

python对diamonds数据集进行数据分析
一、探索性数据分析
探索性数据分析(Exploratory Data Analysis)这是通过一系列的方法,让你最大化对数据的直觉,为了让你对数据有感觉,你不仅需要知道数据里有什么,你还需要知道数据里没有什么,而完成这件事情的方法只有一个,那就是结合各种统计学的图形把数据以各种形式展现在我们面前。
The goal is to show the data, summarize the evidence and identify interesting patterns while eliminating ideas that likely won’t pan out. ——Exploratory Data Analysis wiht R
其实就是通过图形将数据呈现,让你对数据有一定的了解,为进一步的分析奠定基础。最重要的部分其实就是画图了,所以这一部分将diamonds.csv数据进行分析对比,比较对钻石价格影响的因素。
二、提出问题
1、钻石的什么特性对价格的影响最大。
2、钻石克拉重量(Carat weight)、颜色(Color)、净度(Clarity)、切工(Cut)彼此之间有没有什么联系。
3、价格概率分布。
三、数据查看和预处理
1、描述数据集中的字段信息
本数据集描述了宝石相关信息和价格之间的关系
字段描述:
carat:代表钻石的重量
cut:代表了钻石的切工,由低到高依次为Fair, Good, Very Good, Premium, Ideal
color:代表了钻石的颜色从最低的J到最高的D
clarity:代表了钻石的透明程度从低到高依次为I1, SI1, SI2, VS1, VS2, VVS1, VVS2, IF
