AI训练过程
conda虚拟环境安装以及数据标注软件安装

创建虚拟环境
conda create -n 名称 python==3.8.5
激活环境
conda activate 名称
列出所有环境
conda info --envs 或 conda env list
退出虚拟环境
conda deactivate
删除环境
conda env remove --name 名称
下载资源包
pip install 名称
如果慢的情况下,可用镜像源
pip install package_name -i https://mirrors.aliyun.com/pypi
这些常用的国内的镜像包括:
阿里云:https://mirrors.aliyun.com/pypi
清华大学:https://pypi.tuna.tsinghua.edu.cn/simple
中国科技大学:https://pypi.mirrors.ustc.edu.cn/simple/
豆瓣(Douban):https://pypi.douban.com/simple/
https://pypi.doubanio.com/simple
店铺牌匾识别系统需求文档
一、概述(作为了解的)
项目背景:随着店铺数量的不断增加,人工审核牌匹信息的工作量是巨大的而且容易出错。
为了提高效率和准确性,引入人工智能技术进行自动识别和分类。
目标:开发一个基于人工智能的牌匾识别系统,能够自动识别和分类不同店铺的牌图片,提取关键信息(如:店铺名称提取、电话、营业时间、商场招牌名称、自适应判断、名称判断相关性判断)。
二、项目目标
主要目标:
1.自动识别牌匾上的文字。
2.提取并存储关键信息(如:店铺名称提取、电话、营业时间、商场招牌名称、自适应判断、名称判断相关性判断)。
3.生成结构化数据,便于后续处理和分析。
次要目标:
1.提供友好的用户界面,方便操作。
2.支持多语言的识别。
3.提供错误纠正和反馈机制。
三、功能需求
核心功能:
图片上传:支持用户上传牌匾图片。
自动识别:自动识别图片中的文字,并提取关键信息。
信息展示:在界面上展示识别出的信息,供用户确认和修正,信息存储:将识别出的信息存储到数据库中。
错误反馈:提供错误反馈机制,用户可以手动纠正识别错误。
扩展功能:
批量处理:支持批量上传和处理图片。
多语言支持:支持多种语言的识别和处理。
历史记录:记录每次识别的操作日志,便于追踪和审计。
四、数据需求
数据来源:
从公开数据集中获取样本数据(可花钱买)
从实际业务中收集牌匾图片数据。
数据预处理:
清洗和标注数据
数据格式:
图片格式:jpg、jpeg、png
标注格式:JSON、XML
五、验收标准
功能验收:
系统能够正确识别并提取牌匾上的文字。
系统能够处理多种语言的牌匾图片。
系统能够批量处理图片。
系统能够生成结构化数据,并存储在数据库中。
性能验收:
识别的准确率:95%以上。
处理速度:每分钟处理100图片以上。
用户体验:
界面优化,操作简单。
错误反馈机制完善,用户可以手动纠正错误。
六、项目进度
阶段规划:
需求分析:1周
数据准备:2周
模型训练:4周
系统开发:8周
系统测试:2周
上线部署:1周
店铺牌匾识别系统-标注规则
备注:判断某一个东西的逻辑是:先排除
一、品牌词判断(判断一个品牌词是不是一个真正的品牌)
品牌词判断可根据招牌特征,是否 是连锁,是否加入大众点评。
第一步:首先,应该判断给出的示例图片中的门店名称是否与品牌词对应。不对应,则当前图片为无效数据,不可参考,查看其他示例图片。
第二步:根据品牌词、参数图片,满足以下几点中的任意一个,判为“不是品牌”。
1.「无专名」是地方小吃类的词,如鸡蛋灌饼、老妈蹄花、牛肉板面、煎饼果子、一元一串等,这一类词一定不是品牌;
2.「无专名」的菜品类、经营范围类的词,如:早点摊、小酒馆、麻辣龙虾、蔬菜水果等,这一类词一定不是品牌;
3.「无特色的专名」,如:“诚信”、“阳光”、“好吃”、“实惠”、“电白”等之类常见的形容词作为专名,这一类词一定不是品牌;
第三步:若不满足第二步的任何条件,再根掘参考招牌图片,满足1-3个条件中的任意一个,判为“是品牌”
1.招牌图片上有明确的R标和TM标识。
2.招牌有“xx店”标识的分店
3.给定的参考图中,有两张有效的参考图中的招牌是一模一样的,则可以直接认为是连锁品牌
第四步:若给的参考图多于一张,并且每一张品牌门店招牌图的牌匾都不相同,则可以认为当前品牌为“非品牌词”。
第五步:如果给定的有效招牌只有一张,则可以查询大众点评,大众点评查询后有超过一家的门店,发现查询结果满足下面1和2任意一种就属于品牌。
1.名称相同,而且首图或者logo相同
2.名称相同,而且门店招牌特征一致
第六步:如果大众点评查询后只有一家门店或查不到,则参考有无公众号判断是否是品牌。
二、品牌分类判断(判断品牌所属类型)
判断品牌属于“父品牌”、“子品牌”、“独立品牌”
1.百度检索对应的品牌词的专名,查询是否有官,查询不到对应官网,可以直接认为是独立品牌。
2.有官网,根据官网中的集团介绍,品牌介绍等等入口,判断当前品牌词属于父品牌还是子品力牌。
三、品牌词名称规范(根据招牌提取品牌词主名称)
1.根据POI招牌,规则提取品牌词名称(专名+通名),招牌无通名可以不提取通名,但必须有专名。
2.5个示例POI,至少2张门脸图、招牌,设计一致,方可提取对应品牌词名称。
3.若5个示例都不一致,则无需提取,备注:无法规范。
四、电话
规则一:如果店铺只有手机号,则只需填写手机号。
规则二:如果一个店铺有多个手机号或座机,必须将此店铺的所有座机和手机号全部填写。
前置的需求文档+标注规则都结束后
数据标注
备注:不是ai训练师要干的事情,但是要懂,因为后面要涉及到验收(质检)的操作。
数据标注分类:文本标注、图像标注、语音标注数据标注工具:
图像标注:labelimg、labelme
1.1 labelimg工具介绍

快速截图快捷键:w
保存当前操作:s
VOC:xml
YoLo:txt
mL:json
1.2 有关于标注的目录结构
外层文件夹:dianpu
内层:image:数据集
label:标注
数据源问题
问题点:当数据集中的某些“图片“可能不符合要求(当添加到labelimg中,无效)【文件名称或者后缀名】不符合要求,我们要统一文件名和后缀名该怎么办?
利用代码统一生成文件名和后缀格式
图片转换成jpg格式
若提示没有CV2,那么就运行:
安装cv2:pip install opencv-python
import os
import os.path as osp
