能力一)——>问题1,问题2
层级二(能力一/能力二):——>问题1,问题2,问题3,问题4,问题5
层级三(能力一/能力二/能力三):——> 问题1,问题2,问题3,问题4,问题5,问题7
层级四(能力一/能力二/能力三/能力四):——>问题1,问题2,问题3,问题4,问题5,问题6问题7,问题8
层级五(能力一/能力二/能力三/能力四/能力五):——>问题1,问题2,问题3,问题4,问题5,问题6,问题7,问题8,问题9
问题10的内容供大家体验
3.2 第三章总览
3.2.1 预期在第三章中学习培养的能力
希望你在阅读完第三章后,能获得以下能力中的某些或全部能力:
- 了解资源核算的概念
- 了解资源核算的前置概念
- 了解资源核算的具体流程
- 了解资源核算的具体对象
- 构造资源核算的案例
3.2.2 第三章需要掌握的关键概念
这一张中的每一节都介绍了需要掌握关键概念,他们是:
资源核算——3.3
张量——3.4
内存——3.5
数据类型——3.6
算力——3.7
稠密模型,专家模型——3.8
3.2.3第三章中回答的问题
阅读第三章后我将能够做什么?——3.2.1
我必须掌握哪些关键概念?——3.2.2
什么是资源估算,为什么它很重要?——3.2.3
不同层级的阅读需求是什么?——3.2.4
什么是资源核算,它的意义是什么?——3.3.1
我们具体在估算什么?——3.3.2
在计算资源成本之前我需要知道什么前置概念?——3.3.3
什么是张量?——3.4.1
张量在训练LLM中出现在哪里?——3.4.2
训练过程中对张量执行哪些操作?——3.4.3
在LLM训练中说"内存"时指的是什么?——3.5.1
RAM和VRAM在训练LLM中各扮演什么角色?——3.5.2
什么是数据类型,它在LLM中有什么作用?——3.6.1
有哪些常见的数据类型,它们各自的适用场景是什么?——3.6.2
多维张量如何在线性内存中存储?——3.6.3
什么是算力,为什么它很重要?——3.7.1
用什么单位来度量算力?——3.7.2
这些算力数字在实践中是什么样的?——3.7.3
我们如何衡量硬件的使用效率(MFU)?——3.7.4
训练过程中算力主要消耗在哪里?——3.8.1
稠密模型和专家模型有什么区别?——3.8.2
估算训练资源的具体公式是什么?——3.8.3
3.2.4 对于不同层级的阅读建议
每个人有不同的学习目标,基于不同的学习目标,这里给出不同的阅读建议:
只想简单了解资源核算的概念的人——>能力1——>建议阅读3.3.1,3.3.2
只想了解资源核算原理的人——>能力1,2,3,4——>除3.8.3外全部阅读
想根据给定信息定量进行资源核算的人——>能力1,2,3,4,5——>全部阅读
3.3 资源核算
3.3.1 资源核算的定义和意义
为了衡量大语言模型训练任务的可执行性。进而选取合适的技术方案来进行训练任务。
3.3.2 资源核算的对象
这里资源核算的意思是对执行大语言模型训练任务时所产生的资源占用和资源消耗进行计算。
简单而言,在大语言模型中资源核算的对象指所占用的训练时占用的内存,和训练所耗费的算力,和训练所花费的时间。
3.3.3 资源核算的前置概念
需要掌握计算具体资源的方法,需要掌握以下前置概念:
张量,内存,数据类型,参数规模,算力。
数据类型和参数规模决定内存放不放的下。放不下意味着无法进行训练,
参数规模和数据类型决定计算任务总的计算次数。
而算力决定了执行计算任务的效率。
3.4 张量
3.4.1 张量的定义
(以下内容由Minimax 2.7模型生成)
张量是深度学习中最基本的数据结构,可以简单地理解为多维数组。
一句话理解
| 维度 | 数学名称 | 生活例子 |
|---|---|---|
| 0维 | 标量(Scalar) | 一个数字,如 5、3.14 |
| 1维 | 向量(Vector) | 一行/一列数字,如 [1, 2, 3] |
| 2维 | 矩阵(Matrix) | 表格/Excel表,如 3行4列 |
| n维 | 张量(Tensor) | 多维数组,如 图片(3维)、视频(4维) |
生活类比
📊 标量: 5 → 今天的温度
📈 向量: [1, 2, 3] → 股票价格序列
📋 矩阵: [[1,2],[3,4]] → 成绩表(学生×科目)
📦 张量: RGB图片(高×宽×3) → 彩色图像 `
3.4.2 张量在训练LLM中的作用
张量在LLM中几乎是无处不在,模型各层的参数、梯度、优化器状态、输入数据、中间层激活值。都以张量的状态存在。由于自然语言难以表示多维的数据结构,因此下面破例在理论环节引入代码,以一个简单的transformer层为样本帮助理解(这个示例由Minimax m2.7模型生成)
以一个简单的 Transformer 层为例
import torch
import torch.nn as nn
# 假设模型配置
batch_size = 4
seq_len = 128
vocab_size = 50000
d_model = 512 # 嵌入维度
d_ff = 2048 # 前馈网络维度
n_heads = 8
1. 输入数据 → 张量