depth:深度
table:代表了钻石的桌面比例
price:代表了钻石的价格
x:钻石的长
y:钻石的宽
z:钻石的高
2、导入数据和相关库
import dtale import seaborn as sns import pandas as pd df = pd.read_csv(r'C:\Users\冉婷媛\Desktop\seaborn-data\diamonds.csv') dtale.show(df, ignore_duplicate=True)
3、查看数据集信息
3.1检查缺失值的情况
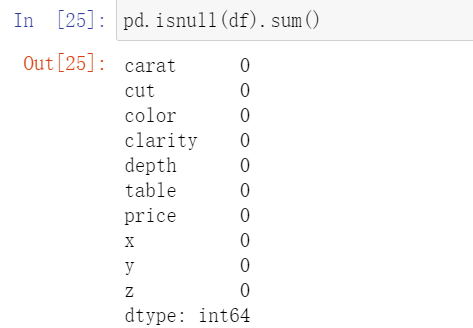
可以看到数据的完整性还是可以的,没有缺失的情况
3.2查看数据类型
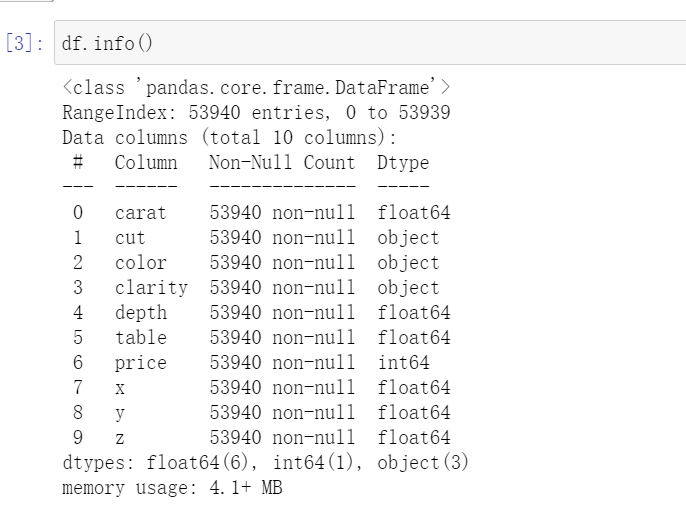
可以看到 carat属性,depth属性,table属性,x,y,z属性都是float类型的,后续分析起来会比较方便。
3.3查看数据信息
import dtale import seaborn as sns import pandas as pd import pandas as pd import numpy as np import seaborn as sns import matplotlib as mpl import matplotlib.pyplot as plt from IPython.display import display plt.rc("font",family="SimHei",size="12") diamond = pd.read_csv(r'C:\Users\冉婷媛\Desktop\seaborn-data\diamonds.csv') dtale.show(df, ignore_duplicate=True)