import numpy as np
import cv2
def cv_imread_chinese(file_path):
cv_img = cv2.imdecode(np.fromfile(file_path, dtype=np.uint8), cv2.IMREAD_COLOR)
return cv_img
def folder_rename(src_folder_path, target_folder_path):
os.makedirs(target_folder_path, exist_ok=True)
file_names = os.listdir(src_folder_path)
for i, name in enumerate(file_names):
try:
print("{}:{}".format(i, name))
src_name = osp.join(src_folder_path, name)
src_img = cv_imread_chinese(src_name)
target_path = osp.join(target_folder_path, "yolo_data_{}.jpg".format(i))
cv2.imwrite(target_path, src_img)
except Exception as e:
print(f"处理文件 {name} 时出错: {e}")
if __name__ == '__main__':
folder_rename("demo/images/test", "newdemo/img")
xml格式转成txt
若提示没有CV2,那么就运行:
安装cv2:pip install opencv-python
import xml.etree.ElementTree as ET
import os
def convert_xml_to_txt(xml_file, class_mapping):
# 解析 XML 文件
tree = ET.parse(xml_file)
root = tree.getroot()
# 获取图像的宽度和高度
size = root.find('size')
img_width = int(size.find('width').text)
img_height = int(size.find('height').text)
txt_lines = []
# 遍历所有的对象
for obj in root.findall('object'):
# 获取类别名称
class_name = obj.find('name').text
if class_name not in class_mapping:
continue
class_id = class_mapping[class_name]
# 获取边界框坐标
bbox = obj.find('bndbox')
xmin = float(bbox.find('xmin').text)
ymin = float(bbox.find('ymin').text)
xmax = float(bbox.find('xmax').text)
ymax = float(bbox.find('ymax').text)
# 计算 YOLO 格式的坐标
x_center = ((xmin + xmax) / 2) / img_width
y_center = ((ymin + ymax) / 2) / img_height
width = (xmax - xmin) / img_width
height = (ymax - ymin) / img_height
# 添加到 TXT 文件的行中
txt_lines.append(f"{class_id} {x_center:.6f} {y_center:.6f} {width:.6f} {height:.6f}")
return txt_lines
def convert_folder(xml_folder, txt_folder, class_mapping):
# 创建 TXT 文件保存的文件夹
if not os.path.exists(txt_folder):
os.makedirs(txt_folder)
# 遍历 XML 文件夹中的所有文件
for xml_file in os.listdir(xml_folder):
if xml_file.endswith('.xml'):
xml_path = os.path.join(xml_folder, xml_file)
# 生成对应的 TXT 文件路径
txt_file = os.path.splitext(xml_file)[0] + '.txt'
txt_path = os.path.join(txt_folder, txt_file)
# 转换 XML 文件
txt_lines = convert_xml_to_txt(xml_path, class_mapping)
# 写入 TXT 文件
with open(txt_path, 'w') as f:
for line in txt_lines:
f.write(line + '\n')
if __name__ == "__main__":
# 定义类别映射,根据实际情况修改
class_mapping = {
"cat": 0,
"dog": 1
}
# 这里修改为实际存放 XML 文件的文件夹路径
xml_folder = "newdemo/img"
# 这里修改为实际要存放转换后 TXT 文件的文件夹路径
txt_folder = "demo"
convert_folder(xml_folder, txt_folder, class_mapping)
验收和质检
可视化检查--抽样检查
抽样检查==》单个验收
# 单张可视化图片查看
import cv2
import xml.etree.ElementTree as ET
def visualize_annotations(image_path, annotation_path):
image = cv2.imread(image_path)
tree = ET.parse(annotation_path)
root = tree.getroot()
for obj in root.findall('object'):
bbox = obj.find('bndbox')
xmin = int(bbox.find('xmin').text)
ymin = int(bbox.find('ymin').text)
