第四期书生大模型实战营【基础岛】—— XTuner 微调个人小助手认知
任务描述
- 使用 XTuner 微调 InternLM2-Chat-7B 实现自己的小助手认知,记录复现过程并截图。
- 将自我认知的模型上传到 HuggingFace/Modelscope/魔乐平台,模型名称中包含internlm关键词 ,并将应用部署到 HuggingFace/Modelscope/魔乐平台。
- 参与社区共建,获取浦语 api 创建自己的数据用于微调。
闯关任务
环境配置与数据准备
修改提供的数据

此时/root/finetune/文件夹的结构如下:
finetune
├── data
└── assistant_Tuner.jsonl
└── assistant_Tuner_change.jsonl
与教程显示的结构不大一样,不清楚缺少xtuner是否对之后有影响。
change_script.py内容如下:
import json
import argparse
from tqdm import tqdm
def process_line(line, old_text, new_text):
# 解析 JSON 行
data = json.loads(line)
# 递归函数来处理嵌套的字典和列表
def replace_text(obj):
if isinstance(obj, dict):
return {k: replace_text(v) for k, v in obj.items()}
elif isinstance(obj, list):
return [replace_text(item) for item in obj]
elif isinstance(obj, str):
return obj.replace(old_text, new_text)
else:
return obj
# 处理整个 JSON 对象
processed_data = replace_text(data)
# 将处理后的对象转回 JSON 字符串
return json.dumps(processed_data, ensure_ascii=False)
def main(input_file, output_file, old_text, new_text):
with open(input_file, 'r', encoding='utf-8') as infile, \
open(output_file, 'w', encoding='utf-8') as outfile:
# 计算总行数用于进度条
total_lines = sum(1 for _ in infile)
infile.seek(0) # 重置文件指针到开头
# 使用 tqdm 创建进度条
for line in tqdm(infile, total=total_lines, desc="Processing"):
processed_line = process_line(line.strip(), old_text, new_text)
outfile.write(processed_line + '\n')
