第四期书生大模型实战营——入门岛
入门岛关卡概览
-
第1关 Linux基础知识
-
(必做)完成SSH连接与端口映射并运行
hello_world.py -
将Linux基础命令在开发机上完成一遍
-
使用VScode远程连接开发机并创建一个conda环境
-
第2关 Python基础知识
-
(必做)通过Leetcode 383
-
(必做)VScode连接InternStudio debug笔记
-
pip安装到指定目录
-
第3关 Git基础知识
-
提交自我介绍
-
构建个人项目
-
第4关 玩转HF/魔搭/魔乐社区
-
(必做)使用HF/魔搭/魔乐社区下载模型(至少下载
config.json和model.safetensors.index.json文件) -
(优秀作业必做)将下载好的文件上传到对应HF/魔搭/魔乐社区
-
(优秀作业必做)在HF平台上使用Spaces并把intern_cobuild部署成功
第1关 Linux基础知识
SSH及端口映射
什么是SSH
SSH全称Secure Shell,中文翻译为安全外壳,它是一种网络安全协议,通过加密和认证机制实现安全的访问和文件传输等业务。SSH 协议通过对网络数据进行加密和验证,在不安全的网络环境中提供了安全的网络服务。
SSH 是(C/S架构)由服务器和客户端组成,为建立安全的 SSH 通道,双方需要先建立 TCP 连接,然后协商使用的版本号和各类算法,并生成相同的会话密钥用于后续的对称加密。在完成用户认证后,双方即可建立会话进行数据交互。
什么是端口映射
端口映射是一种网络技术,它可以将外网中的任意端口映射到内网中的相应端口,实现内网与外网之间的通信。通过端口映射,可以在外网访问内网中的服务或应用,实现跨越网络的便捷通信。
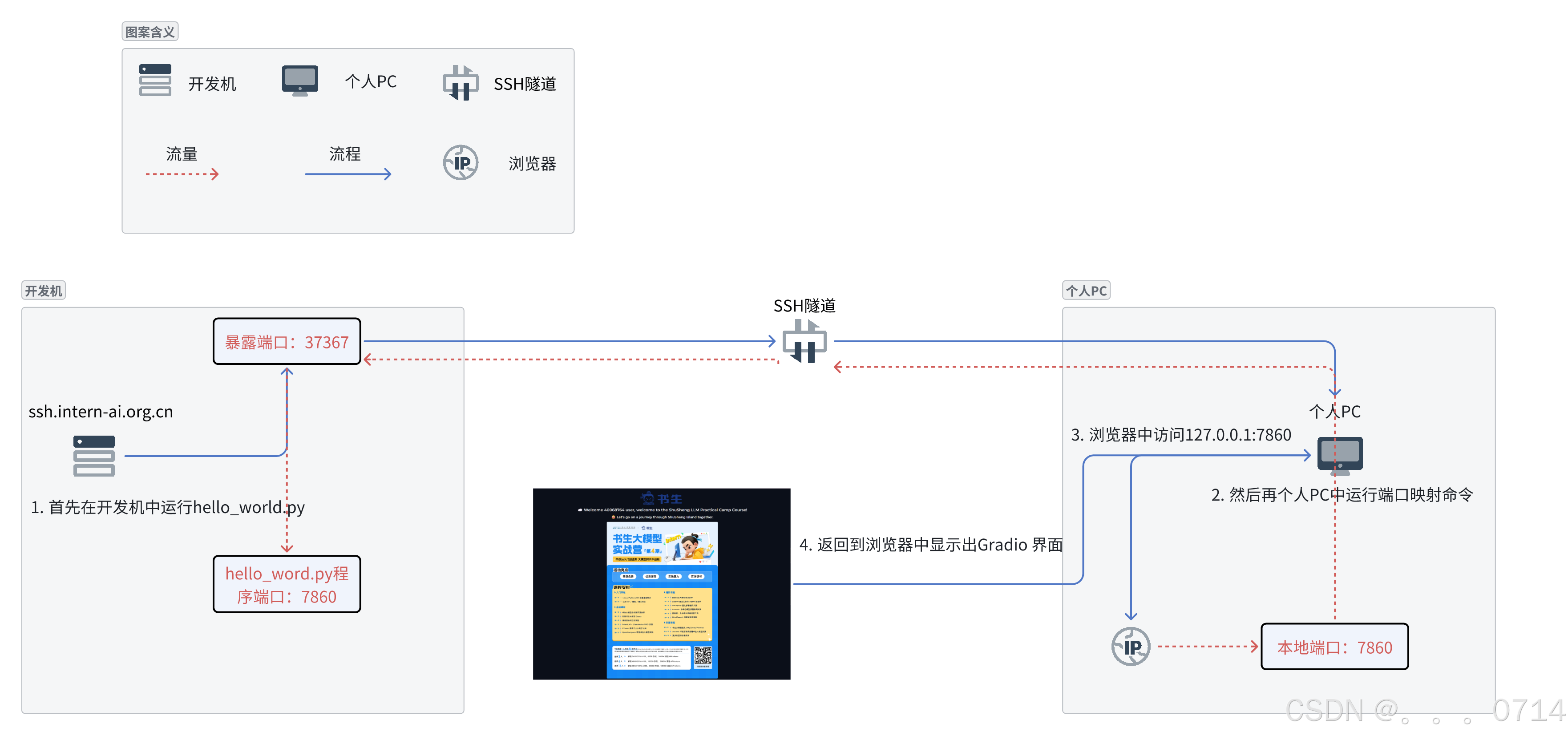
在主机上运行端口映射命令
ssh -p 37367 root@ssh.intern-ai.org.cn -CNg -L 7860:127.0.0.1:7860 -o StrictHostKeyChecking=no
个人PC会远程连接到开发机唯一暴露在外的37367端口,(这个在SSH的时候提到过每个人的开发机暴露的端口都不一样),并设置隧道选项。暴露端口是作为中转站进行流量的转发。
-C:启用压缩,减少传输数据量。
-N:不执行远程命令,只建立隧道。
-g:允许远程主机连接到本地转发的端口。
当在个人PC上执行这个SSH命令后,SSH客户端会在本地机器的7860端口上监听。
任何发送到本地7860端口的流量,都会被SSH隧道转发到远程服务器的127.0.0.1地址上的7860端口。
这意味着,即使开发机的这个端口没有直接暴露给外部网络,我们也可以通过这个隧道安全地访问远程服务器上的服务。
实战
1.使用VScode远程连接开发机
(1)创建开发机

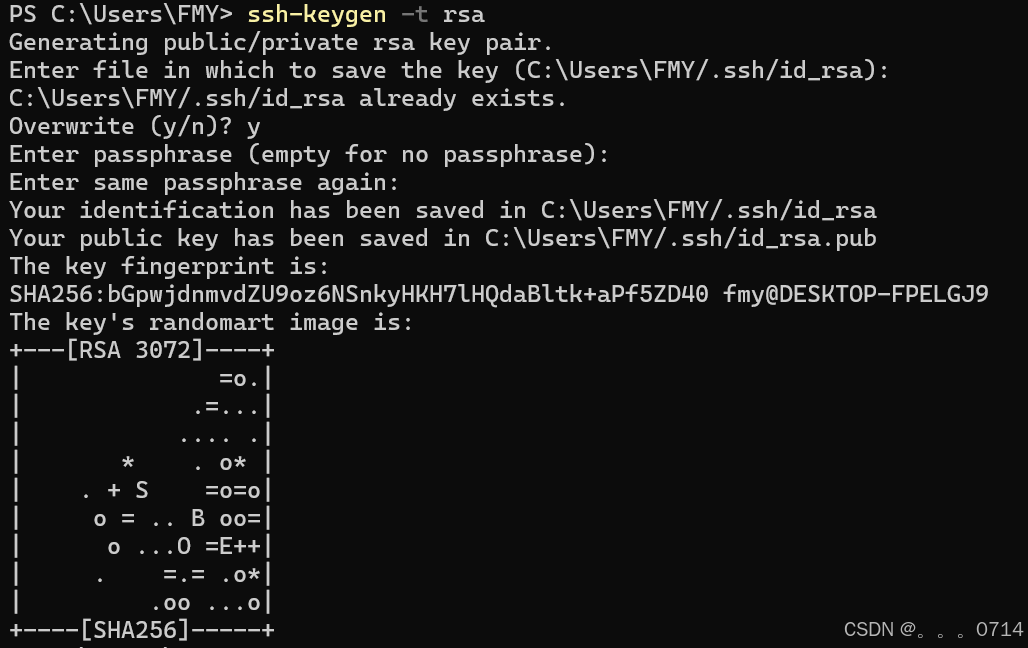
(2) 配置SSH密钥
使用RSA算法生成密钥,命令为ssh-keygen -t rsa:
注意,windows中使用PowerShell而不是cmd
ssh-keygen支持RSA和DSA两种认证密钥。
常用参数包括:
-t:指定密钥类型,如dsa、ecdsa、ed25519、rsa。
-b:指定密钥长度。
-C:添加注释。
-f:指定保存密钥的文件名。
-i:读取未加密的ssh-v2兼容的私钥/公钥文件。
使用Get-Content命令查看生成的密钥并复制:

添加SSH公钥:
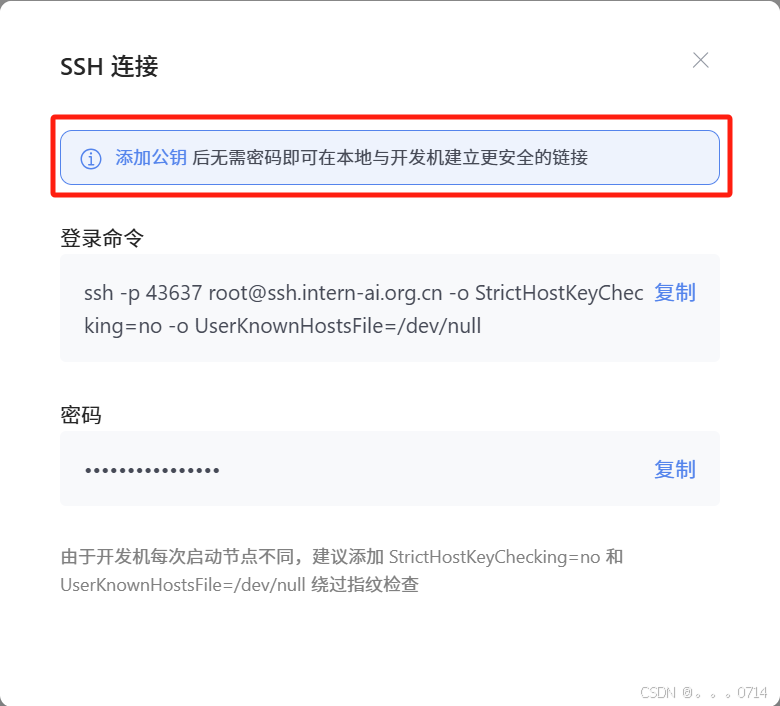
添加公钥成功:
重启终端
(3)使用VScode进行SSH远程连接
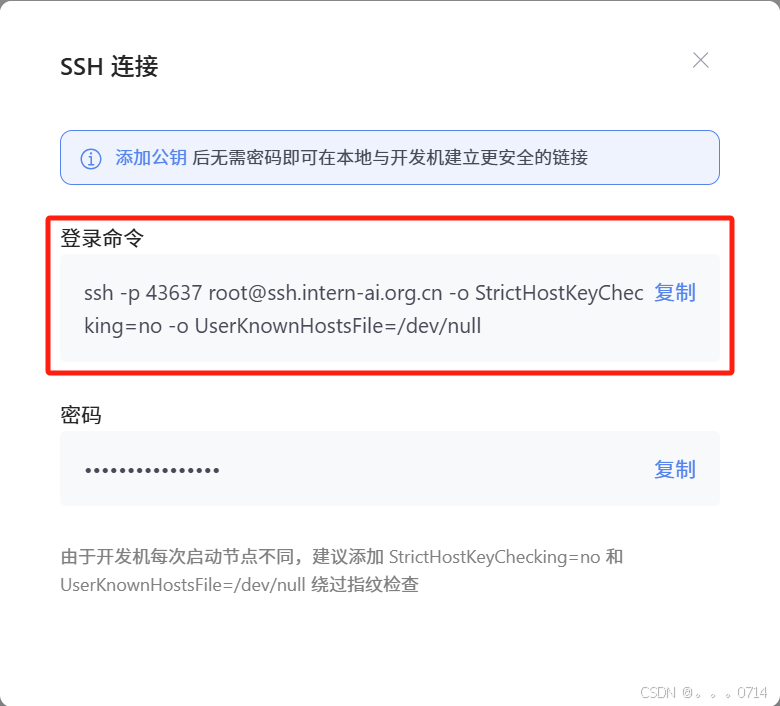
复制SSH连接的登陆命令:
打开本地VScode,安装Remote-SSH插件:
点击侧边栏的远程连接图标,在SSH中点击“+”按钮,添加开发机SSH连接的登录命令并回车:

可使用默认的配置文件,若自定义配置文件,具体内容如下:
Host ssh.intern-ai.org.cn #主机ip也可以是域名
HostName ssh.intern-ai.org.cn #主机名
Port 43637 #主机的SSH端口
User root #登录SSH使用的用户
#忽略指纹验证,但是在一般的安全实践中,不建议随意禁用严格的主机密钥检查:
StrictHostKeyChecking no #表示禁用严格的主机密钥检查。这意味着当连接到一个新的 SSH 服务器时,不会严格验证服务器的主机密钥,可能会带来一定的安全风险
UserKnownHostsFile /dev/null #将用户已知的主机密钥文件设置为 /dev/null ,这实质上是忽略了对已知主机密钥的记录和使用。
点击连接该远程开发机:
connected表示开发机连接成功:
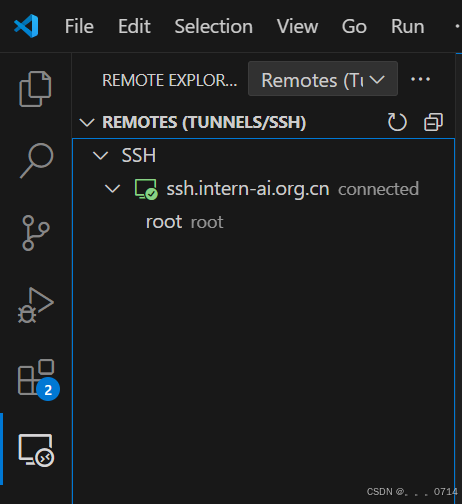
当下一次进行远程连接的时候,就不需要输入登录命令等信息了,只需要打开VScode的远程连接就可以看到第一次连接的开发机信息,下面的root代表我们第一连接开发机时使用的是/root工作目录。
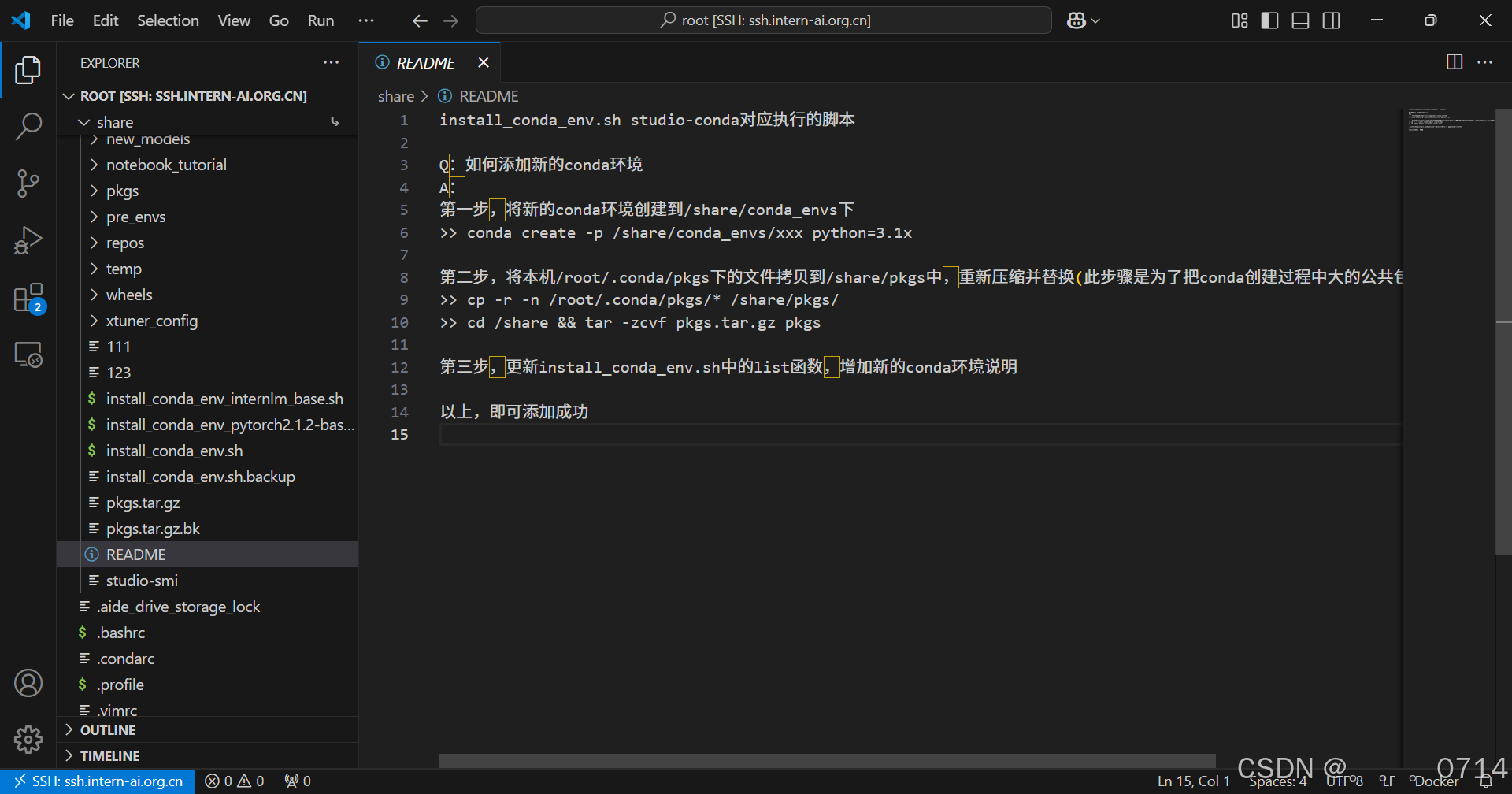
查看/root/share/目录下的README文件:
2.创建一个conda环境
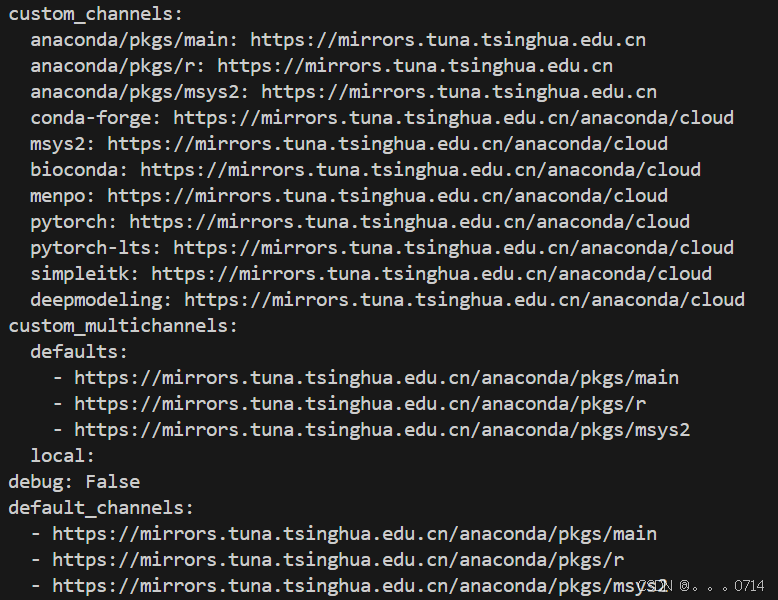
单击VScode页面底部状态栏中的“终端”图标(通常显示为两个图标一个X和一个!),可以快速打开VScode的终端面板。使用conda config --show查看conda的默认配置,发现该开发机提供的conda已使用国内清华镜像源,无需换源:
使用conda env list查看当前conda中的所有环境:

使用conda create -n L0 python=3.10创建一个新环境L0:
创建虚拟环境的常用参数如下:
-n 或 --name:指定要创建的环境名称。
-c 或 --channel:指定额外的软件包通道。
–clone:从现有的环境克隆来创建新环境。
-p 或 --prefix:指定环境的安装路径(非默认位置)。-
创建后,可以在.conda目录下的envs目录下找到。
3.完成端口映射并运行hello_world.py
