
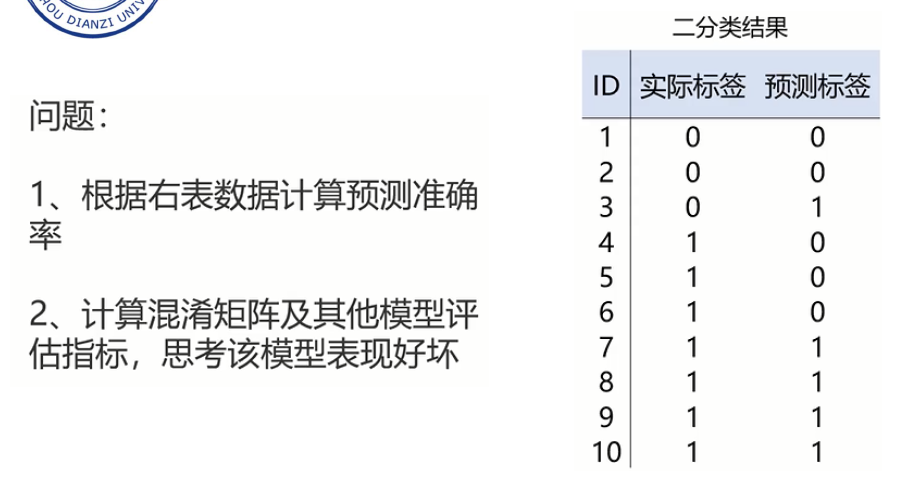
混淆矩阵
机器学习的结果要用不同于训练数据的测试数据进行评价,否则就没有意义
针对训练数据的100% 准确率是没有意义的……
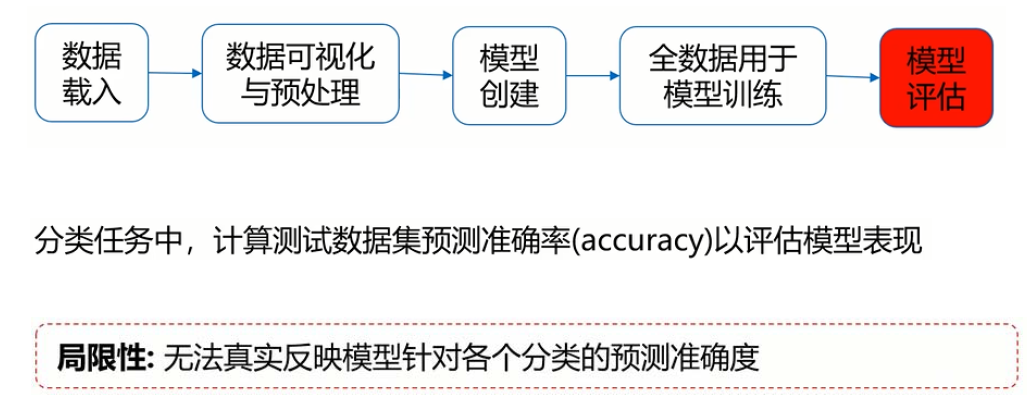
准确率
粗略的评价对象是准确率,旨在评价数据中分类正确的样本数与样本总数之比
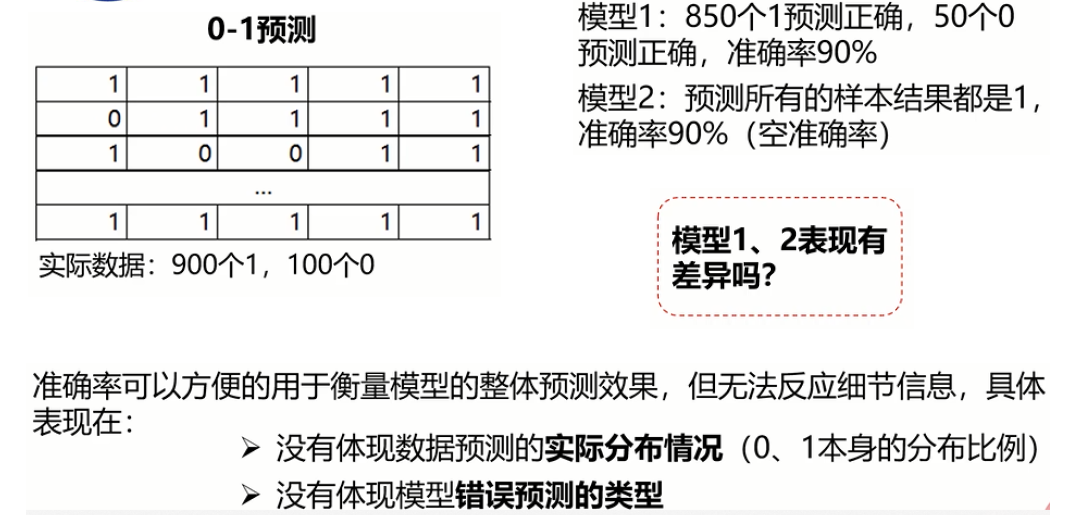
混淆矩阵