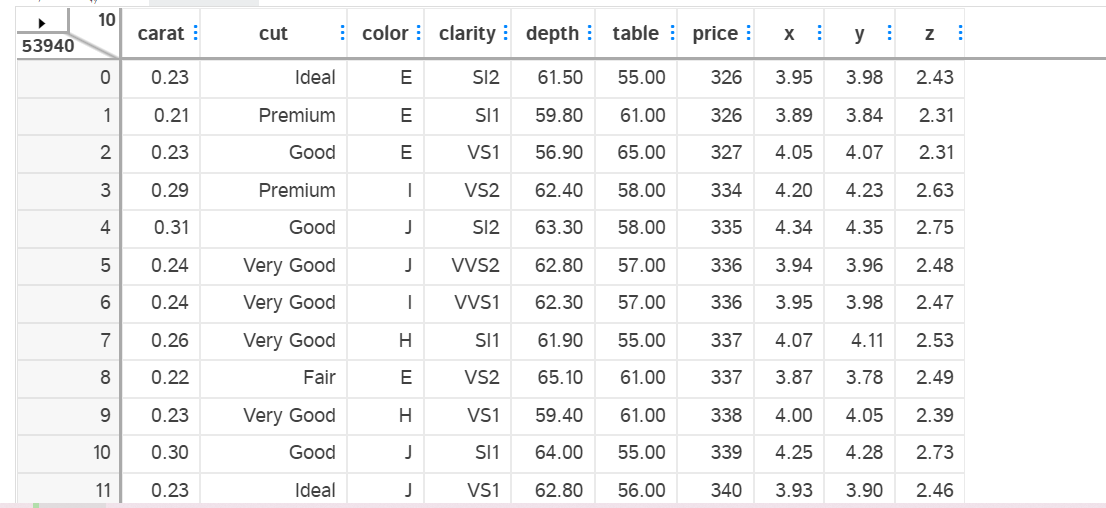
我们的数据集中包含53940个样本,10个特征。观察上表我们进一步发现,切工(cut),成色(color)和净度(clarity)三个特征为字符串类型表示的等级型离散型特征。其余特征为连续型特征。我们可以统计每一个特征的取值分布。
对于连续型特征,直接使用默认参数,计算每一个特征非空值数量、最大值、最小值、平均值和分位数等统计量。
diamond.describe().round(2)
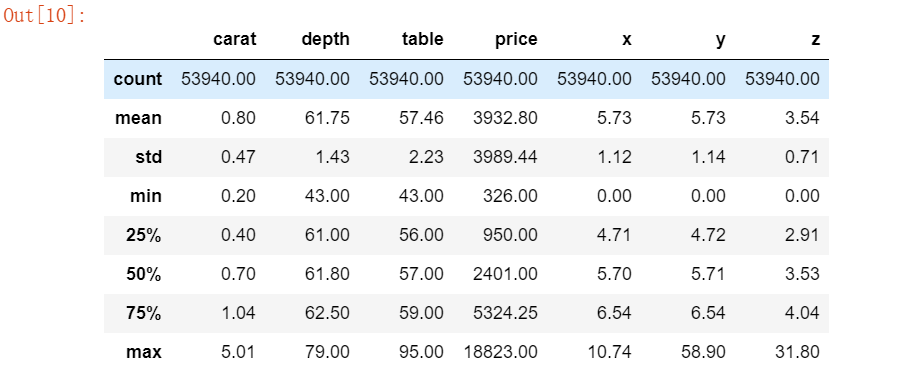
观察上表的第一行,我们发现取值与样本数量一致,说明上述特征均不存在缺失值。 观察第一列克拉重量特征,我们发现在五万多钻石样本中,最小的钻石重量为0.2克拉,最大的钻石重量为5.01克拉。 钻石的平均重量为0.8克拉。 观察price列,对于钻石价格,最便宜的为326美元,最贵的为18823美元,钻石的平均价格为3923.8美元。
对于离散型特征,我们首先感兴趣每一个特征唯一取值数量以及最频繁的取值及其数量。 在pandas中,我们依然可以使用DataFrame提供的describe函数完成。 不过,需要设置其include参数,如下所示。

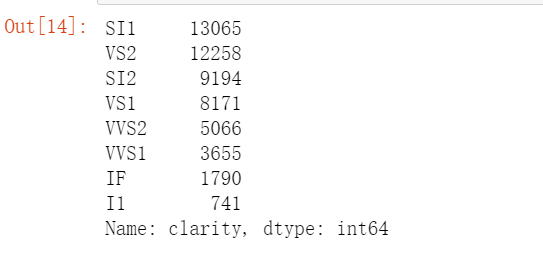
观察上述表第一行,我们同样发现三个离散型特征也不存在缺失值。切工等级有5个等级,最多的等级为"Ideal",有21551颗钻石属于该等级。成色有7个等级,最多的等级为"G",有11292颗钻石属于该等级。 净度则有8个等级,最多的等级为"SI1",有13065颗钻石属于该等级。