# 输入: 4句话,每句128个token
input_ids = torch.randint(0, vocab_size, (batch_size, seq_len))
print(input_ids.shape) # torch.Size([4, 128])
# 嵌入后: 转换为 d_model 维向量
embedding = nn.Embedding(vocab_size, d_model)
x = embedding(input_ids)
print(x.shape) # torch.Size([4, 128, 512])
# ↑ ↑ ↑
# batch seq hidden
2. 模型参数 → 张量集合
# 单层 Self-Attention 的所有参数
attention_layer = nn.MultiheadAttention(d_model, n_heads, batch_first=True)
print("=== Attention 层参数 ===")
for name, param in attention_layer.named_parameters():
print(f"{name:40} shape: {str(param.shape):20} 参数量: {param.numel():,}")
# 输出:
# q_proj.weight shape: torch.Size([512, 512]) 参数量: 262,144
# q_proj.bias shape: torch.Size([512]) 参数量: 512
# k_proj.weight shape: torch.Size([512, 512]) 参数量: 262,144
# k_proj.bias shape: torch.Size([512]) 参数量: 512
# v_proj.weight shape: torch.Size([512, 512]) 参数量: 262,144
# v_proj.bias shape: torch.Size([512]) 参数量: 512
# out_proj.weight shape: torch.Size([512, 512]) 参数量: 262,144
# out_proj.bias shape: torch.Size([512]) 参数量: 512
3. 前向传播 → 中间激活值
# 注册钩子捕获中间激活
activations = {}
def hook_fn(name):
def forward_hook(module, input, output):
activations[name] = output.detach()
return forward_hook
# 注册钩子
attention_layer.register_forward_hook(hook_fn("attention_output"))
# 前向传播
output, attn_weights = attention_layer(x, x, x)
print("=== 中间激活值 ===")
for name, act in activations.items():
print(f"{name}: shape={act.shape}")
# 输出:
# attention_output: shape=torch.Size([4, 128, 512])
# ↑ ↑ ↑
# batch seq hidden(注意力计算后的输出)
4. 反向传播 → 梯度张量
# 前向传播
output, _ = attention_layer(x, x, x)
loss = output.mean() # 假设的损失
# 反向传播
loss.backward()
print("=== 梯度张量 ===")
for name, param in attention_layer.named_parameters():
if param.grad is not None:
print(f"{name:40} grad_shape: {str(param.grad.shape):20} grad_mean: {param.grad.mean():.6f}")
# 输出:
# q_proj.weight grad_shape: torch.Size([512, 512]) grad_mean: 0.000012
# q_proj.bias grad_shape: torch.Size([512]) grad_mean: 0.000023
# k_proj.weight grad_shape: torch.Size([512, 512]) grad_mean: 0.000018
# ... (类似结构)
5. 优化器状态 → 额外张量
optimizer = torch.optim.Adam(attention_layer.parameters(), lr=1e-4)
# Adam 优化器会维护一阶/二阶矩估计
print("=== Adam 优化器状态 ===")
for name, state in optimizer.state.items():
print(f"参数: {name}")
for key, val in state.items():
