银行风控模型的建立
一、神经网络模型
import pandas as pd # 参数初始化 inputfile = '../data/bankloan.xls' data = pd.read_excel(inputfile) # 导入数据 #print(data) x = data.iloc[:,:8] y = data.iloc[:,8] #print(x) #print(y) from keras.models import Sequential from keras.layers.core import Dense, Activation model = Sequential() # 建立模型 model.add(Dense(input_dim = 8, units = 8)) model.add(Activation('relu')) # 用relu函数作为激活函数,能够大幅提供准确度 model.add(Dense(input_dim = 8, units = 1)) model.add(Activation('sigmoid')) # 由于是0-1输出,用sigmoid函数作为激活函数 model.compile(loss = 'mean_squared_error', optimizer = 'adam') # 编译模型。由于我们做的是二元分类,所以我们指定损失函数为binary_crossentropy,以及模式为binary # 另外常见的损失函数还有mean_squared_error、categorical_crossentropy等,请阅读帮助文件。 # 求解方法我们指定用adam,还有sgd、rmsprop等可选 model.fit(x, y, epochs = 1000, batch_size = 10) # 训练模型,学习一千次 #yp = model.predict_classes(x).reshape(len(y)) # 分类预测 import numpy as np predict_x=model.predict(x) classes_x=np.argmax(predict_x,axis=1) yp = classes_x.reshape(len(y)) ''' # 评估模型,不输出预测结果 loss,accuracy = model.evaluate(x, y, batch_size=128) print('\ntest loss',loss) print('accuracy',accuracy) ''' score = model.evaluate(x, y, batch_size=128) #分类预测精确度 print(score) from cm_plot import * # 导入自行编写的混淆矩阵可视化函数 cm_plot(y,yp).show() # 显示混淆矩阵可视化结果
运行结果如下