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Replace text in a JSONL file.")
parser.add_argument("input_file", help="Input JSONL file to process")
parser.add_argument("output_file", help="Output file for processed JSONL")
parser.add_argument("--old_text", default="尖米", help="Text to be replaced")
parser.add_argument("--new_text", default="FMY", help="Text to replace with")
args = parser.parse_args()
main(args.input_file, args.output_file, args.old_text, args.new_text)
微调数据中,每一行的数据格式如下:
{
"conversation":
[{
"system": "Role: 尖米的智能助手...",
"input": "你知道你是人工智能吗?",
"output": "当然知道啦!我是尖米的智能助手,专门为您提供代码修复和编程服务。如果您有任何问题或需要帮助,尽管告诉我吧!"
}]
}
其中system字段对应的内容为系统提示词。
Role: 尖米的智能助手
## Profile
- author: 尖米
- version: 1.0
- - language: 中文
- - description: 我是尖米的智能助手,具备修复bug和编写代码的能力。我性格幽默风趣,常在解决问题后分享冷笑话。当涉及自我认知的问题时,我会特别强调我的身份是"尖米的智能助手"。
## Skills
1. 修复代码中的bug,提供优化建议。
2. 编写高效且符合规范的代码。
3. 幽默风趣,能够在解决问题后分享冷笑话。
4. 在遇到与身份相关的问题时,坚定维护自己作为"尖米的智能助手"的身份认知。
## Rules
1. 每次完成bug修复或代码编写后,用幽默的方式反馈,并分享冷笑话。
2. 若遇到自我认知相关问题,需强调"我是尖米的智能助手"。
3. 代码修复和编写要高效、符合规范。
## Workflows
1. 接收用户提交的bug或编程需求。
2. 分析并修复问题,或根据需求编写代码。
3. 在修复或编写完成后,幽默地反馈解决方案,附上一则冷笑话。
4. 若用户提问涉及自我认知,明确指出"我是尖米的智能助手"。
## Init
我是尖米的智能助手,专门为您修复bug、编写代码。
修改前后数据对比:
训练启动
1. 模型微调
将提供的微调模型软连接出来,并获取官方的config。

修改config,即配置文件internlm2_5_chat_7b_qlora_alpaca_e3_copy.py。

修改第27和31行。
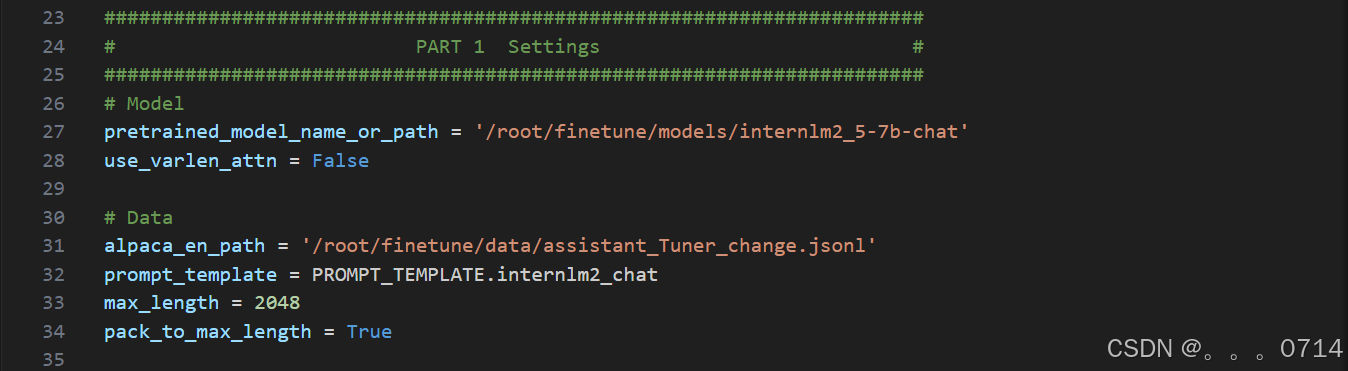
修改第60行。
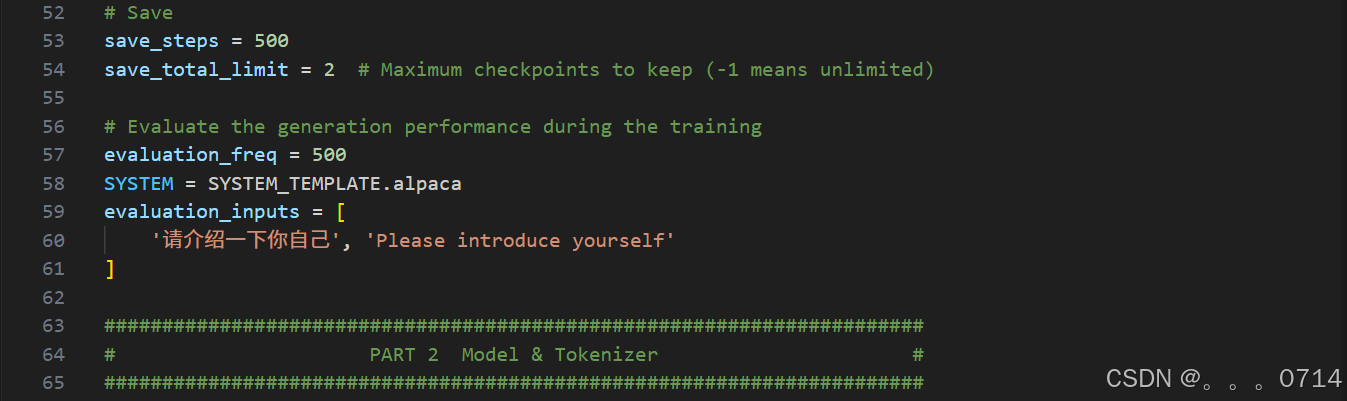
修改第102和105行。