print(f" {key}: shape={val.shape}")
break # 只看第一个参数的状态
# 输出:
# 参数: q_proj.weight
# exp_avg: shape=torch.Size([512, 512]) ← 一阶矩估计 (动量)
# exp_avg_sq: shape=torch.Size([512, 512]) ← 二阶矩估计 (自适应学习率)
# 计算优化器状态占用的显存
total_state = sum(v.numel() * 4 for v in optimizer.state.values()) # float32 = 4 bytes
print(f"\n单个参数优化器状态占用: {total_state / 1024 / 1024:.2f} MB")
# 输出: 单个参数优化器状态占用: 1.00 MB
完整参数统计
def count_tensor_stats(model):
stats = {
'参数': {'count': 0, 'size_mb': 0},
'梯度': {'count': 0, 'size_mb': 0},
'优化器状态': {'count': 0, 'size_mb': 0},
}
for name, param in model.named_parameters():
stats['参数']['count'] += 1
stats['参数']['size_mb'] += param.numel() * 4 / 1024 / 1024
if param.grad is not None:
stats['梯度']['count'] += 1
stats['梯度']['size_mb'] += param.grad.numel() * 4 / 1024 / 1024
# 假设使用 Adam (2个状态 per 参数)
stats['优化器状态']['count'] = stats['参数']['count'] * 2
stats['优化器状态']['size_mb'] = stats['参数']['size_mb'] * 2
return stats
stats = count_tensor_stats(attention_layer)
print("=== 显存占用统计 ===")
for name, s in stats.items():
print(f"{name}: {s['count']} 个张量, 约 {s['size_mb']:.2f} MB")
# 输出:
# === 显存占用统计 ===
# 参数: 6 个张量, 约 1.50 MB
# 梯度: 6 个张量, 约 1.50 MB
# 优化器状态: 12 个张量, 约 3.00 MB
3.4.3 对张量的操作
在训练大模型的过程中,大部分步骤都可以归类于对张量的各种操作。在大模型训练中,要在合适的时候执行对应的向量操作
3.5 内存
3.5.1 内存的定义
在大模型的训练中,训练的硬件对应着不同的内存。一般来说,因为大模型主要在GPU上训练,所以,大模型中的内存一般指代的是GPU显存(VRAM),而不是CPU使用的内存(RAM)。
如果大模型在CPU上进行训练,那么内存指代的是CPU使用的内存(RAM)而非GPU的显存(VRAM)。
3.5.2 内存在训练LLM中的作用
在GPU上训练时VRAM和RAM在大模型训练中的属性作用如下表所示(此表由Minimax M2.7模型生成)
RAM vs VRAM 功能对比
| 对比维度 | RAM (内存) | VRAM (显存) |
|---|---|---|
| 容量 | 16GB - 512GB | 8GB - 80GB |
| 带宽 | 50 - 100 GB/s | 500 - 2000 GB/s |
| 延迟 | 较高 (~100ns) | 较低 (~1μs) |
| 访问权限 | CPU 和 GPU 均可访问 | GPU 独占,CPU 需通过 PCIe 访问 |
| 成本 | 较低 | 较高 |
训练时的具体作用
| 阶段/组件 | RAM (内存) | VRAM (显存) |
|---|---|---|
| 数据存储 | 整个训练数据集(可分片加载) | 当前 batch 的输入数据 |
| 数据预处理 | CPU 进行数据增强、tokenization | 预处理后的 tensor 暂存 |
| 模型权重 | 加载模型用于调试和备份 | 前向/反向计算中的活跃权重 |
| 梯度计算 | 多卡梯度聚合时临时存储 | 单卡梯度计算和存储 |
| 优化器状态 | Checkpoint 保存时使用 | Adam 等优化器的动量、方差状态 |
| 激活值 | 不使用 | 存储中间层输出(反向传播必需) |
| KV Cache | 推理时不使用 | 推理时存储注意力缓存 |
| 临时缓冲区 | 进程间通信、进程池 | CUDA kernel 临时计算空间 |
| 日志和监控 | TensorBoard、打印日志 | 训练指标中间结果 |
3.6 数据类型
3.6.1 数据类型的定义和作用
在大模型的训练中的数据类型指代的是数据存储的格式,不同的数据格式的表示范围,表示精度(准确性),所占用的内存大小不一样。