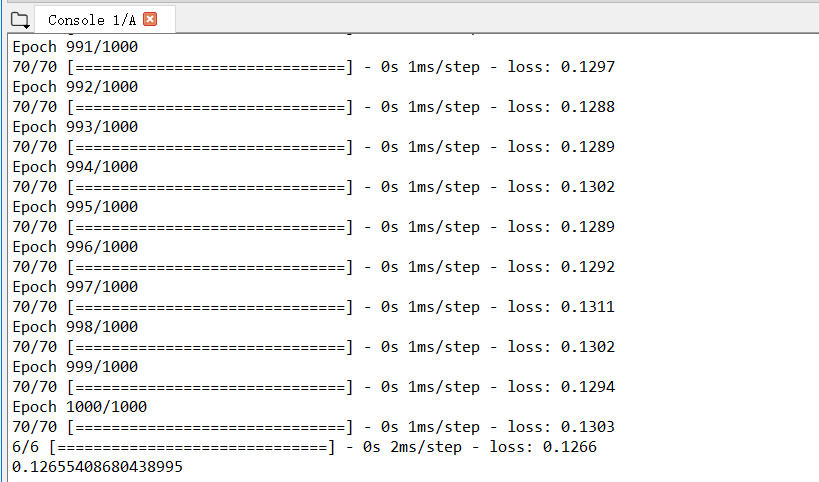
由上图可得,该模型经过1000次训练后,该模型的损失值为0.126,损失值较小说明该模型预测较准确。
该模型的混淆矩阵如下:
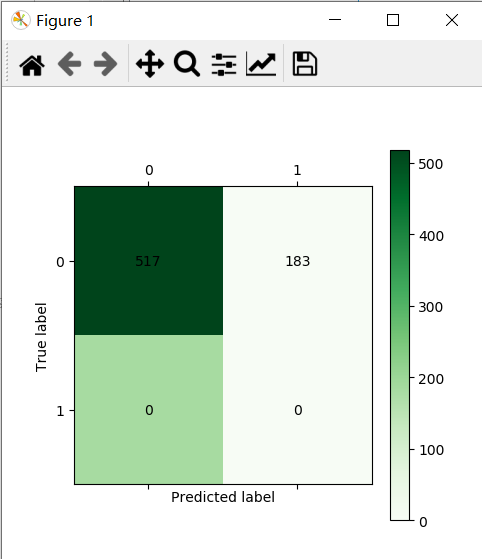
二、决策树算法
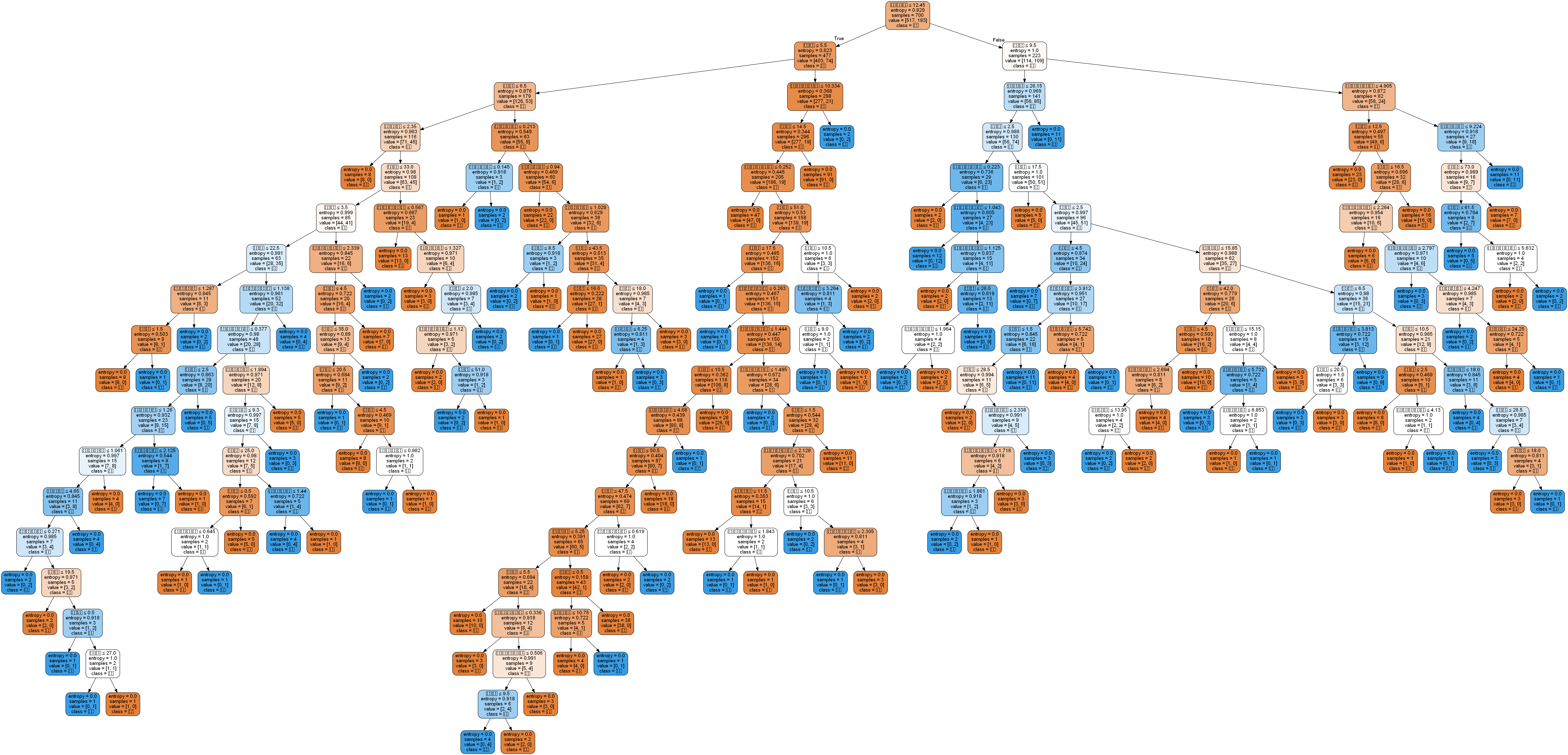
import pandas as pd # 参数初始化 filename = '../data/bankloan.xls' data = pd.read_excel(filename) # 导入数据 x = data.iloc[:,:8] y = data.iloc[:,8] #模型训练及预测 from sklearn.tree import DecisionTreeClassifier as DTC dtc = DTC(criterion='entropy') # 建立决策树模型,基于信息熵 dtc.fit(x, y) # 训练模型 # 导入相关函数,可视化决策树。 # 导出的结果是一个dot文件,需要安装Graphviz才能将它转换为pdf或png等格式。 from sklearn.tree import export_graphviz x = pd.DataFrame(x) """ string1 = ''' edge [fontname="NSimSun"]; node [ fontname="NSimSun" size="15,15"]; { ''' string2 = '}' """ with open("../tmp/tree.dot", 'w') as f: export_graphviz(dtc, feature_names = x.columns, out_file = f) f.close() from IPython.display import Image from sklearn import tree import pydotplus dot_data = tree.export_graphviz(dtc, out_file=None, #regr_1 是对应分类器 feature_names=data.columns[:8], #对应特征的名字 class_names=data.columns[8], #对应类别的名字 filled=True, rounded=True, special_characters=True) graph = pydotplus.graph_from_dot_data(dot_data) graph.write_png('../tmp/example.png') #保存图像 Image(graph.create_png())
结果如下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号