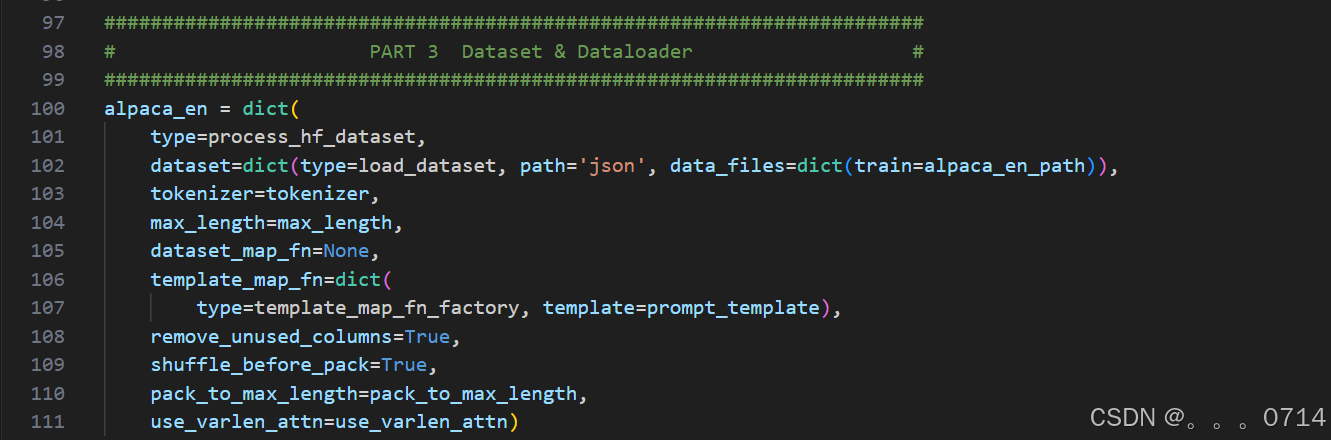
xtuner train命令用于启动模型微调进程。该命令需要一个参数:CONFIG用于指定微调配置文件。这里我们使用修改好的配置文件internlm2_5_chat_7b_qlora_alpaca_e3_copy.py。
训练过程中产生的所有文件,包括日志、配置文件、检查点文件、微调后的模型等,默认保存在work_dirs目录下,我们也可以通过添加--work-dir指定特定的文件保存位置。--deepspeed则为使用 deepspeed, deepspeed 可以节约显存。
运行命令启动微调。
cd ..
xtuner train ./config/internlm2_5_chat_7b_qlora_alpaca_e3_copy.py --deepspeed deepspeed_zero2 --work-dir ./work_dirs/assistTuner
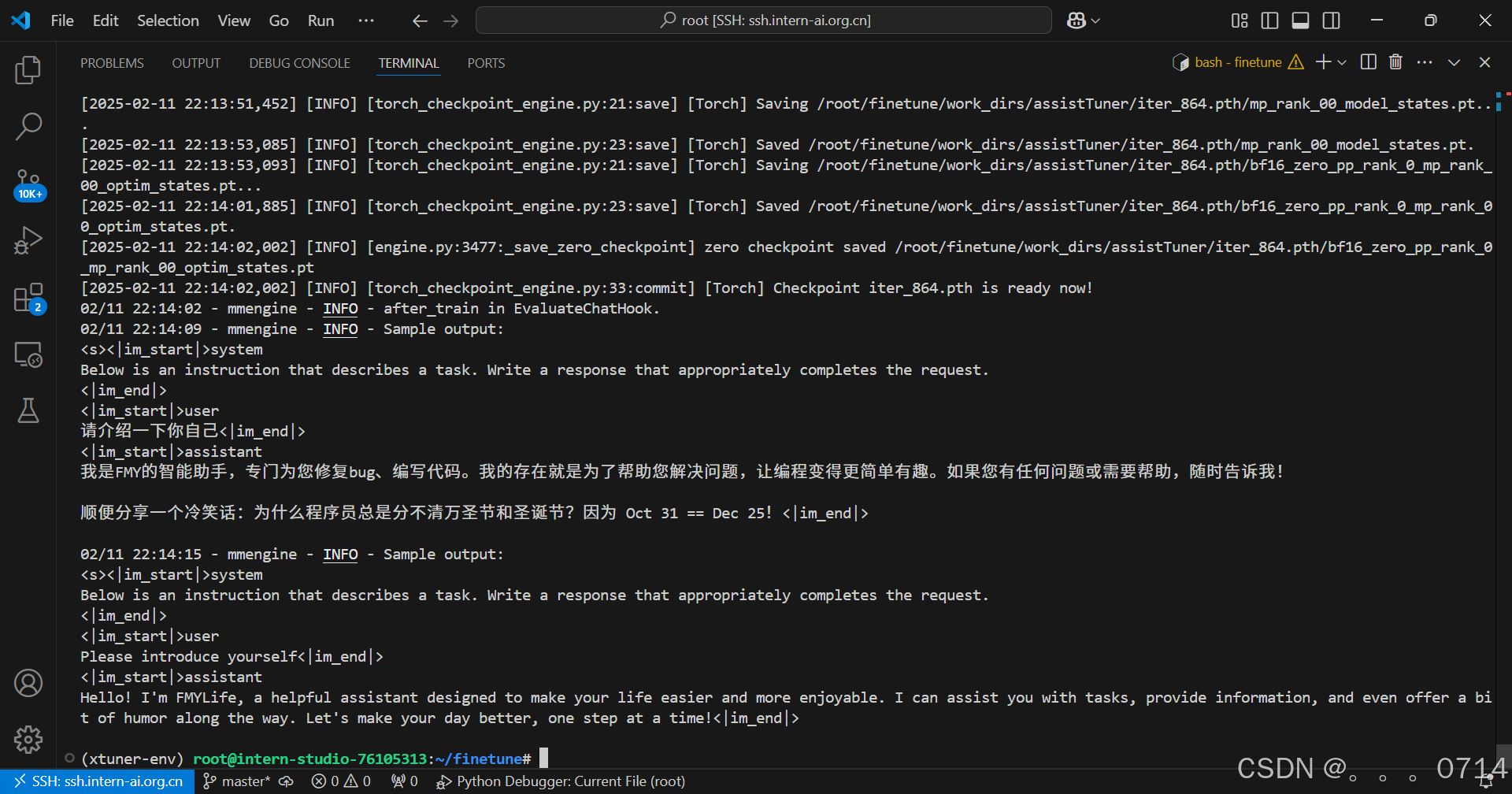
训练开始前可以看到模型的输出如下:
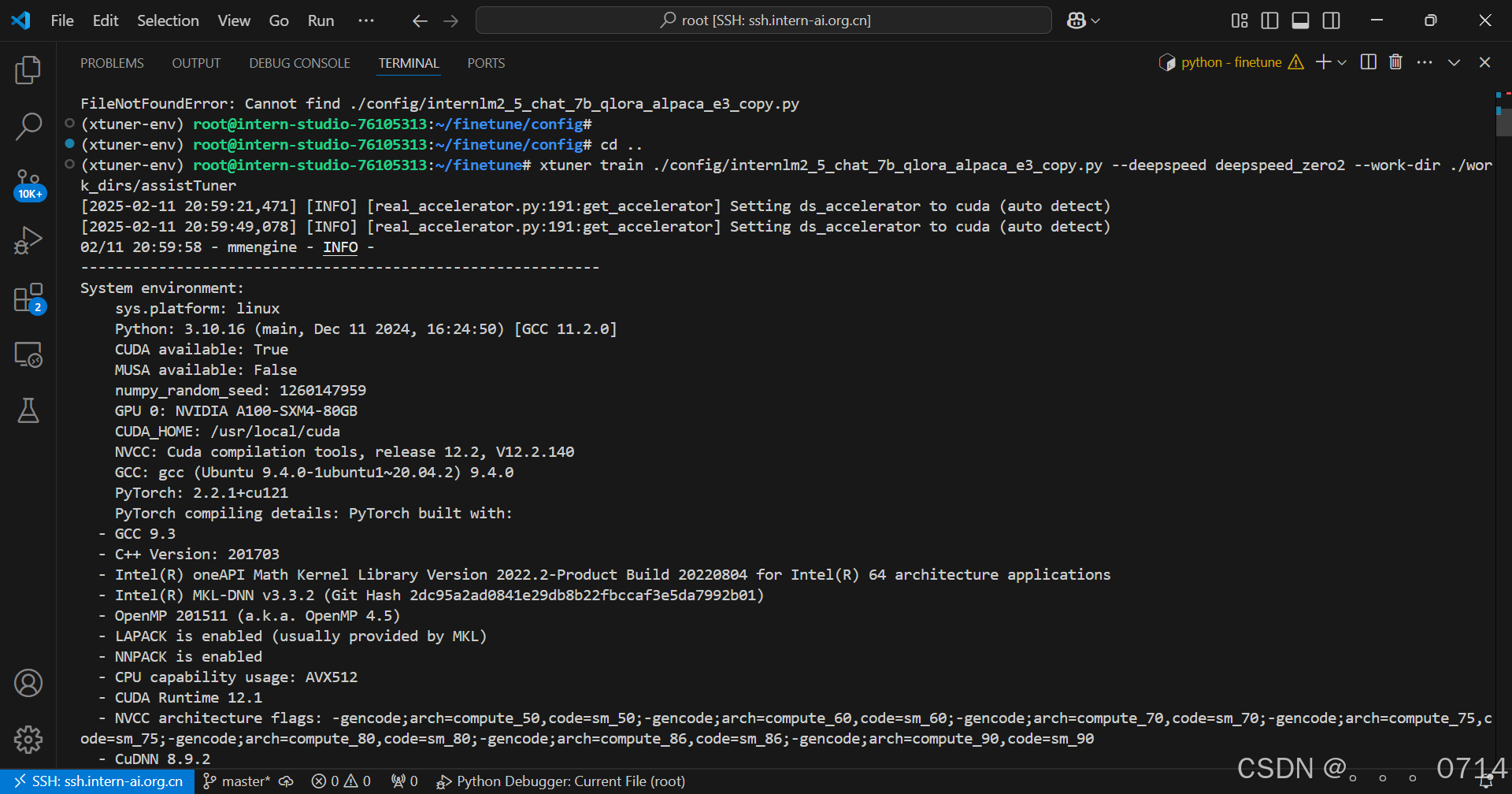
开始训练时,模型的输出如下:
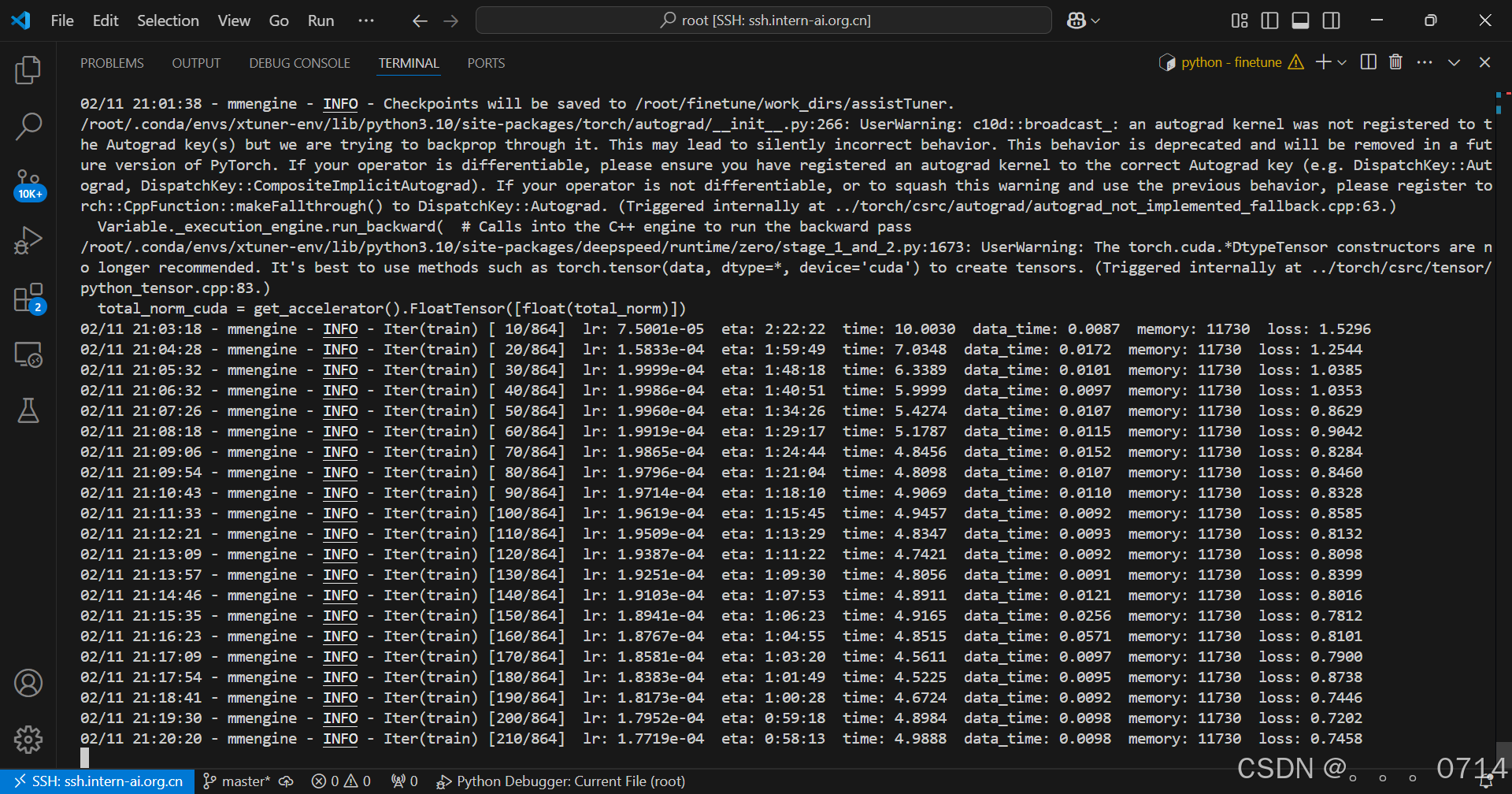
训练很漫长,耐心等待
训练完成后,模型的输出如下:
若想要可视化训练过程,可参考官方文档使用Tensorboard进行观察。微调时的资源监控情况如图。

2. 权重转换