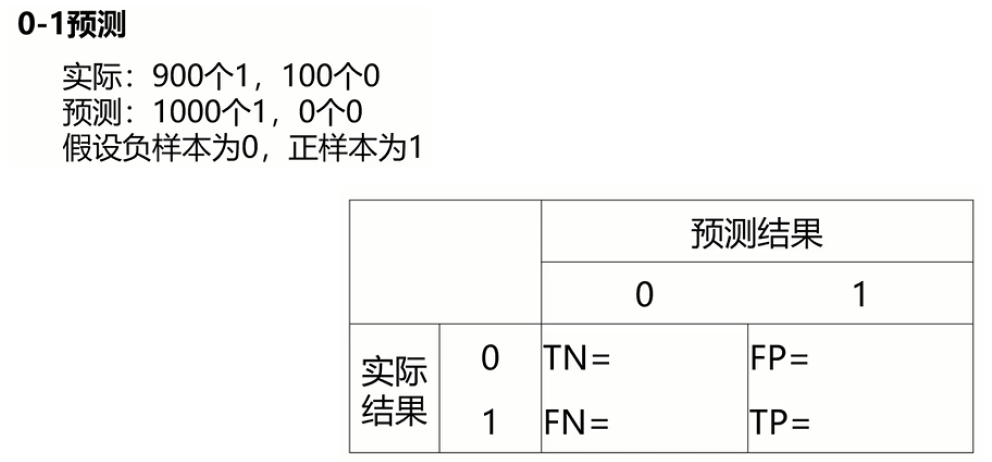
首先……简单起见,考虑二分类问题的评价方法。将符合设定的训练数据称为正例(Positive),不符合设定的数据称为负例(Negative)。
正确答案有正例和负例两种,分类器的输出也有正和负两种,组合起来就是四种
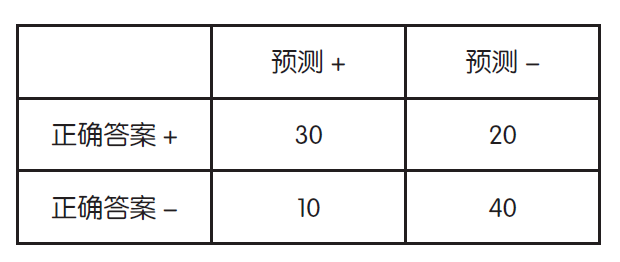

