2020 中青杯思路+代码
题目
自1990年12月19日上海证券交易所挂牌成立,经过30年的快速发展,中国证券市场已经具有相当规模,在多方面取得了举世瞩目的成就,对国民经济的资源配置起着日益重要的作用。截至2019年年底,上海和深圳两个证券交易所交易的股票约4000种。目前,市场交易制度、信息披露制度和证券法规等配套制度体系已经建立起来,投资者日趋理性和成熟,机构投资者迅速发展已具规模,政府对证券市场交易和上市公司主体行为的监管已见成效。
随着近年来我国资本市场的发展和证券交易规模的不断扩大,越来越多的资金投资于证券市场,与此同时市场价格的波动也十分剧烈,而波动作为证券市场中最本质的属性和特征,市场的波动对于人们风险收益的分析、股东权益最大化和监管层的有效监管都有着至关重要的作用,因此研究证券市场波动的规律性,分析引起市场波动的成因,是证券市场理论研究和实证分析的重要内容,也可以为投资者、监管者和上市公司等提供有迹可循的依据。
问题一:投资者购买目标指数中的资产,如果购买全部,从理论上讲能够完美跟踪指数,但是当指数成分股较多时,购买所有资产的成本过于高昂,同时也需要很高的管理成本,在实际中一般不可行。
(1)在附件数据的分析和处理的过程中,请对缺损数据进行补全。
(2)投资者购买成分股时,过多过少都不太合理。对于附件的成分股数据,请您通过建立模型,给出合理选股方案和投资组合方案。
问题二:尝试给出合理的评价指标来评估问题一中的模型,并给出您的分析结果。
问题三:通过附件股指数据和您补充的数据,对当前的指数波动和未来一年的指数波动进行合理建模,并给出您合理的投资建议和策略。
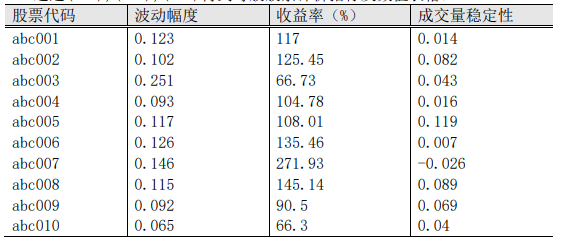
附件:十支股票的相关重要参数。
问题一
(1) 第一问就是插补,用Python的pandas构建时间索引,做线性插值就行。
for xsn in sn.sheet_names: datas = pd.read_excel('data.xlsx',sheet_name=xsn) m = list(datas.columns)[1:] tmp = pd.DataFrame({'date':pd.date_range(datas.iloc[0:,0].min(),datas.iloc[0:,0].max())}) datas['date']=pd.to_datetime(datas['date'],format='%Y/%m/%d') datas = pd.merge(datas,tmp,on='date',how='outer').sort_values('date') # 线性插值 for name in m: datas[name] = datas[name].interpolate(method='linear') # 对数据进行四舍五入 for name in m: datas[name]=[round(value,2) for value in datas[name]] datas['volume']=[round(value) for value in datas['volume']] # 重新排列索引 datas.index = range(len(datas)) # 转换时间类型为object datas['date'] = [x.strftime('%Y/%m/%d') for x in datas['date']] datas.to_excel(writer,sheet_name=xsn,index=False)
(2)可以用BRAR(人气意愿指标)来进行选股策略计算。
AR计算方法:
N日AR=(N日内(H-O)之和除以N日内(O-L)之和)*100
其中,H为当日最高价,L为当日最低价,O为当日收盘价,N为设定的时间参数,一般原始参数日设定为26日
BR计算方法:
N日BR=N日内(H-CY)之和除以N日内(CY-L)之和
其中,H为当日最高价,L为当日最低价,CY为前一交易日的收盘价,N为设定的时间参数,一般原始参数日设定为26日。
BRAR指标说明:
一般情况下,AR指标可以单独使用,BR指标则需与AR指标并用,才能发挥效用。
- BR<AR,且BR<100,可考虑逢低买进。
- BR<AR,而AR<50时,是买进信号;BR>AR,再转为BR<AR时,也可买进。
- AR和BR同时急速上升,意味着股价已近顶部,持股者应逢高卖出。
- BR急速上升,而AR处在盘整或小跌时,应逢高卖出。
- BR从高峰回跌,跌幅达1至2倍时,若AR无警戒讯号出现,应逢低买进。
百度百科:https://baike.baidu.com/item/arbr%E6%8C%87%E6%A0%87
相关文章:https://zhuanlan.zhihu.com/p/61488013
问题二
总的方法就是构建指标+层次分析/主成分分析/熵权法+聚类分析就行,我用的熵权法+聚类分析。
构建指标
构建三个指标,计算使用收盘价:
- 收益率(复合增长率):(最后一日价格 / 第一日价格)**(1/(最后一日时间 - 第一日时间))*100%
- 股价波动幅度:k =(最高价-最低价)/ 最低价,然后最sum(k)求平均值
- 交易量稳定性:sum(当前价格 - 前一日价格) / 时间长度
上面的数据都可以进行重采样,以周或者月为周期都可以。