在训练模型时,要根据实际条件,综合参数数量,显存规模,模型精度,训练时间等要素确定合适的数据类型,以做到性能要求与模型表现的平衡
3.6.2 大模型训练中常见的数据类型及应用场景(以下内容摘自原教程)
- Float32 (FP32 / 单精度浮点数)

- 规格:占用 4 字节 (32 bits)。结构为:1位符号位 + 8位指数位 + 23位尾数位。
- 地位:PyTorch 的默认数据类型,也是科学计算领域的“黄金标准”。
- 优点:数值精度高,动态范围大,训练最稳定,几乎不会出现数值溢出问题。
- 缺点:对于大模型而言太“奢侈”。它占用的显存是 16位格式的两倍,且在现代 GPU(如 H100)上的计算吞吐量远低于低精度格式。
- 炼丹用途:通常用于存储参数的主副本 (Master Weights) 和 优化器状态 (Optimizer States),以确保在梯度累积和参数更新时不会因为精度丢失而导致模型无法收敛。
- Float16 (FP16 / 半精度浮点数)
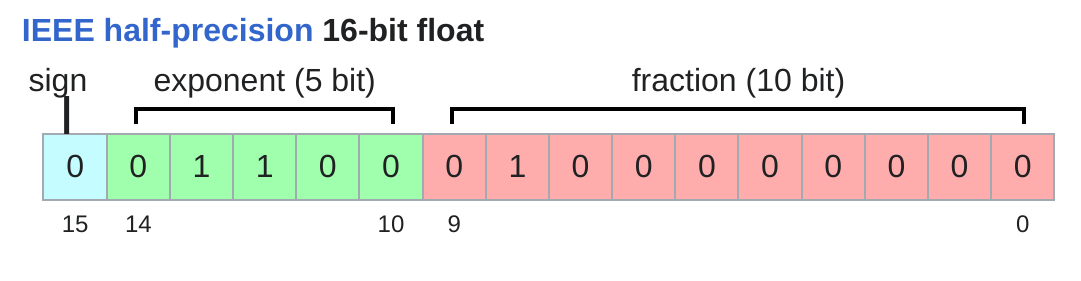
- 规格:占用 2 字节 (16 bits)。结构为:1位符号位 + 5位指数位 + 10位尾数位。
- 优点:显存占用比 FP32 减少一半,计算速度快。
- 致命缺陷:动态范围(Dynamic Range)太窄。
- 由于指数位只有 5 位,它无法表示非常小的数(会发生下溢 Underflow,直接变成 0)或非常大的数(会发生上溢 Overflow,变成 Infinity)。
- 例如:在 FP16 中,
1e-8这样的小数会被直接当作0处理,导致梯度消失。
- 用途:这是上一代 GPU(如 V100)混合精度训练的主流。为了解决溢出问题,必须使用复杂的损失缩放 (Loss Scaling) 技术。目前在 LLM 训练中正逐渐被 BF16 取代。
- BFloat16 (BF16 / Brain Floating Point)
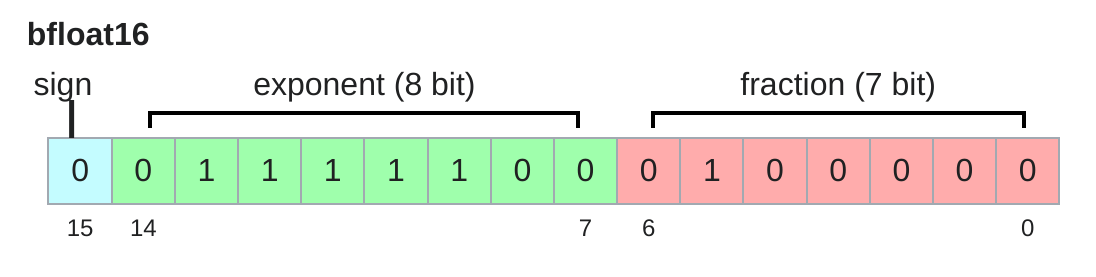
- 规格:占用 2 字节 (16 bits)。结构为:1位符号位 + 8位指数位 + 7位尾数位。
- 来源:由 Google Brain 专为深度学习设计。
- 设计逻辑:“要范围,不要精度”。
- 深度学习模型(尤其是神经网络)对小数点的后几位精度不敏感,但对数值的范围非常敏感。
- BF16 直接截断了 FP32 的尾数,但保留了和 FP32 相同的 8 位指数位。
- 优点:
- 拥有和 FP32 一样宽广的动态范围,不需要 Loss Scaling 也能稳定训练。
- 显存占用和 FP16 一样少。
- 在 A100/H100 等新硬件上计算速度极快。
- 用途:当前 LLM 训练的绝对主流选择。通常用于存储激活值 (Activations) 以及进行前向和反向传播的矩阵乘法计算。
- FP8 (8位浮点数)

图3.8 8位浮点数
- 规格:占用 1 字节 (8 bits)。
- 变体:
- E4M3:4位指数,3位尾数(精度稍高,范围稍小)。
- E5M2:5位指数,2位尾数(范围稍大,精度更低)。
- 优点:极致的显存压缩和计算吞吐量。
- 硬件限制:仅在 NVIDIA H100 及更新的架构(配合 Transformer Engine)上才被原生支持。
- 炼丹用途:目前主要用于推理阶段的量化 (Quantization)。虽然理论上可以用于训练(H100 支持),但由于精度极低,训练极不稳定,属于比较前沿的研究领域。
3.6.3 张量在内存中的存储机制
训练大模型所要处理的对象是多个维度的张量,而计算机内存则是一维排布的序列。为了在实际运行的计算机中执行抽象的数学运算,我们必须理解张量在内存中的存储机制。(以下内容摘自于原教程,内容有所改动)
在早期的 pytorch 版本中,张量在一台机器上的存储,占用了两部分内存,一个内存储存了这个张量的形状(size)、步长(stride)、数据类型(dtype)等元数据信息,我们把这一部分称之为头信息区(Tensor);另一个内存储存的就是真正的数据,我们称为存储区 (Storage)。但是将“存储区”作为一个独立的、可公开访问的对象,其带来的复杂性和潜在风险,远大于它为用户提供的一些灵活性。
因此,在现在的 pytorch 版本中,PyTorch 的设计者们选择将这一层实现细节进行封装,让 Tensor 对象本身成为一个集成了“指针+元数据”的单一实体。这意味着一个张量本身并不直接“包含”数据,而是指向一块连续的内存区域,并附带一套规则(元数据),告诉程序如何根据你请求的索引去这块内存里找到对应的数据。让我们定义一个4x4的二维张量作为例子:
x = torch.tensor([
[0., 1, 2, 3],
[4, 5, 6, 7],
[8, 9, 10, 11],
[12, 13, 14, 15],
])
张量在底层可以是按行存储也可以是按列存储。Numpy 和 Pytorch 都采用了按行存储的方式,任何维度的张量在底层存储都占据着内存中连续的空间,那么问题来了,我们如何访问到我们想要的位置的数据?