xmax = int(bbox.find('xmax').text)
ymax = int(bbox.find('ymax').text)
label = obj.find('name').text
color = (0, 255, 0) # Green color for bounding box
thickness = 2
cv2.rectangle(image, (xmin, ymin), (xmax, ymax), color, thickness)
cv2.putText(image, label, (xmin, ymin - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, color, thickness)
cv2.imshow('Annotated Image', image)
cv2.waitKey(0)
cv2.destroyAllwindows()
if __name__ == '__main__':
visualize_annotations('./newdemo/yolo_data_1.jpg', './label/yolo_data_1.xml')
抽样检查==》全部验收
# 全部可视化图片查看
import cv2
import xml.etree.ElementTree as ET
import os
def visualize_all_annotations(image_dir, annotation_dir):
for filename in os.listdir(image_dir):
if filename.endswith('.jpg') or filename.endswith('.png'):
image_path =os.path.join(image_dir, filename)
annotation_filename=os.path.splitext(filename)[0]+'.xml'
annotation_path = os.path.join(annotation_dir, annotation_filename)
if os.path.exists(annotation_path):
visualize_annotations(image_path, annotation_path)
else:
print(f"No annotation found for {filename}")
def visualize_annotations(image_path,annotation_path):
image = cv2.imread(image_path)
tree = ET.parse(annotation_path)
root = tree.getroot()
for obj in root.findall('object'):
bbox = obj.find('bndbox')
xmin = int(bbox.find('xmin').text)
ymin = int(bbox.find('ymin').text)
xmax = int(bbox.find('xmax').text)
ymax = int(bbox.find('ymax').text)
label = obj.find('name').text
color = (0, 255, 0) # Green color for bounding box
thickness = 2
cv2.rectangle(image, (xmin, ymin), (xmax, ymax), color, thickness)
cv2.putText(image, label, (xmin, ymin - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, color, thickness)
cv2.imshow('Annotated Image', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
if __name__ == '__main__':
image_directory='./newdemo'
annotation_directory='./label'
visualize_all_annotations(image_directory,annotation_directory)
备注:可视化检查和labelimg工具检查的区别:
如果有覆盖的情况:labelimg很难直观看到,可视化工具会让有更加直观的标注标签显示,labelimg没有
总结:可视化工具质检销量超过labelimg工具质检。
目标检测
连接服务器
基于算力服务器训练模型
将训练的项目导入服务器中
如将项目导入data目录下
conda activate lisi
安装过程
1.进入到data项目目录下,创建虚拟环境
conda createn lisi(名称) python==3.8.5
2.进入虚拟环境
conda activate lisi
3.安装GPU
conda install pytorch==1.10.0 torchvision torchaudio cudatoolkit=11.3
4.安装项目所需依赖
pip install -v -e
5.安装更新:torch torchvision
pip install --upgrade torch torchvision
例子(目标检测:yolov8)
搭建环境
一、创建虚拟环境
第一步:通过终端命令进入到【yolov8项目】中
第二步:创建标注工具环境
conda create -n demo8 python==3.8.5
第三步:进入环境
conda activate demo8
二、配置环境
流程一:配置环境
1.把【yolov8】项目拖到【pycharm】工具中在
【Pycharm】工具,右下角点击
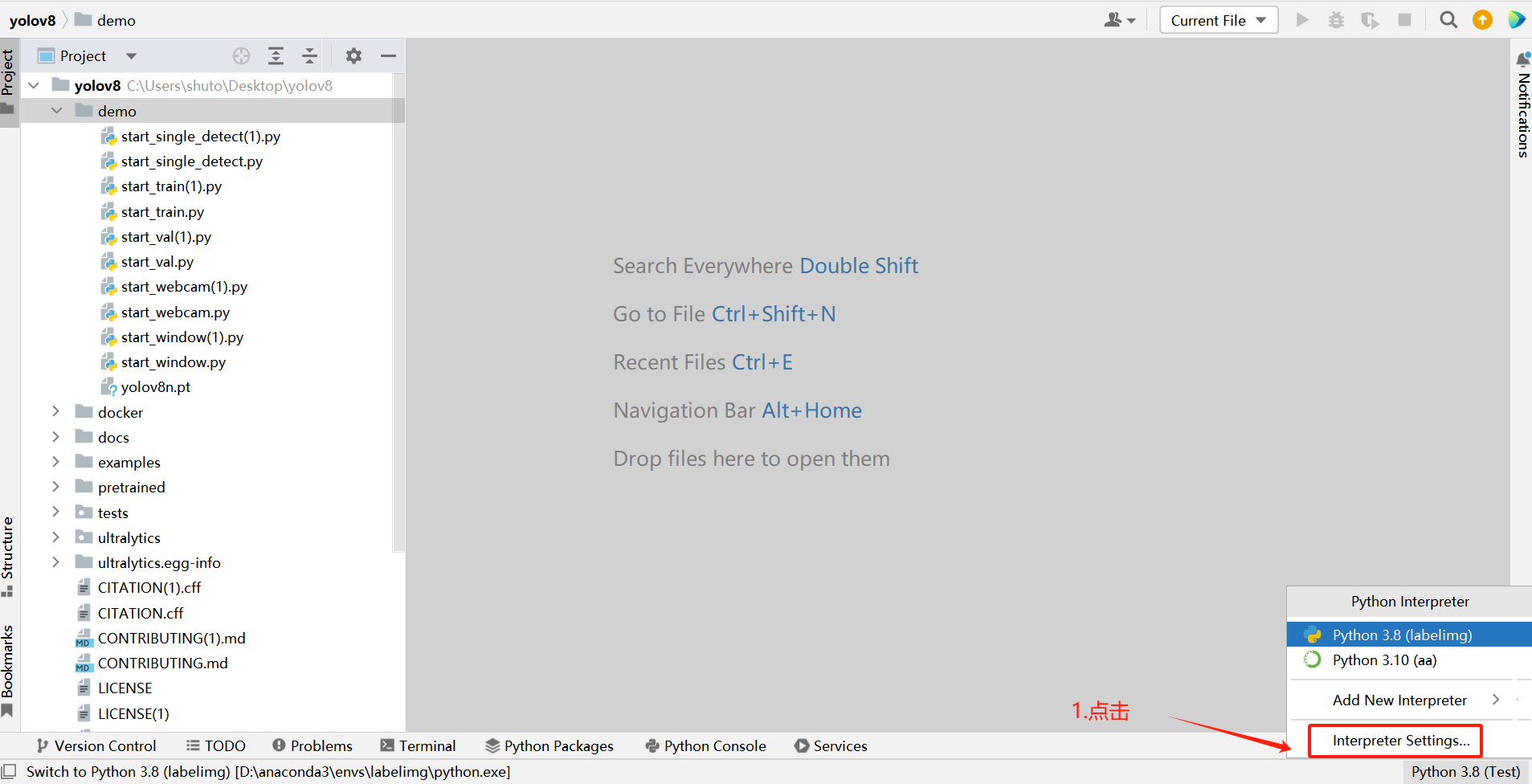
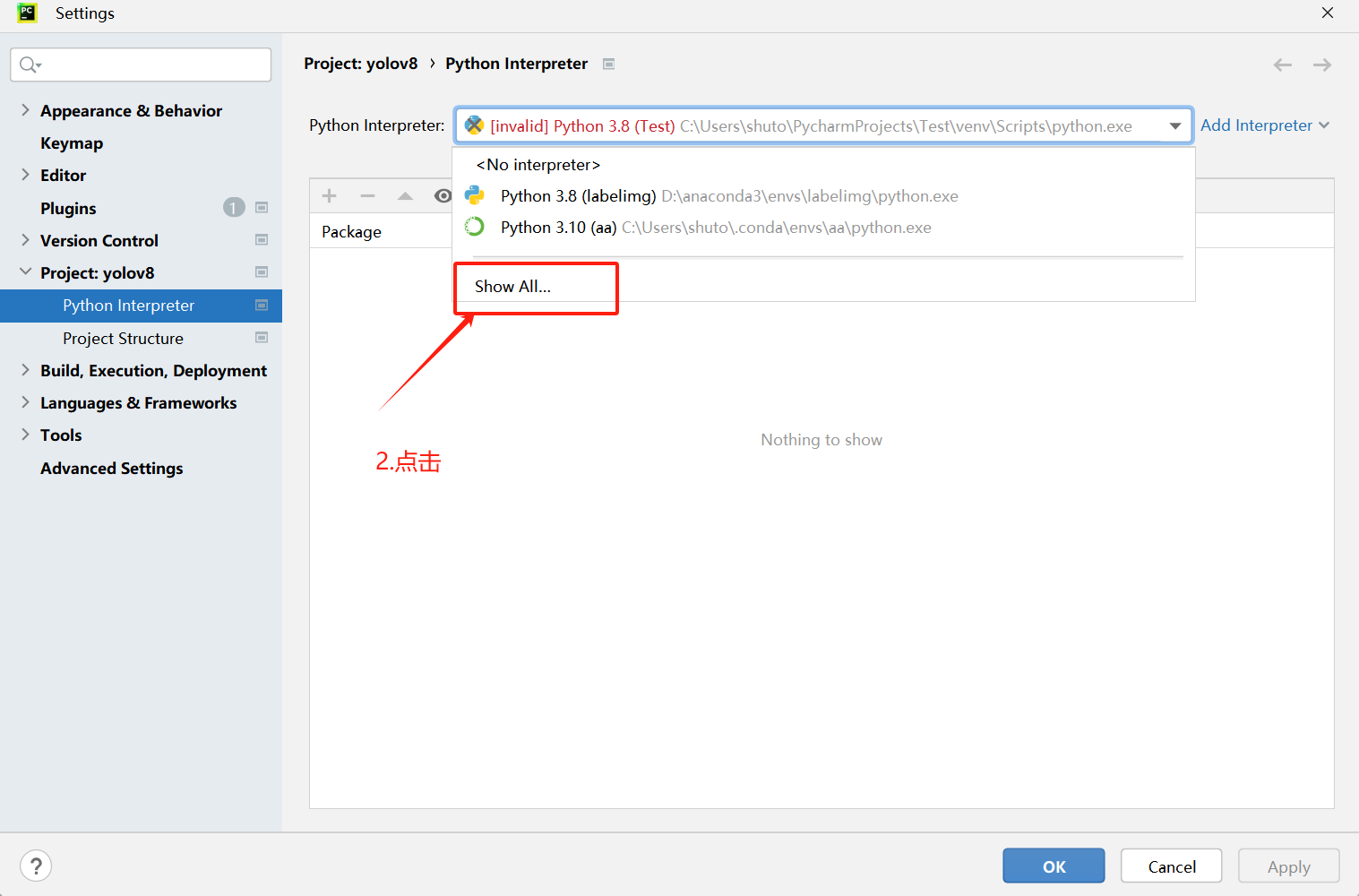
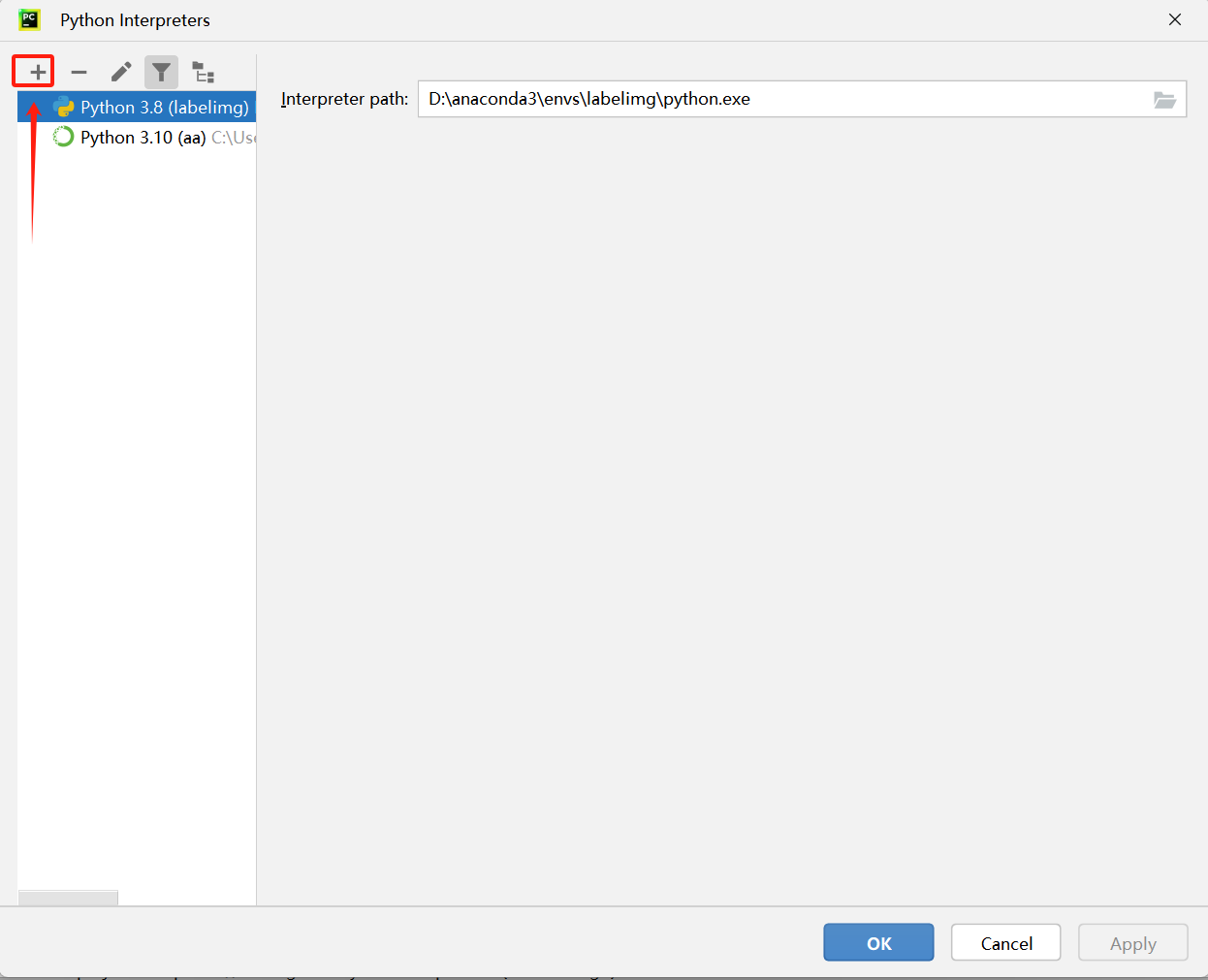
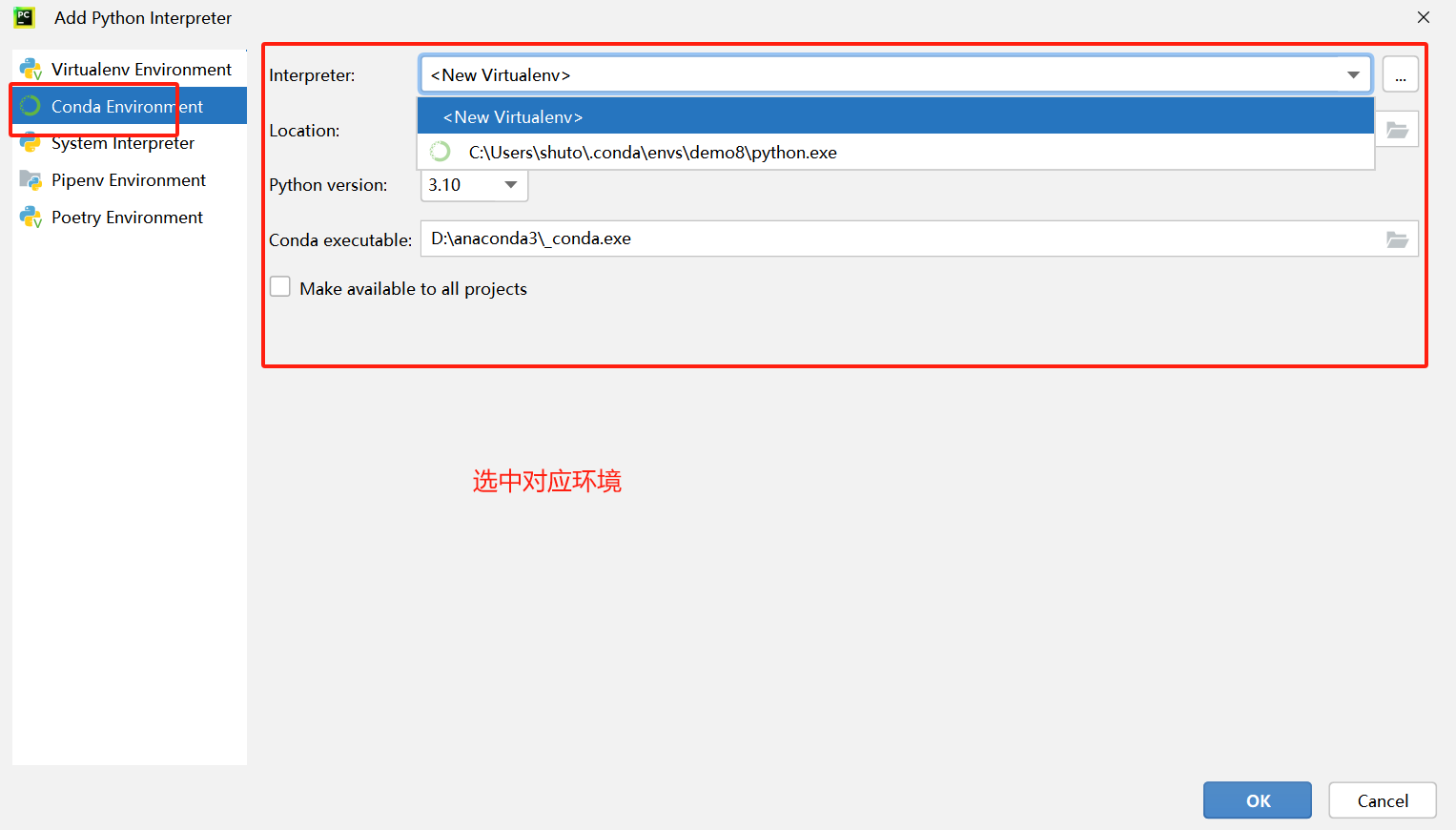
三、安装依赖
以上配置完毕后,接着要安装依赖:打开终端**
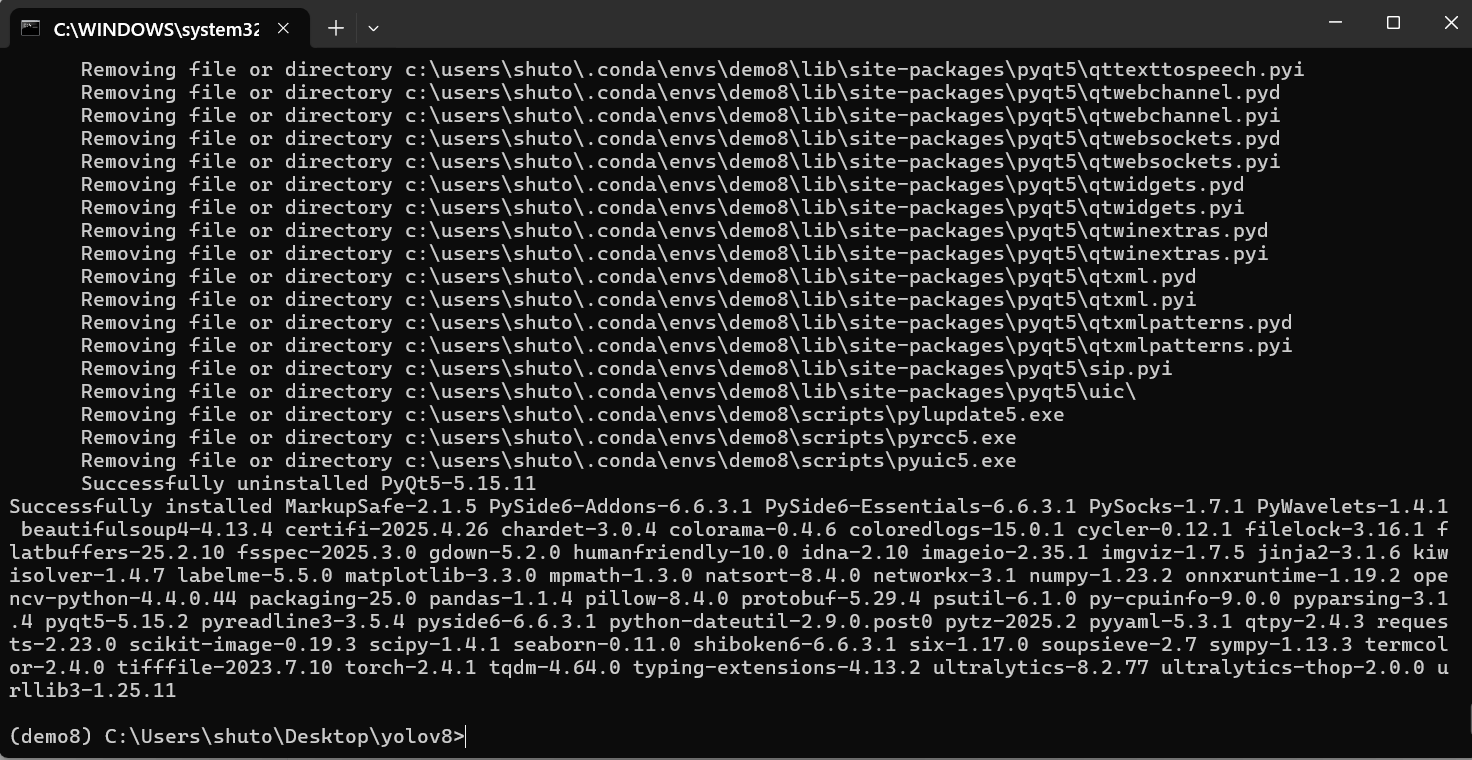
pip install -v -e .