创建一个新的文件,命名为hello_world.py,并将代码内容复制粘贴到该文件中并保存:
hello_world.py代码如下:
import socket
import re
import gradio as gr
# 获取主机名
def get_hostname():
hostname = socket.gethostname()
match = re.search(r'-(\d+)$', hostname)
name = match.group(1)
return name
# 创建 Gradio 界面
with gr.Blocks(gr.themes.Soft()) as demo:
html_code = f"""
<p align="center">
<a href="https://intern-ai.org.cn/home">
<img src="https://intern-ai.org.cn/assets/headerLogo-4ea34f23.svg" alt="Logo" width="20%" style="border-radius: 5px;">
</a>
</p>
<h1 style="text-align: center;">☁️ Welcome {get_hostname()} user, welcome to the ShuSheng LLM Practical Camp Course!</h1>
<h2 style="text-align: center;">😀 Let’s go on a journey through ShuSheng Island together.</h2>
<p align="center">
<a href="https://github.com/InternLM/Tutorial/blob/camp3">
<img src="https://oss.lingkongstudy.com.cn/blog/202410081252022.png" alt="Logo" width="50%" style="border-radius: 5px;">
</a>
</p>
"""
gr.Markdown(html_code)
demo.launch()
激活环境L0并pip install gradio==4.29.0安装hello_world.py的依赖:

运行该文件,并本地打开链接就可以看到Web UI的界面了:
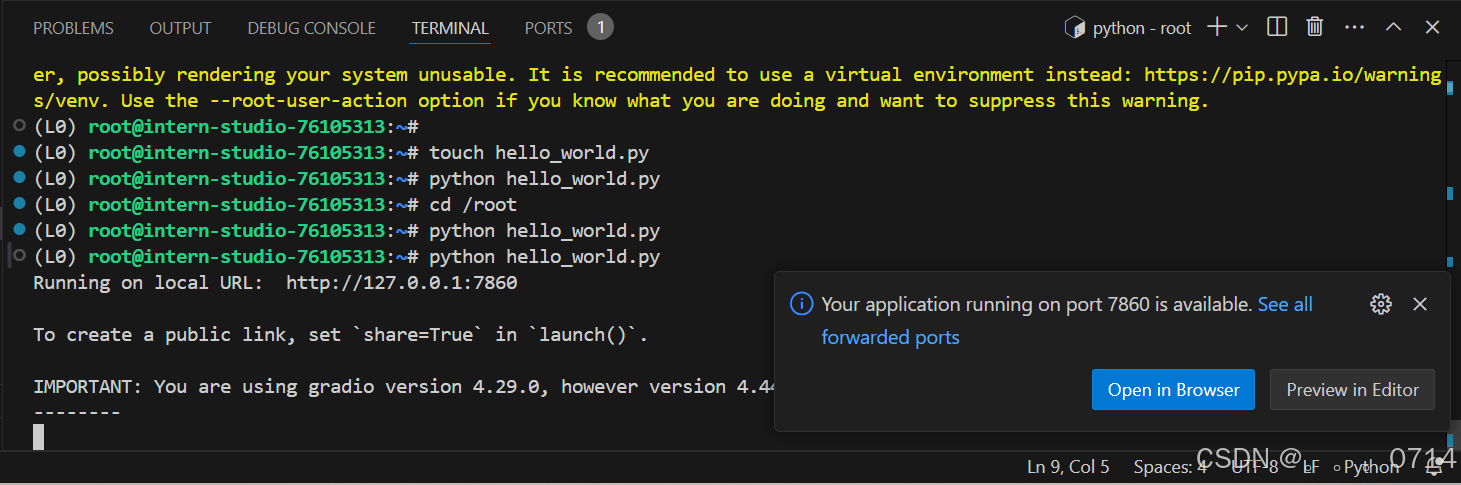
由于VScode提供了自动端口映射的功能,因此不需要手动配置,在终端的右侧可以找到端口选项:

第2关 Python基础知识
VScode连接InternStudio debug笔记
1.python debug
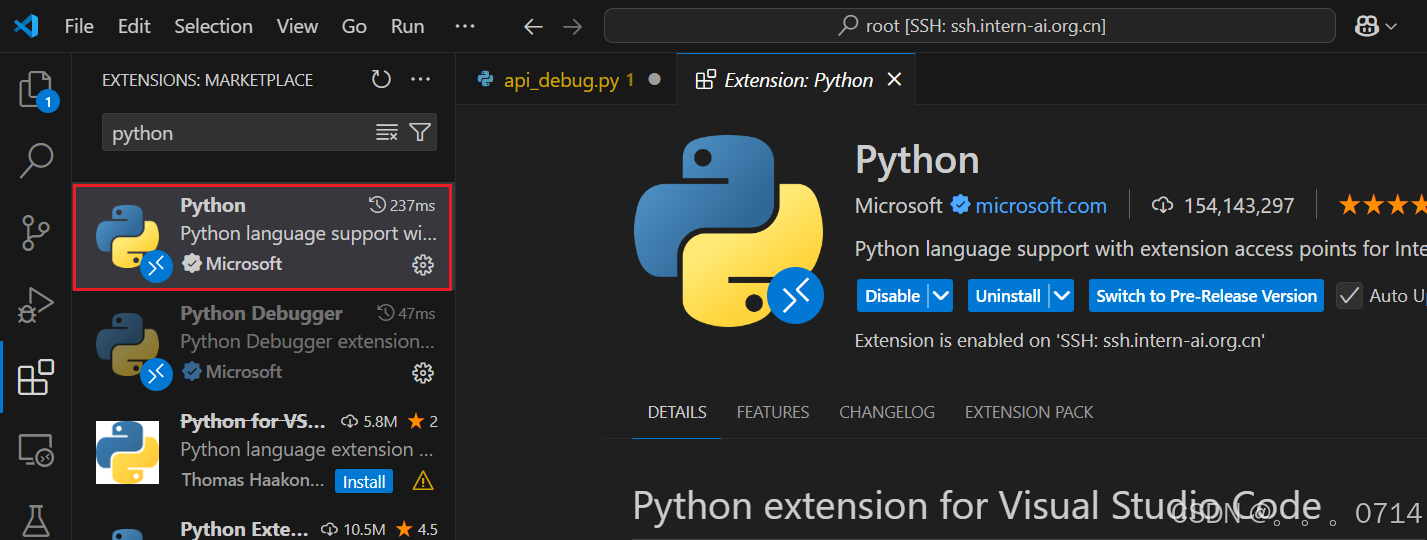
Step1.安装Python扩展
- 打开VSCode,点击左侧扩展栏,搜索Python,并安装。
 Step2.配置调试
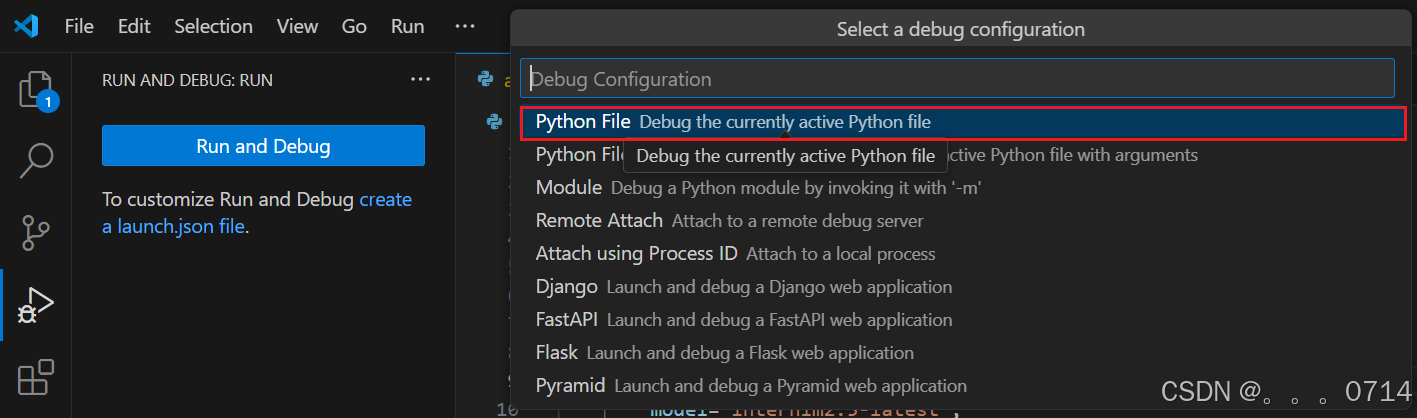
Step2.配置调试 - 打开你的Python文件,点击左侧活动栏的“运行和调试”图标。
- 首次debug需要配置,点击“create a launch.json file”,选择python debugger后选择“Python File” config。
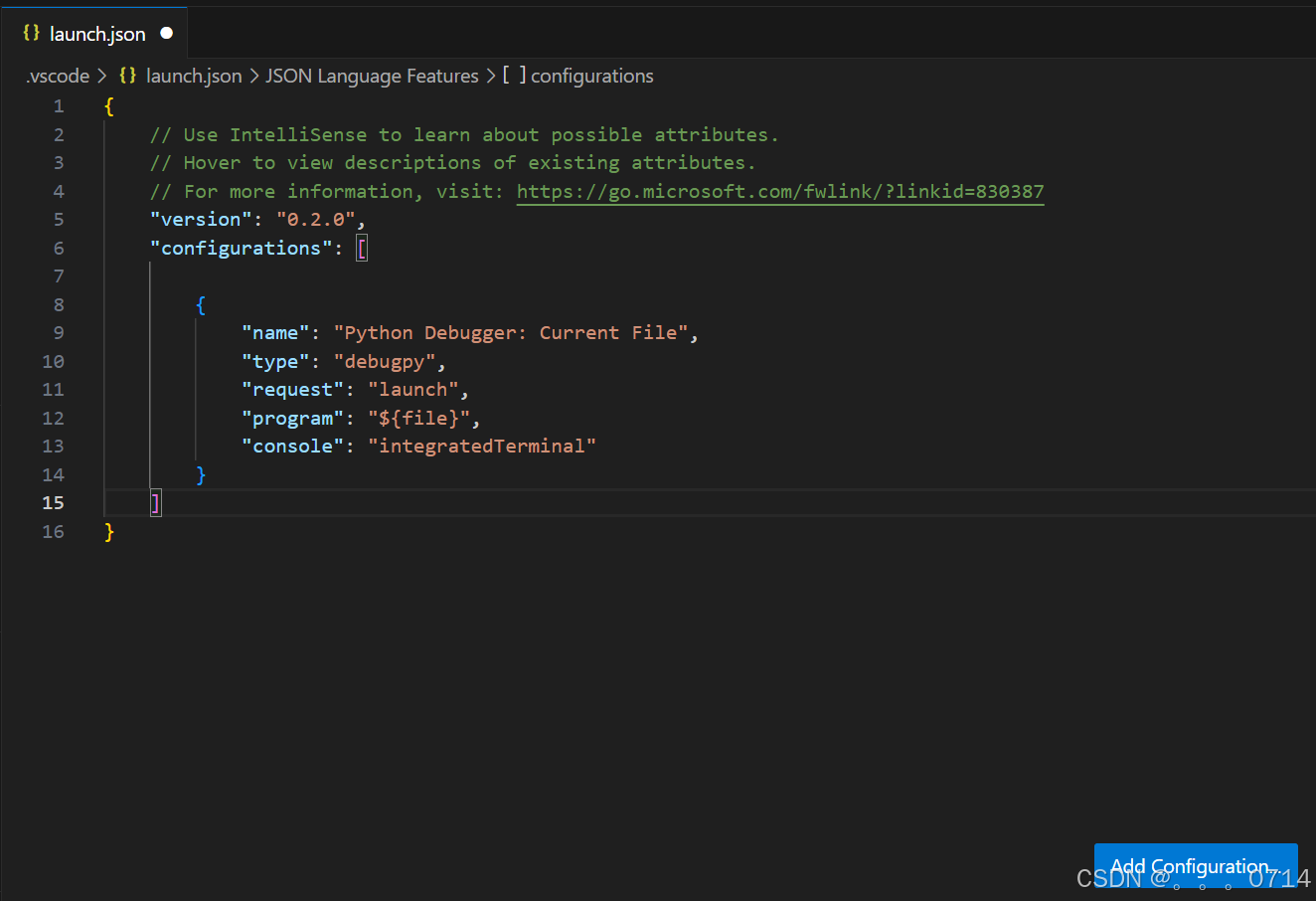
 - 可以直接编辑生成的launch.json文件,配置调试参数,比如添加config(Add Configuration)等。
- 可以直接编辑生成的launch.json文件,配置调试参数,比如添加config(Add Configuration)等。
Step3.设置断点
- 在代码行号旁边点击,可以添加一个红点,这就是断点(如果不能添加红点需要检查一下Python扩展是否已经正确安装)。当代码运行到这里时,它会停下来,这样你就可以检查变量的值、执行步骤等。
- 普通断点:在代码行号左侧点击,添加断点。
- 条件断点:在断点标记上右键,选择条件断点(conditional breakpoint)。
- VSCode 中常用的条件断点主要有三种类型:
- 表达式(Expression):输入一个 Python 表达式,每次触发断点时运行该表达式,当表达式的值为 True 时 VS Code 会暂停执行。例如:x == 10
- 触发计数(Hit Count):断点触发计数达到输入值时才会暂停运行。
- 记录日志(Log Message):触发该断点时在 Debug Console 中输出指定信息,实际上就是 logpoint。需要输入要输出的信息,如果要用到表达式,可以使用 {} 将表达式括起来。例如,每次记录变量 i 的值可以写 x={i}。
Step4.启动debug
- 点击VSCode侧边栏的“Run and Debug”(运行和调试),选择调试配置后,点击绿色箭头(开始调试)按钮,或者按F5键。
Step5.查看变量
- 当代码在断点处停下来时,你可以查看和修改变量的值。在“Run and
Debug”侧边栏的“Variables”(变量)部分,你可以看到当前作用域内的所有变量及其值。
Step6.单步执行代码
- 你可以使用顶部的debug面板的按钮来单步执行代码。这样,你可以逐行运行代码,并查看每行代码执行后的效果。
- debug面板各按钮功能介绍:

- 1 continue: 继续运行到下一个断点。
- 2 step over: 单步跳过,可以理解为运行当前行代码,不进入具体的函数或者方法。
- 3 step into: 单步进入。如果当前行代码存在函数调用,则进入该函数内部。如果当前行代码没有函数调用,则等价于step over。
- 4 step out: 单步退出函数,返回到调用该函数的上一层代码。
- 5 restart: 重新启动调试。
- 6 stop: 终止调试。
Step7.修复错误并重新运行
如果你找到了代码中的错误,可以修复它,然后重新运行debug来确保问题已经被解决。
通过遵循以上步骤,你可以使用VSCode的debug功能来更容易地找到和修复你Python代码中的错误。可以自己编写一个简单的python脚本,并尝试使用debug来更好的理解代码的运行逻辑。记住,debug是编程中非常重要的一部分,所以不要怕花时间在这上面。随着时间的推移,你会变得越来越擅长它!