进一步地,如果我们想了解每一个等级钻石的数量。 则可以使用pandas中Series的value_counts函数来统计。
diamond["cut"].value_counts()

diamond["color"].value_counts()
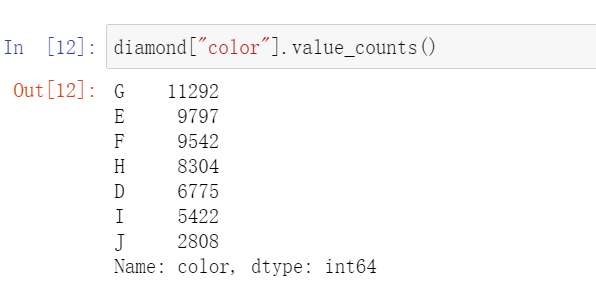
diamond["clarity"].value_counts()
当然,这只是初步观察,后续我们会用数据可视化来清晰的展示,并证实我们的猜测。
四、各变量相关性数据分析与可视化
下面我们借助seaborn工具,通过可视化的方法进一步理解钻石数据集。
1、通过直方图观察钻石价格的分布。
import seaborn as sns %matplotlib inline sns.distplot(diamond["price"],bins=300,kde=False,color="cyan")
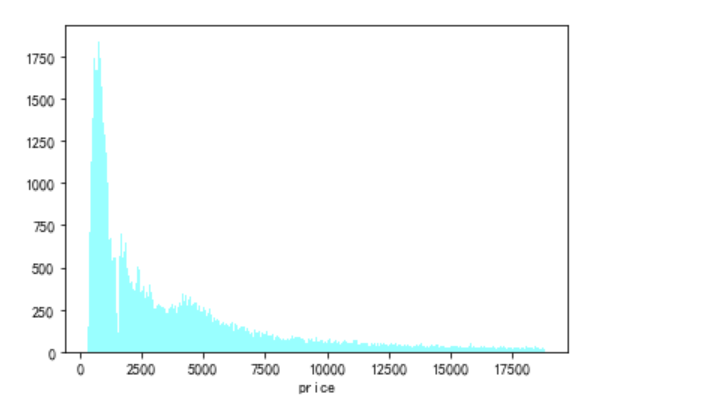
可以看到,钻石价格基本服从幂律分布。 其次我们通过柱状图展示不同切工等级,成色等级和净度等级钻石的分布。
2不同切割(cut)方式的统计
sns.countplot(diamond.cut)
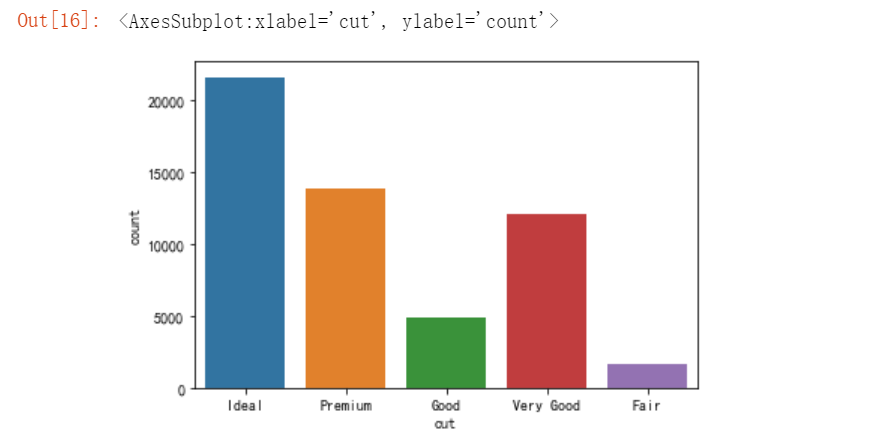
可见,切工为理想(Ideal)等级的钻石最多。切工等级高的钻石样本数量多。
3、不同颜色等级(color)方式的统计
sns.countplot(diamond.color)
