免登录下载微博图片代码研究及优化1.0
1.代码基础:https://github.com/yAnXImIN/weiboPicDownloader.git
2.下载后运行代码初体验
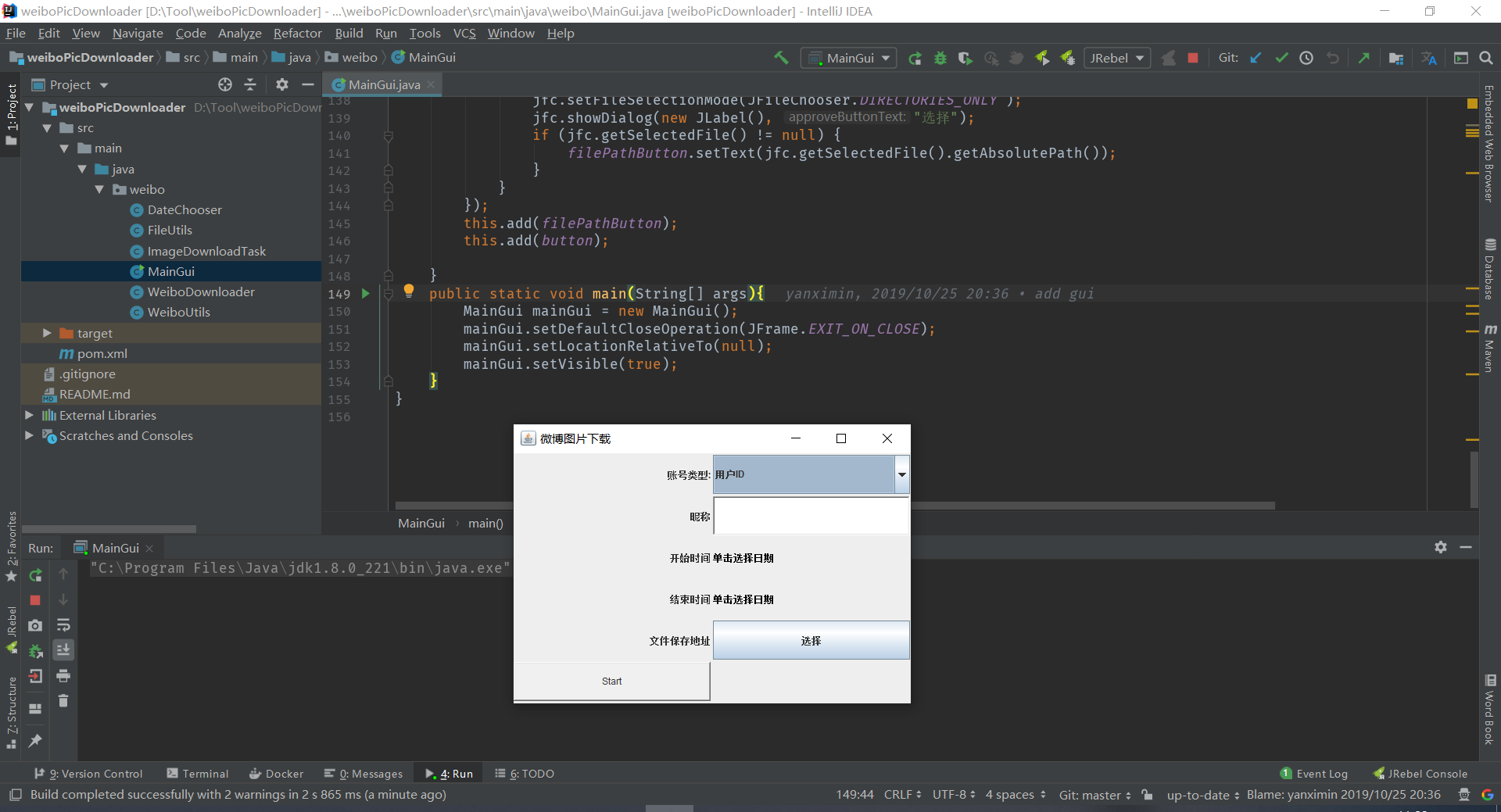
3.找一个微博试试看,看代码文档这里需要微博id,随便找一条微博,找到ouid,这里是火影忍者的微博,id是
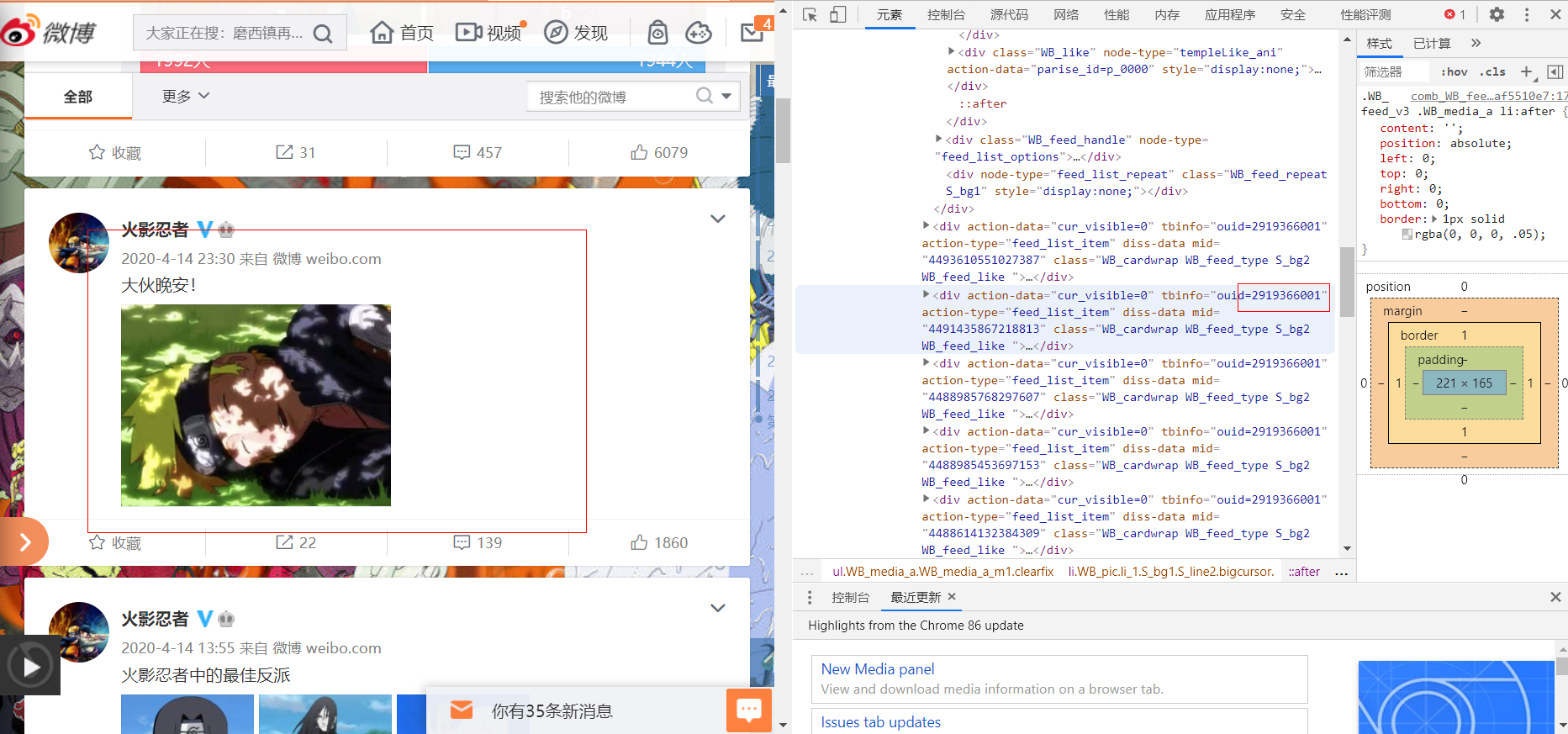
3.实验一下效果
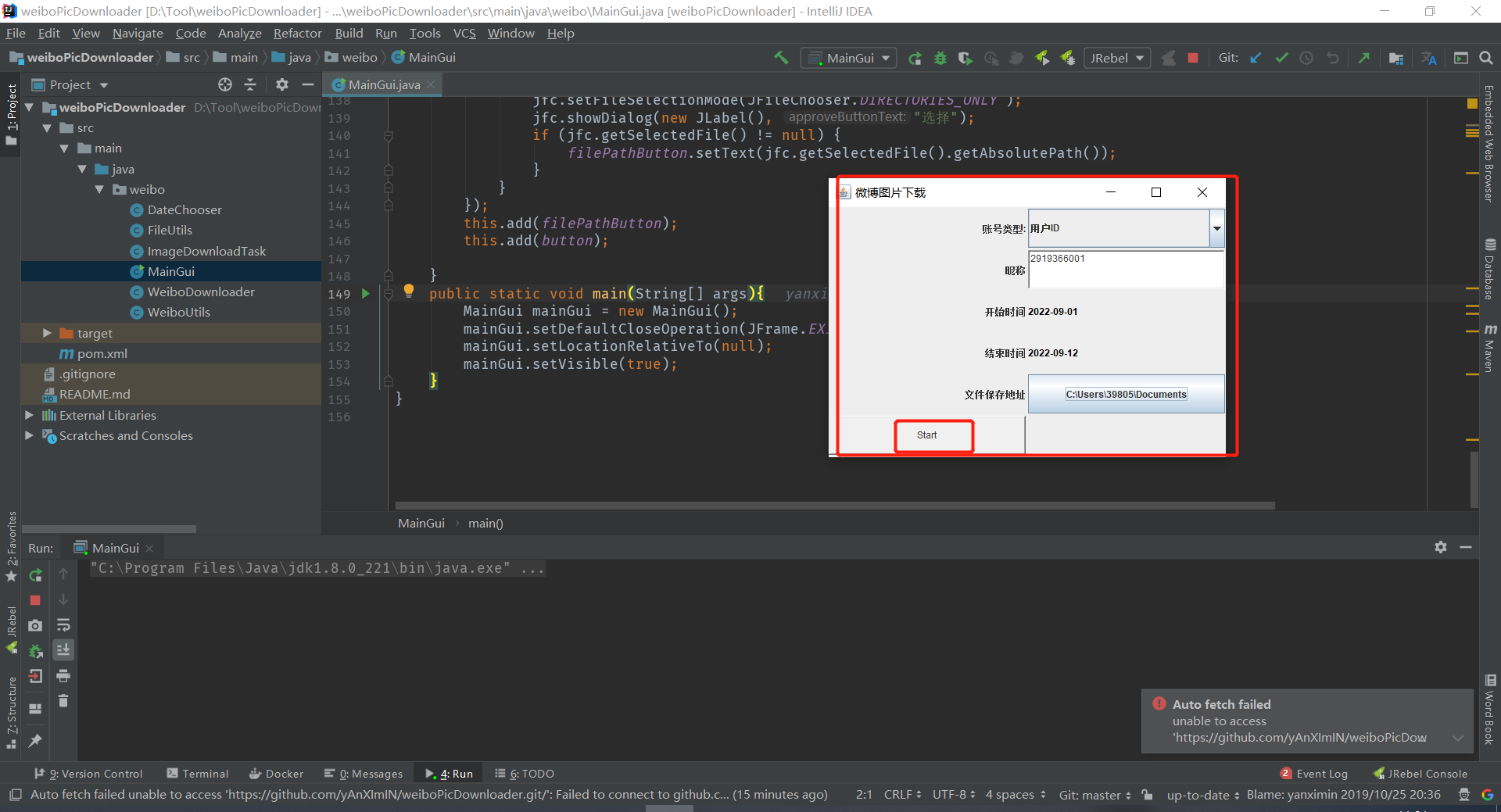
1.最后运行结果为0
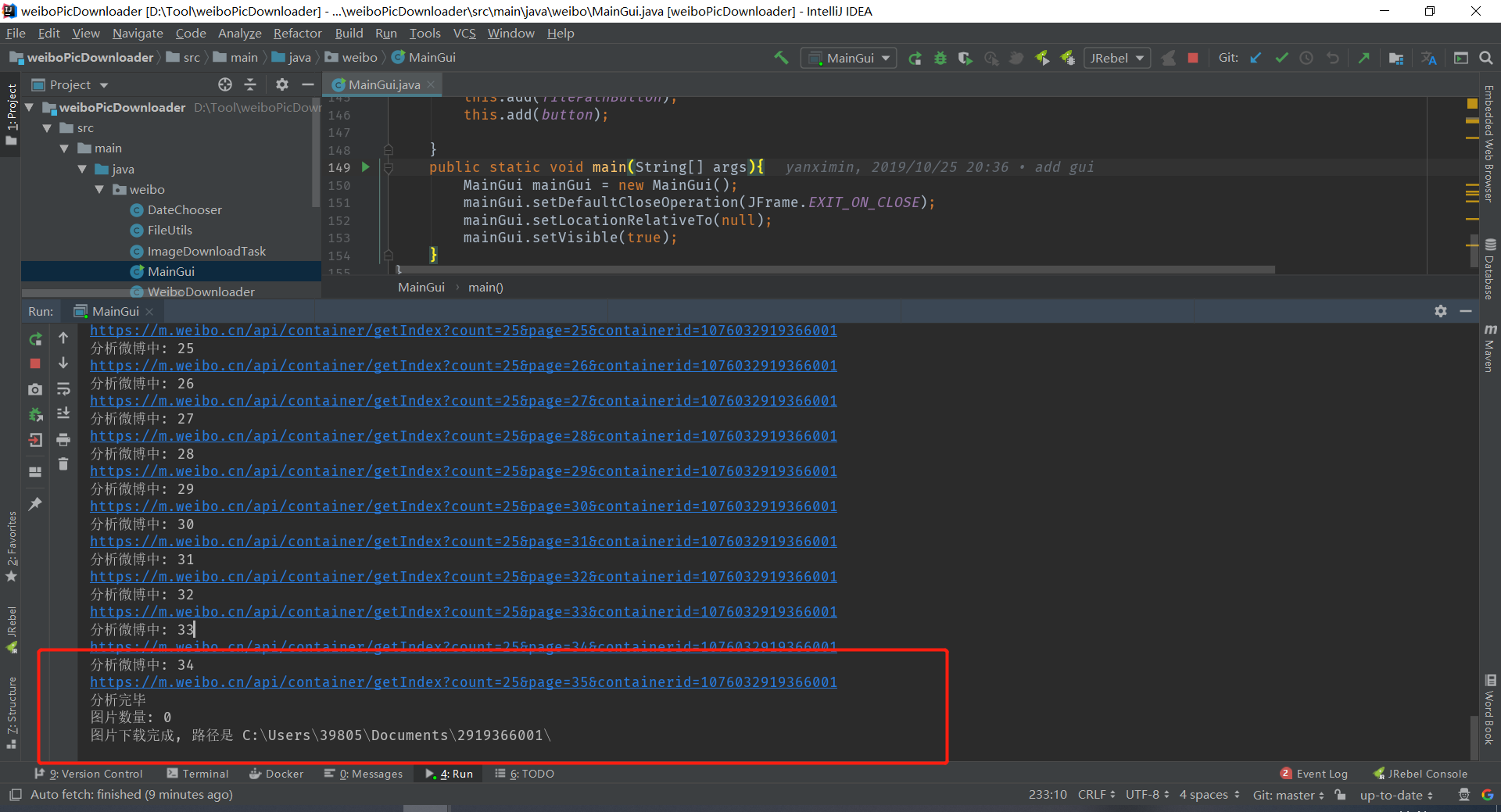
4.分析一下,可能时间太短,但是重新把时间跨度拉长了几年还是没用。
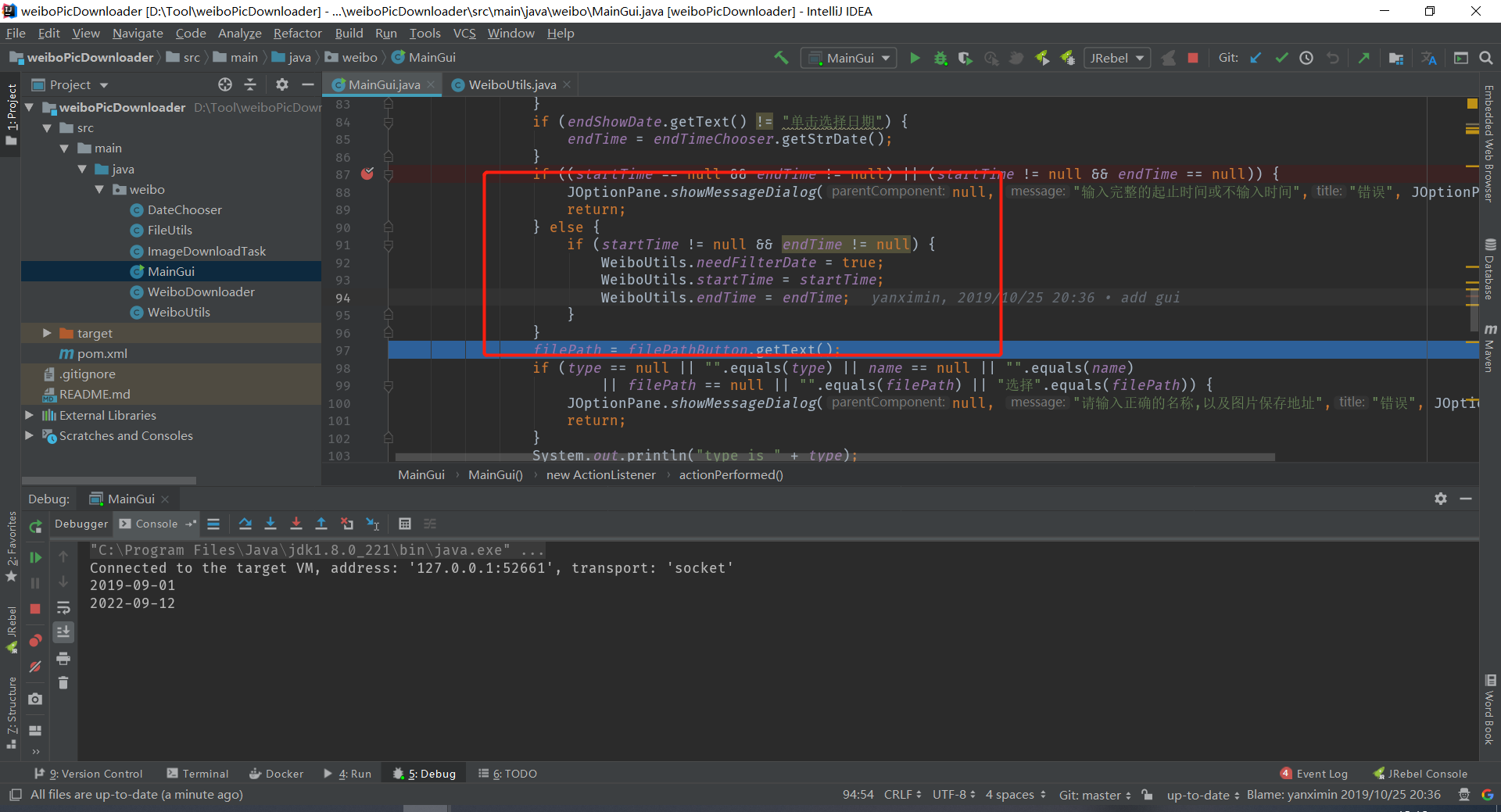
时间已经设置排查到任何时间都会转为1970-01-01,所以我们选的时间都比这个要早,排除了。
注释后,不用选择时间重新运行试试,成功。
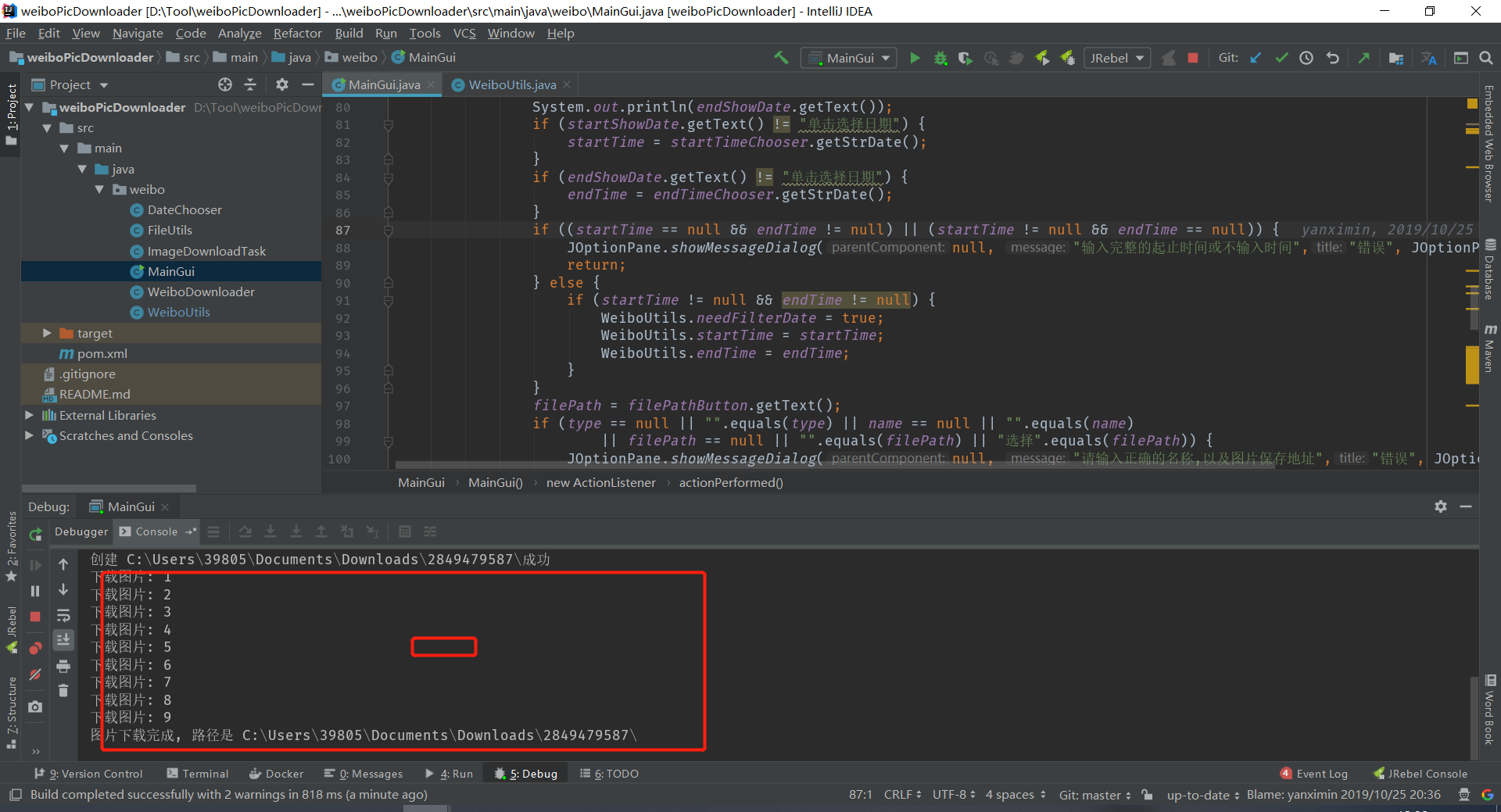
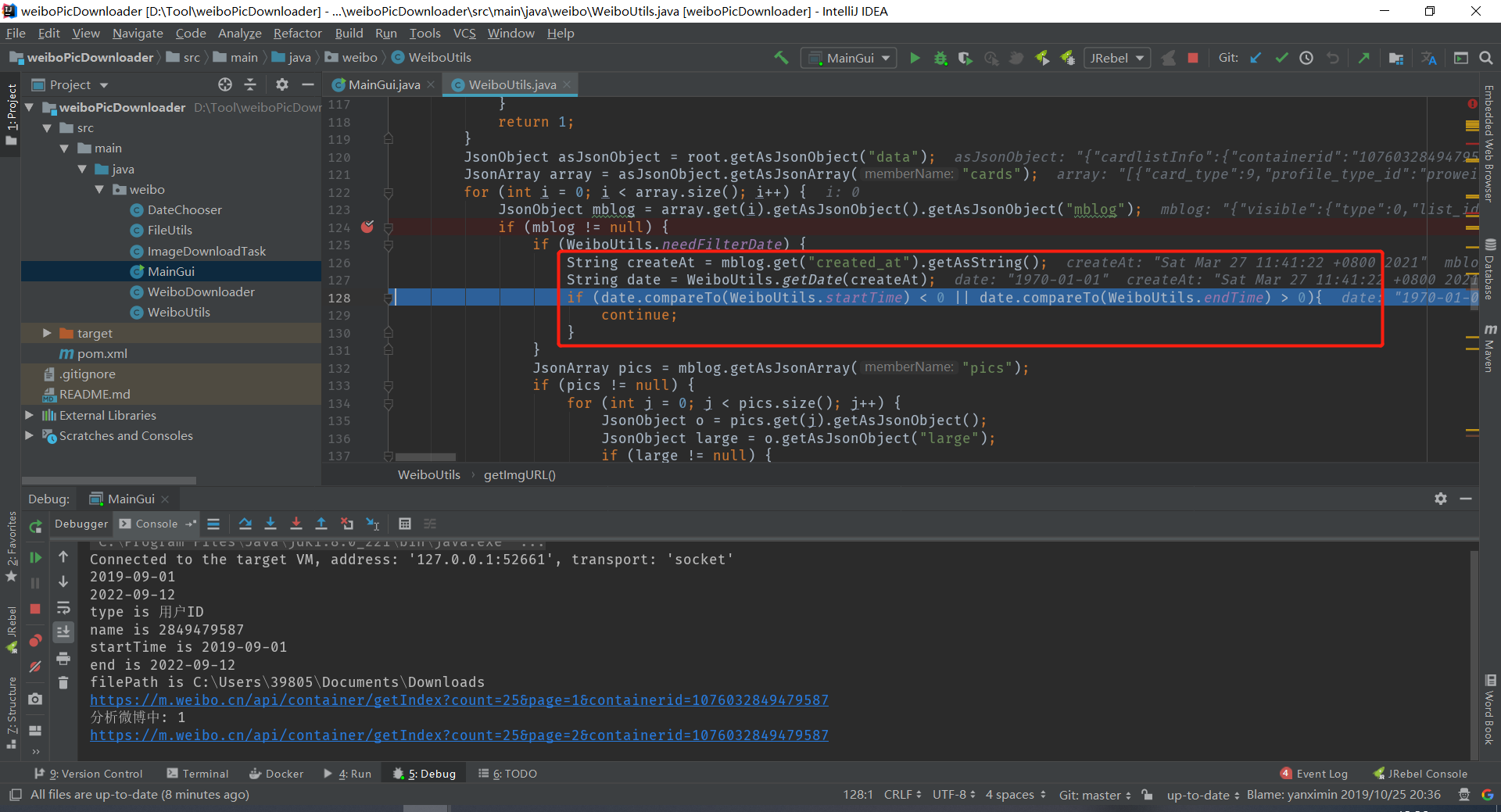