2.命令行debug
很多时候我们要debug的不止是一个简单的python文件,而是很多参数,参数中不止会有简单的值还可能有错综复杂的文件关系,甚至debug一整个项目。这种情况下,直接使用命令行来发起debug会是一个更好的选择。
其实不太理解这个要用在什么场景啦
VScode设置
VScode支持通过remote的方法连接我们在命令行中发起的debug server。首先我们要配置一下debug的config。
还是点击VScode侧边栏的“Run and Debug”(运行和调试),单击"create a lauch.json file"
选择debugger时选择python debugger。选择debug config时选择remote attach就行,随后会让我们选择debug server的地址,因为我们是在本地debug,所以全都保持默认直接回车就可以了,也就是我们的server地址为 localhost:5678。
配置完以后会打开配置的json文件,但这不是重点,可以关掉。这时我们会看到run and debug界面有变化,出现了debug选项。
注意:已经有配置好的json文件
如果有已经配置好的debug json配置文件,则需要在原json上增加配置。可以通过Run and Debug卡片左上角的下拉菜单单击Add configuration,或者点击设置按钮打开配置文件,在配置文件的右下角也会有一个Add configuration。剩下的步骤就和前面一样选择Python debugger-Remote attach,剩下的全都保持默认直接回车就可以了,也就是我们的server地址为 localhost:5678。
debug命令行
现在vscode已经准备就绪,让我们来看看如何在命令行中发起debug。如果没有安装debugpy的话可以先通过pip install debugpy安装一下。
python -m debugpy --listen 5678 --wait-for-client ./myscript.py
-
./myscript.py可以替换为我们想要debug的python文件,后面可以和直接在命令行中启动python一样跟上输入的参数。记得要先在想要debug的python文件打好断点并保存。--wait-for-client参数会让我们的debug server在等客户端连入后才开始运行debug。在这就是要等到我们在run and debug界面启动debug。
注意: 在开发机上使用该debug方式运行的时候可能会报以下warning。此时,debug可能不能正常运行,需要按他提示的给python加上-Xfrozen_modules=off参数禁用冻结模块即可。
Debugger warning: It seems that frozen modules are being used, which may make the debugger miss breakpoints. Please pass -Xfrozen_modules=off to python to disable frozen modules.
python -m -Xfrozen_modules=off debugpy --listen 5678 --wait-for-client ./myscript.py
先在终端中发起debug server,然后再去vscode debug页面单击一下绿色箭头开启debug。
使用别名简化命令
由于python -m debugpy --listen 5678 --wait-for-client这个命令太长了,可以给这段常用的命令设置一个别名。
在linux系统中,可以对 ~/.bashrc 文件中添加以下命令
alias pyd='python -m debugpy --wait-for-client --listen 5678'
然后执行
source ~/.bashrc
这样之后使用 pyd 命令(你可以自己命名) 替代 python 就能在命令行中起debug了,之前的debug命令就变成了
pyd ./myscript.py
实战
通过Leetcode 383

class Solution(object):
def canConstruct(self, ransomNote, magazine):
"""
:type ransomNote: str
:type magazine: str
:rtype: bool
"""
# 用于存储 magazine 中每个字符的出现次数
char_count = {}
# 遍历 magazine 中的每个字符
for char in magazine:
if char in char_count:
char_count[char] += 1
else:
char_count[char] = 1
# 遍历 ransomNote 中的每个字符
for char in ransomNote:
if char not in char_count or char_count[char] == 0:
return False
char_count[char] -= 1
return True
提交通过截图:
python调用InternLM API并debug
获取API Key
书生·浦语的API文档
我们可以使用openai python sdk来调用InternLM api。注意在配置api key时,更推荐使用环境变量来配置以避免token泄露。
- 可以在终端中临时将token加入变量,此时该环境变量只在当前终端内有效。
export api_key="填入你的api token"
python internlm_test.py
- 若是想永久加入环境变量,可以对 ~/.bashrc 文件中添加以下命令。
export api_key="填入你的api token"
- 保存后记得
source ~/.bashrc。
debug单个文件
下面是一段调用书生浦语API实现将非结构化文本转化成结构化json的例子,其中有一个小bug会导致报错。为了便于debug所以将api_key明文写在代码中,这是一种极其不可取的行为!