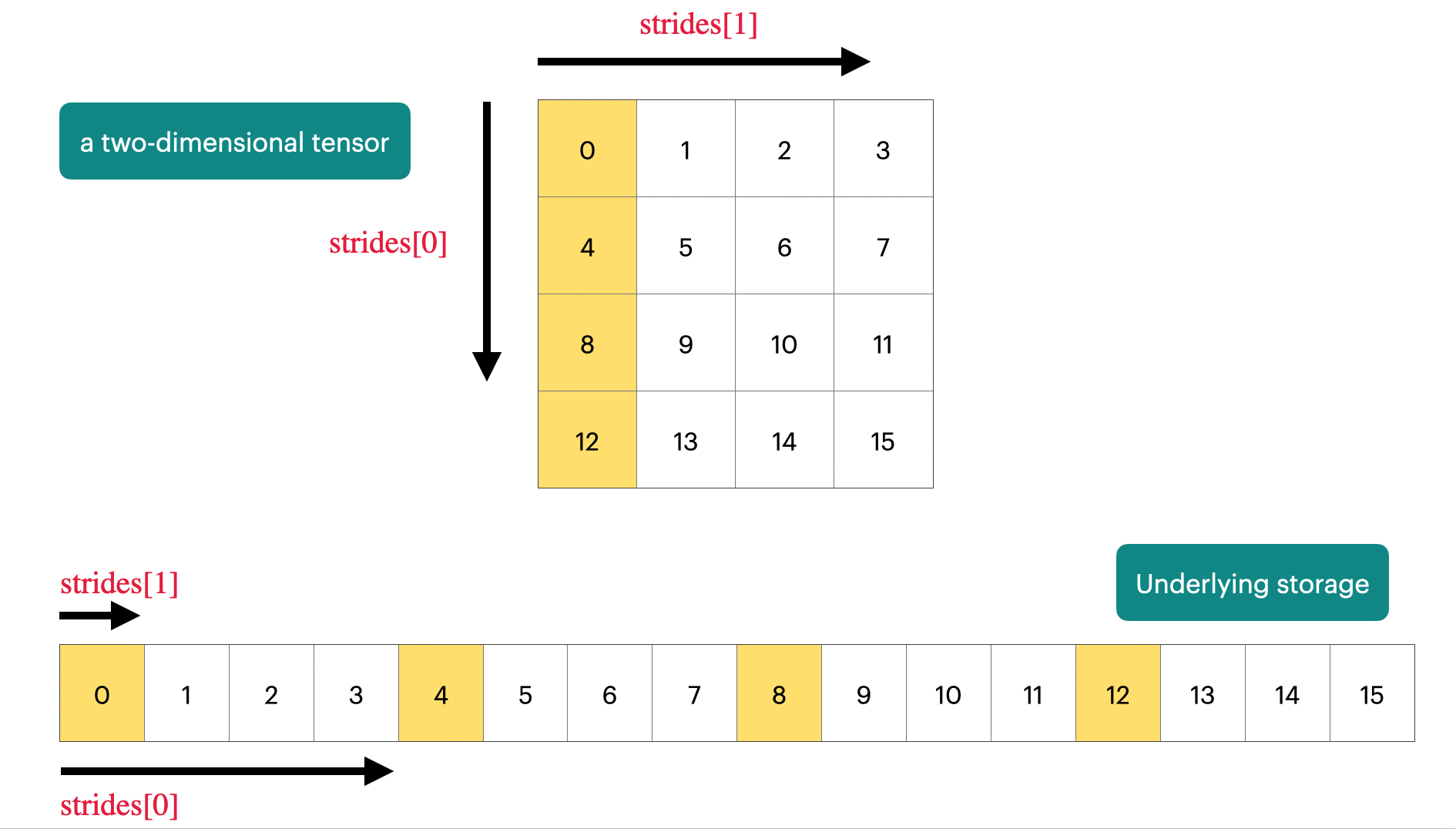
答案就是步长(Strides)!用一句话来说,PyTorch通过“步长”这一元数据,巧妙地将多维张量的逻辑结构映射到一维的物理内存上。
步长在数据格式上是一个元组,定义了在每个维度上移动一个单位时,在底层存储中需要“跳过”的元素数量。
这个二维张量在内存中的存储顺序是一维的,是一段直线。但是,在定义里,它是二维的。是一个平面。
stride(0)规定了,如果要访问到下一行中的头元素,必须从这一行的头元素所占用的第一个内存单位开始,跳过4个元素的所占用的内存单位。才能访问到下一行的头元素。
stride(0)规定了,如果要访问到下一列中的头元素,必须从这一列的头元素所占用的第一个内存单位开始,跳过1个元素的所占用的内存单位。才能访问到下一列的头元素。
下面一段代码是二维向量中stride数据和计算元素实际位置的代码:
# 步长(stride):在每个维度上移动时跳过的元素数
assert x.stride(0) == 4 # 行维度:移动到下一行需跳过4个元素
assert x.stride(1) == 1 # 列维度:移动到下一列需跳过1个元素
# 计算元素位置:行索引r,列索引c
r, c = 1, 2
index = r * x.stride(0) + c * x.stride(1) # 位置6
3.7 算力
3.7.1 算力的定义和意义
算力的定义是处理信息的能力,在大模型训练的场景中一般是指GPU处理信息的能力。
算力是衡量GPU处理信息能力的一个指标,是设计训练方案的重要参考。
3.7.2 算力的单位
用以衡量算力的常用单位一个重要单位是浮点运算总数(FLOPs),和模型浮点运算总数利用率(MFU)下面介绍FLOPs的概念。
FLOP及衍生概念:
要理解算力的单位,首先我们要理解什么是浮点运算(FLOP),而要理解浮点元算,首先我们要理解什么是浮点(FP)。
浮点数是一种用于表示实数的数值类型,其特点是小数点的位置可以浮动。它采用类似科学计数法的形式,通过符号位、指数位和尾数位来表示一个数值。这种表示方式能够在有限的存储空间内表示非常大的数或非常小的数。3.6节中所介绍的各类数据结构都属于浮点数。
而浮点运算(FLOP) 就是对浮点数的运算,这些运算包含基础的四则运算(加减乘除)和扩展运算(乘加融合,平方根,倒数,指数,对数,三角函数,比较)。
而FLOPs(浮点运算总数)指一个运算任务中需要执行的浮点运算总次数。
而FLOPS(每秒执行浮点运算总数,即FLOP/s)指硬件每秒钟能够提供的浮点运算次数。
在实际的应用中,FLOPS的数量级常常可达亿及甚至
3.7.2 算力的单位FLOPs
FLOP及衍生概念:
要理解算力的单位,首先我们要理解什么是浮点运算(FLOP),而要理解浮点元算,首先我们要理解什么是浮点(FP)。
浮点数是一种用于表示实数的数值类型,其特点是小数点的位置可以浮动。它采用类似科学计数法的形式,通过符号位、指数位和尾数位来表示一个数值。这种表示方式能够在有限的存储空间内表示非常大的数或非常小的数。3.6节中所介绍的各类数据结构都属于浮点数。
而浮点运算(FLOP) 就是对浮点数的运算,这些运算包含基础的四则运算(加减乘除)和扩展运算(乘加融合,平方根,倒数,指数,对数,三角函数,比较)。
而FLOPs(浮点运算总数)指一个运算任务中需要执行的浮点运算总次数。
而FLOPS(每秒执行浮点运算总数,即FLOP/s)指硬件每秒钟能够提供的浮点运算次数。
在实际的应用中,FLOPS的数量级常常十亿及以上,因此,下面列出了一些用以表示不同数量级的FLOPS的单位(以下内容由MiniMax 2.7模型生成):
| 前缀 | 全称 | 中文 | 数值 | 换算 |
|---|---|---|---|---|
| KFLOPS | Kilo FLOPS | 千次 | 10³ | 1,000 |
| MFLOPS | Mega FLOPS | 百万次 | 10⁶ | 1,000,000 |
| GFLOPS | Giga FLOPS | 十亿次 | 10⁹ | 1,000,000,000 |