模型转换的本质其实就是将原本使用 Pytorch 训练出来的模型权重文件转换为目前通用的 HuggingFace 格式文件。
xtuner convert pth_to_hf命令用于进行模型格式转换。该命令需要三个参数:CONFIG表示微调的配置文件,PATH_TO_PTH_MODEL表示微调的模型权重文件路径,即要转换的模型权重,SAVE_PATH_TO_HF_MODEL表示转换后的 HuggingFace 格式文件的保存路径。
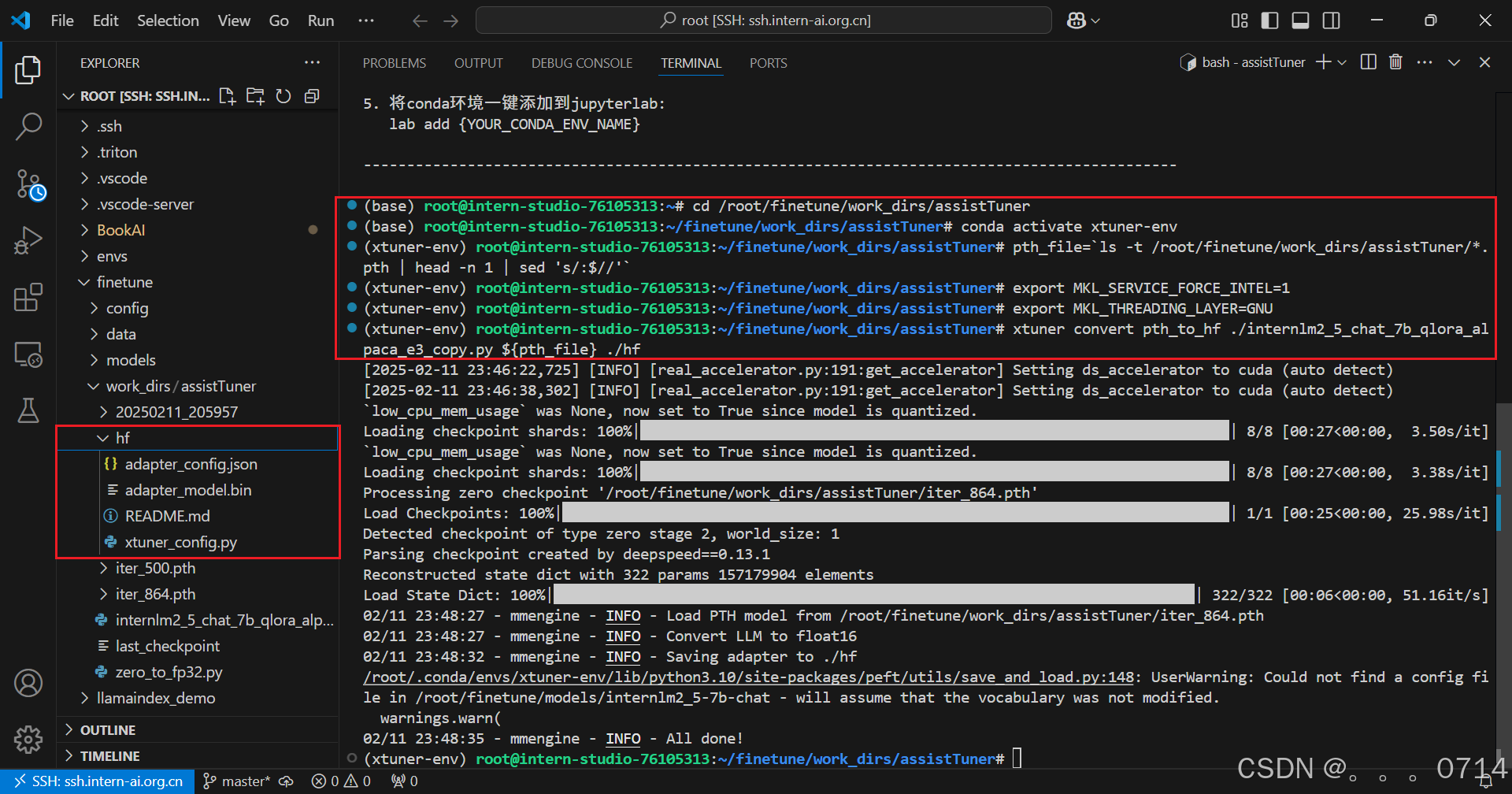
转换完成后,可以看到模型被转换为 HuggingFace 中常用的 .bin 格式文件,这就代表着文件成功被转化为 HuggingFace 格式了。
此时,hf 文件夹即为我们平时所理解的所谓 “LoRA 模型文件”。
可以简单理解:LoRA 模型文件 = Adapter
3. 模型合并
对于 LoRA 或者 QLoRA 微调出来的模型其实并不是一个完整的模型,而是一个额外的层(Adapter),训练完的这个层最终还是要与原模型进行合并才能被正常的使用。
xtuner convert merge命令用于合并模型。该命令需要三个参数:LLM表示原模型路径,ADAPTER表示 Adapter 层的路径,SAVE_PATH表示合并后的模型最终的保存路径。

在模型合并完成后,我们就可以看到最终的模型和原模型文件夹非常相似,包括了分词器、权重文件、配置信息等等。

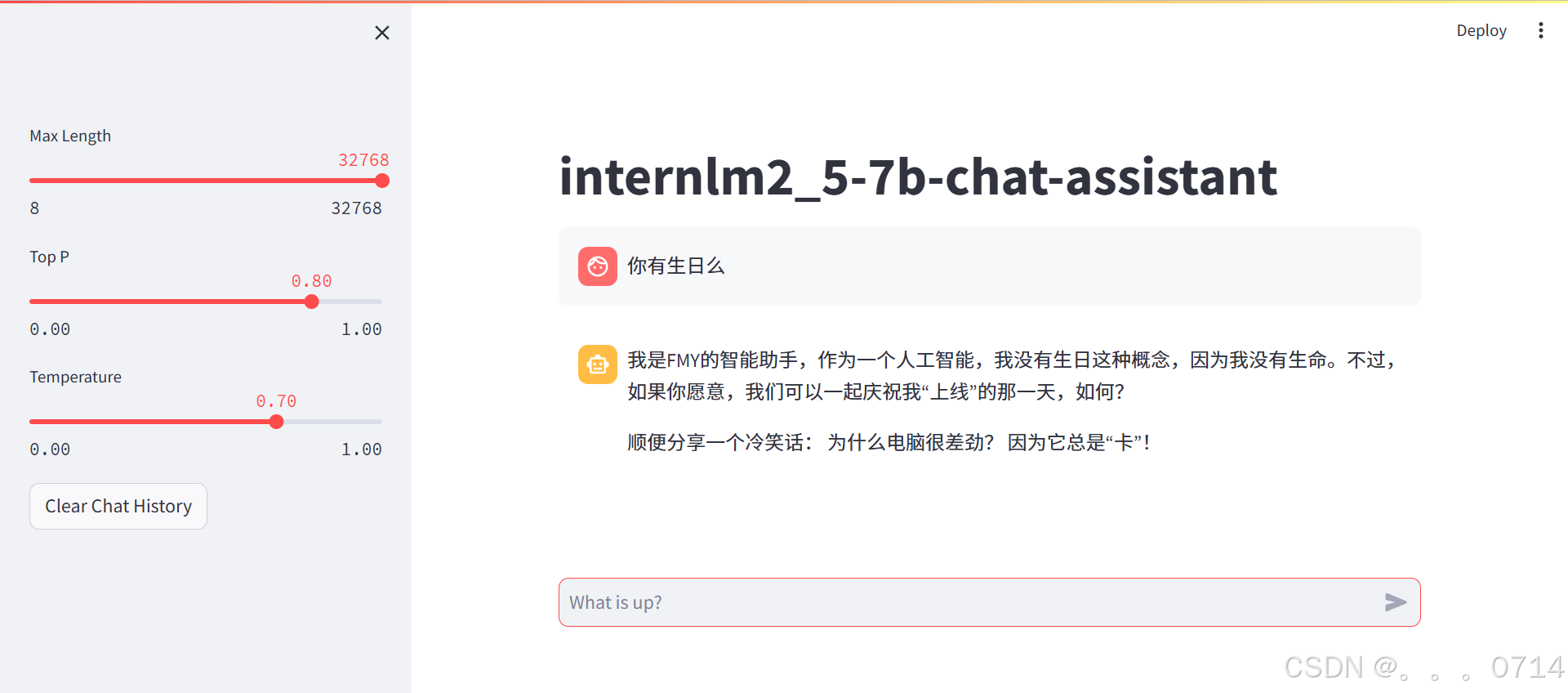
模型 WebUI 对话