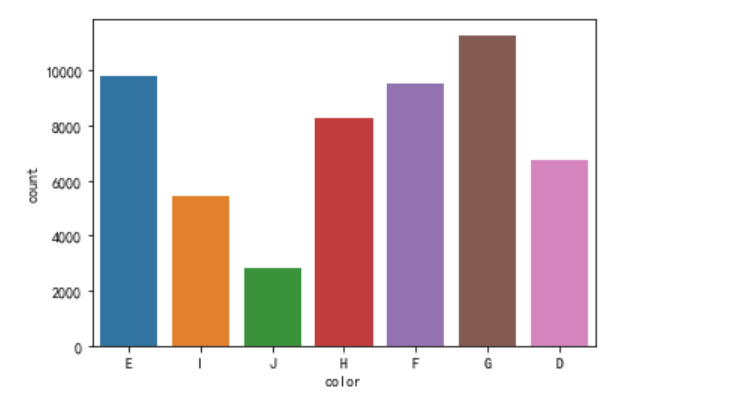
成色等级低和等级高的钻石数量较少,“G”等级的钻石数量最多。
4、钻石的carat特征分析
diamonds.hist(column= "carat", # 具体列 figsize=( 8, 8), # 图片大小 color= "blue"); # 绘画颜色
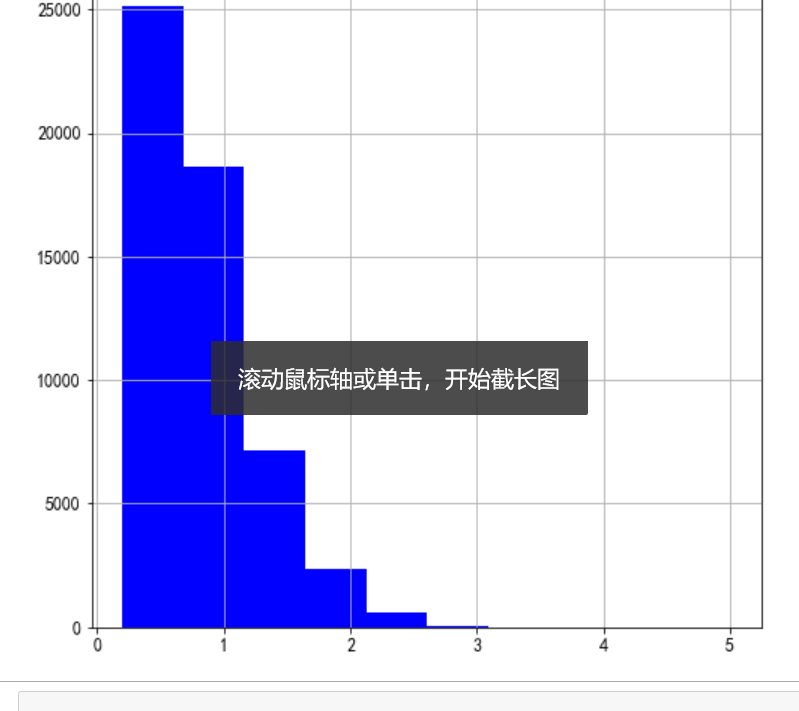
从图上我们可以看到钻石重量的分布是十分倾斜的:大多数钻石大约1克拉及以下,但也有极少量极端值。
为了获得更多细节的数据,我们可以增加分箱的数量来查看更小范围内的钻石重量,通过限制x轴的宽度使整个图形在画布上显得不那么拥挤。
diamonds.hist(column= "carat", figsize=( 8, 8), color= "blue", bins= 50, range= ( 0, 3.5));
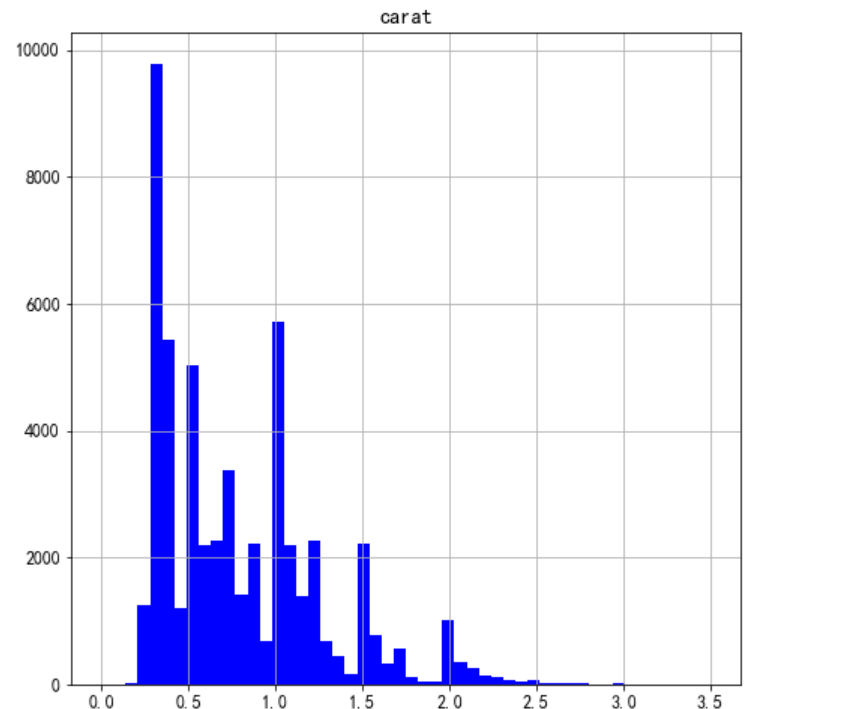
这个直方图让我们更好地了解了分布中的一些细微差别,但我们不能确定它是否包含所有数据。将X轴限制在3.5可能会剔除一些异常值,以至于它们在原始图表中没有显示。接下来看看有没有钻石大于3.5克拉:
df[df[ "carat"] > 3.5]
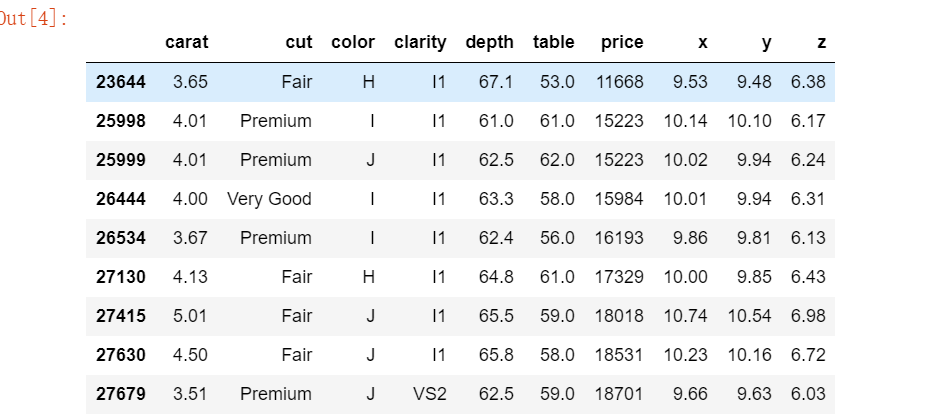
哦豁,真的有9颗钻石比3.5克拉大,这些'怪种'钻石我们应该关心吗?出于数据探索的目的,我们完全可以舍弃这些点,但如果是把数据的全貌展示给别人看,我觉得有必要详细说明:范围之外还存在9个离群点。
箱线图是另一种单变量图, 方法pd.boxplot
df.boxplot(column= "carat");