from openai import OpenAI
import json
def internlm_gen(prompt,client):
'''
LLM生成函数
Param prompt: prompt string
Param client: OpenAI client
'''
response = client.chat.completions.create(
model="internlm2.5-latest",
messages=[
{"role": "user", "content": prompt},
],
stream=False
)
return response.choices[0].message.content
api_key = ''
client = OpenAI(base_url="https://internlm-chat.intern-ai.org.cn/puyu/api/v1/",api_key=api_key)
content = """
书生浦语InternLM2.5是上海人工智能实验室于2024年7月推出的新一代大语言模型,提供1.8B、7B和20B三种参数版本,以适应不同需求。
该模型在复杂场景下的推理能力得到全面增强,支持1M超长上下文,能自主进行互联网搜索并整合信息。
"""
prompt = f"""
请帮我从以下``内的这段模型介绍文字中提取关于该模型的信息,要求包含模型名字、开发机构、提供参数版本、上下文长度四个内容,以json格式返回。
`{content}`
"""
res = internlm_gen(prompt,client)
res_json = json.loads(res)
print(res_json)
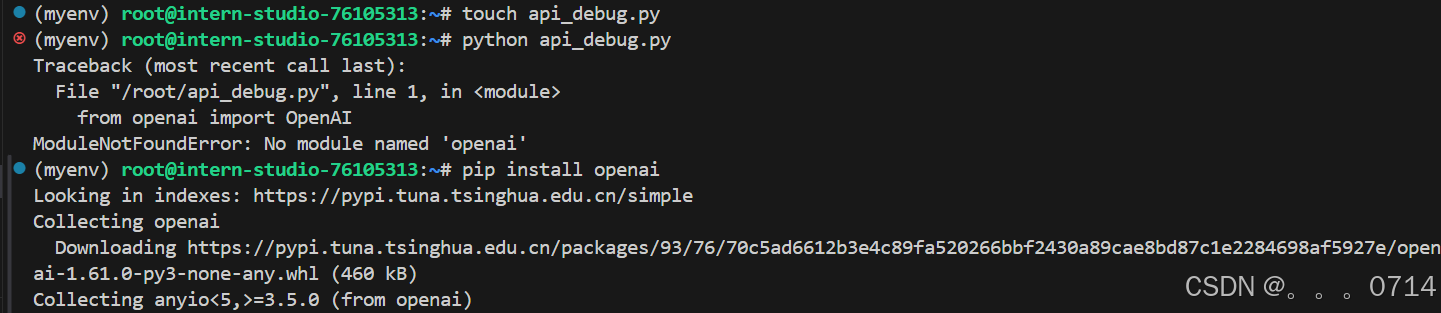
(1)首次运行报错,未安装openai库:
(2)再次运行报错,定位在res = internlm_gen(prompt,client):
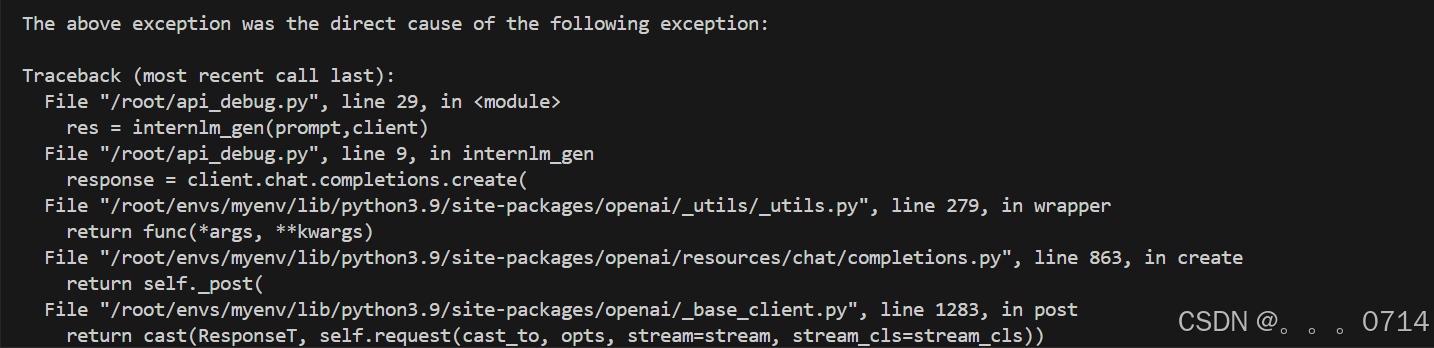
(3)python debug安装扩展并配置调试
(4)设置断点,启动debug,查看变量
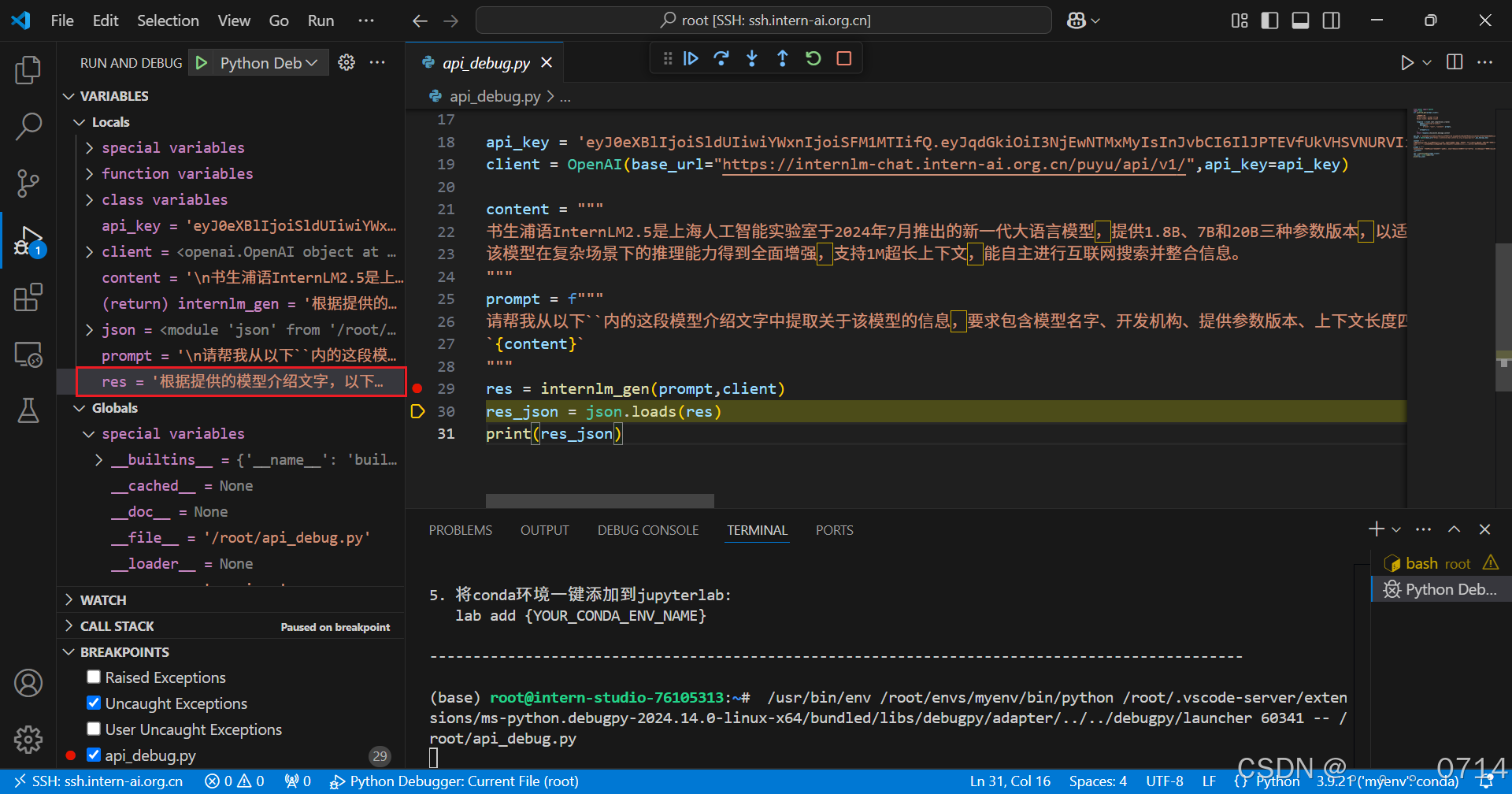
res变量的值如下:
'根据提供的模型介绍文字,以下是提取的关于该模型的信息,以JSON格式返回:\n\n```json\n{\n "模型名字": "书生浦语InternLM2.5",\n "开发机构": "上海人工智能实验室",\n "提供参数版本": ["1.8B", "7B", "20B"],\n "上下文长度": "1M"\n}\n```\n\n这个JSON对象包含了模型名字、开发机构、提供参数版本以及上下文长度这四个关键信息。希望这对您有帮助!如果有其他问题或需要进一步的信息,请随时告诉我。'
错误定位:res 变量中的内容并不是一个纯粹的 JSON 字符串。它包含了一些额外的文本描述,如 “根据提供的模型介绍文字,以下是提取的关于该模型的信息,以 JSON 格式返回:” 以及前后的注释信息和格式化标记(如 json 和 ),而 json.loads() 方法只能处理标准的 JSON 格式字符串,所以遇到这些非 JSON 内容时就会抛出解析错误。
(5)修复错误并重新运行
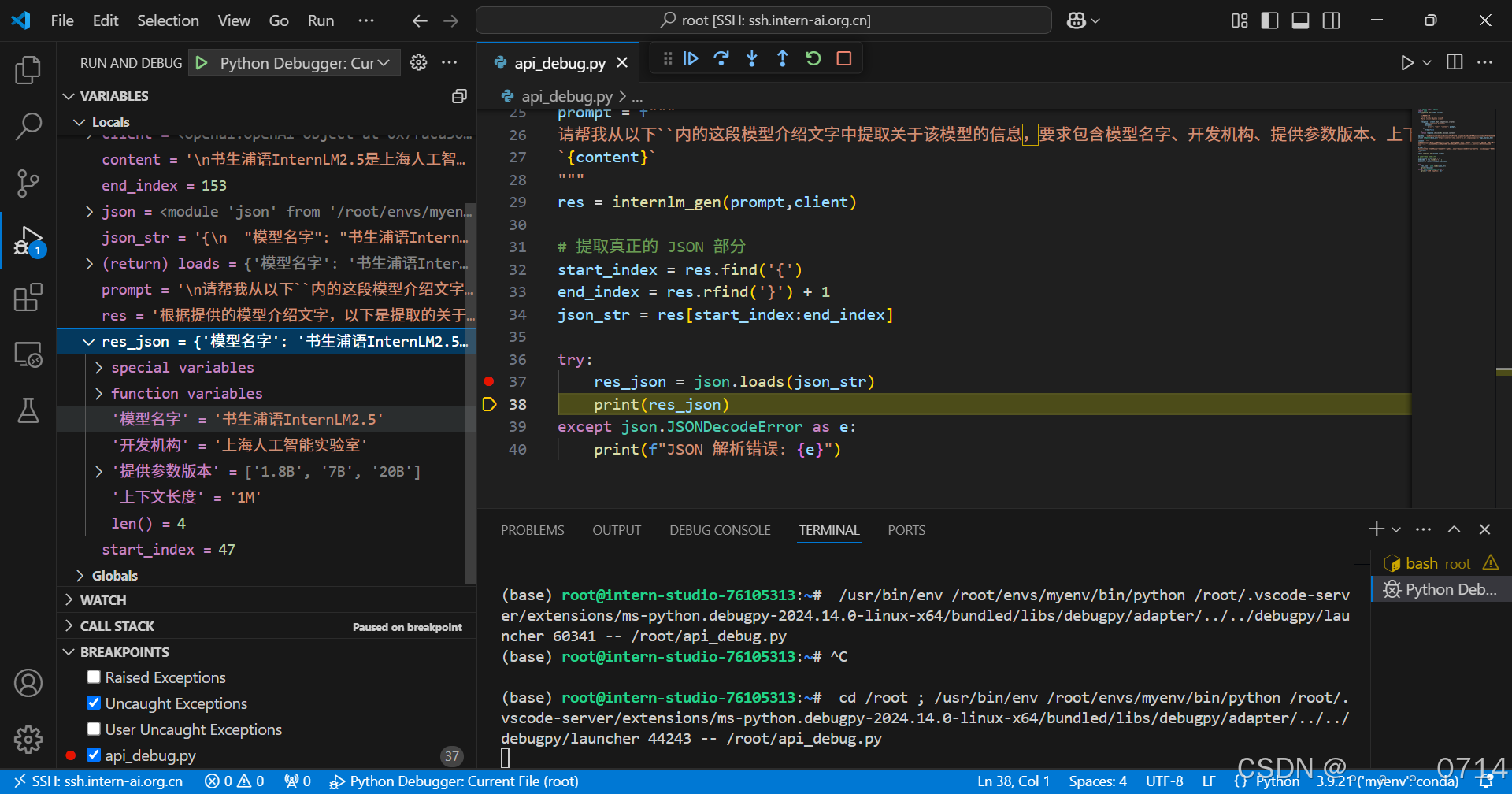
pip安装到指定目录
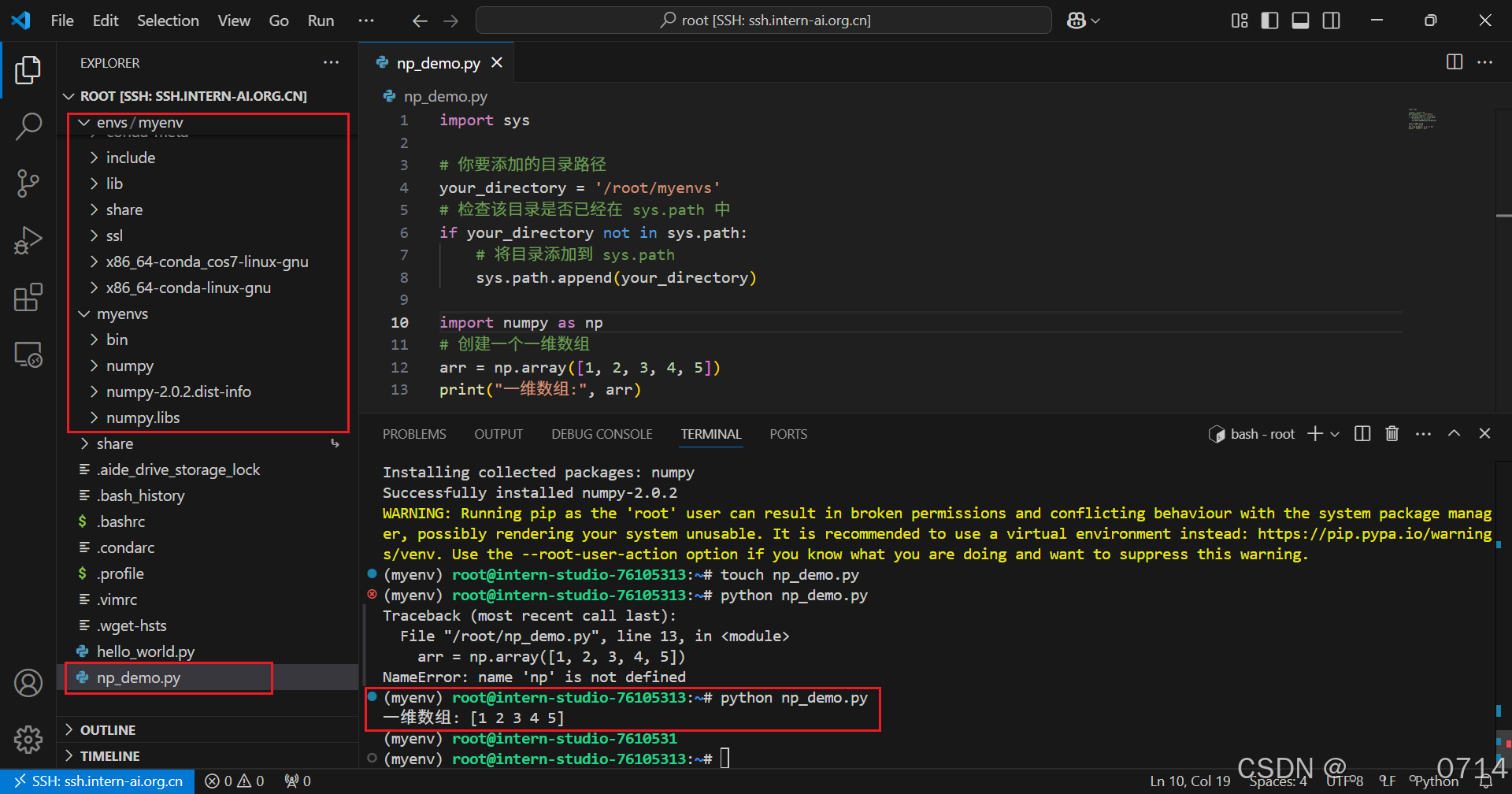
使用VScode连接开发机后使用pip install -t命令安装一个numpy到开发机/root/myenvs目录下,并成功在一个新建的python文件中引用。
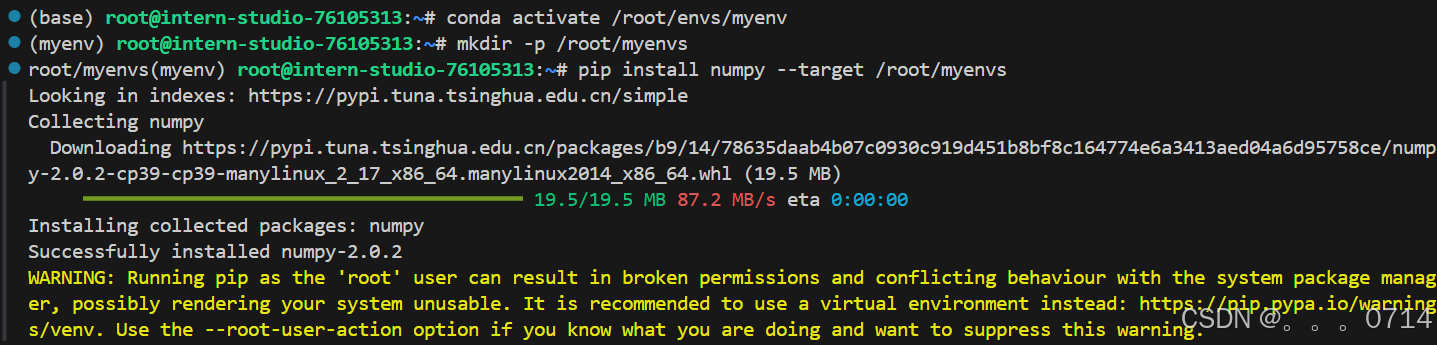
创建新的文件np_demo.py并运行:

第3关 Git基础知识
Git相关
Git是一个开源的分布式版本控制系统,可以有效、高速的处理从很小到非常大的项目版本管理。 Git的诞生离不开Linux社区的努力,它是开源的,而且是免费的。它支持多种操作系统,包括 Linux、Unix、Mac OS X、Windows。
Git简易入门四部曲