| TFLOPS | Tera FLOPS | 万亿次 | 10¹² | 1,000,000,000,000 |
| PFLOPS | Peta FLOPS | 千万亿次 | 10¹⁵ | 1,000,000,000,000,000 |
| EFLOPS | Exa FLOPS | 十亿亿次 | 10¹⁸ | 1,000,000,000,000,000,000 |
| ZFLOPS | Zetta FLOPS | 十万亿亿次 | 10²¹ | 1,000,000,000,000,000,000,000 |
| YFLOPS | Yotta FLOPS | 一秭次 | 10²⁴ | 1,000,000,000,000,000,000,000,000 |
3.7.3 算力单位应用的实际案例
(以下内容来自原教程)
- GPT-3 (2020年):训练耗时约 3.14×1023 FLOPs 文章
- GPT-4 (2023年):据推测训练耗时约 2×1025 FLOPs 文章
- 政策背景:美国曾有一项行政命令,要求任何训练FLOPs超过 1 × 10²⁶ 的基础模型必须向政府报告(该命令已于2025年被撤销)
- NVIDIA A100:峰值性能为 312 TFLOP/s (即 3.12×1014 FLOP/s) 官方手册
- NVIDIA H100:峰值性能为 1979 TFLOP/s,但这通常是在启用“稀疏性”(sparsity)的情况下。对于密集矩阵乘法,其性能约为一半,即 989.5 TFLOP/s 官方手册
3.7.4 模型浮点运算次数利用率(MFU)
(以下内容均来自原教程,根据需要有所修改)
MFU = (实际FLOP/s) / (硬件峰值FLOP/s)
- MFU >= 0.5:被认为是相当不错的性能
- MFU 接近 1.0:非常难达到,因为硬件不可能100%满负荷运转,总会有内存访问、数据传输等开销
注意:这个公式忽略了通信和系统开销,只关注纯粹的计算效率。
3.8 估算语言模型的训练消耗
3.8.1 消耗算力的主要对象
在理解完张量,内存,数据类型,算力等前置概念后,我们终于来到了计算具体的语言模型训练消耗的章节。下面是训练任务中消耗算力的主要对象(以下表格由Minimax M2.7模型生成):
| 环节 | 算力消耗 | 说明 |
|---|---|---|
| 反向传播 | ~50% | 计算梯度,计算量最大 |
| 前向传播 | ~45% | 计算输出,每层都要遍历 |
| 优化器更新 | ~2-3% | 参数更新,相对较少 |
| 数据加载 | ~2-3% | 数据传输,不是计算 |
一般而言,在训练大模型的过程中”前向传播“和”反向传播“中是两个必不可少的过程,也是算力消耗的主要过程。一般而言,只需要估算出反向传播和前向传播的大致消耗,就能估算出此次任务的算力消耗。
”前向传播“和”反向传播“的定义见……(待补充)
3.8.2 稠密模型(DM)与专家模型(MoE)的定义
由前文”前向传播“和”反向传播的定义可知。大模型工作时需要让输入数据要经过一层层的”神经元“,而在训练的过程中,出于节约资源,加快训练时间的考虑,有些模型只会让部分参数参与进计算中,这就是所谓专家模型(MoE,Model of Expert)的简单理解,而相对的,有些模型会让所有参数都参与进计算任务中,这就是所谓稠密模型(DM,Dense model),以下是稠密模型和专家模型的简单对比(以下内容由MiniMax 2.7模型生成):
一句话总结
| 模型 | 特点 |
|---|---|
| 稠密模型 | 存100%,用100% |
| 稀疏模型 (MoE) | 存100%,用10% |
核心概念对比
| 维度 | 稠密模型 (Dense) | 稀疏模型 (Sparse / MoE) |
|---|---|---|
| 英文名称 | Dense Model | Sparse Model / Mixture of Experts |
| 中文名称 | 稠密模型 | 稀疏模型 / 混合专家模型 |
