


算法描述
使用文本编辑的时候,常常会用到搜索功能,比如在一个文本"abcabcabcabcabcd"里查找"abcabcd"第一次出现的位置,这个功能如何用代码来解决呢?
最直观的办法就是暴力比较,从文本第一个字符开始逐个和要匹配的字符一一比较,遇到不相等的字符,则倒退从第二个字符重复上面的步骤:
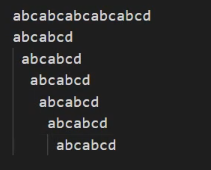
一共比较了六次。通过观察可以发现,有些比较是可以省掉的:
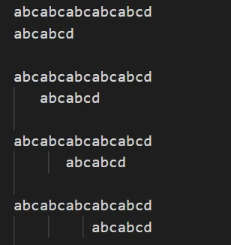
真正的有效比较一共只需要四次。
如何能高效的搜索,最好是遍历文本的次数只有一次。也就是假如有两个指针分别指向文本和匹配字符串,文本的指针最好是逐个前移,前面用的暴力匹配法就是当不匹配时把文本指针回退了,导致性能变低。所以需要考虑如何让被匹配字符串的指针能正确回退。比如下面这个过程:


当字母D与文本不匹配时,如何让被匹配字符串指针回退到C的位置重新开始比较。kmp算法就是解决这个问题的。
首先,要了解两个概念:"前缀"和"后缀"。 "前缀"指除了最后一个字符以外,一个字符串的全部头部组合;"后缀"指除了第一个字符以外,一个字符串的全部尾部组合。
"公共前后缀"就是"前缀"和"后缀"的最长的共有元素的长度,可以用一个数组来记录这个长度。kmp算法中这个数组叫部分匹配表。
假设部分匹配表用int *next表示,文本指针用idx1表示,被匹配的字符串指针用idx2表示,当在某一个位置出现不匹配时,就可以通过idx2=next[idx2-1]来重定位被匹配的字符串指针。而idx1一直是前进不用回退的。
代码实现
1 // s1是文本 s2是要匹配的内容 2 void KMPSearch(string s1, string s2) 3 { 4 int len1 = s1.length(); 5 int len2 = s2.length(); 6 7 // 计算公共前后缀 8 int *next = new int[len2]; 9 next[0] = 0; 10 for(int prefix = 0, suffix = 1; suffix < len2; ++suffix) 11 { 12 while(prefix > 0 && s2[prefix] != s2[suffix]) 13 { 14 prefix = next[prefix-1]; 15 } 16 if(s2[prefix] == s2[suffix]) 17 { 18 ++prefix; 19 } 20 next[suffix] = prefix; 21 } 22 23 // 开始匹配 24 for(int idx1 = 0, idx2 = 0; idx1 < len1; ++idx1) 25 { 26 while(idx2 > 0 && s1[idx1] != s2[idx2]) 27 { 28 idx2 = next[idx2 - 1]; 29 } 30 if(s1[idx1] == s2[idx2]) 31 { 32 ++idx2; 33 } 34 if(idx2 == len2) 35 { 36 std::cout<<"find result pos:"<<idx1 - len2 + 1<<std::endl; 37 return; 38 } 39 } 40 std::cout<<"find no result "<<std::endl; 41 return; 42 }
技术参考
2. 字符串匹配的KMP算法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号