
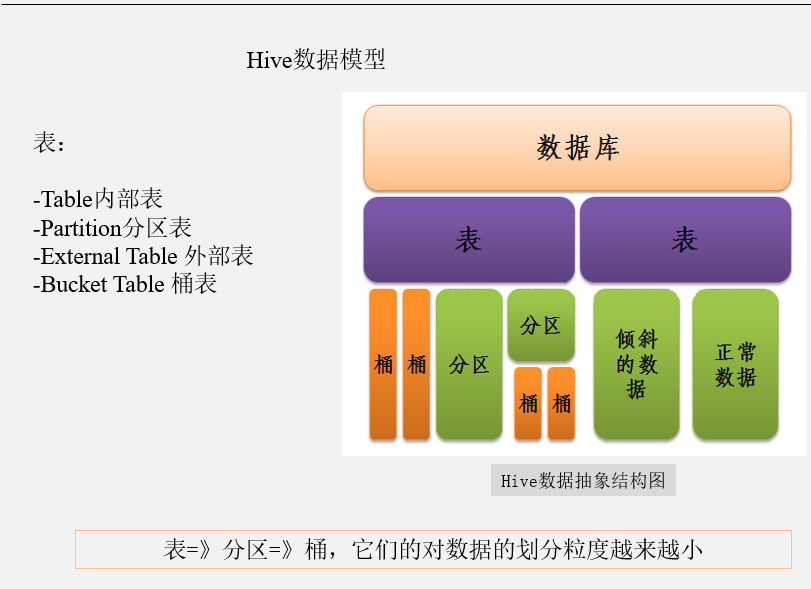
从纸上断的复试开始
hive
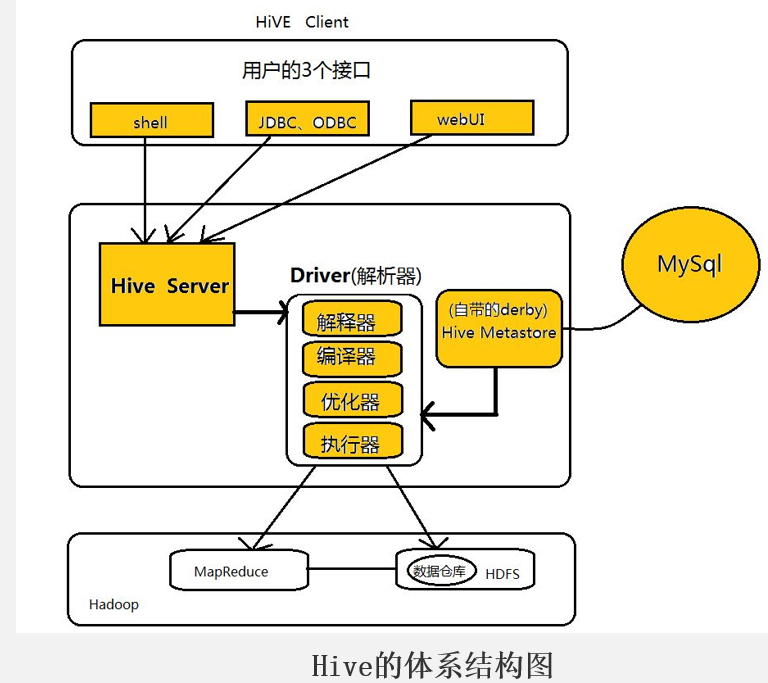
SHive的体系结构可以分为以下几个部分: ①用户接口:包括shell命令、Jdbc/Odbc和WebUi,其中最常用的是shell这个客户端方式对Hive进行相应操作
②Hive解析器(驱动Driver):Hive解析器的核心功能就是根据用户编写的Sql语法匹配出相应的MapReduce模板,形成对应的MapReduce job进行执行。
③Hive元数据库(MetaStore):Hive将表中的元数据信息存储在数据库中,如derby(自带的)、Mysql(实际工作中配置的),Hive中的元数据信息包括表的名字、表的列和分区、表的属性(是否为外部表等)、表的数据所在的目录等。
Hive中的解析器在运行的时候会读取元数据库MetaStore中的相关信息
。 在这里和大家说一下为什么我们在实际业务当中不用Hive自带的数据库derby,而要重新为其配置一个新的数据库Mysql,是因为derby这个数据库具有很大的局限性:
derby这个数据库不允许用户打开多个客户端对其进行操作,只能有一个客户端打开对其进行操作,即同一时刻只能有一个用户使用它,自然这在工作当中是很不方便的,所以我们要重新为其配置一个数据库。
④Hadoop:Hive用HDFS进行存储,用MapReduce进行计算——-Hive这个数据仓库的数据存储在HDFS中,业务实际分析计算是利用MapReduce执行的。




环境变量配置,tar解压后,配置配置文件,启动集群,然后要先启动mysql,mysql创建数据库,然后在hive配置文件添加mysql链接信息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号