RETRO
RETRO
姚伟峰(Matrix Yao)
Info Card
full name
RetrievalEnhancedTRansfOrmerpaper
Improving language models by retrieving from trillions of tokensyear
2022from
GitHub
un-official

Basic Idea
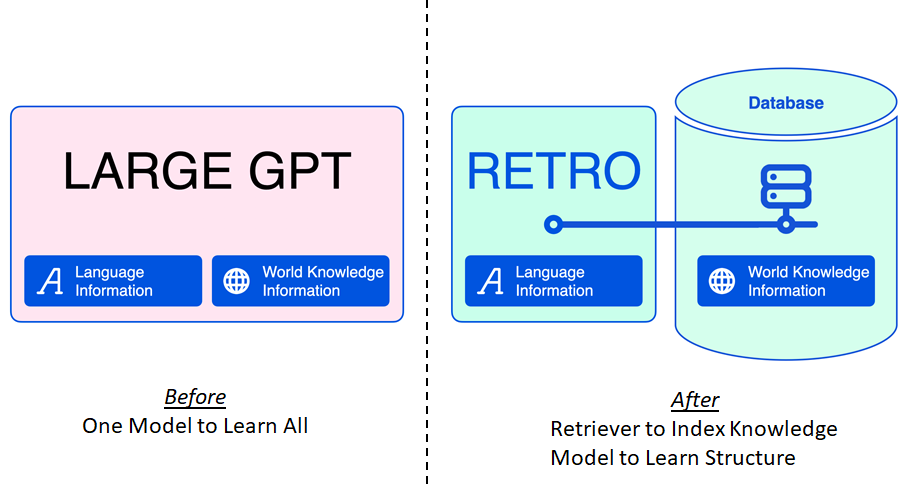
RETRO is a neural language model.
Comparing w/ existing language models like GPT, it separates memorization and generalization, so memorize the world knowledge w/ Retrieval, while learn the language structure w/ Model.
General auto-regressive language model
RETRO’s chunked retrieval enhanced model
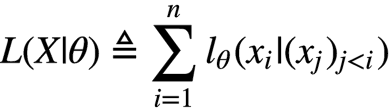
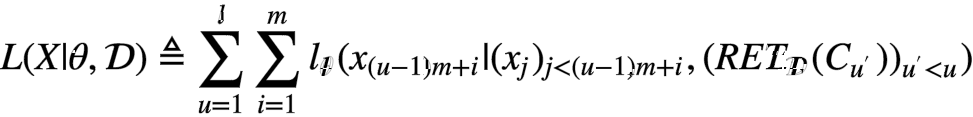
-
Any benefits?
Democratization fast/cheap and good
fast/cheap and good-
Fewer parameters: 25x fewer parameters lead to much lower requirement computation requirement for training and serving;
-
SOTA accuracy: show better perplexity on LM and SOTA accuracy on downstream tasks e.g., question answering;
-
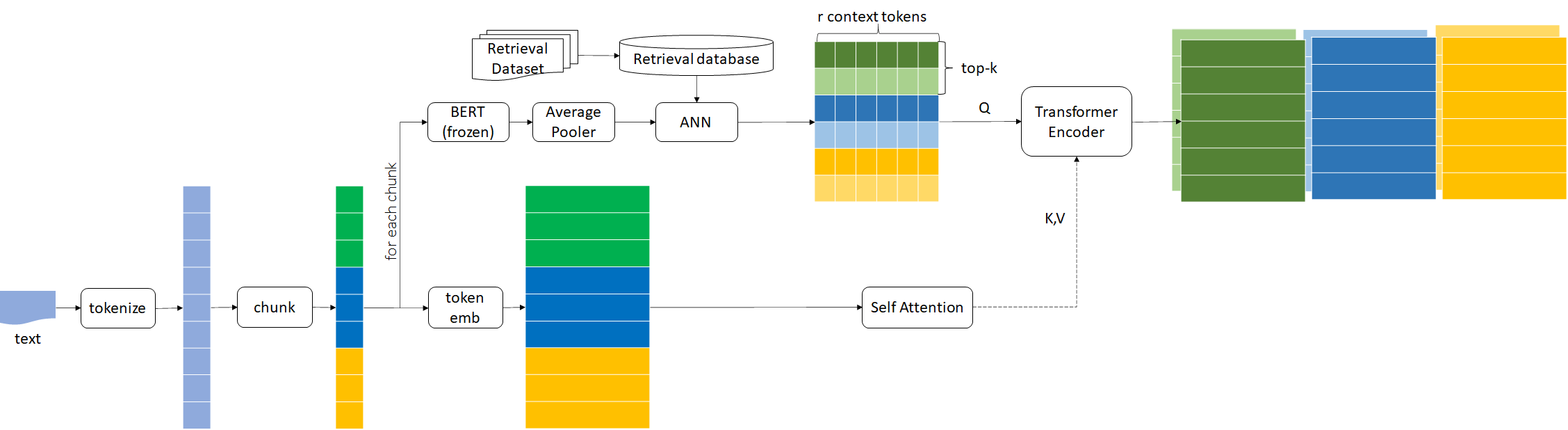
Below diagram from [1] is not the whole picture of RETRO. It’s just the retrieval part.