5.继续排雷,找个图片数量多的博客试试, 下载过程中会出现空指针
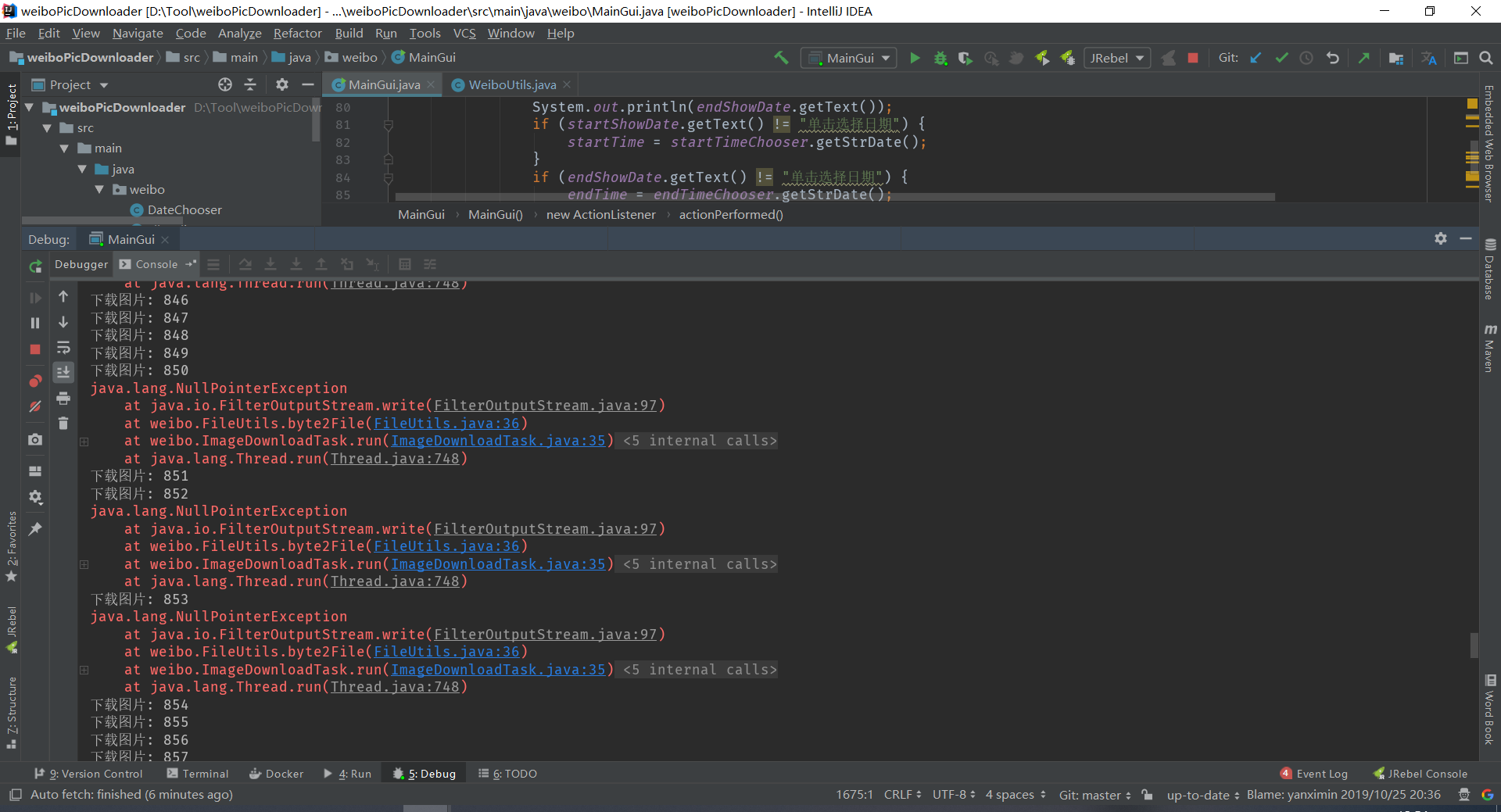
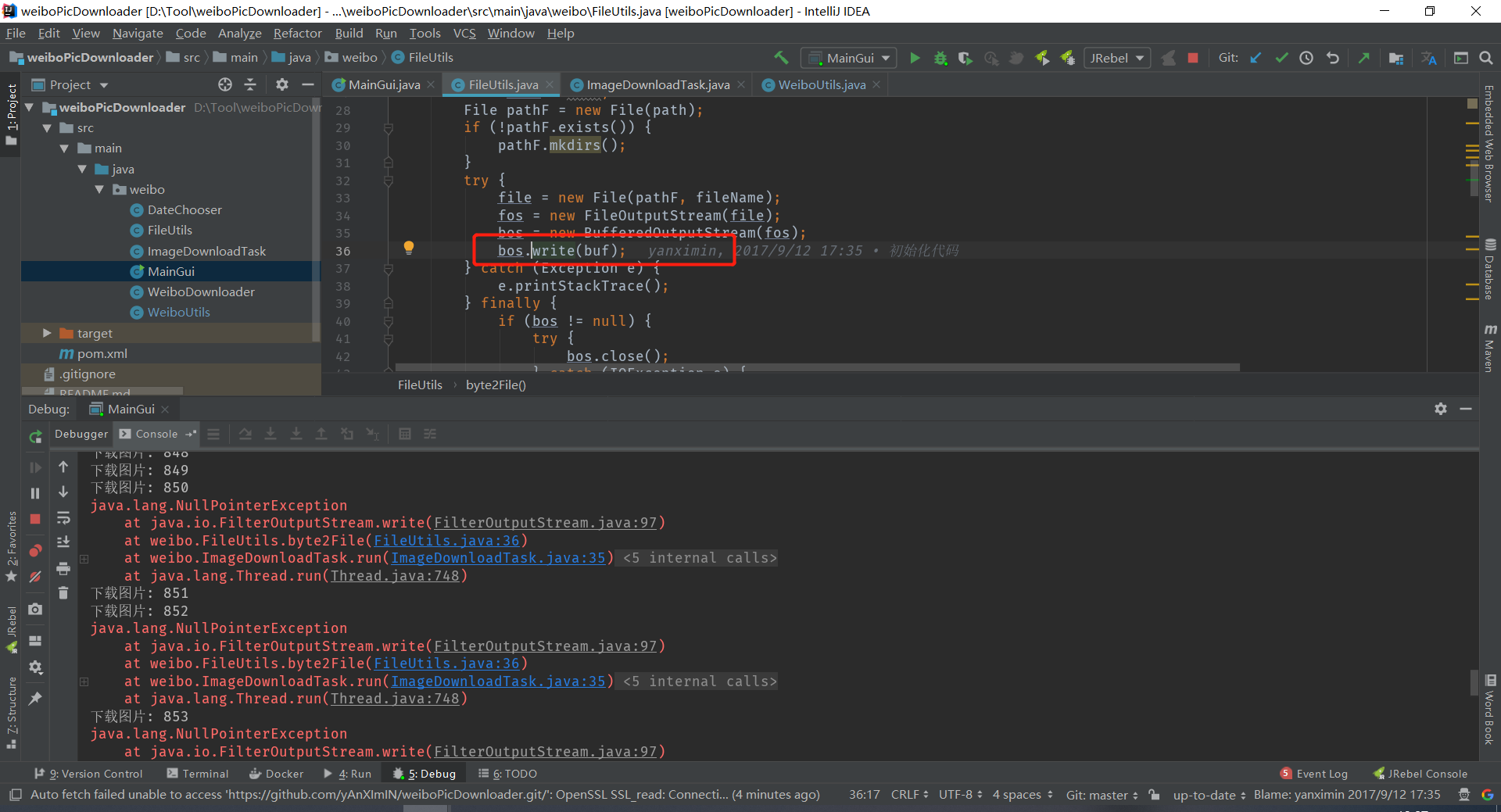
定位到这里是空的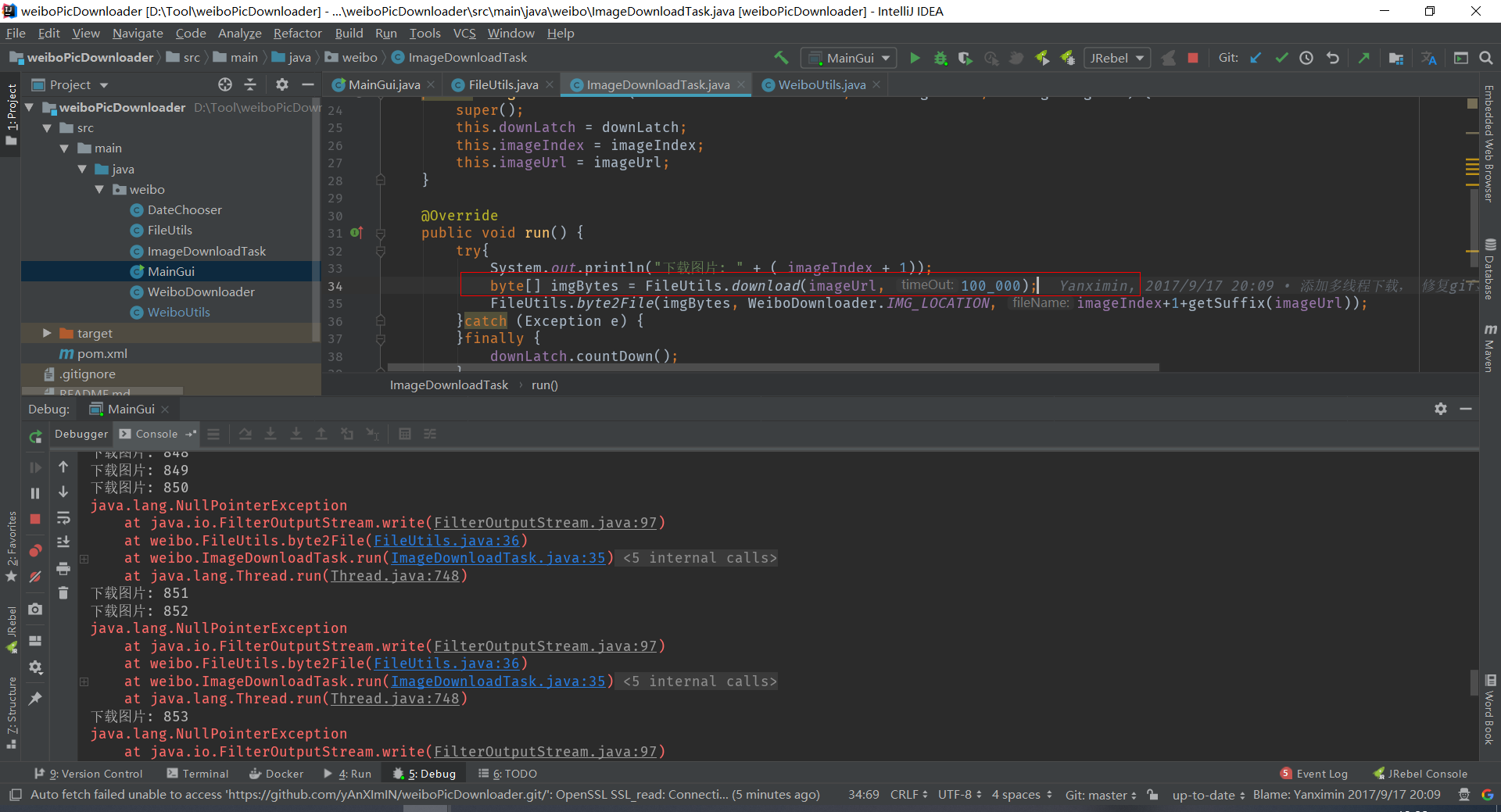
加个打印看看,最后没有报错了,看来有可能是

分析里面的代码,排查一下原因,重新换个id试试。
public static byte[] download(String webUrl, int timeOut) {
HttpURLConnection connection = null;
long start = System.currentTimeMillis();
try {
URL url = new URL(webUrl);
connection = (HttpURLConnection) url.openConnection();
connection.setConnectTimeout(timeOut);
connection.setReadTimeout(timeOut);