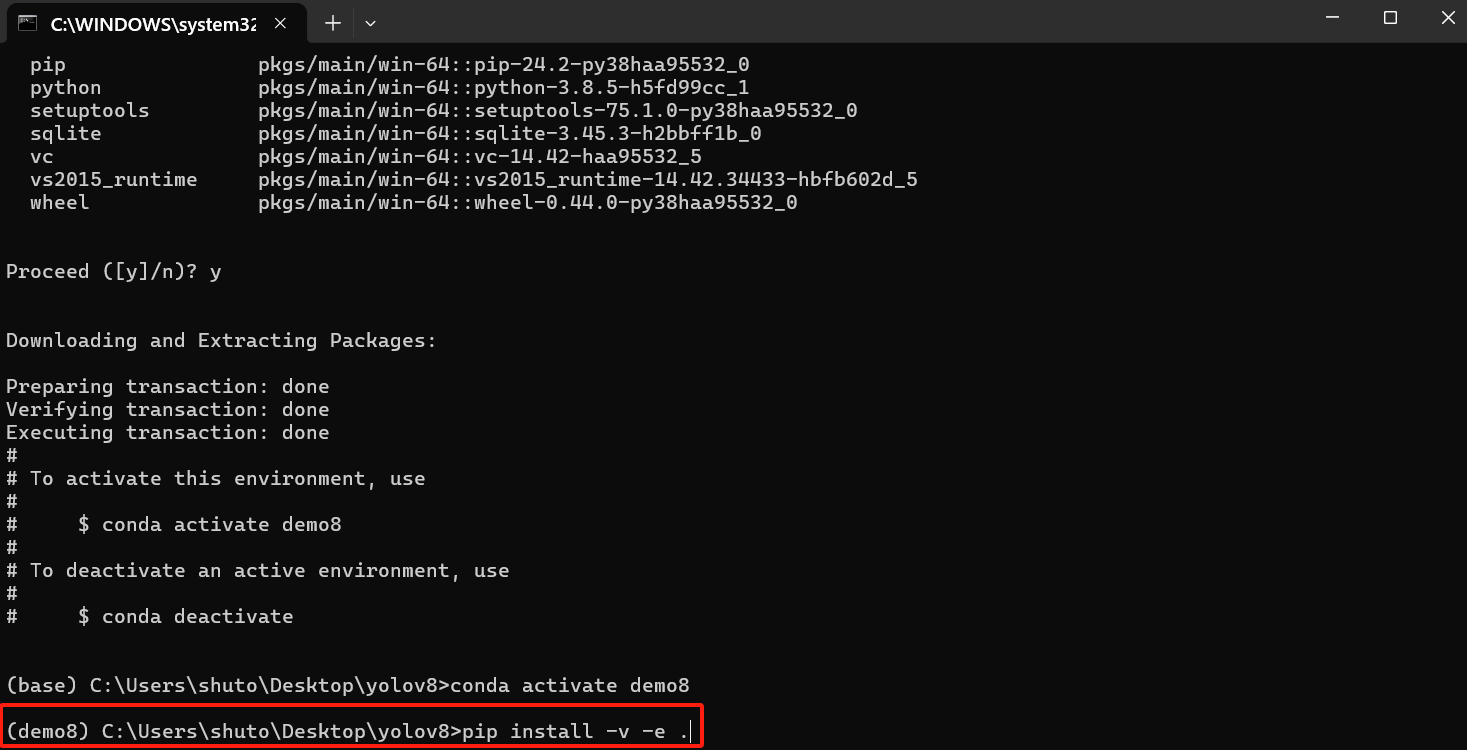
下载完成后,弹窗可关闭
四、测试配置环境是否正常
验证搭建的环境有没有问题,在pycharm终端输入以下命令
yolo task=detect mode=predict model=pretrained/yolov8l.pt source=ultralytics/assets device=CPU
备注:
task=detect:执行目标检测任务。
mode=predict:正确指定推理模式。(mode=train:训练模式(模型训练),mode=val:验证模式(模型性能评估),mode=predict:推理模式(对新数据进行预测),mode=export:导出模式(将模型转换为其他格式,如 ONNX、TensorRT,mode=test:测试模型)
model=pretrained/yolov8l.pt:使用预训练的 YOLOv8 Large 模型。
source=ultralytics/assets:输入数据路径(官方示例资源)。
device=CPU:在 CPU 上运行推理
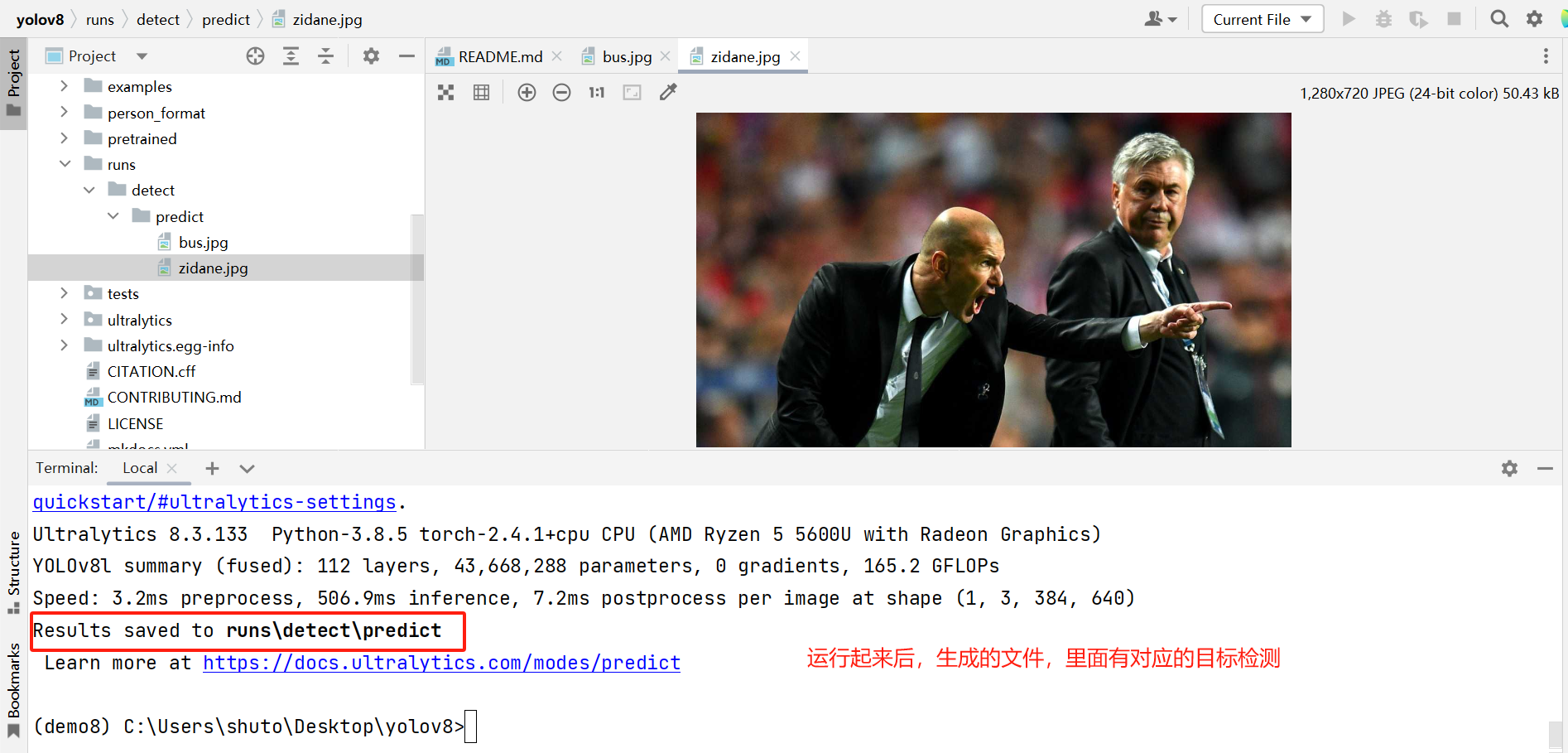
项目目录结构说明
训练模型默认参数
C:\Users\shuto\Desktop\yolov8\ultralytics\cfg\default.yaml
基础模型
C:\Users\shuto\Desktop\yolov8\pretrained\xx.pt
训练集的目录
C:/Users/shuto/Desktop/yolov8/ultralytics/cfg/datasets
训练的过程
模型预测
yolo task=detect mode=predict model=pretrained/yolov8l.pt source=ultralytics/assets device=CPU
模型训练
yolo task=detect mode=train model=pretrained/yolov8l.pt data=ultralytics/cfg/datasets/A_my_data.yaml batch=32 epochs=100 imgsz=100 workers=0 device=CPU cache=True
模型验证
yolo task=detect mode=val model=pretrained/yolov8l.pt data=ultralytics/cfg/datasets/A_my_data.yaml batch=32 device=CPU plots=True
模型测试
yolo task=detect mode=predict model=pretrained/yolov8l.pt source=ultralytics/images/test device=CPU
训练结果
一、weights文件夹:模型权重文件
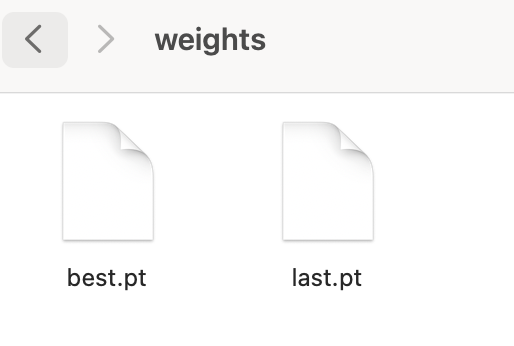
best.pt是整个训练过程中,性能最好的模型权重文件。最终我们要的就是这个文件。我们可以拿它进行实际业务的AI预测或继续微调。
last.pt是最后一次训练的模型权重文件。一般来说,训练越久效果也越好。但有时它也会和best.pt不一致。这意味着最后一次训练的结果,并不是最好的。
二、results.png:训练总图要略
这张图片包含训练过程中的各种评估指标,比如损失函数、精度、召回率、mAP等的图表绘制。这个图表可以直观地看到模型训练过程中性能的变化情况。
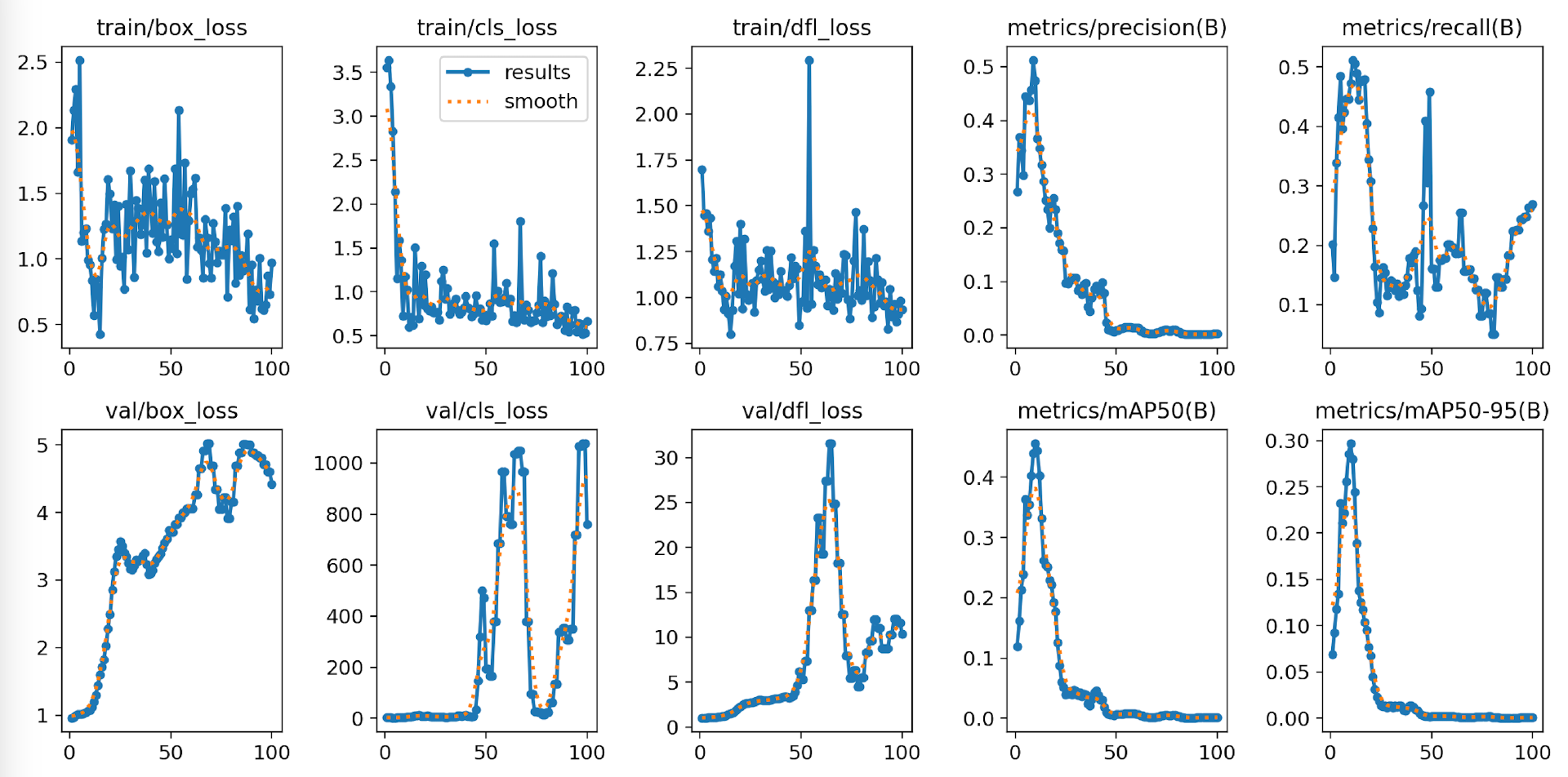
loss系列:
train/box_loss和val/box_loss
train/cls_loss和val/cls_loss
train/dfl_loss和val/dfl_loss
这几组前面的train表示训练集,val是验证集。训练集是用于训练学习的,相当于书本的例题。而验证集则用于考试,相当于试卷的试题。学得好不一定就考得好,主要还得看考题是不是有关联性。不过他们更重要的相同点,好像在于都有loss。
loss是算法中一个常见的概念。翻译成“损失”这个词,其实很形象。生活中,对于能量转化,我们常常用到损失。我们说100单位的电能转化为80单位的动能,能量损失了20%。如果实现了百分百转化,那么损失就是0。
应用到算法中也一样。在有监督训练中,我们是先标记再训练。
对于训练集和验证集,AI本身是知道这个区域标的是什么,位置在哪儿。因此,它会先猜测结论,然后跟正确答案做对比。它的猜测行为称为“推理”或者“预测”。它自己的推理结果和人工标记的答案之间的差异,称为“损失”。那么,损失越小越好,损失为0则说明AI的推理和正确答案之间没有差异,即预测100%命中。
我们看下图,这次训练过程也是如此。这几个train系列的loss都是降低的,X轴表示训练轮次,Y轴表示损失的值。
我们看到loss的值都是降低,这说明很好。但是第一个box_loss好像还有下降的趋势。但是中间的cls_loss在50轮时就已经趋于稳定了,而dfl_loss好像在75轮附近才慢慢稳定。

在看这个图,几乎都没有明显的下降趋势和稳定趋势,就证明还需要进行更多轮训练。
这些指标都代表什么?有什么意义呢?