| 核心思想 | 全部参数参与计算 | 部分参数参与计算 |
| 类比 | 通才型专家 | 专家团队,按需分工 |
参数使用对比
| 维度 | 稠密模型 | 稀疏模型 (MoE) |
|---|---|---|
| 总参数量 | 等于模型规模 | 大于活跃参数量 |
| 活跃参数 | 100% 参与计算 | ~12.5% (8专家激活2个) |
| 参数存储 | 所有参数都存 | 所有专家都存 |
| 参数利用 | 每次都使用 | 按需激活 |
计算资源对比
| 维度 | 稠密模型 | 稀疏模型 (MoE) |
|---|---|---|
| 算力消耗 | 高 (100%) | 低 (~10-20%) |
| 显存消耗 | 中等 | 较高 (存所有专家) |
| 计算效率 | 均匀分布在所有层 | 不均匀 (门控决定) |
| 推理速度 | 较慢 | 较快 |
架构设计对比
| 维度 | 稠密模型 | 稀疏模型 (MoE) |
|---|---|---|
| 结构 | 固定层叠 | 专家网络 + 门控 |
| 门控机制 | 无 | 路由器/门控网络 |
| 专家数量 | 1 (所有参数) | N (多个专家) |
| 激活策略 | 全激活 | 选择性激活 |
代表模型
| 模型类型 | 代表模型 | 架构特点 |
|---|---|---|
| 稠密模型 | GPT-3, BERT, LLaMA (非MoE) | 全参数激活 |
| 稀疏模型 | GPT-4 (据传), Mixtral, LLaMA-MoE | 专家路由 |
优缺点对比
| 方面 | 稠密模型 | 稀疏模型 (MoE) |
|---|---|---|
| 优点 | 稳定可靠、训练简单 | 算力效率高、扩展性好 |
| 缺点 | 计算成本高、扩展受限 | 架构复杂、显存需求高 |
| 适用场景 | 计算资源充足 | 追求效率最大化 |
应用场景对比
| 场景 | 稠密模型 | 稀疏模型 (MoE) |
|---|---|---|
| 大规模预训练 | ✅ 常用 | ✅ 节省成本 |
| 推理部署 | 成本高 | ✅ 成本低 |
| 资源受限环境 | ❌ 不适合 | ✅ 适合 |
| 边缘设备 | ❌ 不适合 | ⚠️ 可优化 |
需要注意的是,专家模型中”专家“并不等同于参数,而是一个子网络。
对于MoE模型而言,总的MoE模型参数=每个专家参数的综合+门控网络的参数。
在大模型的训练任务中,稠密模型和专家模型的资源消耗遵循不同的计算法则,下面会详细介绍。
3.8.3 稠密模型和专家模型的资源核算公式
(以下内容由Minimax M2.7模型生成)
基础参数定义
| 符号 | 含义 |
|---|---|
| $P$ | 模型总参数量 |
| $N$ | 专家总数 |
| $K$ | 每次激活的专家数量 |
| $B$ | 每个参数的字节数 (FP32=4, FP16=2, BF16=2) |
| $S$ | 序列长度 |
| $H$ | 隐藏层维度 |
| $L$ | 层数 |
| $T$ | 训练 Token 数 |
总计算量对比
稠密模型
| 指标 | 公式 | 说明 |
|---|---|---|
| 单次前向传播 | $2 \times P$ | 矩阵乘法 ≈ 2P FLOPs |
| 单次反向传播 | $4 \times P$ | 约为前向的2倍 |
| 单次迭代 | $6 \times P$ | 前向 + 反向 = 6P |
| 总训练计算量 | $6 \times P \times T$ | 全量训练 |
简化公式:
$$FLOPs_{dense} = 6 \times P \times T$$
MoE 模型
| 指标 | 公式 | 说明 |
|---|---|---|
| 单次前向传播 | $2 \times P_{active}$ | 只计算激活的专家 |
| 单次反向传播 | $4 \times P_{active}$ | 激活部分的梯度 |
| 单次迭代 | $6 \times P_{active}$ | 激活部分参与计算 |