connection.setRequestProperty("User-Agent", USER_AGENT);
int len = connection.getContentLength();
//1.最大图片40M,那些报错的可能就是图片太大。但是第二次执行就没报错排查这里
if (len >= MAX_DOWNLOAD_SIZE) {
return null;
}
//2.网络超时了可能。
if (len == -1) {
try (InputStream in = connection.getInputStream()) {
return IOUtils.toByteArray(connection.getInputStream());
}
} else {
byte[] data = new byte[len];
byte[] buffer = new byte[4096 * 2];
int count = 0, sum = 0;
try (InputStream in = connection.getInputStream()) {
while ((count = in.read(buffer)) > 0) {
long elapse = System.currentTimeMillis() - start;
if (elapse >= timeOut) {
data = null;
break;
}
System.arraycopy(buffer, 0, data, sum, count);
sum += count;
}
}
return data;
}
} catch (Exception e) {
return null;
} finally {
if (connection != null) {
connection.disconnect();
}
}
}
出现新的错误
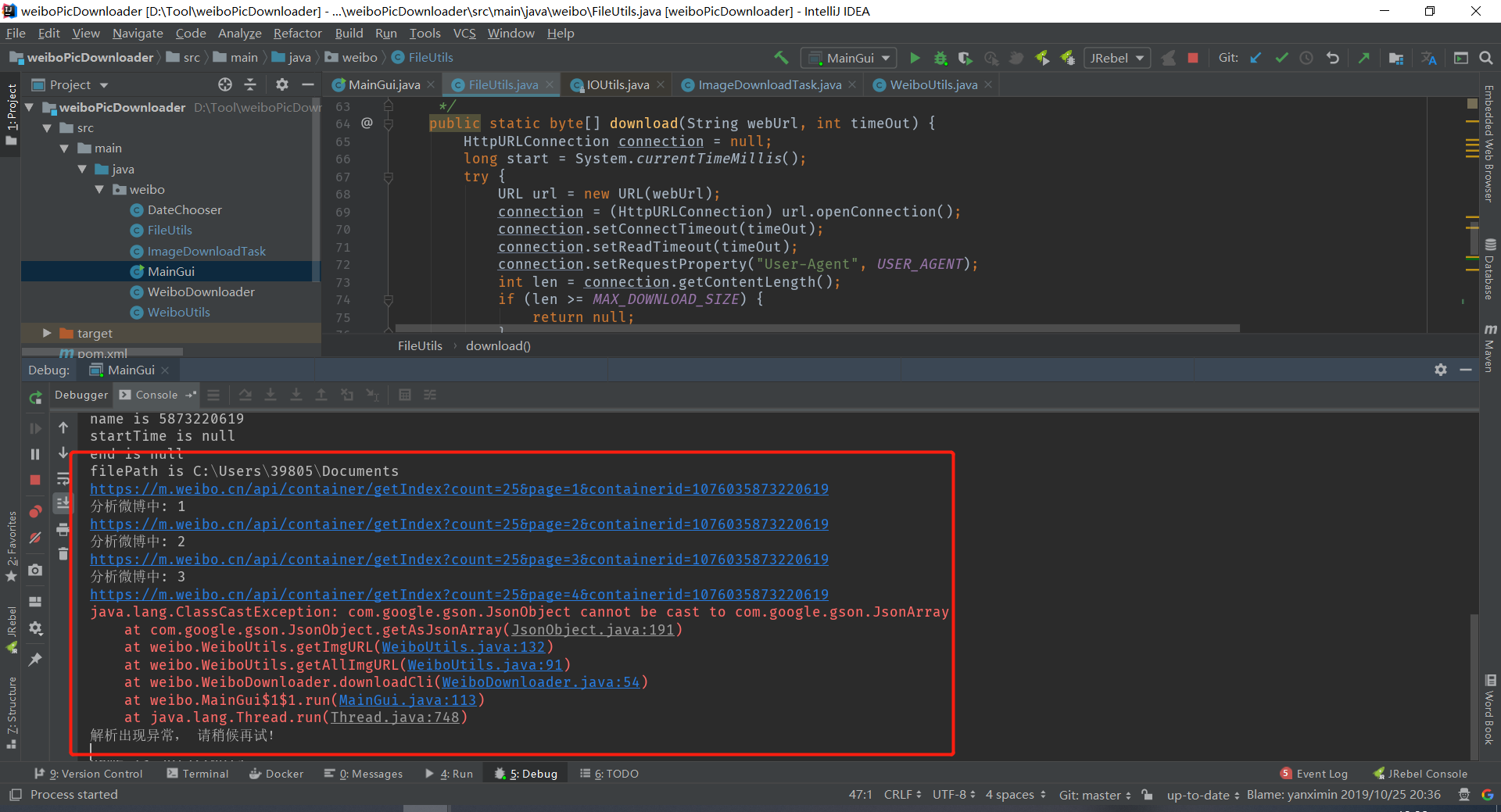
JsonObject asJsonObject = root.getAsJsonObject("data");
JsonArray array = asJsonObject.getAsJsonArray("cards");
for (int i = 0; i < array.size(); i++) {
JsonObject mblog = array.get(i).getAsJsonObject().getAsJsonObject("mblog");