How Does it Work
Step-1: Retrieve Nearest Neighbors and Encode them
-
Points
-
retrieve the top-k nearest neighbors in chunk granularity, neither passage granularity as sentence BERT nor token granularity like ColBERT
-
each of top-k token sequence = concat(neighbor chunk, continuation chunk)
-
each token sequence is encoded w/ bi-directional transformer encoder, optionally w/ self-attended query as k/v
-
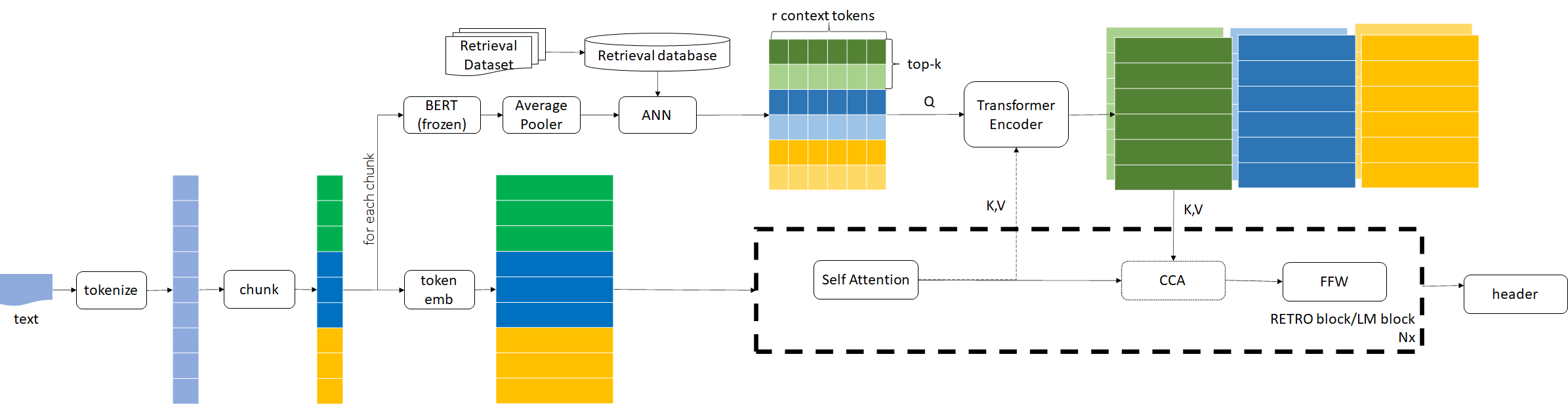
Step-2: Decode Causally
-
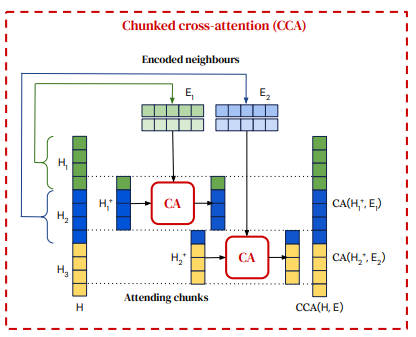
CCA(Chunked Cross Attention)
-
Points
-
both attention and CCA are causal, to make it auto-regressive
-
Results
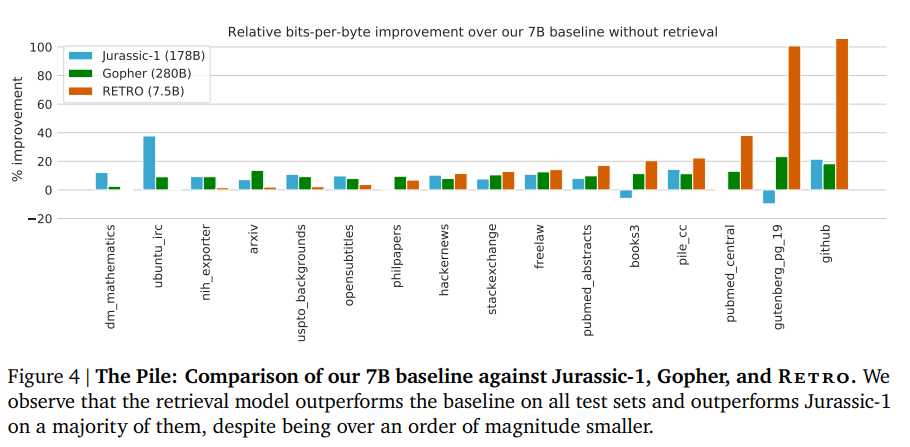
Language Model
Pretty good bits-per-byte even 23+x smaller size.