正确答案+ 为正例,正确答案- 为负例,将分类器判定为正的数据用预测+ 表示,判定为负的数据用预测- 来表示
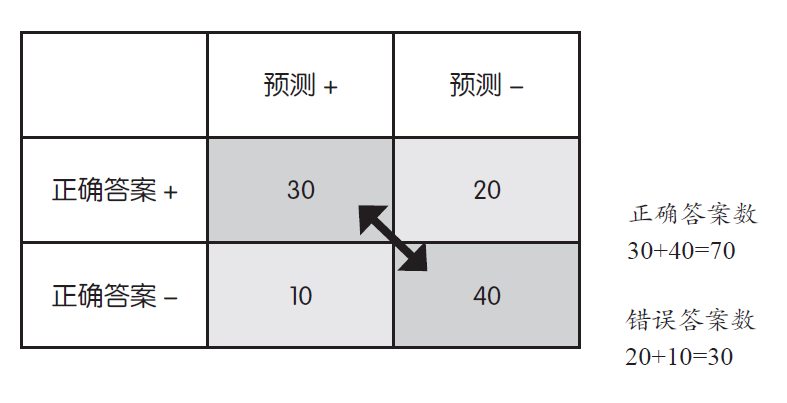
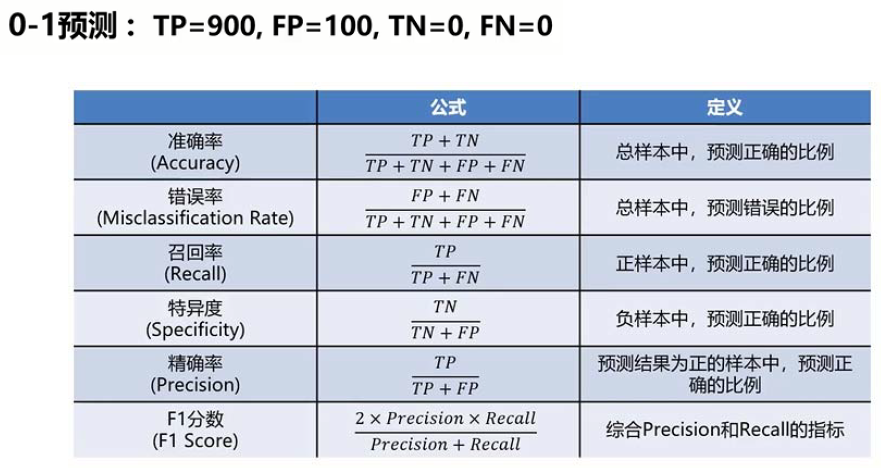
从此表得到的最简单的评价指标是分类器判定的正确答案数除以所有数据的正确答案数

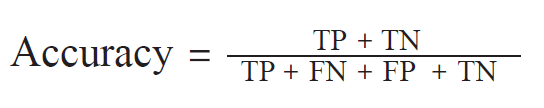
乍看之下这个评价似乎很充分,但对机器学习的评价不能止步于此
例如,特定疾病的诊断,请思考一下未患病者比患病者多得多的情况
如1000 人中只有1 人生病,假如使用全部判定为负例的随机分类器,准确率会怎么样?
0.999……
精确率
表示分类器判定为正确的可靠性
识别器正确判定为正的样本数与分类器预测为正的样本总数之比为精确率
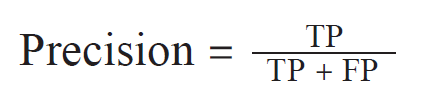
召回率
它是正确判定正例的指标。例如,根据召回率就可以知道在对象数据中患病者能够
被正确检出的概率用分类器正确判定为正的样本数除以正例数,便得到了召回率……
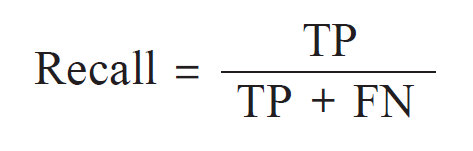
精确率和召回率之间存在着某种对立的关系
如果优先实现高召回率,稍微有点问题分类器就输出正会怎么样?
虽然漏掉患者的情况会变少,但感觉会使很多没有患病的人接受精密检查
- 将综合判断精确率和召回率的指标定义为F 值
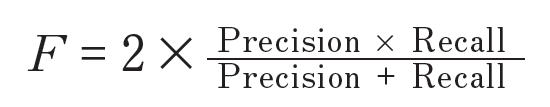
调和平均值

举例

 浙公网安备 33010602011771号
浙公网安备 33010602011771号