使用scrapy选择器selector解析获取百度结果
0x00 概述
需要成功安装scrapy,安装方法与本文无关,不在这多说。
0x01 配置settings
由于百度对于user-agent进行验证,所以需要添加。
settings.py中找到DEFAULT_REQUEST_HEADERS,设置好后如下:
DEFAULT_REQUEST_HEADERS = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/5.0.4.3000 Chrome/47.0.2526.73 Safari/537.36', }
settings.py中找到ROBOTSTXT_OBEY,设置好后如下:
ROBOTSTXT_OBEY = False
0x02 写个爬虫
spider文件夹中建立baidu_spider.py,内容如下:
import scrapy from scrapy.selector import Selector class DmozSpider(scrapy.Spider): name = "dmoz" allowed_domains = ["baidu.com"] start_urls = [ "https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=0&rsv_idx=1&tn=baidu&wd=1111&rsv_pq=e99a82620002899b&rsv_t=9aeedvIqMvwImRMhMsGBvD%2BjM%2Fd%2Byd10oiaBWGgrEiZ79fKqGUhhZCWWE0w&rqlang=cn&rsv_enter=1&rsv_sug3=4&rsv_sug1=1&rsv_sug7=100" ] def parse(self, response): sel = Selector(response) print sel.xpath('//h3[@class="t"]/a/text()') print sel.xpath('//h3[@class="t"]/a/@href')
0x03 看下结果
运行scrapy crawl dmoz命令。
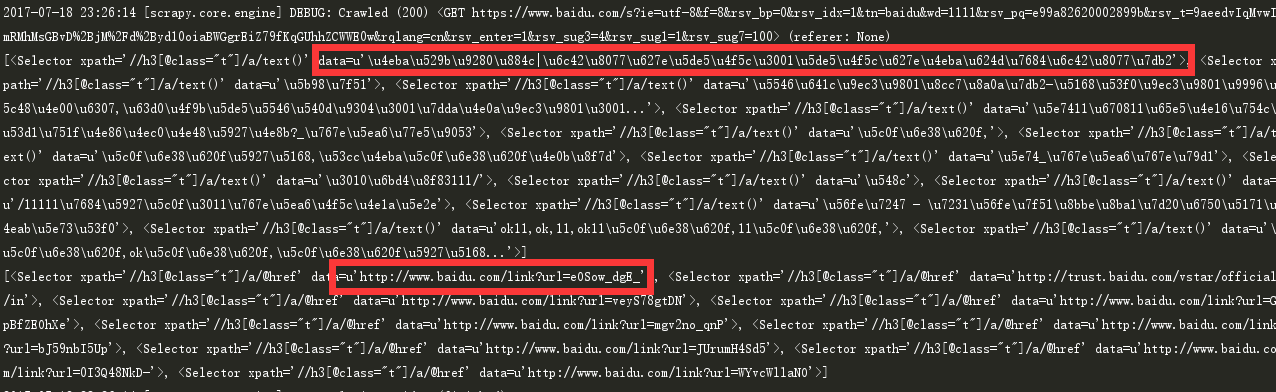
内容和链接已经抓取出来,结果如下:
低调求发展,潜心习安全。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号