

J1 机器学习概述
------------恢复内容开始------------
1 什么是机器学习
机器学习就是从数据中自动分析获得模型,并利用模型对未知数据进行预测。
2 机器学习工作流程
- 获取数据
- 数据基本处理
- 特征工程
- 机器学习(模型训练)
- 模型评估
- 结果达到要求,上线服务
- 结果没达到要求,重新以上步骤
2.1 获取数据
- 数据有很多类型,例如连续类型数据、非连续类型数据
- 训练数据与测试数据等
2.2 数据基本处理
- 即对数据进行缺失值、去除异常值等操作
2.3 特征工程
特征工程是使用专业背景知识与技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
- 特征工程包含内容:
- 特征提取:将任意数据(如文本数据或者图像数据)转换为可用于机器学习的数字特征。
- 特征预处理:通过一些转换函数将特征数据转换成更加适合算法模型的特征数据的过程。例如数据归一化。
- 特征降维:指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程
3 机器学习算法分类
3.1 监督学习
- 定义:输入数据是由输入特征值和目标值所组成。
- 函数的输出可以是一个连续的值(回归),例如预测房价
- 或者输出是有限个离散值(分类),例如判断肿瘤是良性还是恶性
3.2 无监督学习
- 定义:输入数据是由输入特征值组成,没有目标值
- 输入数据没有被标记,也没有明确结果,样本数据类别也未知
- 需要根据样本之间的相似度来对样本类别进行划分,例如分类问题
3.3 半监督学习
- 定义:训练集同时包含有标记样本数据和未标记样本数据
3.4 强化学习
- 定义:实质是决策问题,可连续决策。其目标是为了获取最多的累计奖励
3.5 深度学习
- 得益于神经网络,神经网络在在图像与语音方向发展迅速
4 模型评估
按照数据集的目标值不同,可以把模型评估分为分类模型评估和回归模型评估
4.1 分类模型评估指标
- 准确率(预测正确的数占样本总数的比例)、精确率、召回率、F1-score、AUC指标等
4.2 回归模型评估指标
- 均方根误差
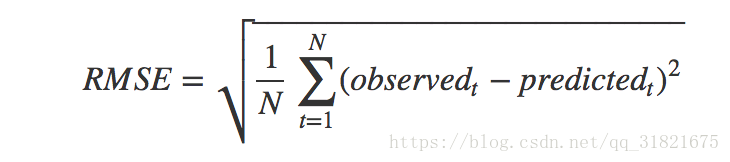
- observed:实际值
- predicted:预测值
- N:样本总数
- 其他指标:相对平方误差(RSE)、平均绝对误差(MAE)、相对绝对误差(RAE)
4.3 拟合
- 欠拟合:模型学习得太过粗糙,连训练集中的样本数据特征关系都没有学出来。即学习到的东西太少,模型太粗糙
- 过拟合:所建的机器学习模型或者是深度学习模型在训练样本中表现得过于优越,导致在测试数据集中表现不佳。即学习到的东西太多,特征太多不好泛化
------------恢复内容结束------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号