box_loss 边界框损失:衡量画框
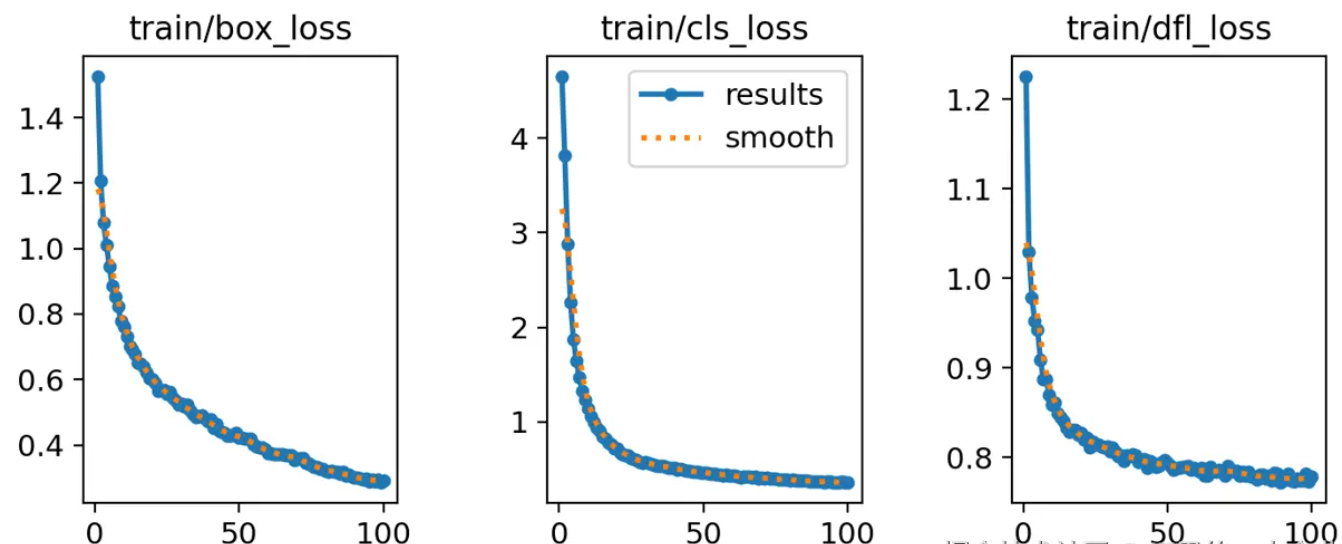
box_loss全称是bounding box loss,表示边界框损失。它表明AI通过训练和学习之后,对于边界框的预测和标准答案之间的损失。
正常情况下,随着训练的进行,损失是越降越低的。如果它是长期忽高忽低,或者一直不明显收敛,那说明训练存在问题。如果box_loss的损失不断降低,而后持续稳定,则说明训练没有问题,也没有必要再投入资源训练了。
但是box_loss表现优秀,仅仅说明它对物体区域(画框)的识别情况。就算这一项100分,整体效果也不一定就好。因为光会画框意义不大,我们还要知道框里的物体是什么。
于是就引入另一个cls_loss指标。
cls_loss 分类损失:判断框里的物体
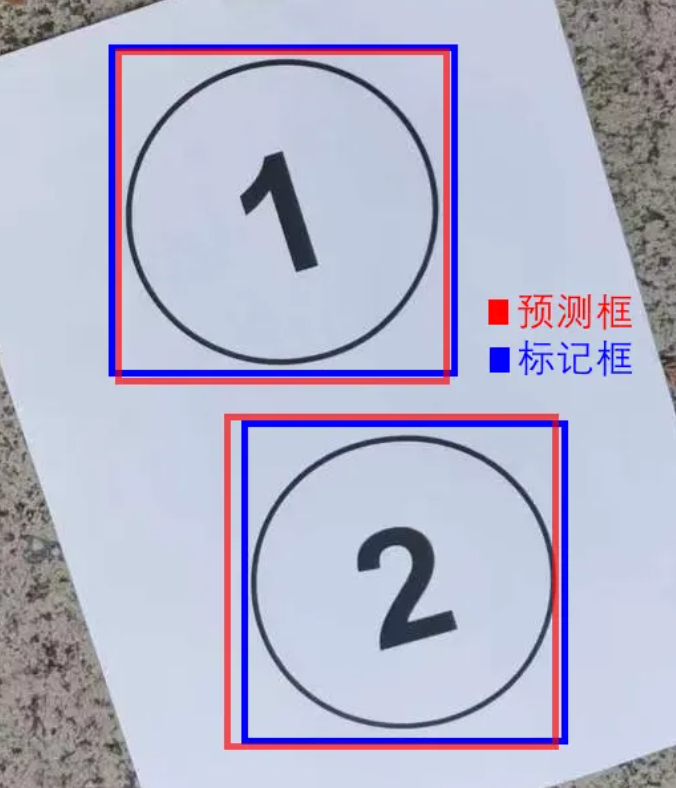
它叫分类损失,全称为classification loss。它衡量的是预测类别和真实类别之间的差异。
我们看下面的图,它不但框出了物体。而且标注出了这个框里是人,那个框里是车,哪个是细菌,哪个是垃圾。

对于框里物体是什么的评价,就用到了cls_loss指标。从这里可以看出,其实目标检测技术,已经包含了图片分类的技术。图片分类很基础。
如果你认为它仅凭哪个区域、什么物体两项指标就结束了,那么确实是小看YOLO算法了。它还有第三项细化指标dfl_loss。
dfl_loss 分布式焦点损失:精益求精
dfl_loss全称是Distribution Focal Loss,中文名称为“分布式焦点损失”。 它辅助box_loss,提供额外的信息,通过对边界框位置的概率分布进行优化,进一步提高模型对边界框位置的细化和准确度。
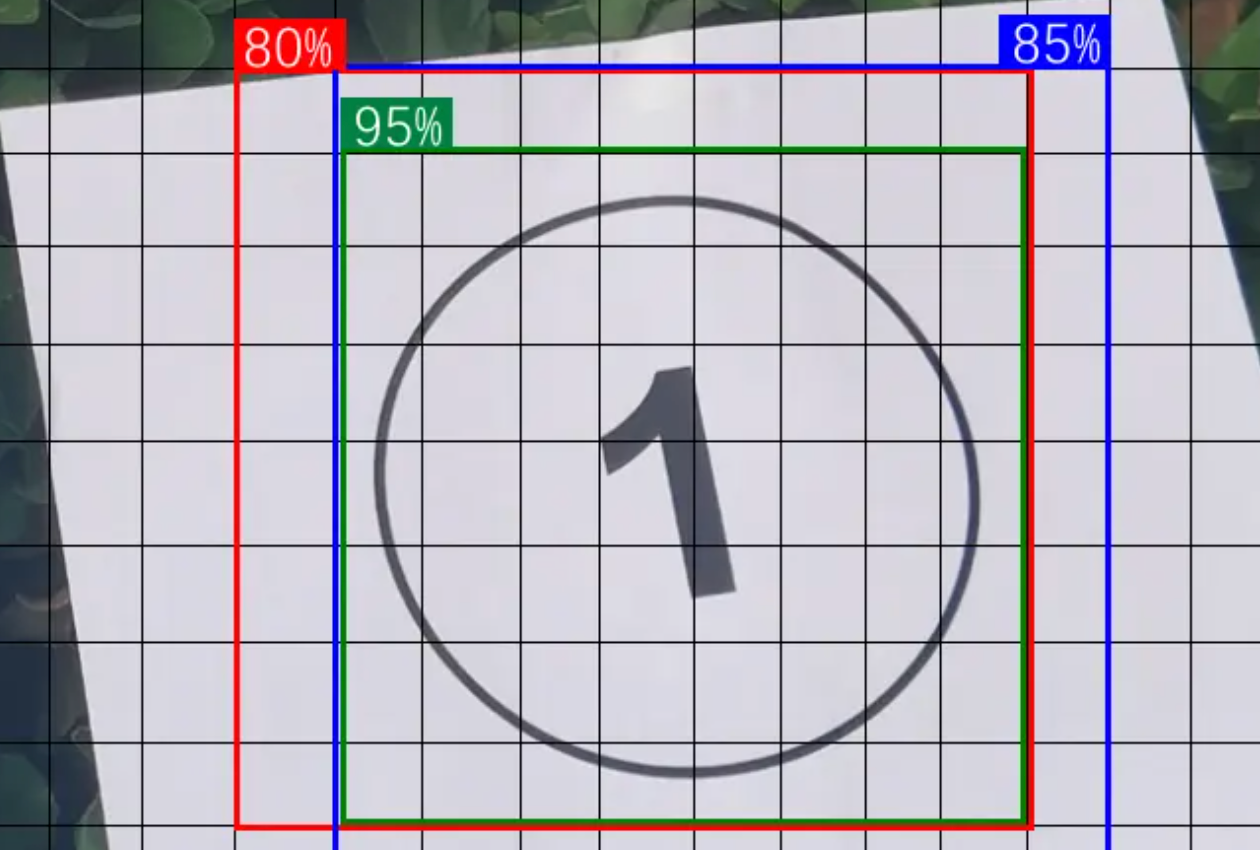
如上图所示,AI模型成功预测出了①的位置。但是红、蓝、绿3个框中的①,好像哪个都没错。因此dfl_loss提供了一个可信度,表明哪一个焦点跟标准答案相比,会更加精确。
val验证集:学得好,不一定考得好
上面是训练集的loss。下面说说验证集的loss。
从规范上讲,验证集和训练集是永远不见面的。这么做是为了验证AI是否真正学到了数据的特征和精髓,而非是靠死记硬背所见过的数据。
也就是说模型在经过几番训练集数据的学习之后,将面对从来没有见过的验证集数据。它将给出预测答案,然后再去对照标准答案。两个答案的差异,就是验证集的损失。