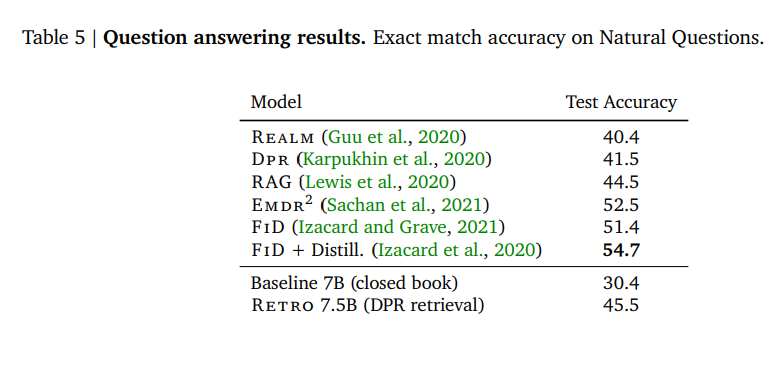
Downstream Task: QA
Not really so good, considering the 7.5B model size. And inferior accuracy than FiD, they blame the encoder weight not enough in current model.
Application on ODQA domain
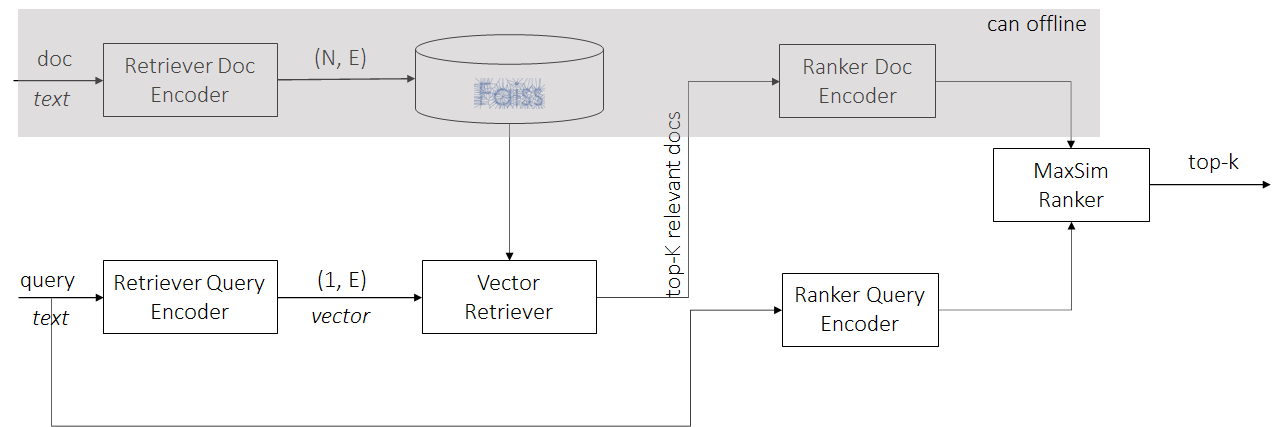
Pipeline Comparison
-
dense retriever + neural ranker
E.g.,-
Single Retrieval Encoder: SentenceEmbedding Retriever + ColBERT Ranker
-
Dual Retrieval Encoder: DPR Retriever + ColBERT Ranker
-
-
RETRO
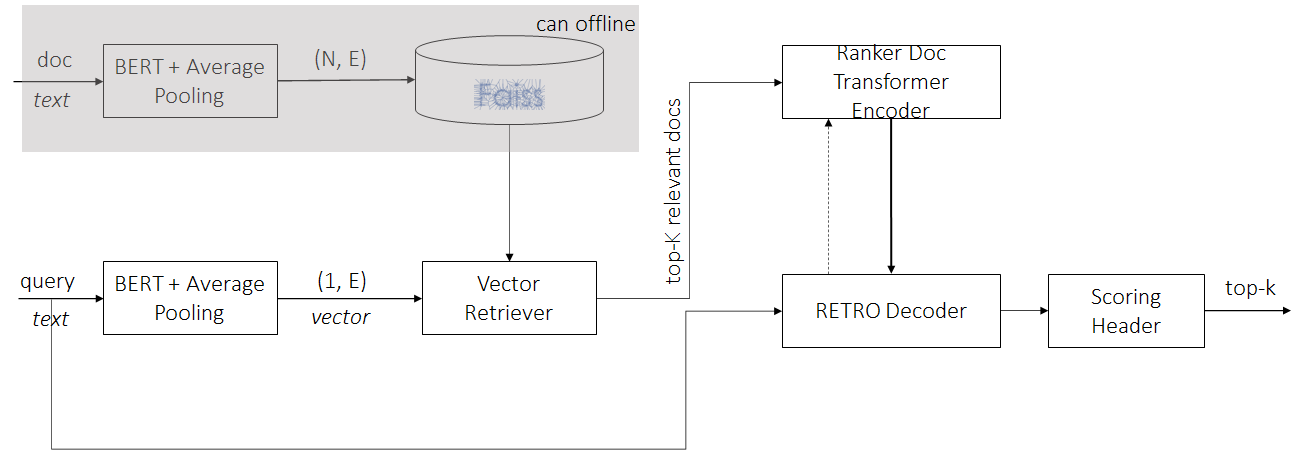
We can see that RETRO can easily fit as a dense retriever + neural ranker ODQA pipeline. It can be viewed as single-encoder dense retriever + neural ranker , and the ranker is compute-heavier than ColBERT, both because of model size and the ranker doc encoder cannot be pre-computed.