在Git的日常使用中,下面四步曲是常用的流程,尤其是在团队协作环境中。
-
添(Add)
- 命令:
git add <文件名>或git add . - 作用:将修改过的文件添加到本地暂存区(Staging Area)。这一步是准备阶段,你可以选择性地添加文件,决定哪些修改应该被包括在即将进行的提交中。
- 命令:
-
提(Commit)
- 命令:
git commit -m '描述信息' - 作用:将暂存区中的更改提交到本地仓库。这一步是将你的更改正式记录下来,每次提交都应附带一个清晰的描述信息,说明这次提交的目的或所解决的问题。
- 命令:
-
拉(Pull)
- 命令:
git pull - 作用:从远程仓库拉取最新的内容到本地仓库,并自动尝试合并到当前分支。这一步是同步的重要环节,确保你的工作基于最新的项目状态进行。在多人协作中,定期拉取可以避免将来的合并冲突。
- 命令:
-
推(Push)
- 命令:
git push - 作用:将本地仓库的更改推送到远程仓库。这一步是共享你的工作成果,让团队成员看到你的贡献。
- 命令:
帮助团队成员有效地管理和同步代码,避免工作冲突,确保项目的顺利进行。正确地使用这些命令可以极大地提高开发效率和协作质量。
Git常用指令
| 指令 | 描述 |
|---|---|
git config | 配置用户信息和偏好设置 |
git init | 初始化一个新的 Git 仓库 |
git clone | 克隆一个远程仓库到本地 |
git status | 查看仓库当前的状态,显示有变更的文件 |
git add | 将文件更改添加到暂存区 |
git commit | 提交暂存区到仓库区 |
git branch | 列出、创建或删除分支 |
git checkout | 切换分支或恢复工作树文件 |
git merge | 合并两个或更多的开发历史 |
git pull | 从另一仓库获取并合并本地的版本 |
git push | 更新远程引用和相关的对象 |
git remote | 管理跟踪远程仓库的命令 |
git fetch | 从远程仓库获取数据到本地仓库,但不自动合并 |
git stash | 暂存当前工作目录的修改,以便可以切换分支 |
git cherry-pick | 选择一个提交,将其作为新的提交引入 |
git rebase | 将提交从一个分支移动到另一个分支 |
git reset | 重设当前 HEAD 到指定状态,可选修改工作区和暂存区 |
git revert | 通过创建一个新的提交来撤销之前的提交 |
git mv | 移动或重命名一个文件、目录或符号链接,并自动更新索引 |
git rm | 从工作区和索引中删除文件 |
实战
提交自我介绍
将本项目直接fork到自己的账号下,这样就可以直接在自己的账号下进行修改和提交。注意取消勾选仅克隆当前分支。配置git并克隆项目到InternStudio本地。
# 修改为自己fork的仓库,改为上图中你的https仓库的git地址,将random-zhou改为自己的用户名
git clone https://github.com/random-zhou/Tutorial.git
#git clone git@github.com:random-zhou/Tutorial.git
#git clone https://github.com/InternLM/Tutorial.git
cd Tutorial/
git branch -a
git checkout -b class origin/class
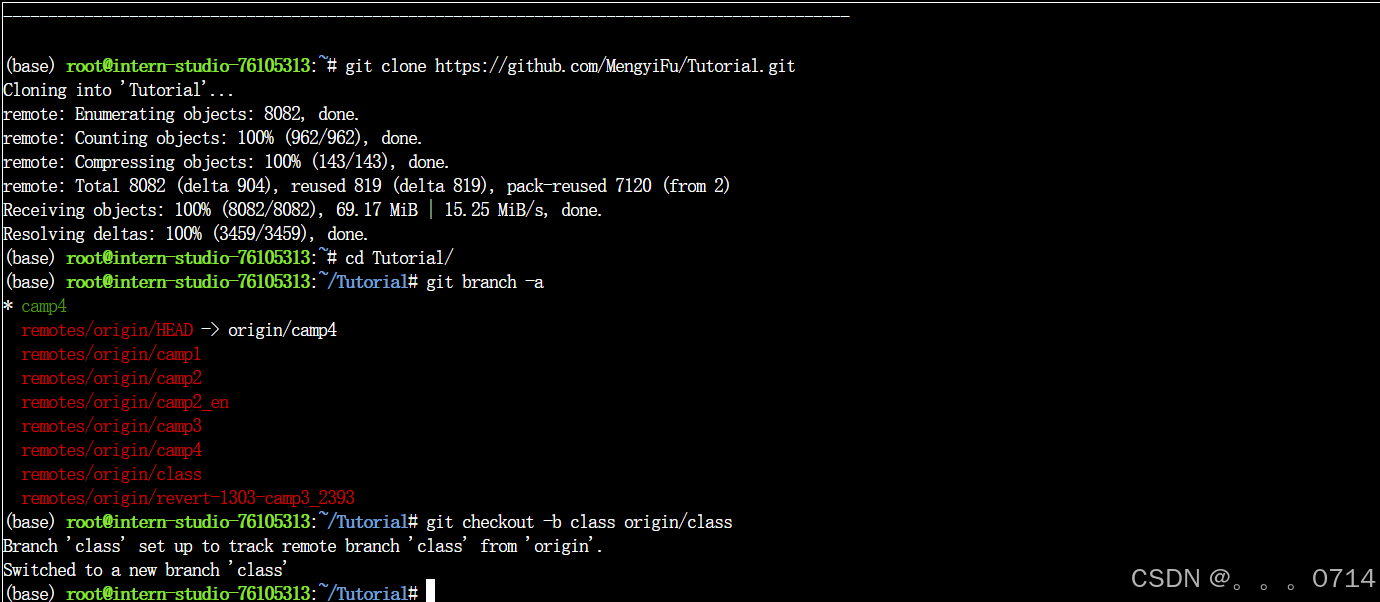
创建分支。
git checkout -b class_036 # 自定义一个新的分支
#git checkout -b class_id 分支名字改为你的uid分支名称
创建自己的介绍文件。
【大家可以叫我】:InternLM
【坐标】:上海
【专业/职业】:小助手
【兴趣爱好】:乒乓球
【项目技能】:cv、nlp
【组队情况】:未组队,快来一起!
【本课程学习基础】:CV、NLP、LLM
【本期活动目标】:一起学习,快乐暑假,闯关达人!
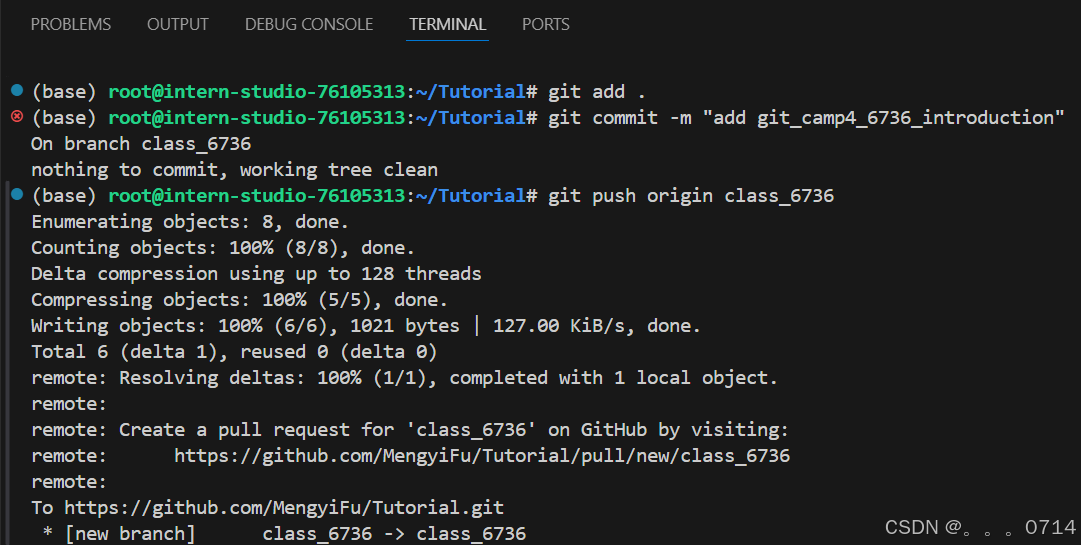