看下面这个验证集曲线的趋势。
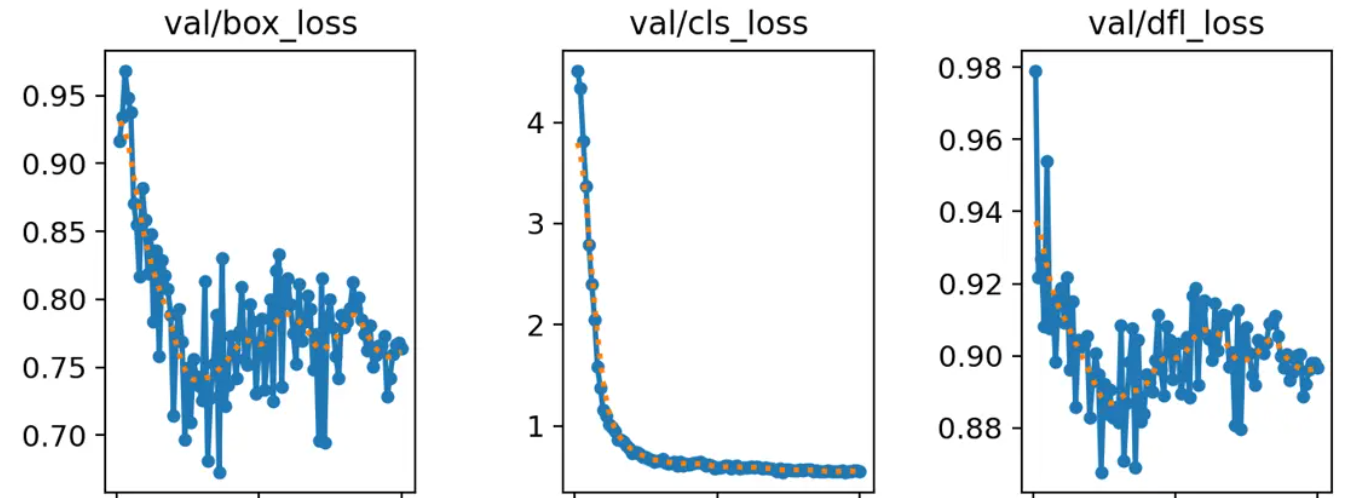
相比训练集的平滑趋势,验证集似乎是有些反复。
其实,这是一种常见现象。只要验证集损失没有显著上升,整体趋势在变好,且与训练集损失的差距不是特别大,这一般是正常的。
不过,要留意以下细节:
-
样本数据的变异:验证集可能包含一些与训练集不同风格的样本,这会导致损失不稳定。好比你拿着泰迪狗做识别训练,最后让模型去认识哈士奇狗,模型有点迷糊,拿不准。
-
模型的过拟合:如果验证集的样本数据正常。模型在训练集上的损失表现很好,但是验证集表现不稳定。那么可能是模型记住了训练集的细节,也就是过于死记硬背,只抓住形没有抓住神。这叫过拟合。
如果遇到比较严重的问题,或者你感觉有问题,该怎么办呢?
可以调整超参数,比如调小学习率,或者使用提前停止策略来防止过拟合。也可以调整batch大小,增加一个批次数量,让它见多识广。
同时,增加训练数据量或使用数据增强技术,可以使模型更好地泛化,减少验证损失的波动。
大家不要小看验证集的指标,这是衡量模型效果的第一道关卡。因为训练集的结果指标顶多算是自娱自乐,这有点像学校内部的月考、期末考试。而验证集则更像是高考。因此,对于验证集的检测,还有更多指标。
精度和召回率:又准又全的考量
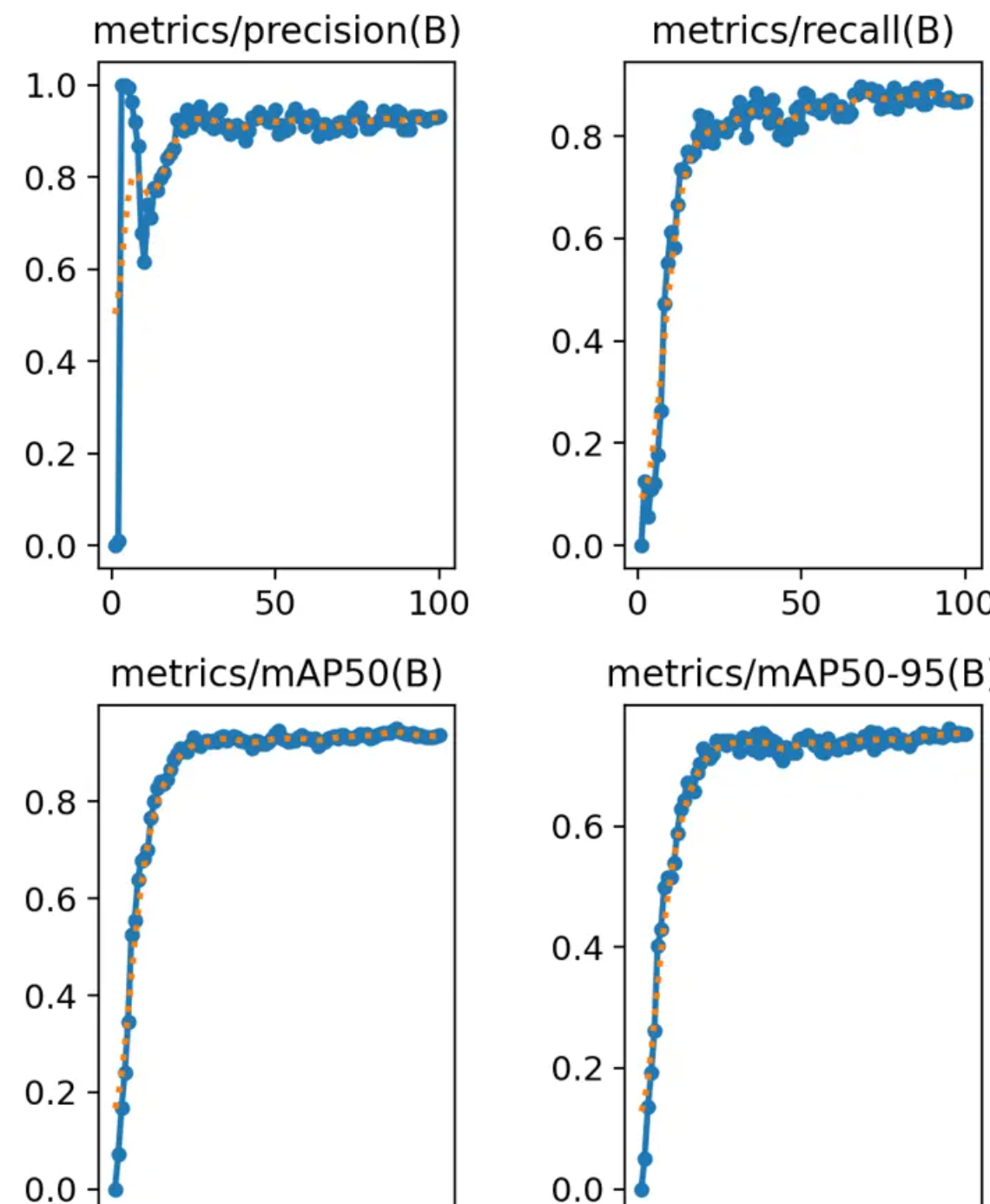
之所以说他们是同一类,看表头就知道,他们的名字前面带metrics,后面带(B)。
metrics表示模型是在验证集上的评估指标。(B)呢,在目标检测任务中表示Bounding Box,即边界框的检测结果。
首先看左上角的第一个precision。precision是精度,或者称为“精确率”。请注意,是精确率,不是准确率。准确率有专门的名词accuracy。两者不一样。
准确率表示预测正确的占比。比如1000件产品中,900件合格。我的AI模型全都找出来了,这时准确率是100%。
准确率存在一个问题,尤其对于少数个体而言不公平。比如预测绝症,100个人预测对了90个人是健康的,预测错了10个病危的人。虽然准确率是90%,但这属于严重事故。于是,精确率的可以解决这个问题。
精确率会从100个里随便抽出10条数据,如果预测错了5个,那么精确率就是50%。高准确率保证的是多数都正确,而高精确率是保证每一个都不出错。
我们看到第一个精确率的图表,大约30轮左右趋于稳定了,而且向1(100%)靠拢。这说明效果不错。
精确率就没有问题吗?也有问题!