for xsn in sn.sheet_names: # 索引值设置 datas = datas.set_index("date") close_datas = datas['close'] # 重采样 resampled = close_datas.resample('m').ohlc() # 波动幅度,月份 # (resampled.high-resampled.low)/resampled.low ripple = (resampled.high-resampled.low)/resampled.low ripple_datas.append(ripple.mean()) # close_datas.plot(figsize=(8,6)) # 收益率 # 最大收益率 (close_datas.max() - close_datas.min())/close_datas.min() # 总收益率 totol_growth = close_datas.iloc[-1]/close_datas.iloc[0] old_date = close_datas.index[0] new_date = close_datas.index[-1] # 复合收益率 complex_growth.append(totol_growth**(1.0/(new_date.year-old_date.year))*100) # 重采样 tmp_datas = datas['volume'] resampled1 = tmp_datas.resample('m').last() # 成交量稳定性 volume_datas.append(round(sum([(datas['volume'].iloc[i+1]-datas['volume'].iloc[i])/datas['volume'].iloc[i] for i in range(len(resampled1)-1)])/len(resampled1),3))
熵权法
指标表都有了,熵权法直接搞就行,这里用MATLAB做的,我试了试优劣解距离法,得到的结果和熵权法差不多。
%% 正向化处理 [n,m] = size(datas_matrix); % 正向化处理的数据所在列 Pos = [1,3]; % 指标类型:1:极小型,2:中间型,3:区间型 ch = [1,2]; % 循环处理每一列 for i = 1 : size(Pos,2) datas_matrix(:,Pos(i)) = Forward_processing(datas_matrix(:,Pos(i)),ch(i),Pos(i)) end %% 矩阵标准化 datas_S_matrix = datas_matrix ./ repmat(sum(datas_matrix.*datas_matrix) .^ 0.5, n, 1) %% model = ["abc001","abc002","abc003","abc004","abc005","abc006","abc007","abc008","abc009","abc010"]; %% 熵权法 p = datas_S_matrix./sum(datas_S_matrix); k = 1/log(n); r = zeros(n,m); for i = 1:n for j = 1:m if p(i,j) == 0 r(i,j) = 0; else r(i,j) = log(p(i,j)); end end end e = -k*sum(p.*r,1); d = ones(1,m)-e weight = d./sum(d) score = sum(weight.*datas_S_matrix,2); results1 = 0 + (100-0)/(max(score)-min(score)).*(score - min(score)); [sorted_score,index] = sort(results1 ,'descend'); rivers1 = []; for i = 1:n rivers1 = [rivers1;model(index(i))]; end s = [rivers1,sorted_score]
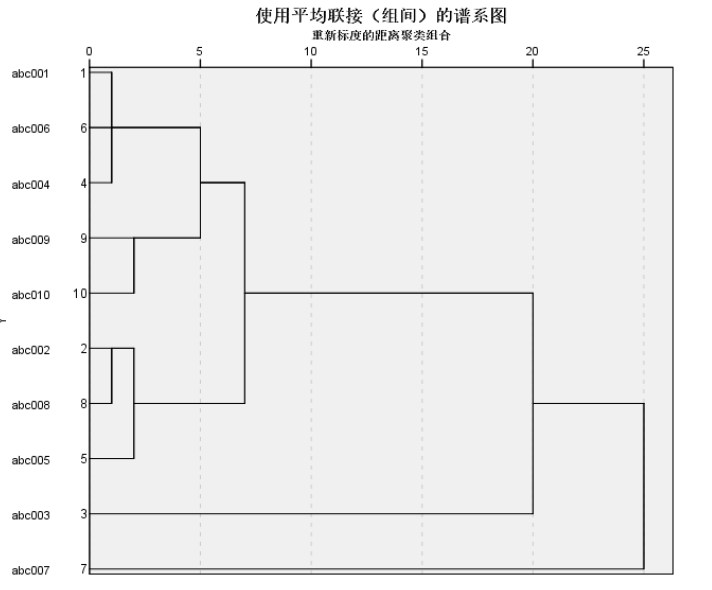
聚类分析
用SPSS做聚类分析
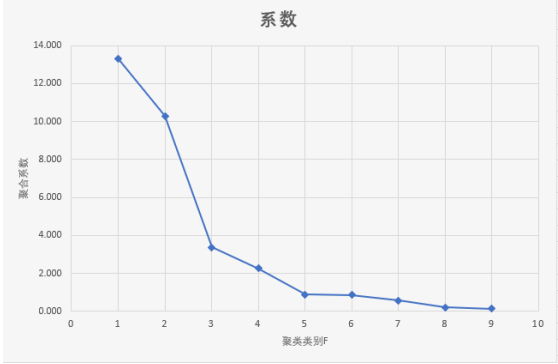
可以看到,F=5,折线变得平缓,所以聚类数为5,再结合谱系图,就能得到分类。
问题三
构建ARIMA时间序列预测模型就行,Python有ARIMA模型的包。
# 重采样,以周为单位 stock_week = datas['close'].resample('W-MON').mean() stock_train = stock_week['2019':'2020'] # stock_train.plot(figsize=(12,8)) # plt.legend(bbox_to_anchor=(1.25,0.5)) # sns.despine() # 一阶差分,平稳性较差 stock_diff=stock_train.diff() stock_diff=stock_diff.dropna() # acf,确定q值=1 acf = plot_acf(stock_diff,lags=20) # pacf,确定p值=1 pacf = plot_pacf(stock_diff,lags=20) # 训练模型 model=ARIMA(stock_train,order=(1,1,1),freq='W-MON') result=model.fit() pred=result.predict('20191111','20200330',dynamic=True,typ='levels') plt.figure(figsize=(6,6)) plt.xticks(rotation=45) plt.plot(pred) plt.plot(stock_train)
代码可以得到趋势预测图,未来一年预测数据调用result.forecast就行。
公众号发送“2020中青杯代码”,自动获取完整代码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号