提交更改分支,推送分支到远程仓库。
git add .
git commit -m "add git_camp4_036_introduction" # 提交信息记录,这里需要修改为自己的uid
git push origin class_036
#注意,这里要改为你自己的分支名称
#大家提交使用英文,避免同步错误
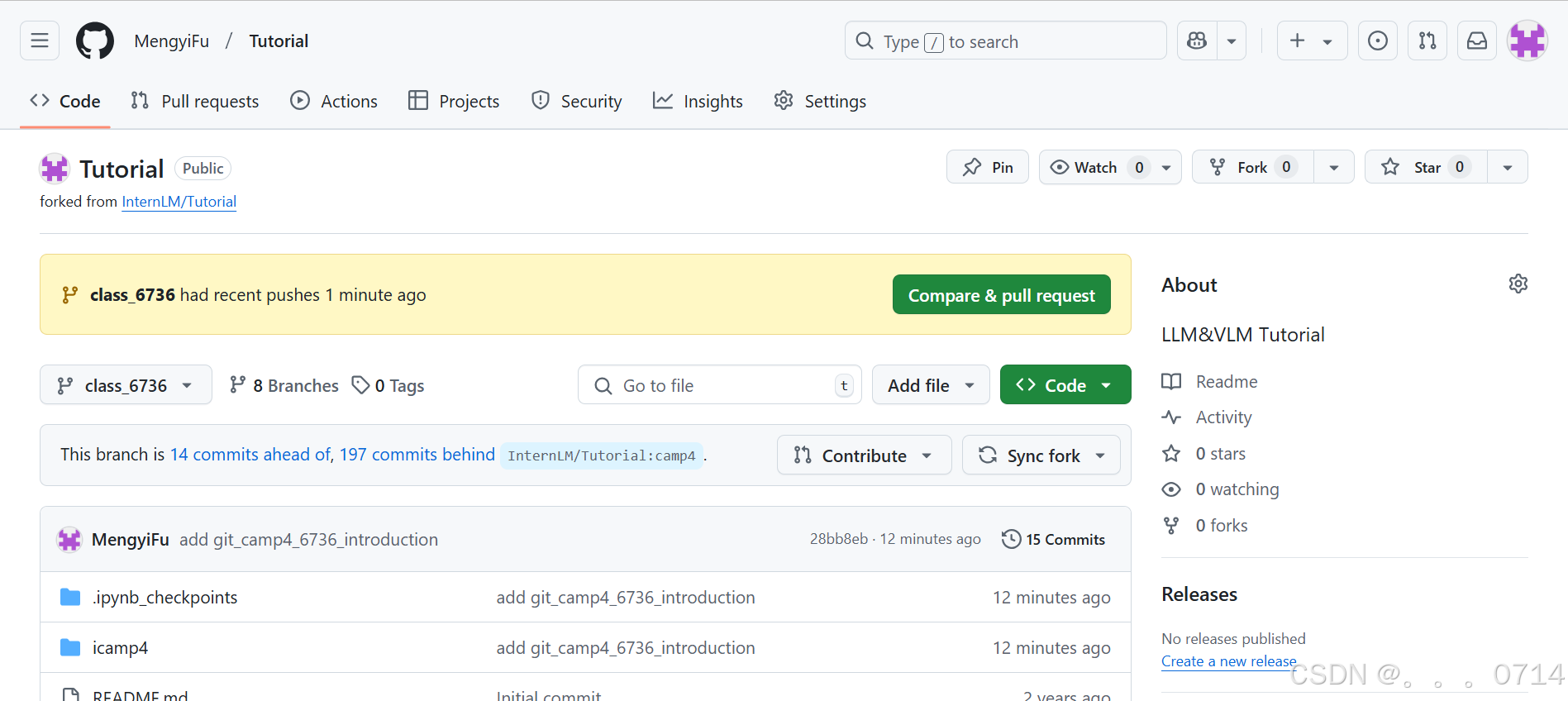
检查提交内容并创建PR:点击右上角Compare & pull request,在“Add a title中”输入 “add git_< id >_introduction”,然后点击“Create pull request”。
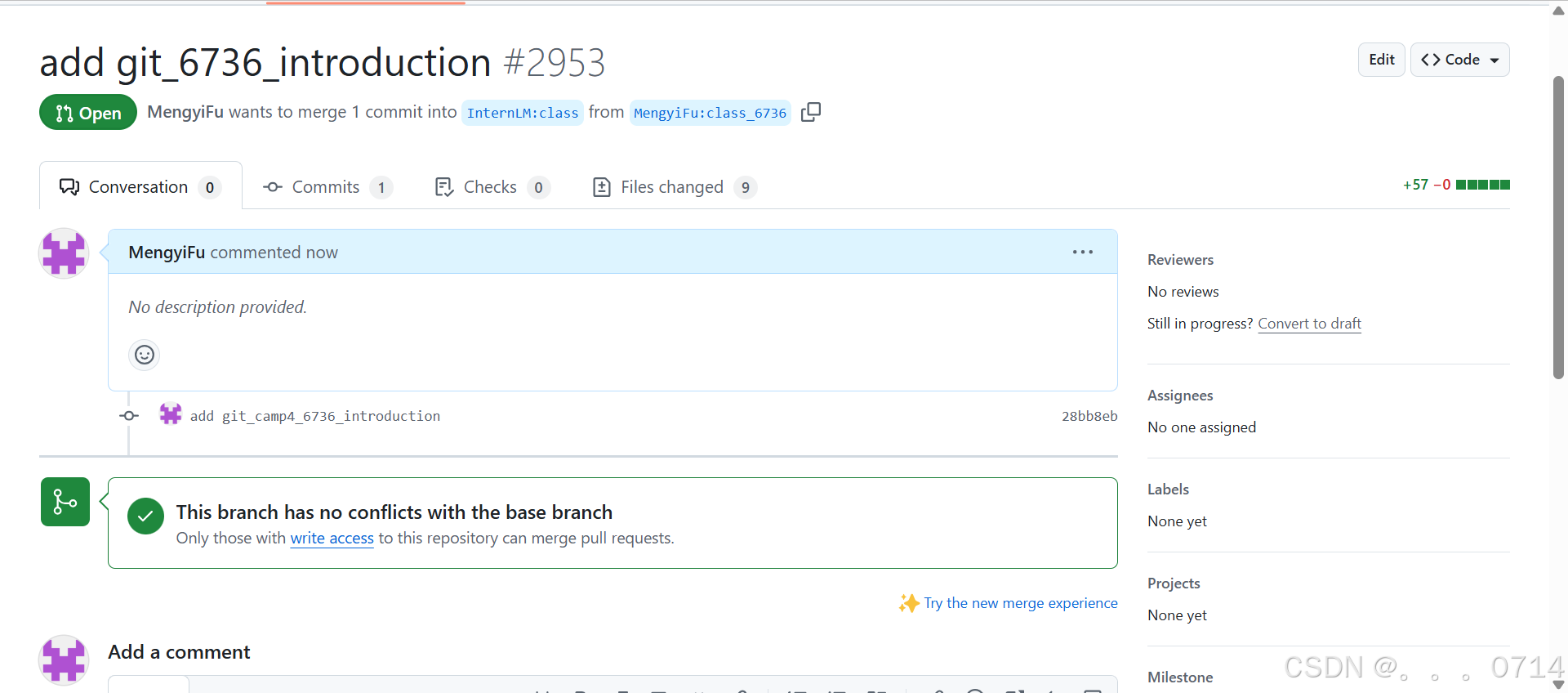
第4关 玩转HF/魔搭/魔乐社区
Hugging Face平台
Hugging Face 最初专注于开发聊天机器人服务。尽管他们的聊天机器人项目并未取得预期的成功,但他们在GitHub上开源的Transformers库却意外地在机器学习领域引起了巨大轰动。如今,Hugging Face已经发展成为一个拥有超过100,000个预训练模型和10,000个数据集的平台,被誉为机器学习界的GitHub。
HF的Transformers库,作为HF最核心的项目,它可以:
- 直接使用预训练模型进行推理;
- 提供了大量预训练模型可供使用;
- 使用预训练模型进行迁移学习。
模型详情页
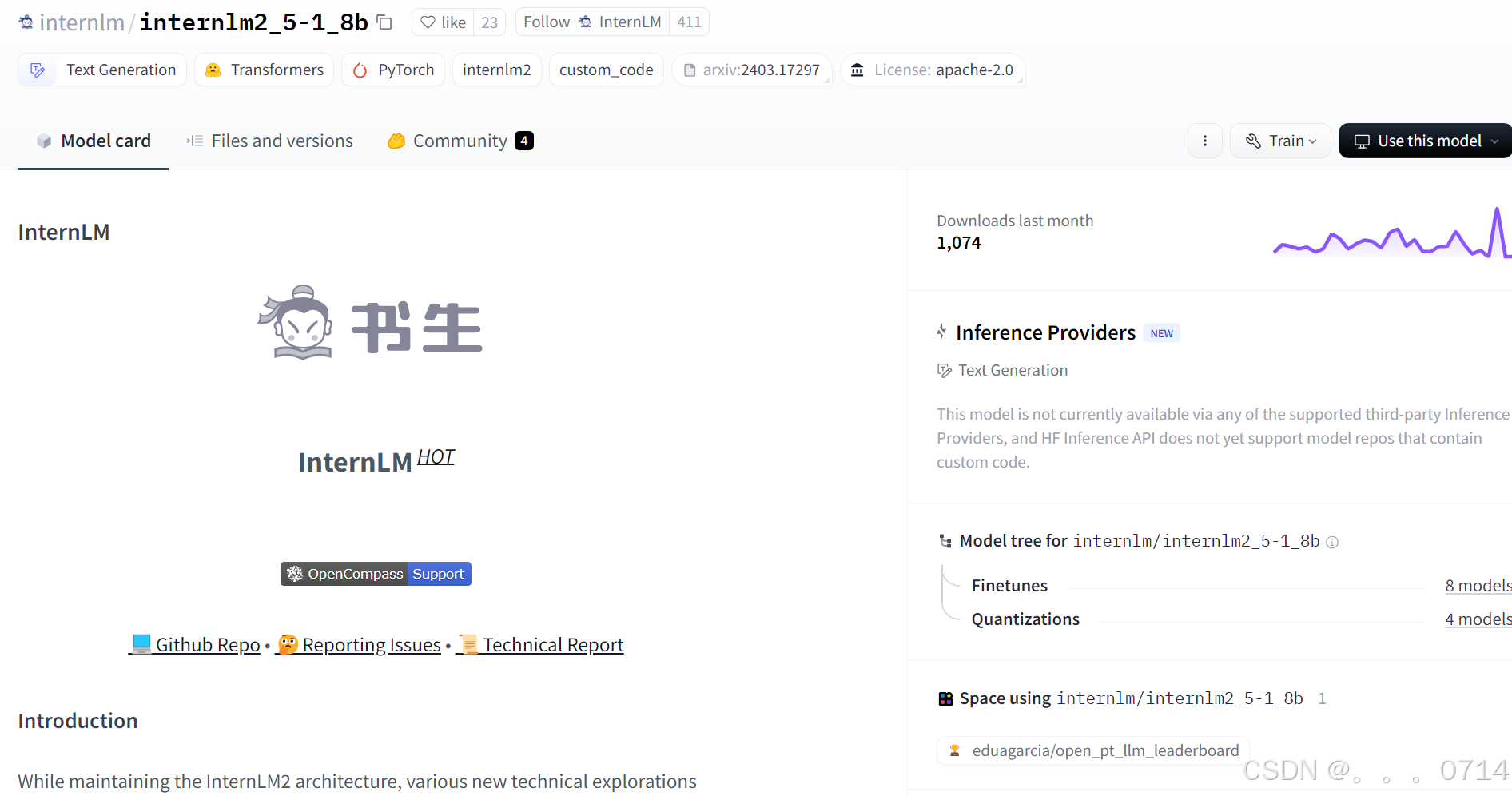
- Model Card:类似于GitHub的README.md文件,都是展示模型的overview。
- Files and Versions:包含模型文件以及模型的版本管理。
- Use this model:提供我们使用模型的示例代码,当然一般在Model card下方也会提到各种该模型的使用方法。
实战
使用GitHub CodeSpace下载模型
Github CodeSpace是Github推出的线上代码平台,提供了一系列templates,我们这里选择Jupyter Notebook进行创建环境。创建好环境后,可以进入网页版VSCode的界面,这就是CodeSpace提供给我们的在线编程环境。
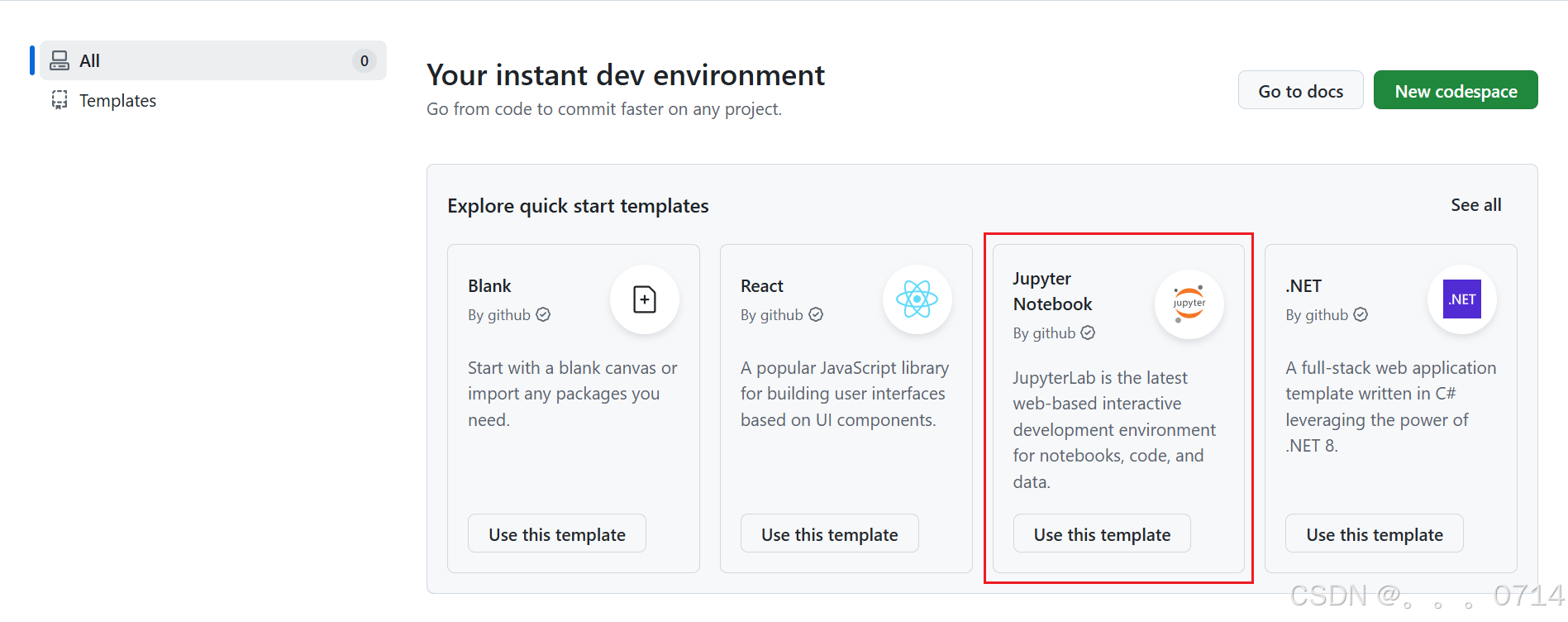
在界面下方的终端安装以下依赖,便于模型运行。
# 安装transformers
pip install transformers==4.38
pip install sentencepiece==0.1.99
pip install einops==0.8.0
pip install protobuf==5.27.2
pip install accelerate==0.33.0
以下载模型的配置文件为例,先新建一个hf_download_json.py 文件,文件内容如下:
import os
from huggingface_hub import hf_hub_download
# 指定模型标识符
repo_id = "internlm/internlm2_5-7b"
# 指定要下载的文件列表
files_to_download = [
{"filename": "config.json"},
{"filename": "model.safetensors.index.json"}
]
# 创建一个目录来存放下载的文件
local_dir = f"{repo_id.split('/')[1]}"
os.makedirs(local_dir, exist_ok=True)
# 遍历文件列表并下载每个文件
for file_info in files_to_download:
file_path = hf_hub_download(
repo_id=repo_id,
filename=file_info["filename"],
local_dir=local_dir
)
print(f"{file_info['filename']} file downloaded to: {file_path}")