精确率考核的是出错率,只要不出错,哪怕只干好一件事,也是100%。如果精确率指标它挑活干,那么就完犊子了。工作、生活中也有这类情况,就是拣着好做的工作去做,结果干得很漂亮。
因此,这时又引入了另一个指标,也就是第二幅图中的召回率recall。召回率的口号是:“宁可做错一千,绝不漏掉一个”。鼓励大家抢着做,谁眼里没活就打低分。这样就解决了那些少干活、拣活干的情况。
其实召回率recall和精确率precision是矛盾的。两者的值很难都高。因为既要脏活、累活、杂活都揽下,还要不允许出错。这对于机器或者人类都是很大的挑战。
但是,考核指标就是要这样的。就要想尽一切办法堵住漏洞。我们看第二幅图中召回率也是在提高的,这说明检测范围在不断扩大,大约在0.8处浮动。因此从前两张图我们可以说,这次训练precision精度是0.9,召回率recall为0.8。
关于P(precision)和R(recall)之间的数据趋势,这里面也有具体的图示。
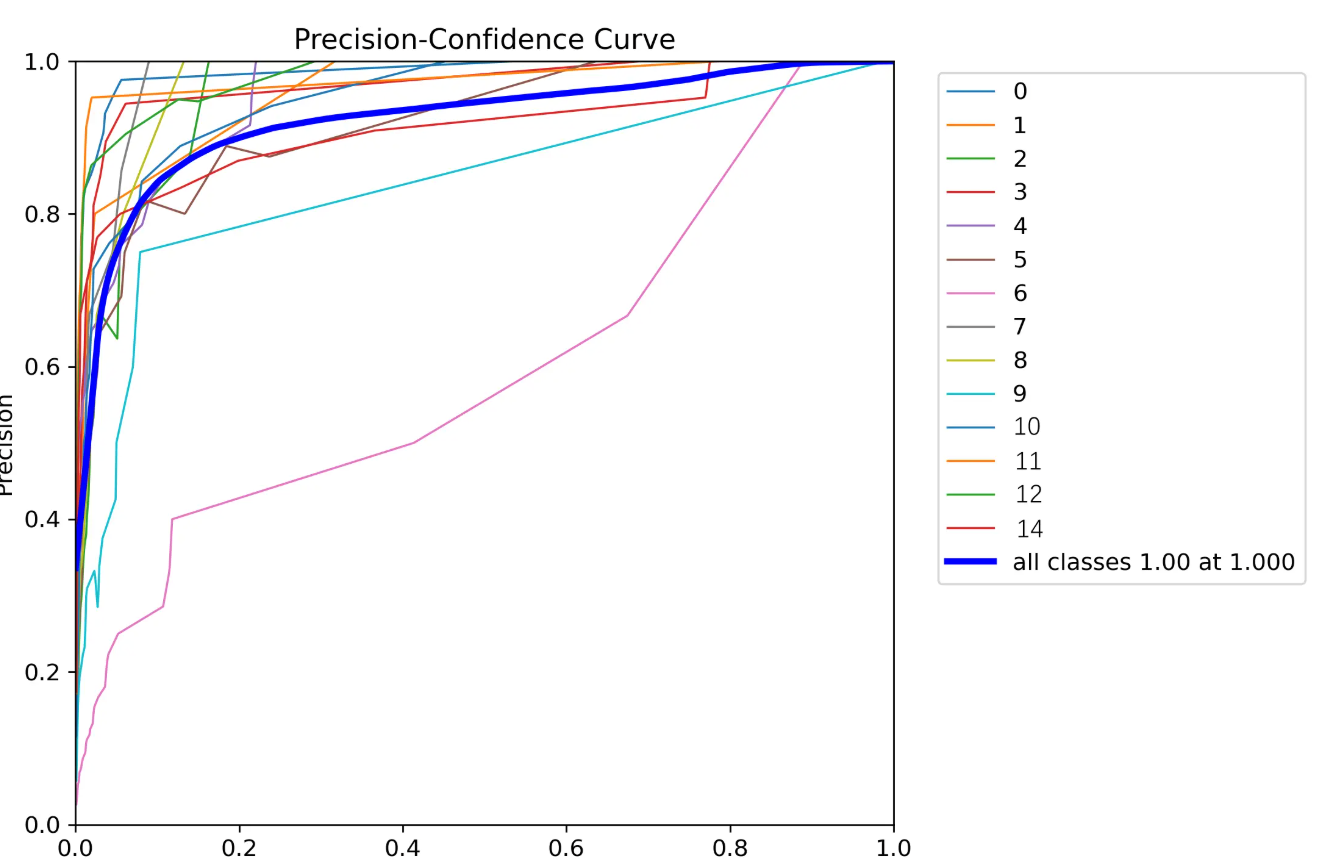
P_curve.png:
runs\detect\train下面有P_curve.png,这是每项精度的曲线。
R_curve.png
这是每项召回率的曲线。
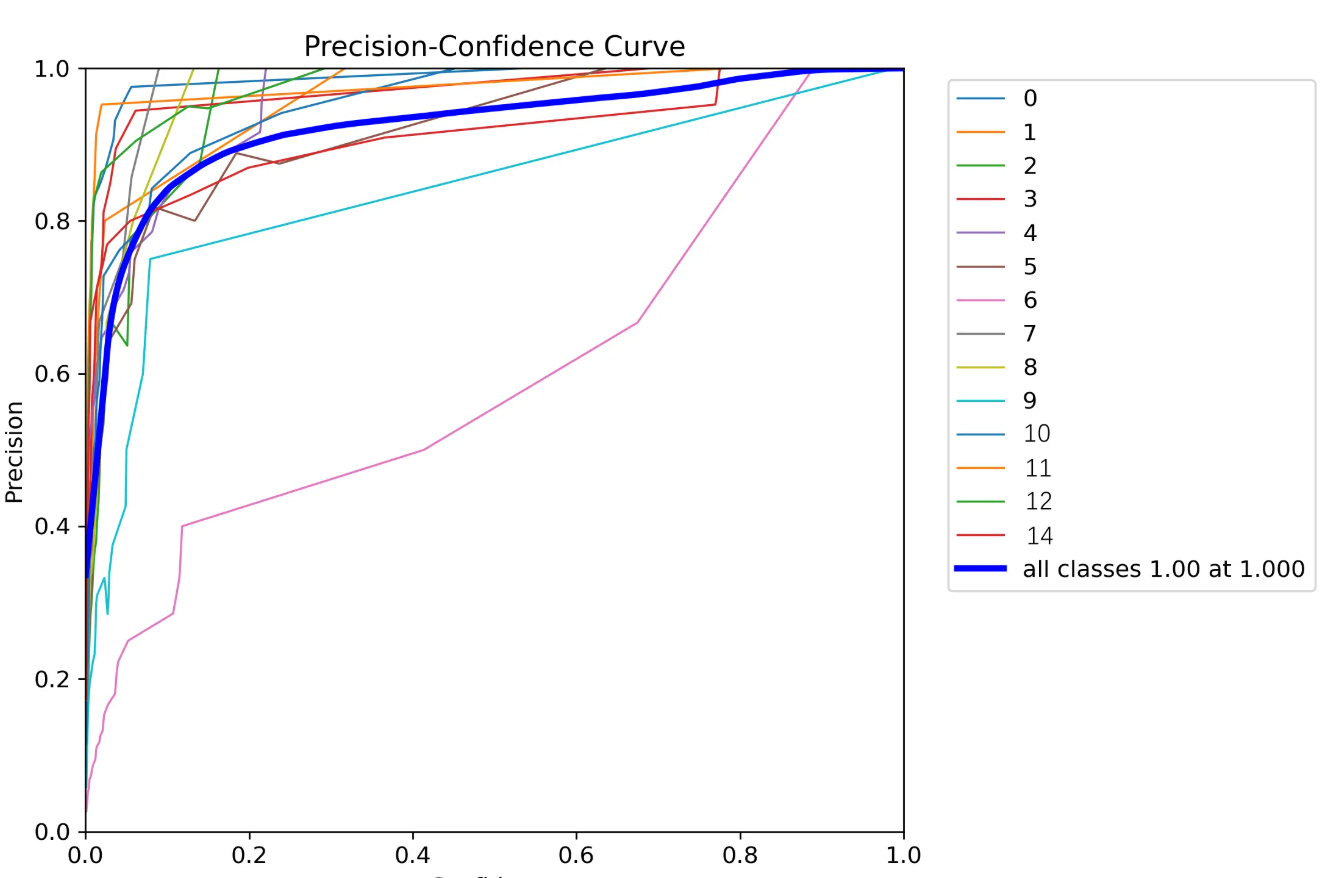
PR_curve.png
则是两者互相妥协的曲线。这个PR图怎么看呢?越接近正方形效果越好。都接近正方形,说明整体效果又准又全。

看上图,蓝色总线接近正方形。但是具体到分类为8的目标,有些拖后腿。
results.png系列还剩两张图片,那就是mAP50与mAP50-95。这俩是一类(也是看名称很像)。
mAP50要拆开看,拆成mAP-50,mAP表示mean Average Precision,称为平均精度。50则是在IoU阈值为50%的情况下的值。
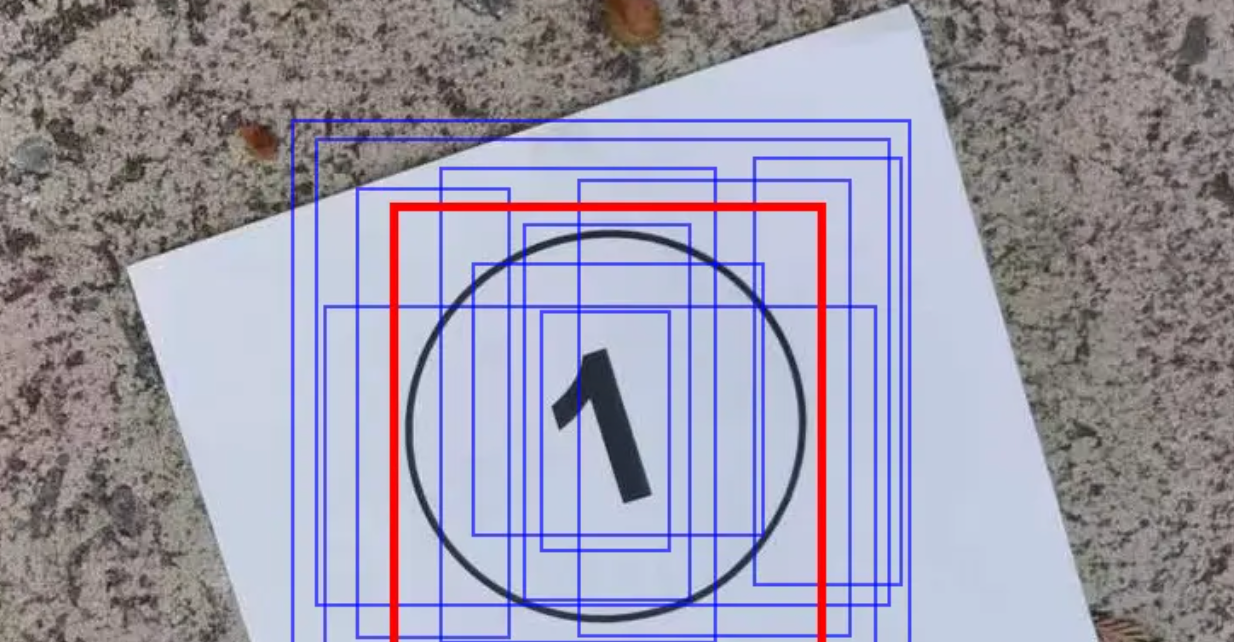
这些个预测出的框框儿,可能是物体的全部,也可能只是中心部分,还或许仅仅是物体的一个角。不管如何,这都是算法通过学习特征计算出来的。谁是谁非,看你怎么选择。
如果预测出的面积(蓝框)能占到实际区域(红框)的50%以上,那么我们就说IoU为50。重合度能到50%,其实能说明AI大体猜中了。因为IoU为100就是完全重合。
mAP50是重合度以50%为界限的平均精度。而mAP50-95则是IoU阈值从50%到95%范围内的平均值。这个更加严格一些。因此,我们看到图里面mAP50-95的值确实也低一些。
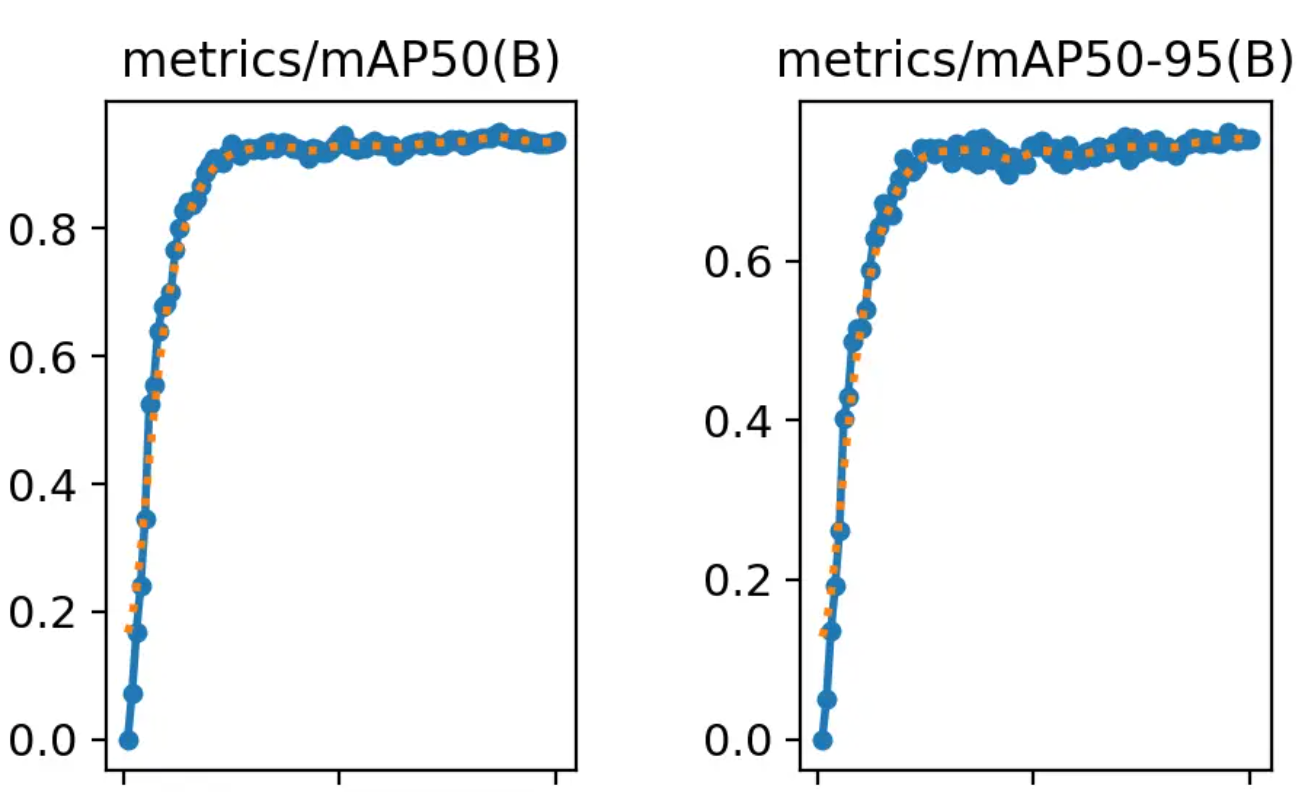
从这里能看出啥信息呢?