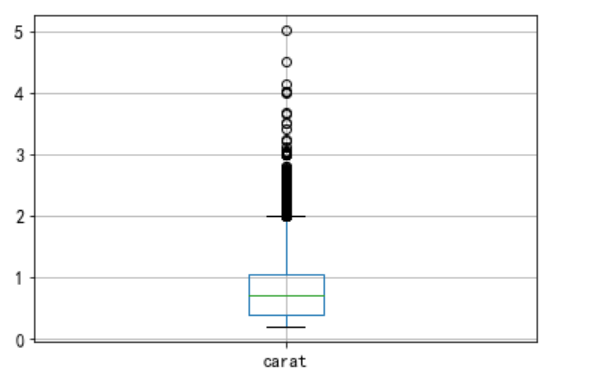
箱线图的中心框代表中间50%的观察值,中心线代表中位数。
boxplot最有用的特性之一是能够生成并排的boxplots。每个分类变量都在一个不同的boxside上绘制一个分类变量。
5、钻石的特征与其价格之间的关系
5.1价格和克拉之间的关系
下面,我们来通过图表了解一下钻石的特征与其价格之间的关系。 我们要问的第一个问题是:钻石克拉重量越大,价格越高吗? 由于上述两个特征均为连续型特征,我们可以绘制散点图来分析。 seaborn工具的jointplot函数可以方便地绘制散点图。
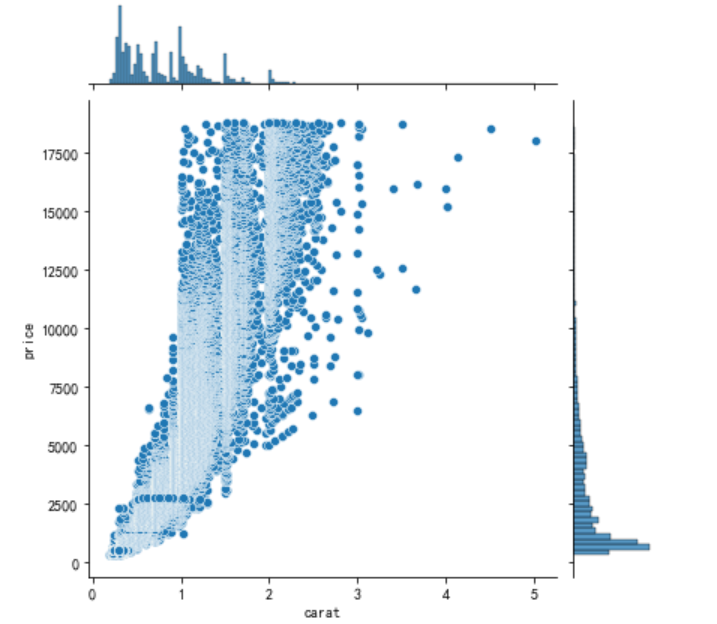
通过散点图虽然能看到指数上升的趋势。 不过我们也发现,存在价格昂贵但克拉重量较小的钻石(上图左上方的点)。也有不少钻石虽然克拉重量很大,但是价格却不是特别高(上图右下方的点)。
5.2切工与价格的关系
切工与价格的关系如何? 我们可以首先将钻石按照切工分组,然后计算每一个切工等级的钻石的平均价格等。 在pandas中,我们可以借助DataFrame的groupby函数进行分组,然后使用mean函数分组聚集计算。
diamond.groupby("cut")["price"].mean()

单单从切工看,价格和切工并不存在很强的直接相关性。我们也可以借助seaborn的盒图直观地观察。
sns.boxplot(x="cut", y = "price",data = diamond, orient="v")
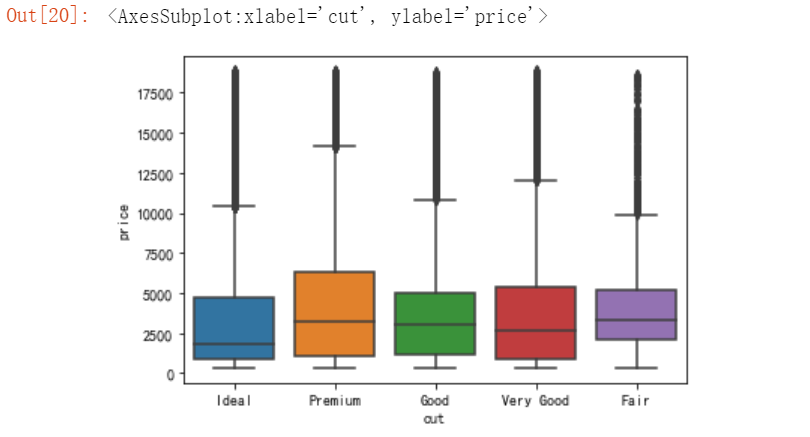
5.3价格和钻石净度之间的关系