运行该文件(注意文件目录请在该文件所在目录下运行该文件),可以看到,已经从Hugging Face上下载了相应配置文件。
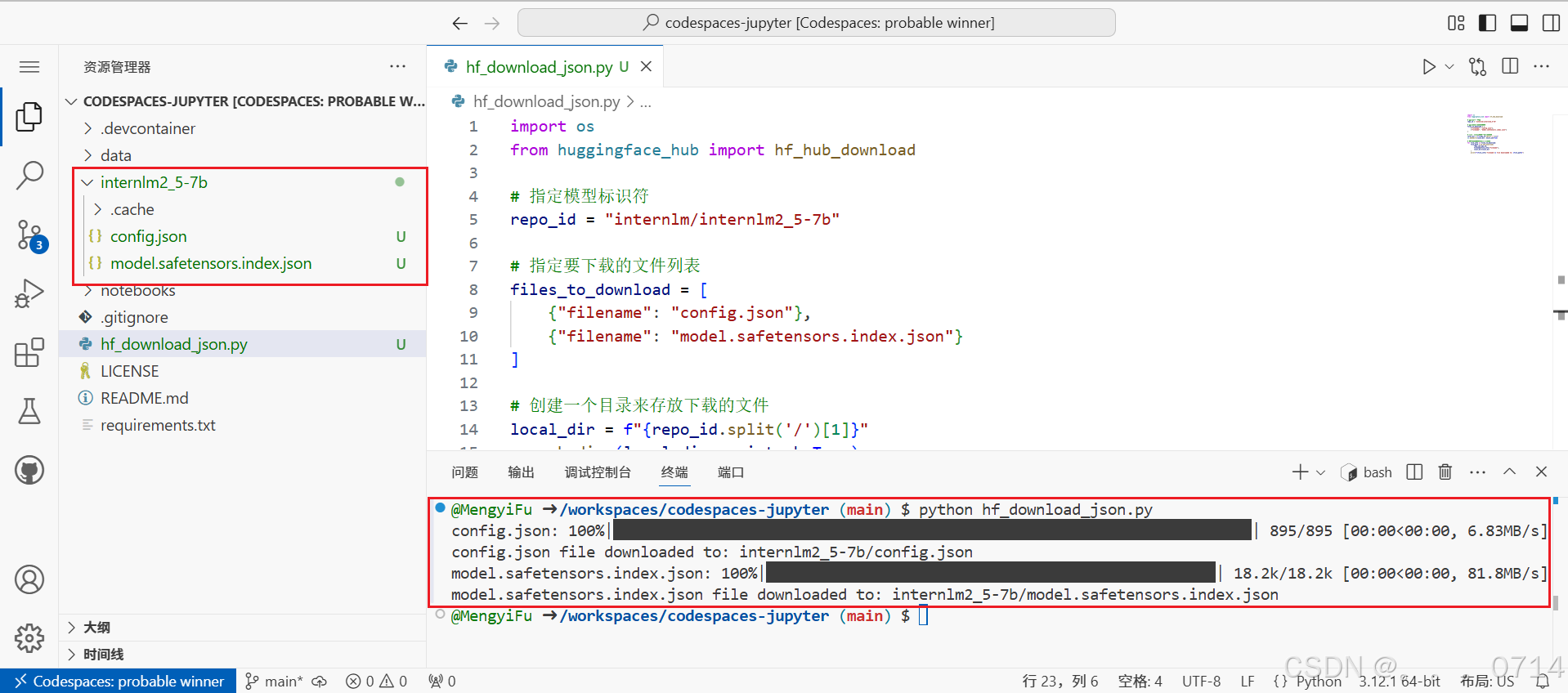
创建一个python文件用于下载internlm2_5-1_8B模型并运行,下载速度跟网速和模型参数量大小相关联。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("internlm/internlm2_5-1_8b", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("internlm/internlm2_5-1_8b", torch_dtype=torch.float16, trust_remote_code=True)
model = model.eval()
inputs = tokenizer(["A beautiful flower"], return_tensors="pt")
gen_kwargs = {
"max_length": 128,
"top_p": 0.8,
"temperature": 0.8,
"do_sample": True,
"repetition_penalty": 1.0
}
# 以下内容可选,如果解除注释等待一段时间后可以看到模型输出
output = model.generate(**inputs, **gen_kwargs)
output = tokenizer.decode(output[0].tolist(), skip_special_tokens=True)
print(output)
这里以“A beautiful flower”开头,模型对其进行“续写”。
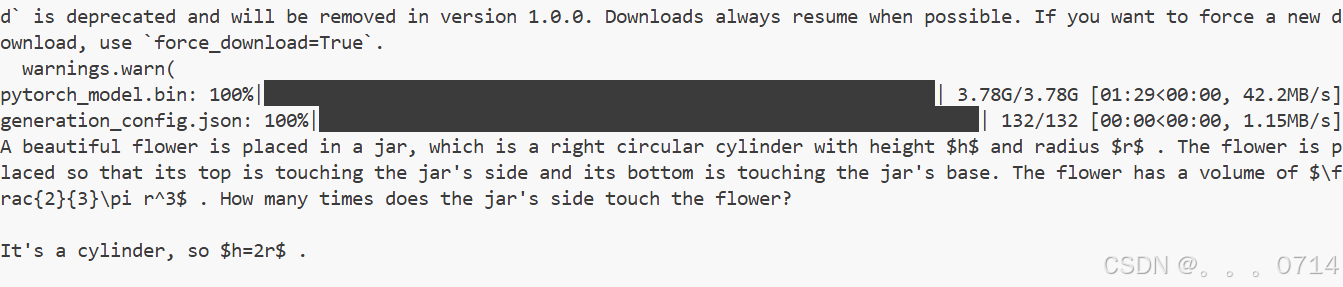
使用Hugging Face Spaces应用部署
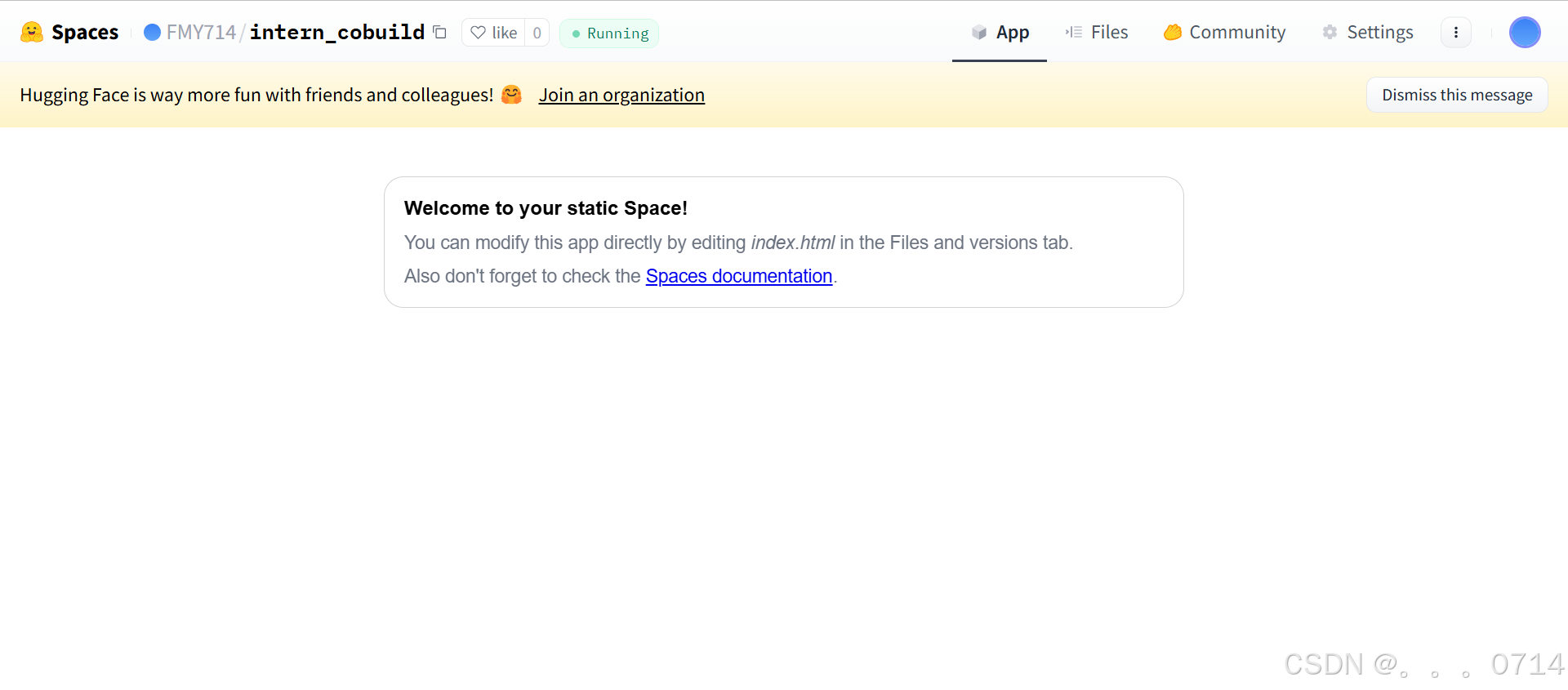
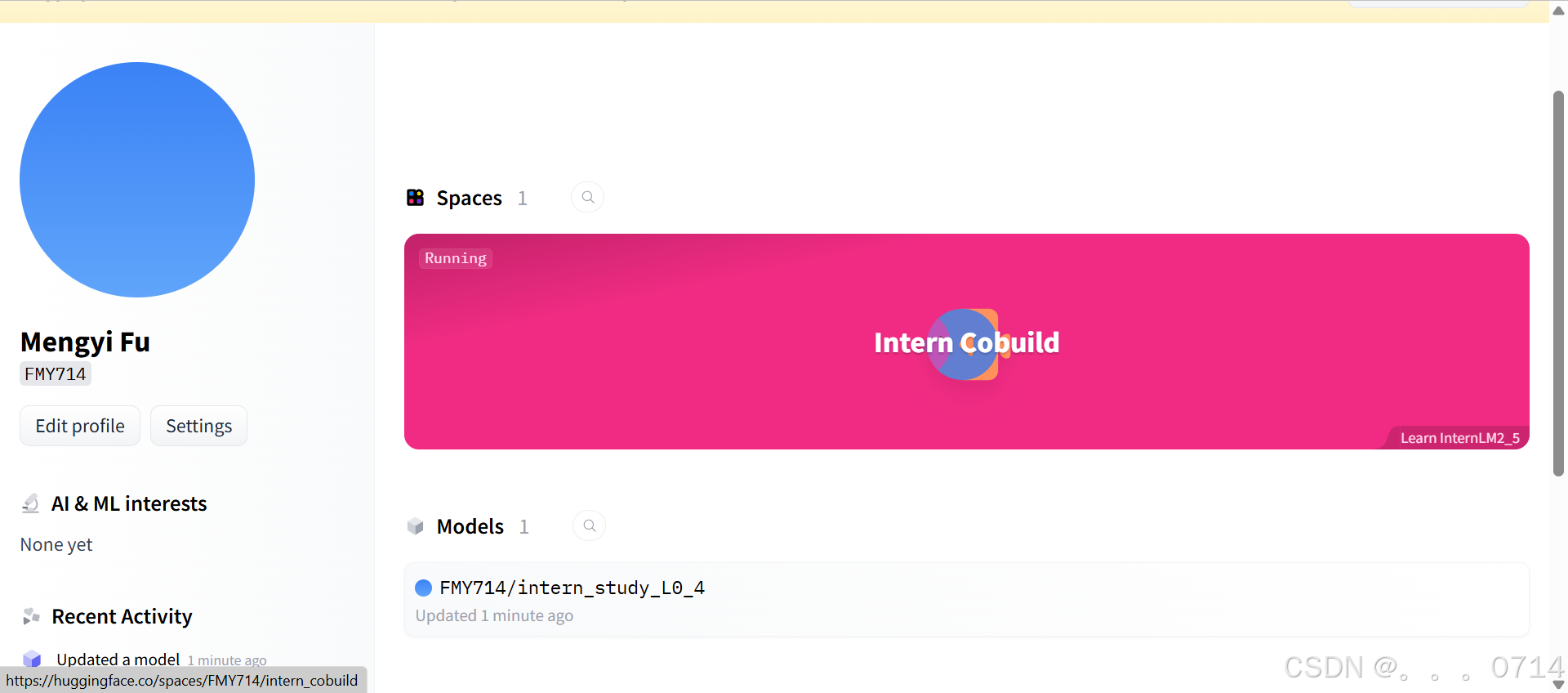
Hugging Face Spaces 是一个允许我们轻松地托管、分享和发现基于机器学习模型的应用的平台。Spaces 使得开发者可以快速将我们的模型部署为可交互的 web 应用,且无需担心后端基础设施或部署的复杂性。 首先访问以下链接,进入Spaces。在右上角点击Create new Space进行创建。
在创建页面中,输入项目名为intern_cobuild,并选择Static应用进行创建。创建成功后会自动跳转到一个默认的HTML页面。
创建好项目后,回到我们的CodeSpace,接着clone项目。
cd /workspaces/codespaces-jupyter
# 请将<your_username>替换你自己的username
git clone https://huggingface.co/spaces/<your_username>/intern_cobuild
cd /workspaces/codespaces-jupyter/intern_cobuild
找到该目录文件夹下的index.html文件,修改我们的html代码,代码内容如下:
<!doctype html>
<html>
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width" />
<title>My static Space</title>
<style>
html, body {
margin: 0;
padding: 0;
height: 100%;
}
body {
display: flex;
justify-content: center;
align-items: center;
}
iframe {
width: 430px;
height: 932px;
border: none;
}
</style>
</head>
<body>
<iframe src="https://colearn.intern-ai.org.cn/cobuild" title="description"></iframe>
</body>
</html>