mAP50这个指标相对宽松,能够展示模型在较低严格度下的整体性能。它更适用于那些对定位要求不是特别严格的应用场景。
mAP50-95则意味着在严格的IoU条件下也能准确检测和定位目标。它适用于那些对定位要求较高的应用场景,如自动驾驶、医疗影像分析等。
因此,完全看你的需求。如果觉得现在的模型识别效果不好,对精度要求又不高能大体定位就行,其实可以调低IoU的值。反正,各类表现都告诉你了。
results.csv:图表里的数据明细

runs\detect\train下有一个results.csv表格文件。其实这是上面刚刚讲的很多图表的数字版本。
如果你想查询某次训练某项指标的具体值,可以从这个表格中查找。
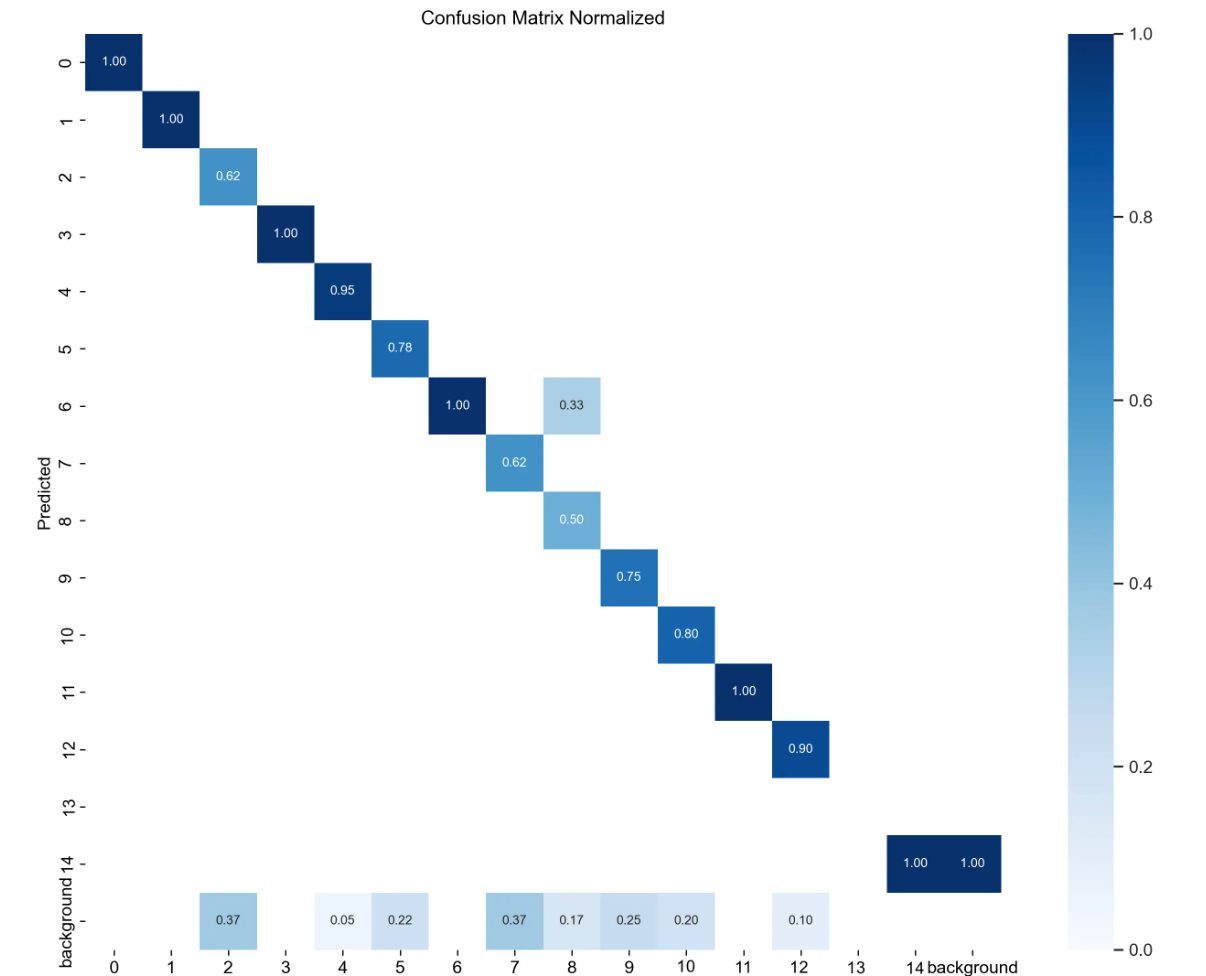
三、labels文件:分类标签的分布
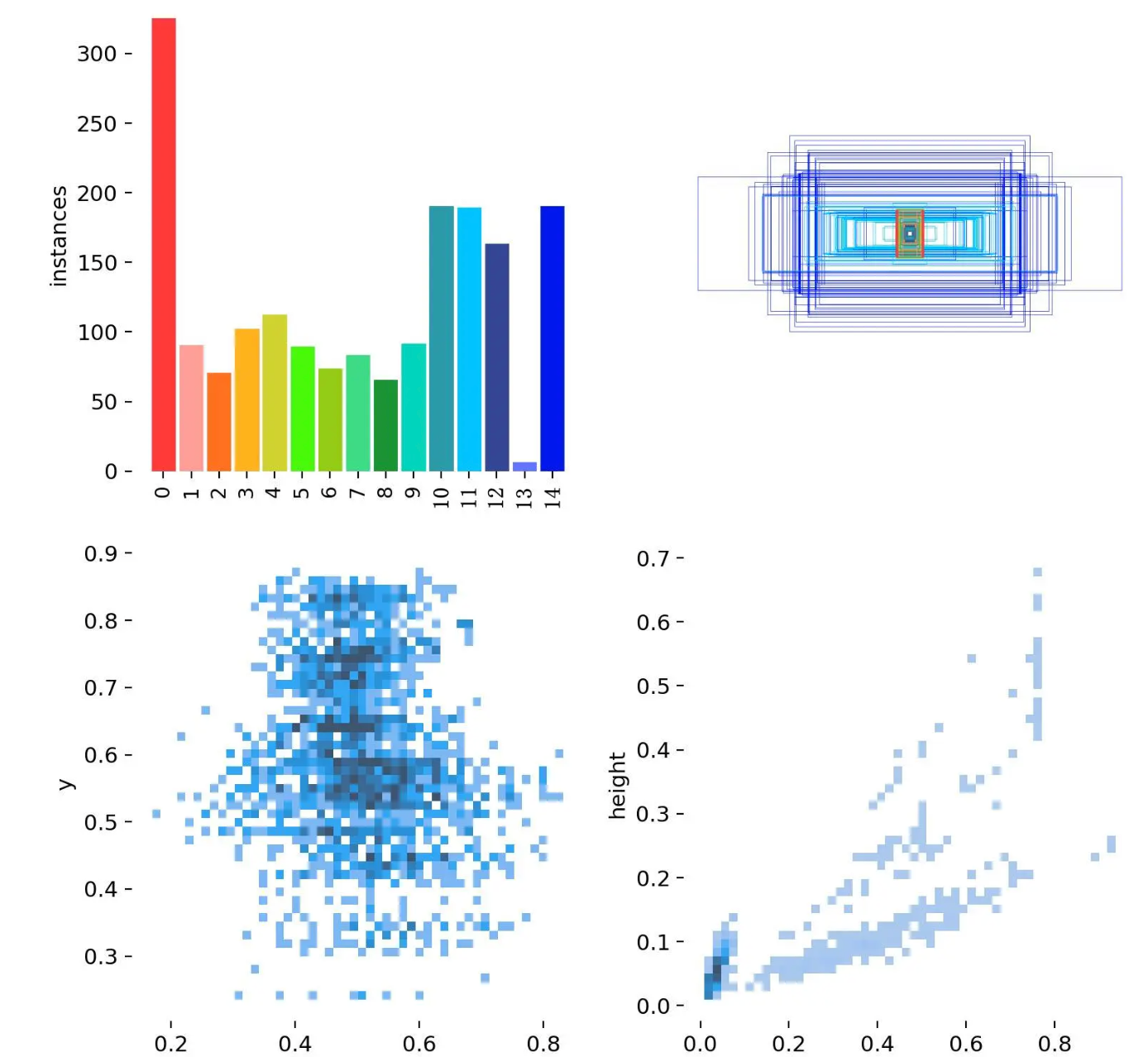
看上图第一项,很明显有一个问题。那就是第13分类的样本数太少。这也导致比如上面的P曲线、R曲线没有第13分类的信息(没注意可以滑上去再看看)。这是因为样本过少,被淹没、忽略了。
下面是是混淆矩阵的归一化版本,对应的图片是confusion_matrix_normalized.png。这里可以更清晰地展示模型在各类别上的性能表现。我们也可以看到第13类别数据为空。
注意:如果报错torchvision,请安装
pip install torchvision

 浙公网安备 33010602011771号
浙公网安备 33010602011771号