if (mblog != null) {
/*if (WeiboUtils.needFilterDate) {
String createAt = mblog.get("created_at").getAsString();
String date = WeiboUtils.getDate(createAt);
if (date.compareTo(WeiboUtils.startTime) < 0 || date.compareTo(WeiboUtils.endTime) > 0){
continue;
}
}*/
JsonArray pics = mblog.getAsJsonArray("pics");//报错位置代码,看来是对象转数组错误,我们打开链接看看。
if (pics != null) {
for (int j = 0; j < pics.size(); j++) {
JsonObject o = pics.get(j).getAsJsonObject();
JsonObject large = o.getAsJsonObject("large");
if (large != null) {
urls.add(large.get("url").getAsString());
}
}
}
}
}
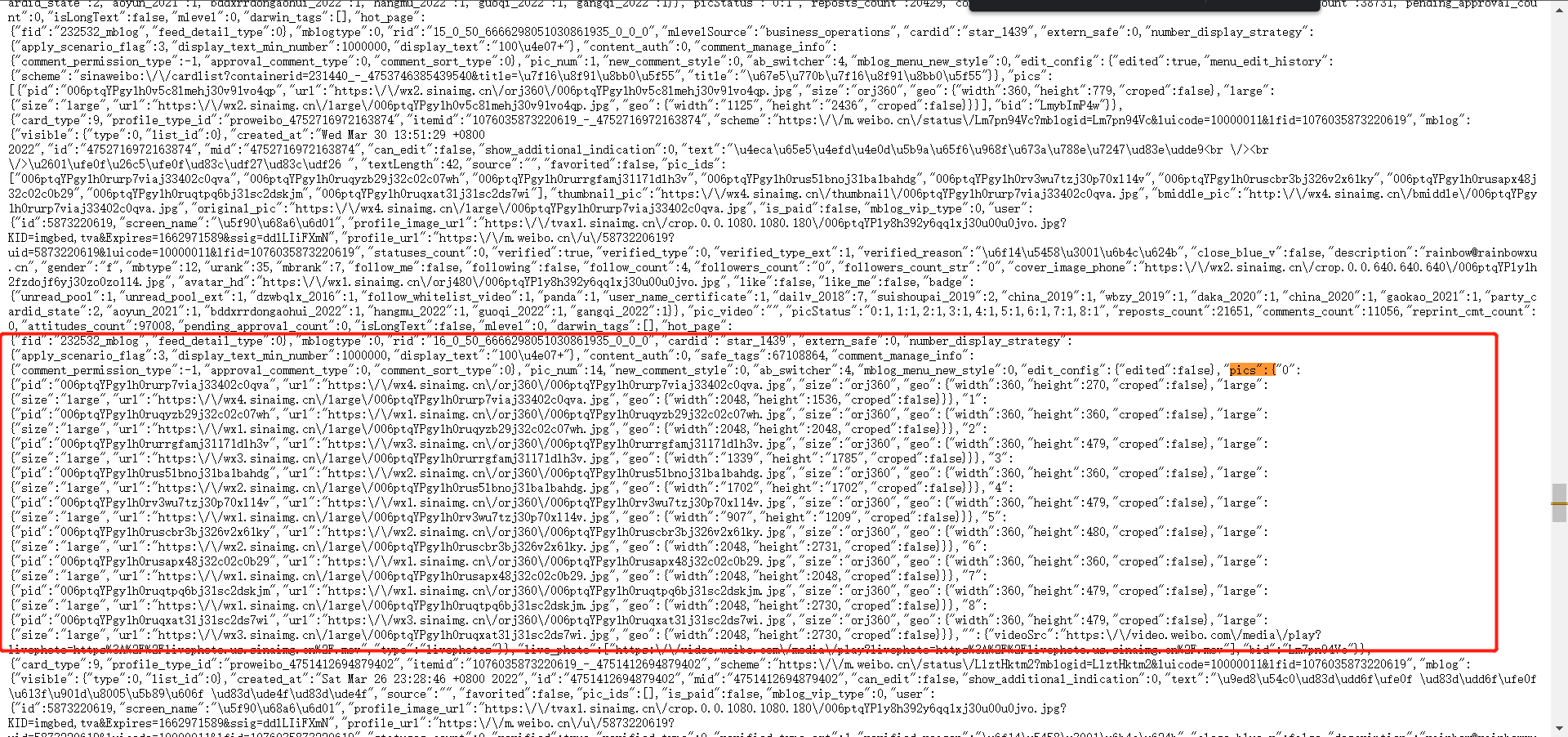
上图确实是出现了对象,不能直接转数组。代码可以做微调
JsonArray pics = null; try { pics = mblog.getAsJsonArray("pics"); } catch (Exception e) { pics=new JsonArray(); JsonObject temp=mblog.getAsJsonObject("pics"); JsonArray finalPics = pics; temp.entrySet().forEach(t->{ finalPics.add(t.getValue()); }); e.printStackTrace(); }
继续调试上个问题,有时候网络异常会造成这个错误。
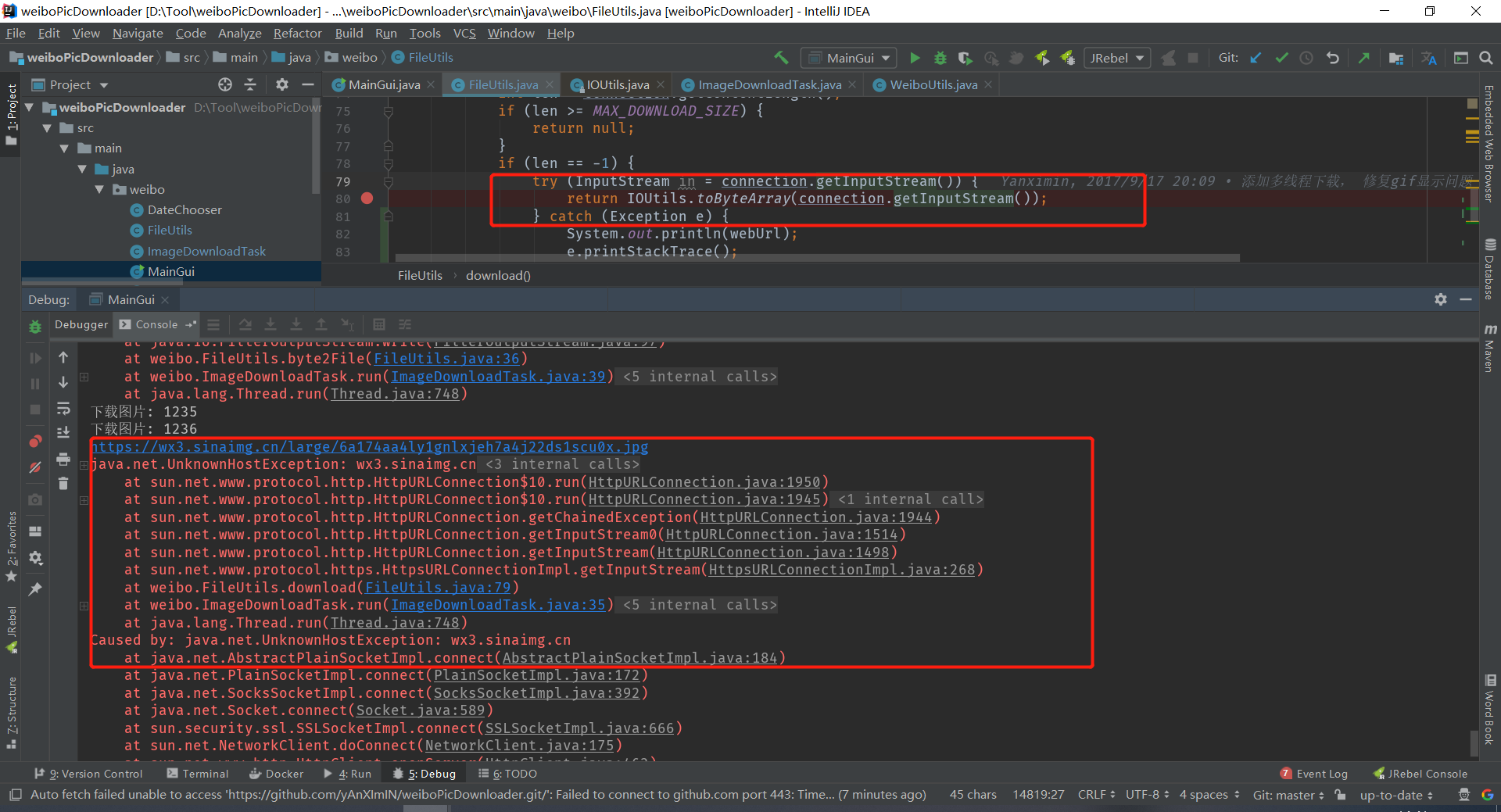
我认为这里出现异常可以重新加入队列。
CountDownLatch downLatch = new CountDownLatch(imgUrls.size());
ExecutorService executor = Executors.newFixedThreadPool(4);