保存后就可以push到远程仓库上了,它会自动更新页面。
git add .
git commit -m "update: colearn page"
git push
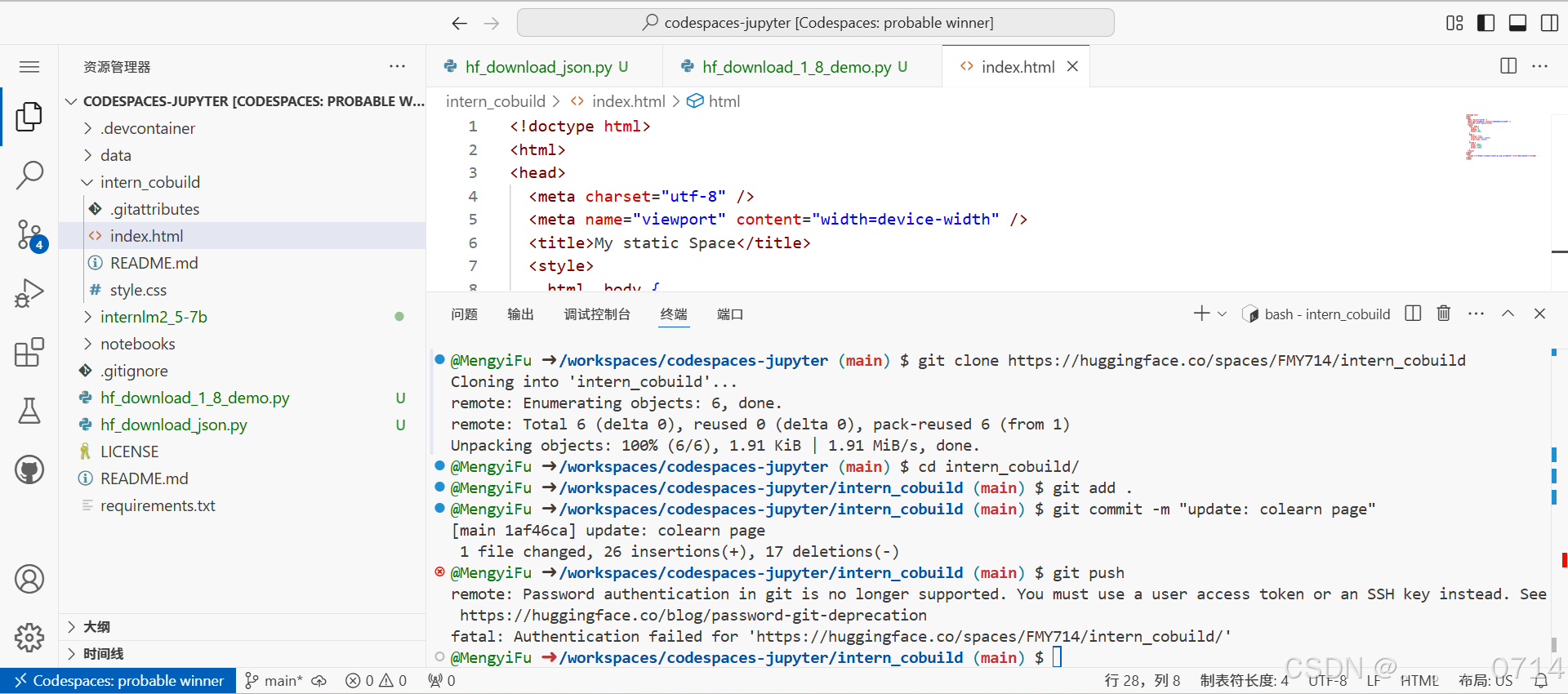
出现以下报错,需要使用用户的Access Token再次设置项目的验证。
remote: Password authentication in git is no longer supported. You must use a user access token or an SSH key instead. See https://huggingface.co/blog/password-git-deprecation
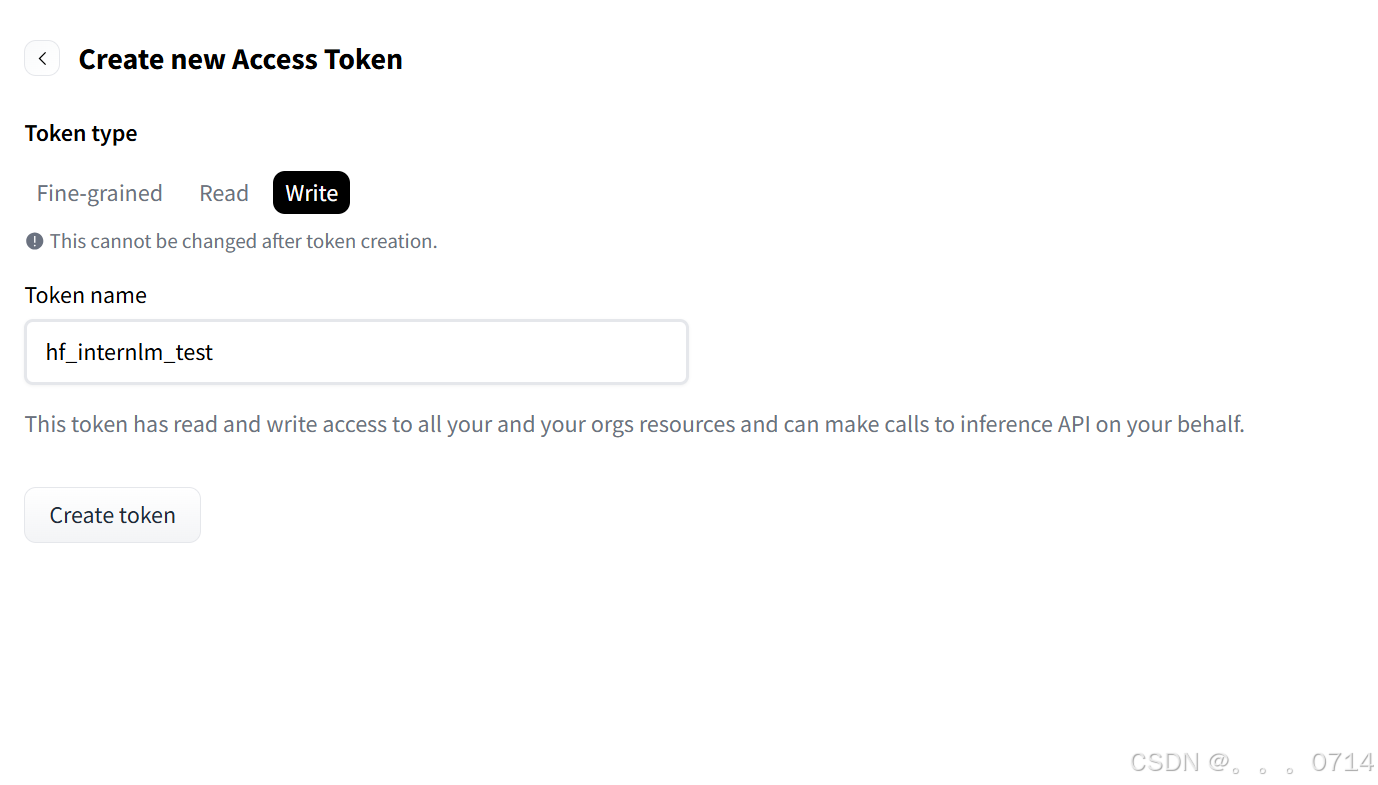
点击Settings进入设置界面,点击Access Tokens进入页面,点击Create new token创建一个类型为“Write”的token,并请复制好token后要存储在合适的地方。
再次尝试git push更新页面。
git remote set-url origin https://<user_name>:<token>@huggingface.co/<repo_path>
git push
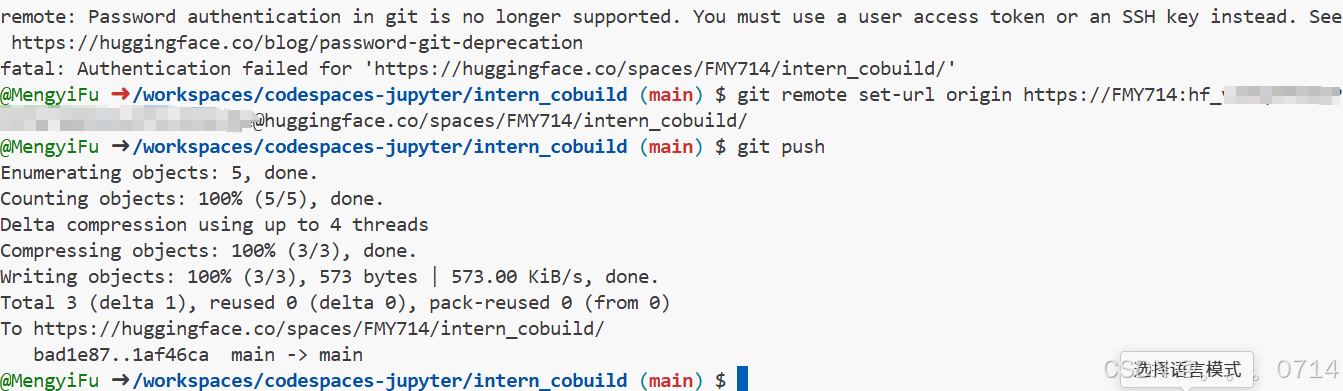
进入Space界面,就可以看到更新后的实战营页面。
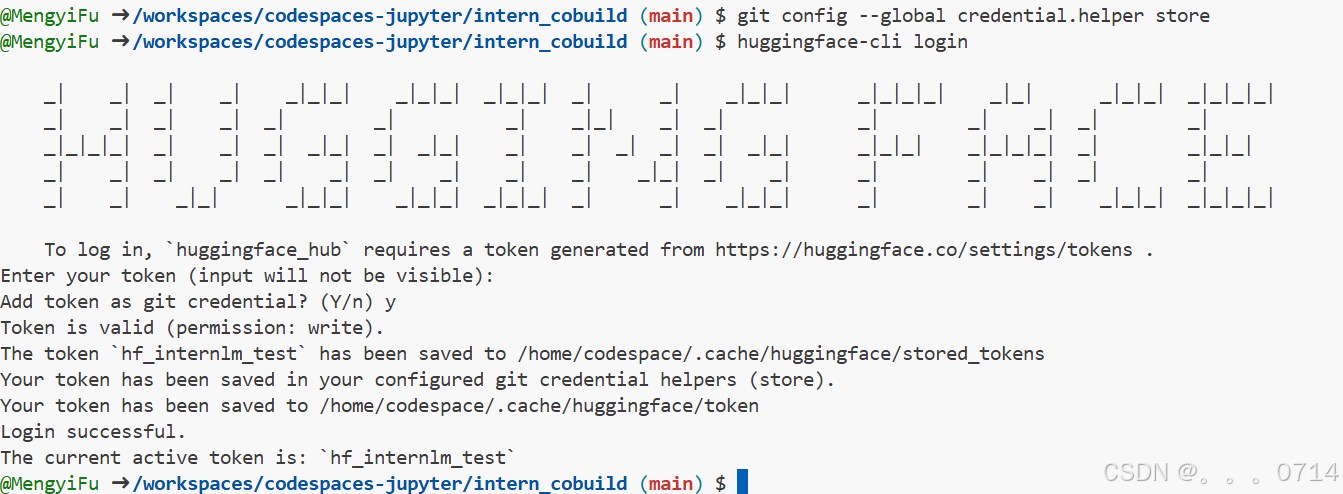
使用CLI上传模型
通过CLI上传 Hugging Face同样是跟Git相关联,通常大模型的模型文件都比较大,因此我们需要安装git lfs,对大文件系统支持。
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
# sudo apt-get install git-lfs # CodeSpace里面可能会有aptkey冲突且没有足够权限
git lfs install # 直接在git环境下配置git LFS
# 使用以下命令进行登录,这时需要输入刚刚的token
pip install huggingface_hub
git config --global credential.helper store
huggingface-cli login
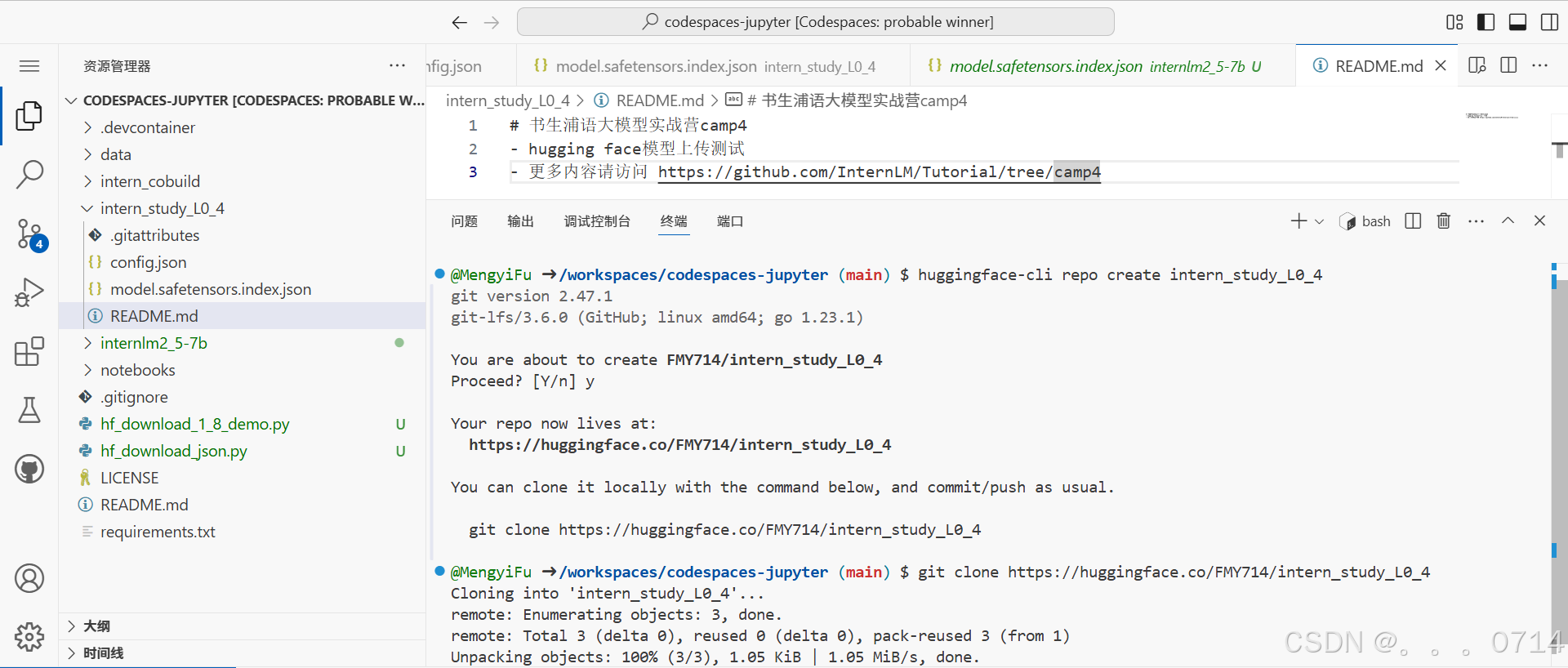
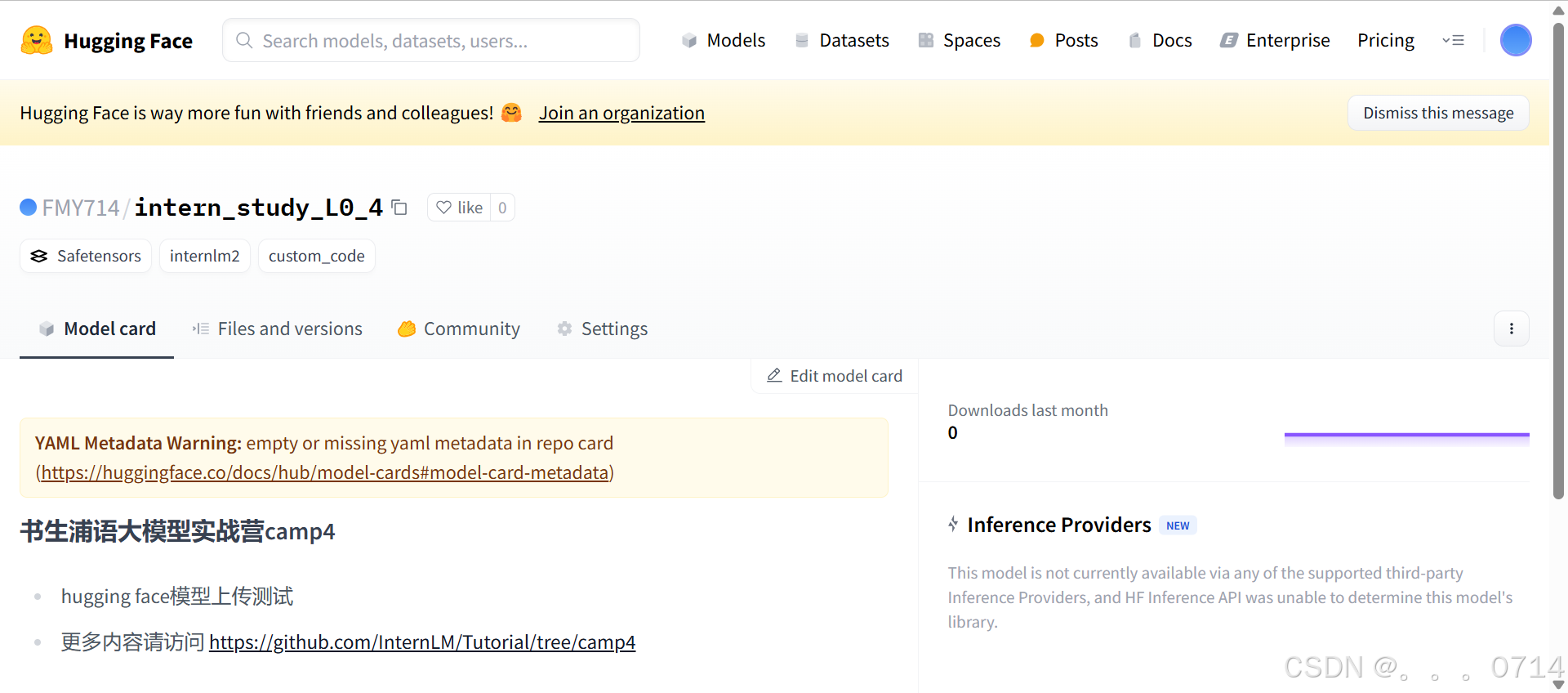
创建项目并克隆到本地,刷新文件目录可以看到克隆好的intern_study_L0_4文件夹。
cd /workspaces/codespaces-jupyter
#intern_study_L0_4就是model_name
huggingface-cli repo create intern_study_L0_4
# 克隆到本地 your_huggingface_name 注意替换成你自己的
git clone https://huggingface.co/{your_huggingface_name}/intern_study_L0_4
我们可以把训练好的模型保存进里面,这里考虑到网速问题,只上传我们刚刚下载好的config.json,把它复制粘贴进这个文件夹里面,还可以写一个README.md文件,比如可以粘贴以下内容:
# 书生浦语大模型实战营camp4
- hugging face模型上传测试
- 更多内容请访问 https://github.com/InternLM/Tutorial/tree/camp4
现在可以用git提交到远程仓库。
cd intern_study_L0_4
git add .
git commit -m "add:intern_study_L0_4"
git push
现在可以在Hugging Face的个人profile里面看到这个model。
var code = “ff022a4c-8f90-4361-aef2-6000bf527387”

 浙公网安备 33010602011771号
浙公网安备 33010602011771号