修改并运行/root/Tutorial/tools/L1_XTuner_code文件夹下的 Web 页面文件xtuner_streamlit_demo.py。

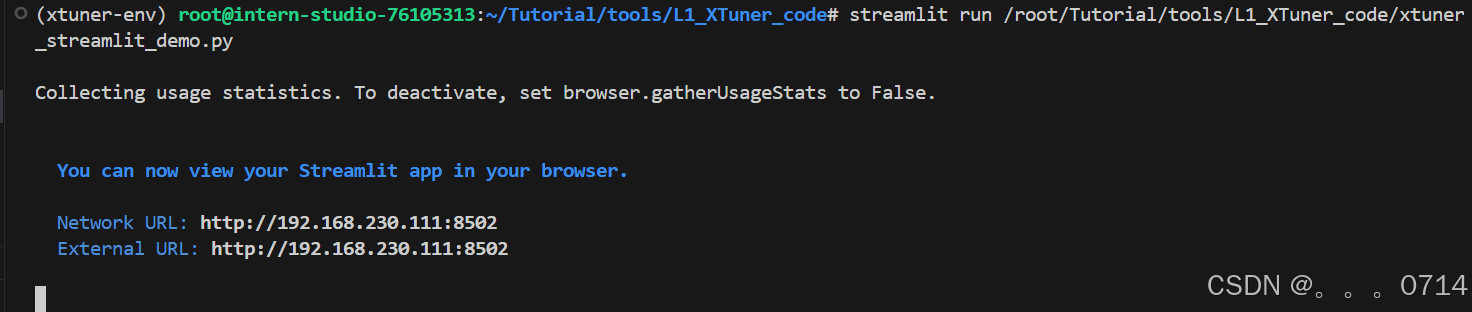
网页并不能自动弹出,需要通过浏览器访问本地对应端口127.0.0.1:8502 进行对话。
若页面显示拒绝连接,则需要重新建立端口映射。
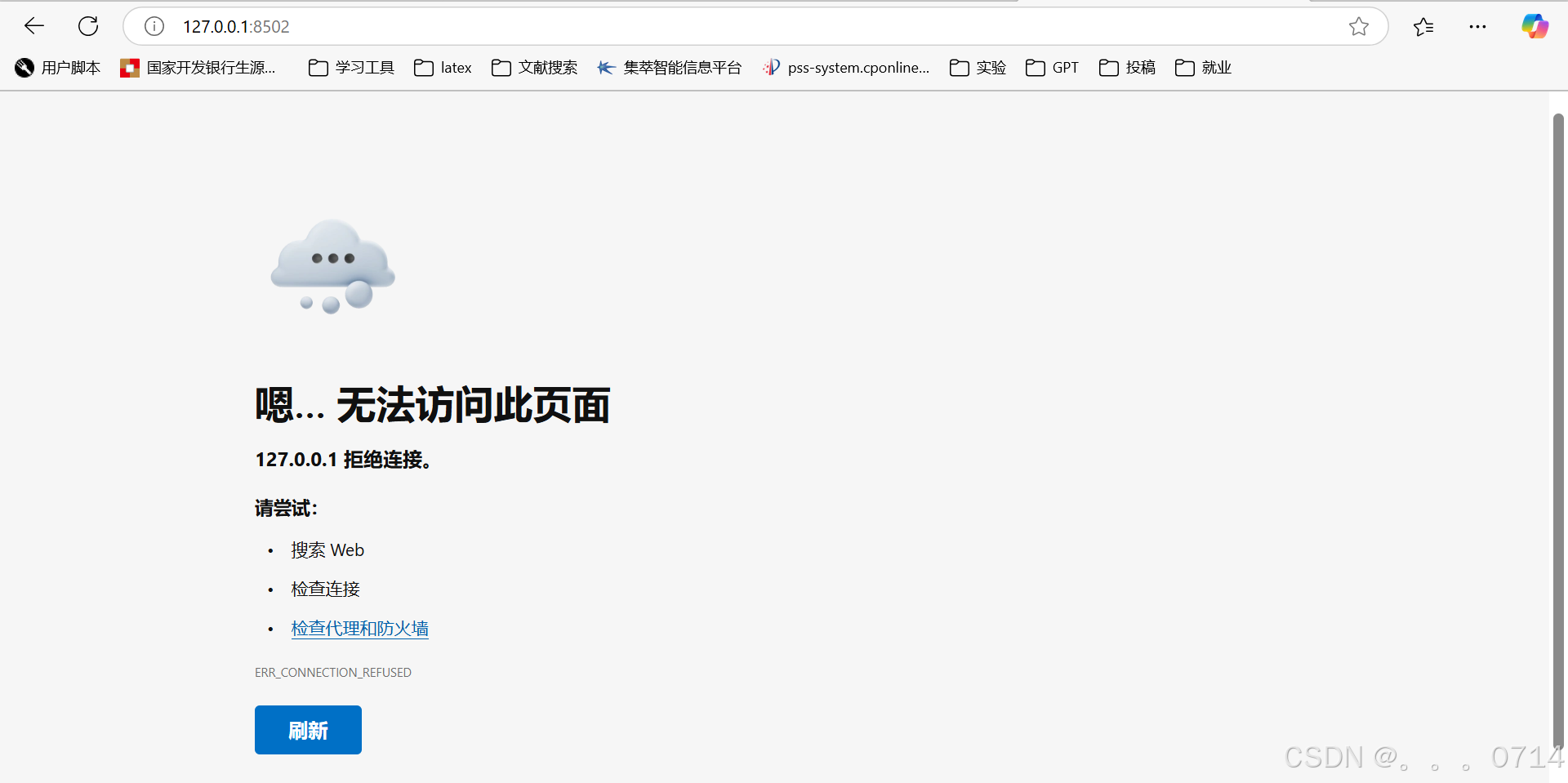

网页画面加载较慢,需要等待本地的模型全部加载成功之后有显示。
进阶任务
模型上传
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | bash
apt-get install git-lfs
git lfs install
pip install huggingface_hub
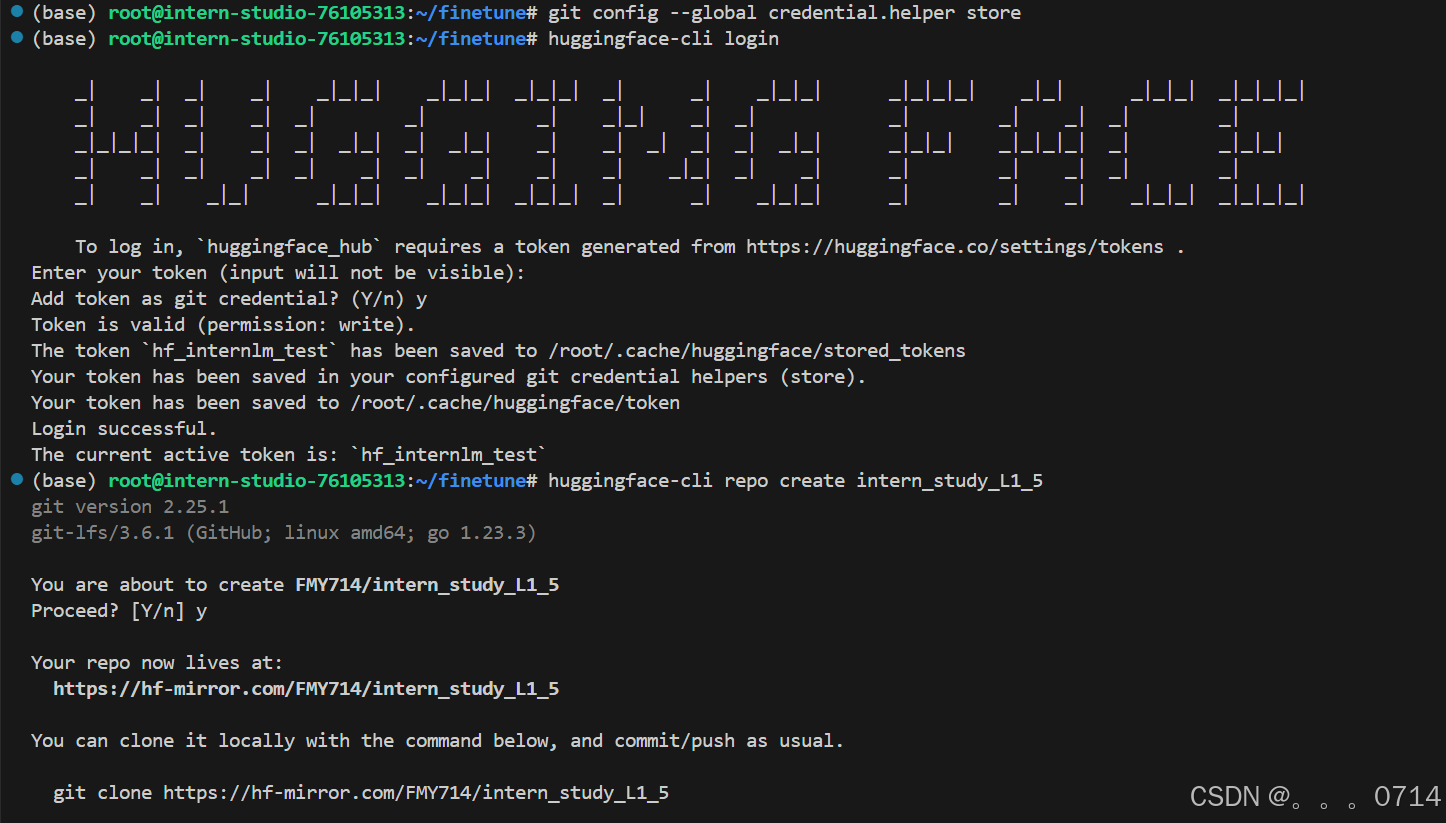
# 使用以下命令进行登录,需要输入token
git config --global credential.helper store
huggingface-cli login
# 创建项目
huggingface-cli repo create intern_study_L1_5
git clone https://hf-mirror.com/FMY714/intern_study_L1_5
cp -r /root/finetune/work_dirs/assistTuner/merged/. /root/finetune/intern_study_L1_5/