for(int i=0;i<imgUrls.size();i++){
executor.submit(new ImageDownloadTask(downLatch, i, imgUrls.get(i)));
}
downLatch.await();
System.out.println("图片下载完成, 路径是 " + IMG_LOCATION);
executor.shutdown();
修改后的代码,下载失败就重新添加到执行数组里重新执行,从总的80%的丢失率直接降低到1%左右,后续丢失了但是循环已经结束也没法重新执行了。
CountDownLatch downLatch = new CountDownLatch(imgUrls.size()); ExecutorService executor = Executors.newFixedThreadPool(4); int j=imgUrls.size(); for(int i=0;i<imgUrls.size();i++){ executor.submit(new ImageDownloadTask(downLatch, i, imgUrls.get(i),imgUrls)); if(i%10==0){ Thread.sleep(1000); } System.out.println("总数:"+imgUrls.size()); }
System.out.println("下载图片: " + ( imageIndex + 1));
byte[] imgBytes = FileUtils.download(imageUrl, 100_000);
if(Objects.isNull(imgBytes)){
System.out.println(imgBytes);
imageUrls.add(imageUrl);
}
FileUtils.byte2File(imgBytes, WeiboDownloader.IMG_LOCATION, imageIndex+1+getSuffix(imageUrl));
这期优化到这里。
新代码:https://github.com/tianxiadatong/wbPicDown
后续构思1.修复大批量下载丢失问题2.加数据库3.图片名称是按数字命名的改成图片地址自带的名称命名。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号