| 总训练计算量 | $6 \times P_{active} \times T$ | 节省算力 |
其中:
$$P_{active} = P \times \frac{K}{N}$$
简化公式:
$$FLOPs_{moe} = 6 \times P \times \frac{K}{N} \times T$$
算力节省比例
| 对比项 | 公式 |
|---|---|
| MoE 相对计算量 | $\frac{K}{N}$ |
| 算力节省比例 | $1 - \frac{K}{N}$ |
| 示例 (8专家激活2个) | $1 - \frac{2}{8} = 75%$ |
总显存消耗对比
稠密模型
| 组件 | 公式 | 说明 |
|---|---|---|
| 模型参数 | $P \times B$ | 存储权重 |
| 梯度 | $P \times B$ | 反向传播梯度 |
| 优化器状态 (Adam) | $2 \times P \times B$ | 一阶矩 + 二阶矩 |
| 激活值 | $\alpha \times B \times S \times H$ | 中间计算结果 |
| 总显存 | $P \times B \times 4 + \alpha \times ...$ | 近似: $4 \times P \times B$ |
简化公式(不含激活值):
$$Memory_{dense} \approx 4 \times P \times B$$
MoE 模型
| 组件 | 公式 | 说明 |
|---|---|---|
| 模型参数 | $P \times B$ | 所有专家都存储 |
| 梯度 | $P_{active} \times B$ | 只计算激活专家的梯度 |
| 优化器状态 | $2 \times P_{active} \times B$ | 只维护激活专家的状态 |
| 激活值 | $\alpha \times B \times S \times H$ | 减少(计算量少) |
简化公式(不含激活值):
$$Memory_{moe} \approx P \times B + 3 \times P_{active} \times B$$
$$= P \times B + 3 \times P \times \frac{K}{N} \times B$$
显存对比总结
| 对比项 | 稠密模型 | MoE 模型 |
|---|---|---|
| 参数存储 | $P \times B$ | $P \times B$ (相同) |
| 梯度存储 | $P \times B$ | $P_{active} \times B$ |
| 优化器存储 | $2 \times P \times B$ | $2 \times P_{active} \times B$ |
| 总算力消耗 | $6 \times P \times T$ | $6 \times P \times \frac{K}{N} \times T$ |
总计算时间对比
理论分析
| 因素 | 稠密模型 | MoE 模型 |
|---|---|---|
| 计算时间 | 与参数量成正比 | 与激活参数量成正比 |
| 通信时间 | 较小 | 门控路由开销 |
| 并行效率 | 高 | 取决于专家分布 |
简化公式
| 模型 | 计算时间公式 |
|---|---|
| 稠密模型 | $Time_{dense} \propto P$ |
| MoE 模型 | $Time_{moe} \propto P \times \frac{K}{N}$ |
实际影响因素
| 因素 | 影响 |
|---|---|
| 专家负载均衡 | 门控不均会导致部分专家过载 |
| 通信开销 | 多专家时跨设备通信增加 |
| 内存带宽 | 加载所有专家的开销 |
3.9 总结与展望
在这章中,我们学习了一些概念,回答了一些问题,获得了一些能力。
在第四章中,我们将学习如何使用pytorch等python库,构建一个简单的线性模型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号