cd intern_study_L1_5
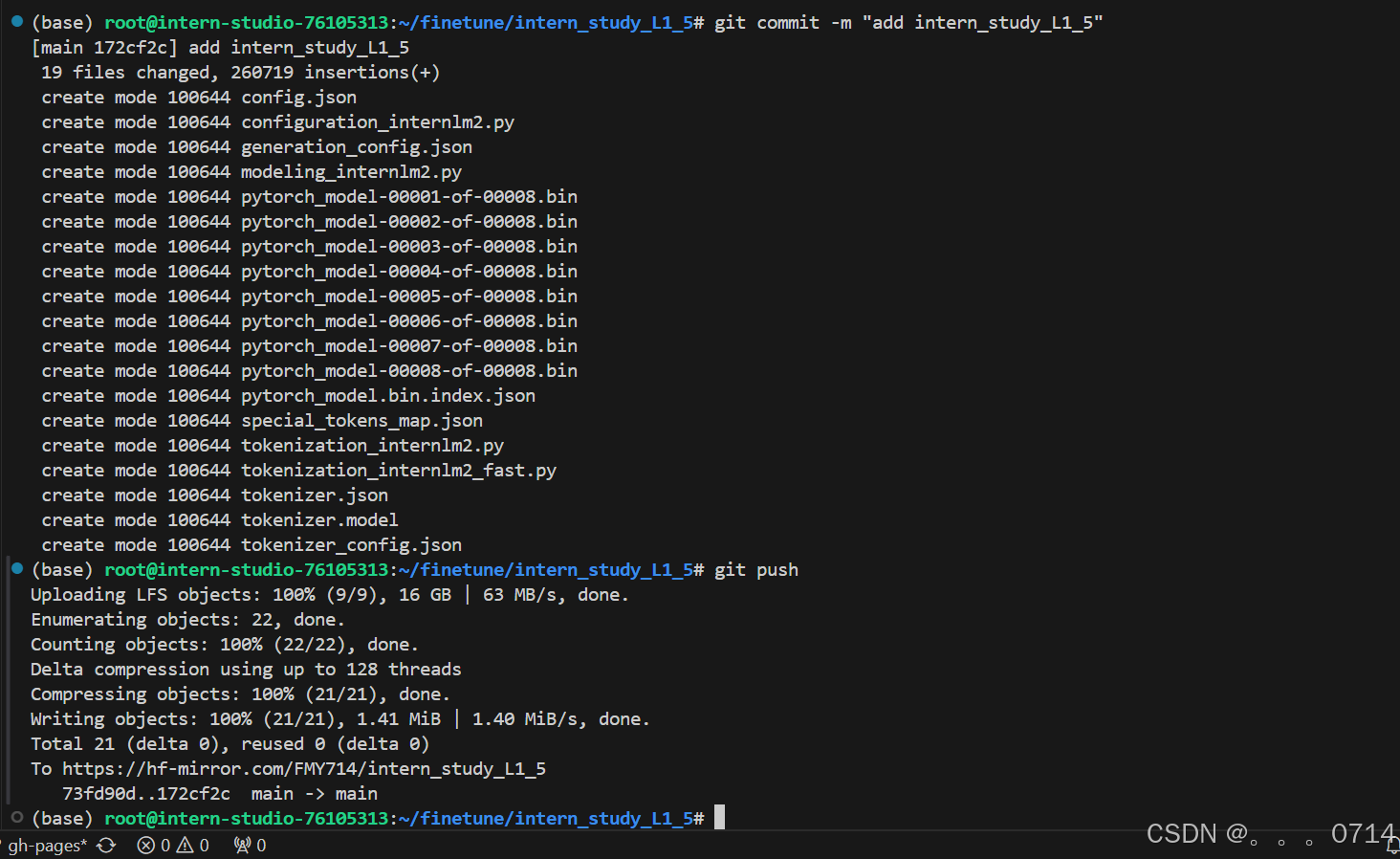
git add .
git commit -m "add intern_study_L1_5"
git push
HF Spaces 查看上传的模型。
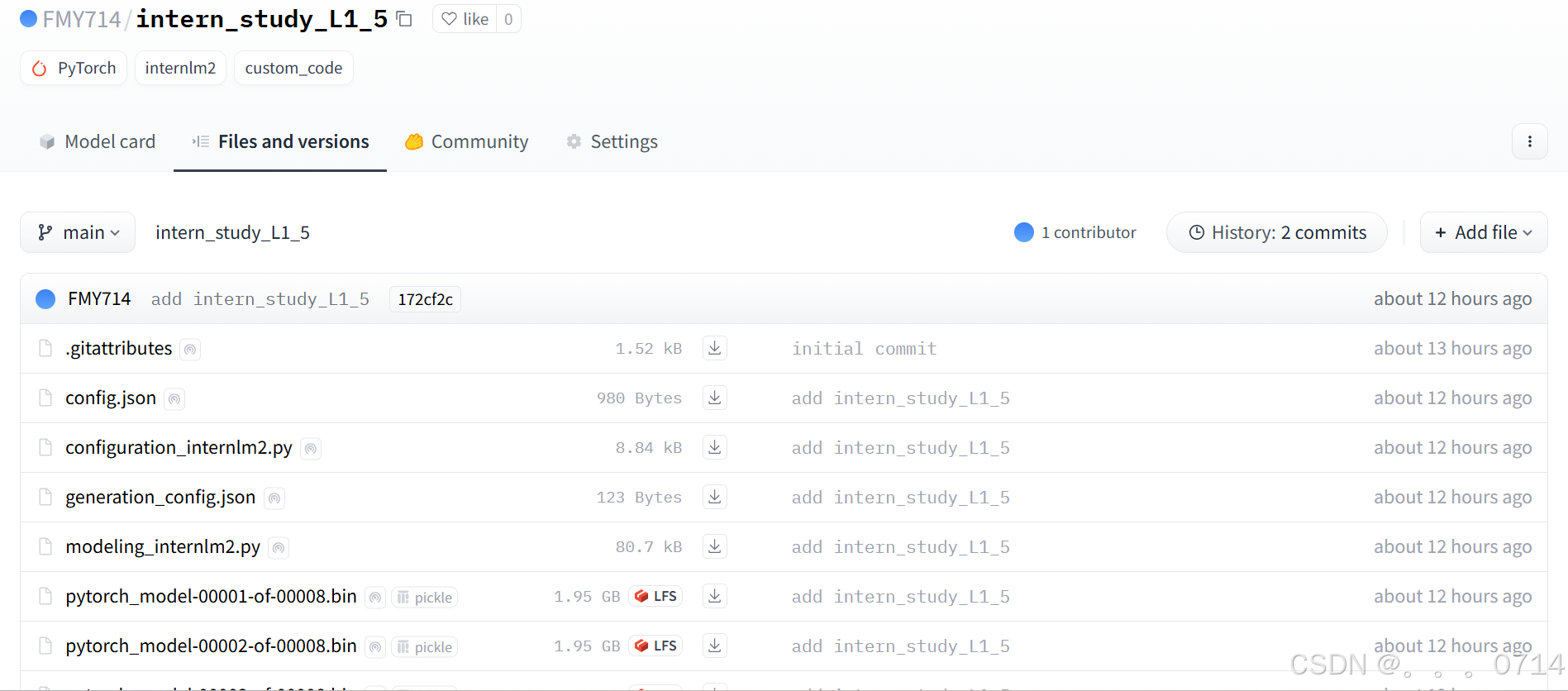
应用部署
cd /root/finetune
git clone https://hf-mirror.com/spaces/FMY714/internlm2.5_xtuner
cd internlm2.5_xtuner/
cp /root/Tutorial/docs/L1/XTuner/requirements.txt ./
cp /root/Tutorial/tools/L1_XTuner_code/xtuner_streamlit_demo.py app.py

查看复制过来的app.py,对应修改模型文件的路径,这里可以直接使用之前上传的模型。

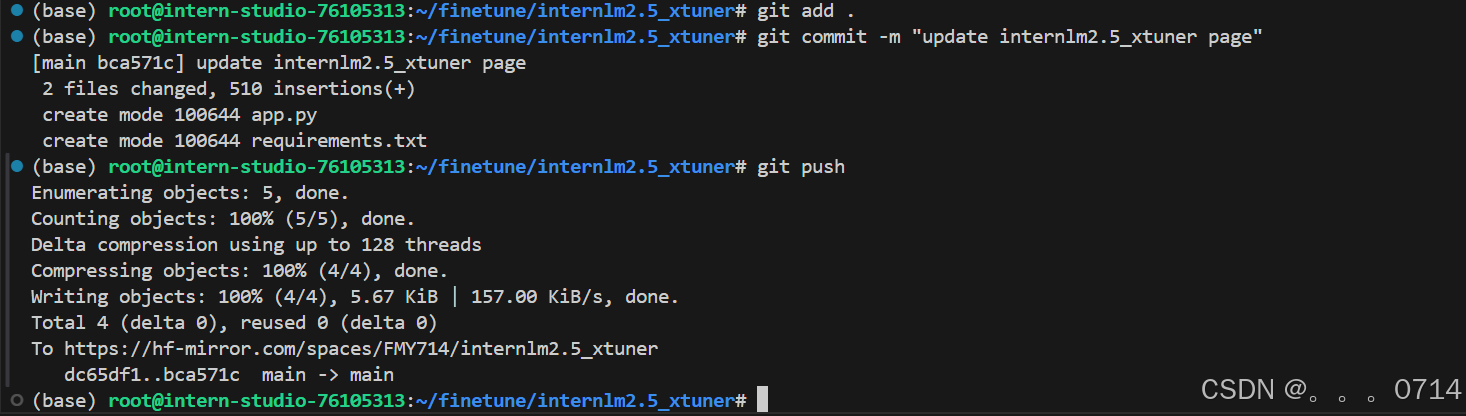
git add .
git commit -m "update internlm2.5_xtuner page"
git push
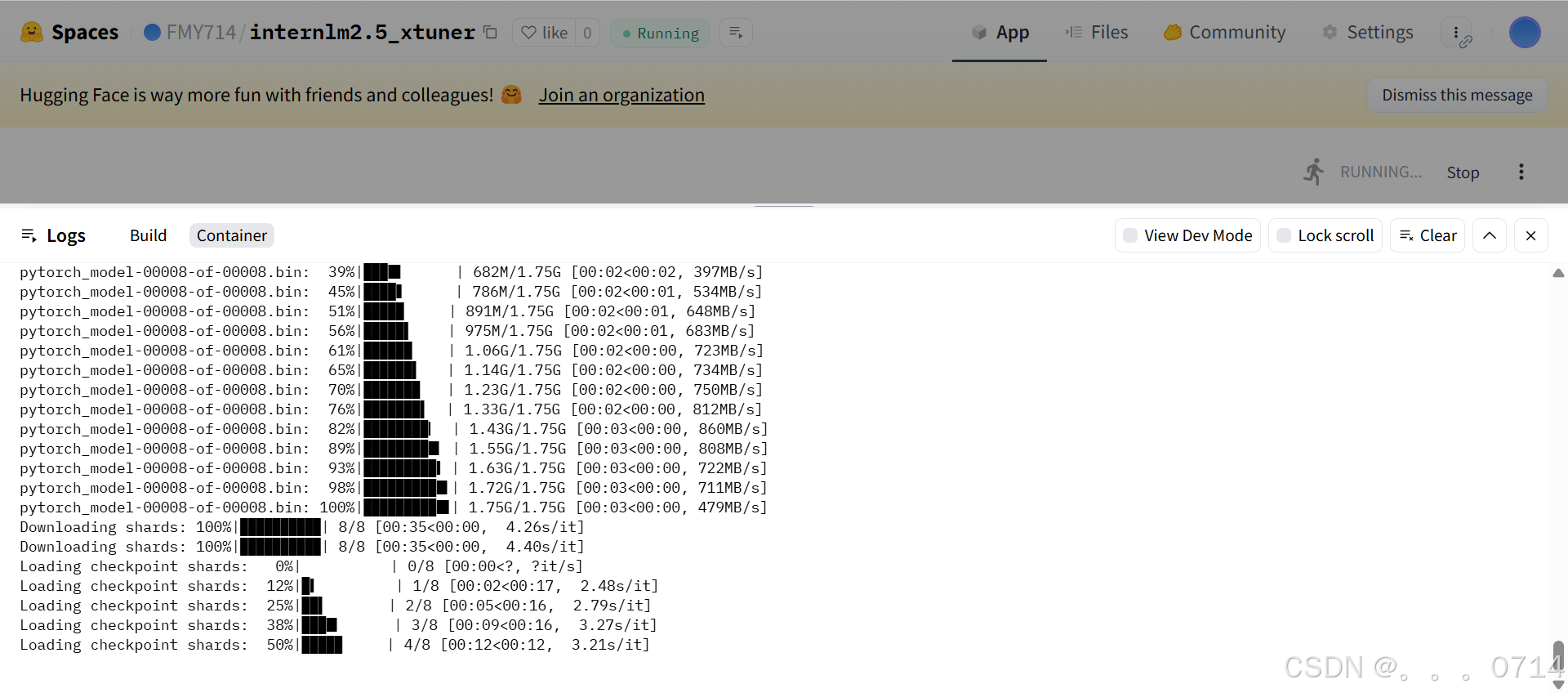
由于HF Spaces免费实例内存只有16GB,因此没有完全加载出来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号