接下来将钻石价格按钻石净度分成两部分来做一个并排的方框图:
df.boxplot(column= "price", by= "clarity", figsize= ( 8, 8));
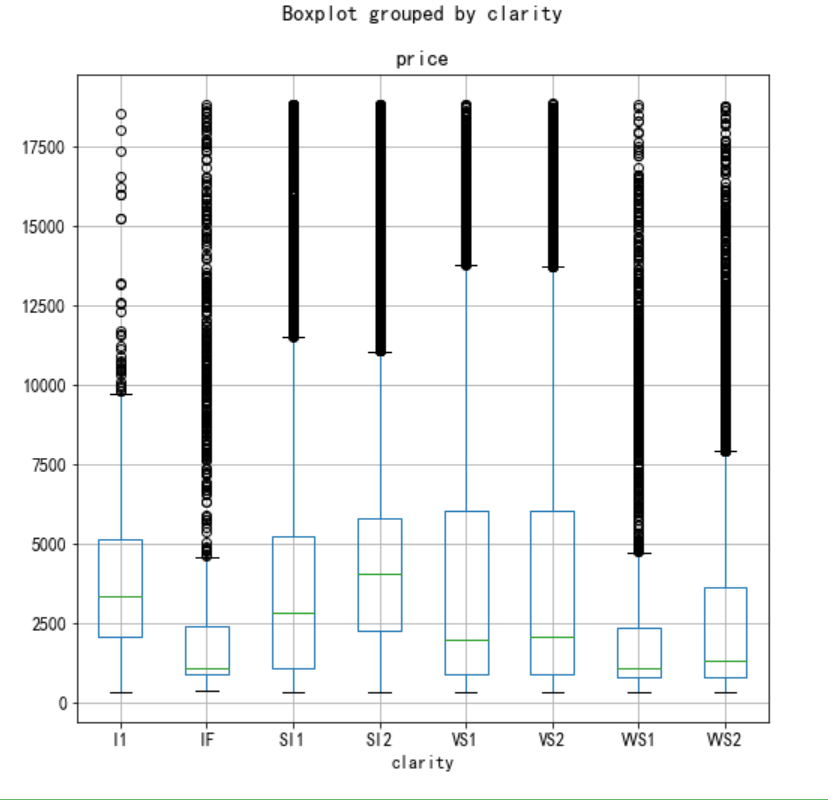
上面的图表显示,透明度较低的钻石往往更大,透明度高的钻石更加小巧。由于尺寸重量是决定钻石价值的另一个重要因素,因此低透明度钻石的中间价较高也就不足为奇了。
5.4价格和克拉,切工之间的关系
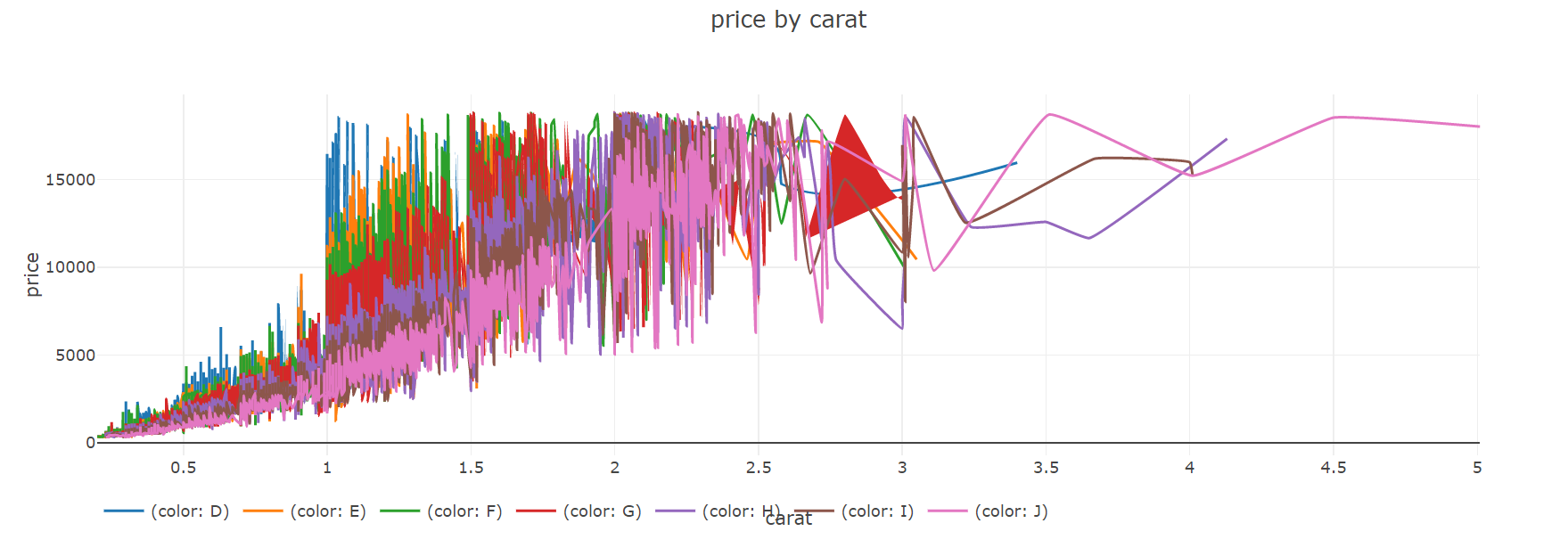
看起来不方便,我们把它分开来看
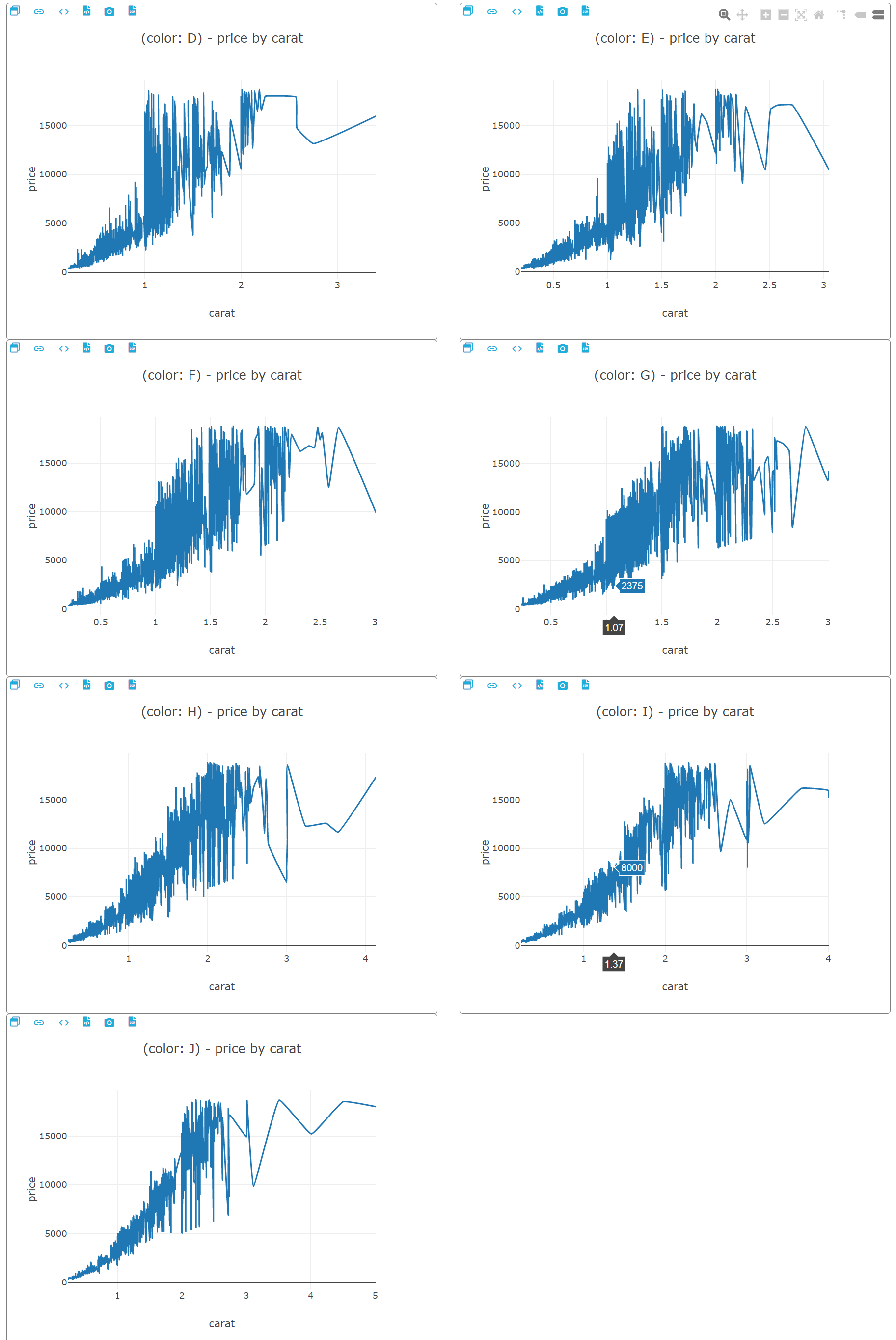
感觉切工对价格的影响不是很大,还是克拉对钻石价格的影响大一些。
5.5价格和钻石净度,克拉之间的关系
添加钻石每克拉的均价,对数据进行重新排列
dff =df.copy() dff['PerPrice'] = df['price']/df['carat'] # 重新摆放列位置 columns = ['carat', 'cut', 'clarity', 'depth', 'PerPrice', 'price'] dff = pd.DataFrame(dff, columns = columns) # 重新审视数据集 display(dff.head(n=2))
对于clarity特征,我们可以分析不同clarity等级和单价的对比。
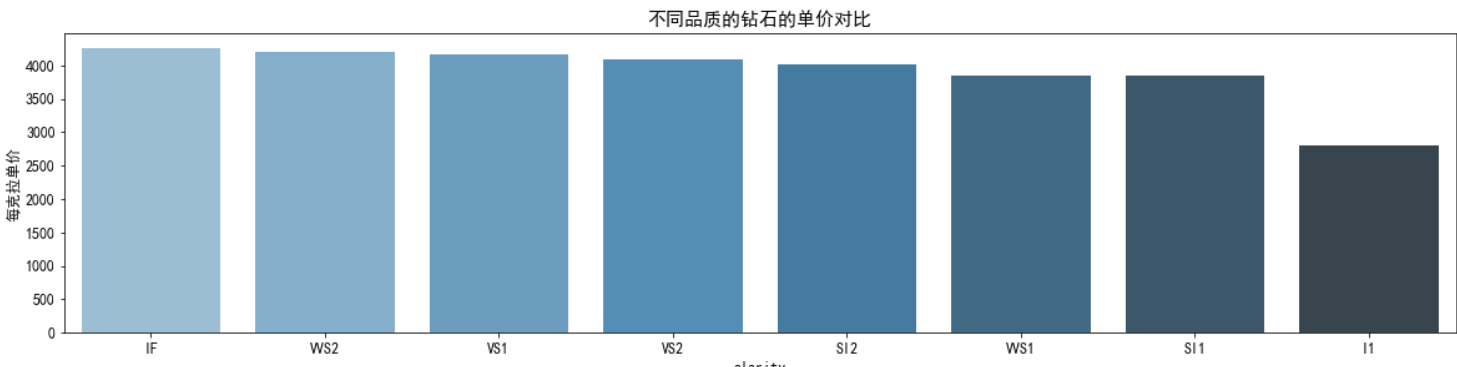
使用了pandas的网络透视功能groupby 分组排序。区域特征可视化直接采用 seaborn完成,颜色使用调色板palette 参数,颜色渐变,越浅说明越少,反之越多。可以观察到:
- 均价:lF品质的均价最高大约是在2500左右,没办法IF的品质最高,其次是VVS2的价格最高,但VVS1的均价居然比VS2 都低,差不多和SI1持平感觉有问题,也可能是受其他因素的影响了。I1的均价是最低的,也在意料当中,但价格比起其他品质等级来说,差距有点大了。
5.5钻石的X,Y,Z属性之间的关系
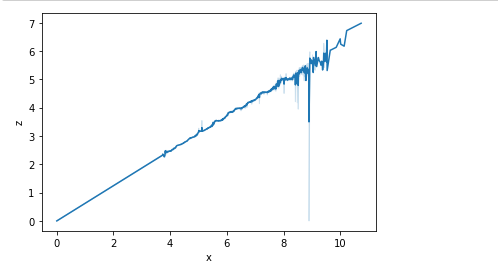
sns.lineplot(x="x",y="z",data=df) plt.show()
sns.displot(df['z'],kde=False) plt.show() sns.displot(df['z'],kde=True) plt.show()
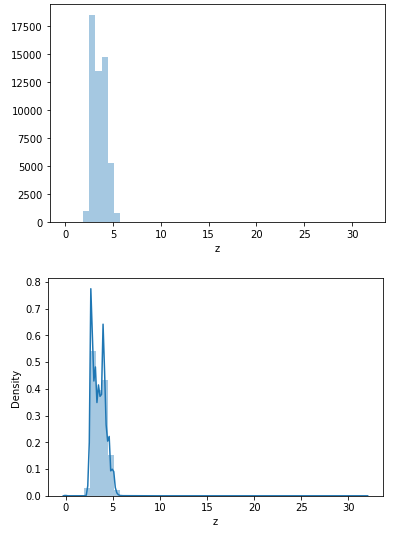
感觉X,Y,Z的属性的相差不大,X和Z是呈现一个正相关的联系。Z这个属性的值还是比较集中的
我们在通过相关系数看一下各个钻石特性和钻石价格之间的关系
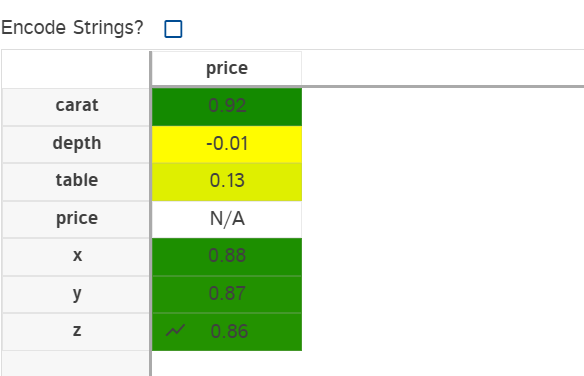
可以看到对钻石的价格影响最深的特征就是钻石的克数,价格跟深度是负相关,也就是说价格越高,深度越低。
五、主要结论
对数据集的探究就到这里了,通过以上的分析可以得出,钻石价格的主要影响因素就是克拉数,所以在买钻石的时候考虑的第一个要素应该是克拉,钻石的价格随克拉数的升高而升高。其次对钻石价格影响较大的是钻石的透明度,透明度越好(IF)的钻石的单价越高。但是透明度较低的钻石往往更大,透明度高的钻石更加小巧。所以说这些数据都不是绝对的,买钻石的时候还是看看当时的行情和自己的喜好再作决定。