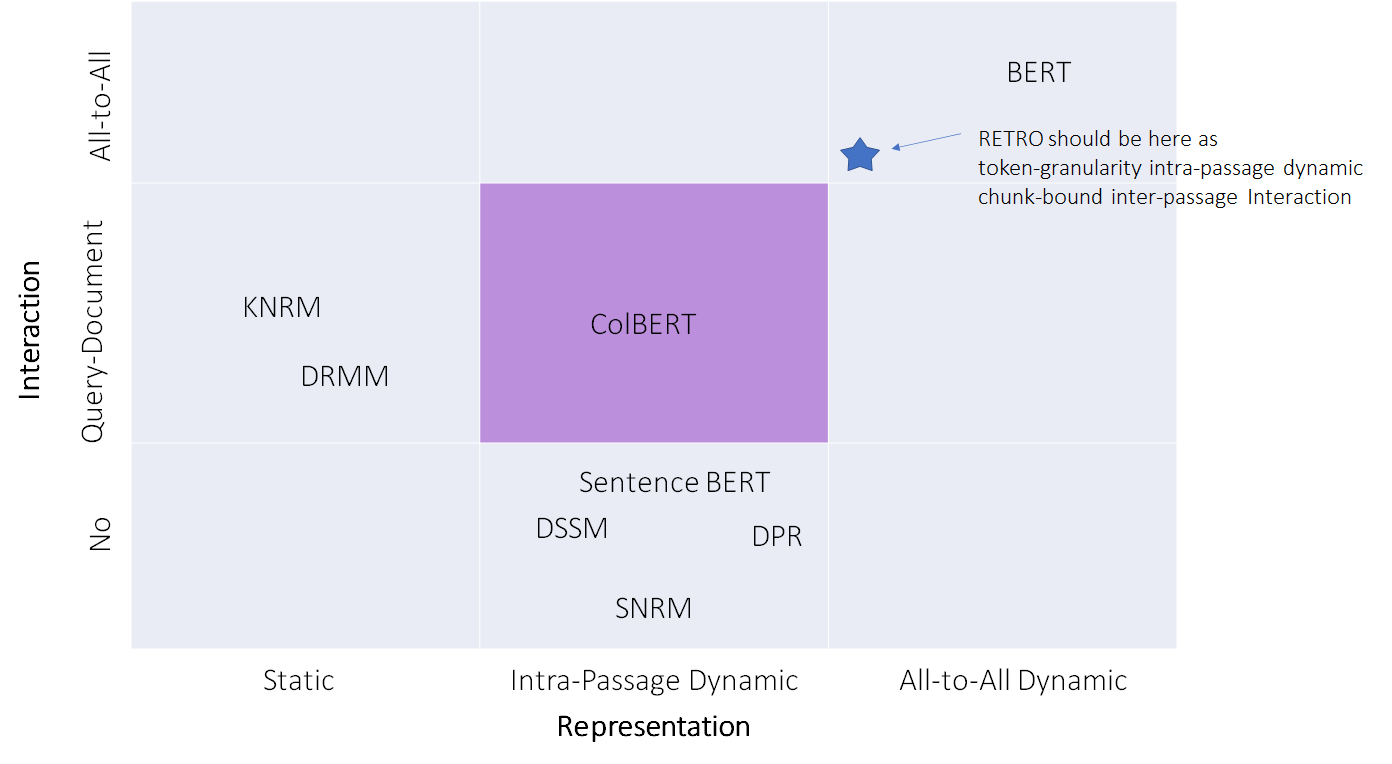
To put RETRO into the map of ODQA paradigms


 浙公网安备 33010602011771号
浙公网安备 33010602011771号