洛谷 P1147 连续自然数和——关于c++中lower_bound的使用范例
洛谷P1147 连续自然数和
关于C++中 lower_bound 的使用范例
以及 前缀和算法 的入门
题目链接:https://www.luogu.com.cn/problem/P1147
题目描述
对一个给定的正整数 \(M\),求出所有的连续的正整数段(每一段至少有两个数),这些连续的自然数段中的全部数之和为 \(M\)。
例子:\(1998+1999+2000+2001+2002 = 10000\),所以从 \(1998\) 到 \(2002\) 的一个自然数段为 \(M=10000\) 的一个解。
输入格式
包含一个整数的单独一行给出 \(M\) 的值(\(10 \le M \le 2,000,000\))。
输出格式
每行两个正整数,给出一个满足条件的连续正整数段中的第一个数和最后一个数,两数之间用一个空格隔开,所有输出行的第一个按从小到大的升序排列,对于给定的输入数据,保证至少有一个解。
样例输入 #1
10000
样例输出 #1
18 142
297 328
388 412
1998 2002
好习惯
- 观察题目,首先要看的就是 \(M\) 的数据范围,观察到 \(M\) 的数据范围是 \(10 \le M \le 2,000,000\) ,显然从 \(1\) 累加到 \(2,000,000\) 会得到一个很大的数字:\(2,000,001,000,000\) ,超过了 \(int\) 的最大值,所以本题应当把变量开成 \(long\ long\).
方法一:暴力出奇迹!
- 很容易想到暴力枚举的方法:给定一个指针 \(i\) 从第一个数开始循环枚举到最后一个数 \(M\) ,并且在每一轮循环的时候,给定第二个指针 \(j\) 从 \(i+1\) 开始循环到 \(M\) ,然后求出从第 \(i\) 个数累加到第 \(j\) 个数的总和 \(sum\),判断 \(sum\) 是否等于 \(M\) 即可。
根据这个思路,我们很容易写出代码:
#include <bits/stdc++.h>
using namespace std;
#define ll long long
ll M;
int main()
{
cin>>M;
for(int i=1;i<=M;i++)
{
for(int j=i+1;j<=M;j++)
{
ll sum=0;
for(int k=i;k<=j;k++)
{
sum+=k;
}
if(sum==M)
{
cout<<i<<' '<<j<<endl;
}
}
}
}
我一写完这代码啪的一下就交上去了,很快啊,就\(TLE\)了:
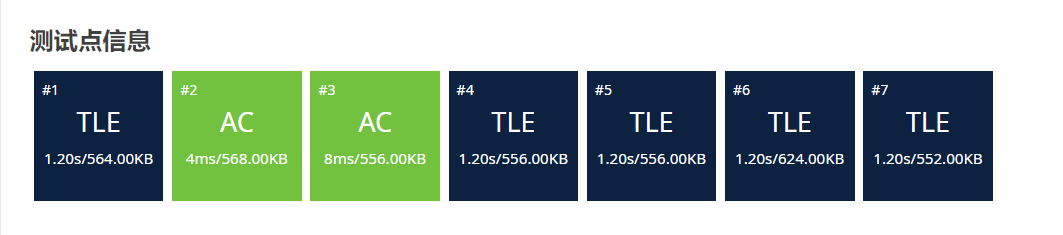
总之就是喜提 \(28\) 分
回看我们写的构式代码,不难发现:套了整整3层循环,也就是说,暴力枚举的代码时间复杂度达到了 \(O(n^3)\),显然严重拖慢了执行效率,因此我们必须考虑如何优化我们的代码。
方法二:前缀和!
- 观察方法一中的第三层循环,其作用是计算从第 \(i\) 个数累加到第 \(j\) 个数的和 \(sum\),每得到一组新的 \(i\) 和 \(j\) 都需要重新累加,这显然非常的累赘。
- 从数学角度来分析,对于一个数列 \(a_{n}\) ,如果我们知道了所有 \(S_{n}\) 的数值,那我们只需要做 \(S_{j}-S_{i-1}\) 就能一步得出从 \(a_{i}\) 累加到 \(a_{j}\) 的值。显然大大提高了计算的效率。
- 从代码角度分析,我们是否可以通过一种处理方式来实现上述的简化呢?答案是可以的!接下来我就要引出一个很常见的代码优化技巧:前缀和。
- 对于每个数值都需要手动输入的数列 \(a_{n}\),我们可以在输入的时候做以下处理:
for(int i=1;i<=n;i++>)
{
cin>>a[i];
s[i]=s[i-1]+a[i];
}
- 不难发现上述代码的作用其实就是每输入一个元素 \(a_{i}\) 时,对应的 \(S_{i}\) 就等于从 \(a_{1}\) 到 \(a_{i-1}\) 的总和 \(S_{i-1}\) 再加上 \(a_{i}\)
也就是该数列的前 \(i\) 项和 \(S_{i}\)
-这样以来,我们就不需要每得到一组 \(i\) 和 \(j\) 都费劲地循环一遍,而是直接一句:\(S_{j}-S_{i-1}\) 高效结束战斗!
根据这个思路,我们很容易写出优化后的代码:
#include <bits/stdc++.h>
using namespace std;
#define ll long long
ll s[20000006];
ll M;
int main()
{
cin>>M;
for(int i=1;i<=M;i++)
{
s[i]=s[i-1]+i;
}
for(int i=1;i<=M;i++)
{
for(int j=i+1;j<=M;j++)
{
ll sum=s[j]-s[i-1];
if(sum==M)
{
cout<<i<<' '<<j<<endl;
}
}
}
}
正当你满怀自信地提交了自己的代码并且准备迎接满分的怀抱时......

噔 噔 咚
你茫然地坐在电脑前,几秒钟前的得意全然消失不见,你盯着这两个 \(TLE\) 的测试点,陷入沉思......
方发三:前缀和 + lower_bound !
-
为了方便阅读,以下统一用 \(sum(i,j)\) 代替 \(S_{j}-S_{i-1}\) ,用来表示从第 \(i\) 个数累加到第 \(j\) 个数的总和,且默认 \(i<j\)。
-
我们观察刚才写的代码,发现虽然我们优化了第三层循环,但是仍然存在两层循环!也就是说,对于这道题的数据强度,\(O(n^2)\) 的复杂度显然是过不去的。
-
这时候我们不得不想办法优化这两个双层循环。让我们回看这道题的题目,我们所找的自然数段是连续的,假如我们现在定了一个指针 \(i\) ,那么我们可以发现,\(i\) 到 \(j\) 的子段是有序的,具体来讲就是:\(sum(i,j)\) 的值是随着 \(j\) 的递增而递增的。
-
根据这个规律,我们发现,如果当前的 \(sum(i,j)\) 偏小,那么所有的 \(j\) 左侧的 \(sum(i,k)_{(k<j)}\) 都是一定更加小的,同理,如果当前的 \(sum(i,j)\) 偏大,那么所有的 \(j\) 右侧的 \(sum(i,k)_{(k>j)}\) 都是一定更加大的。
-
因此我们可以引入二分查找的思想:
只需要查找区间 \([i+1,M]\) 中的一个值 \(ans\),使得 \(sum(i,ans)=M\) 就可以了。如果不存在这样的 \(ans\) 呢?很简单,只需要找到一个比较近似的值充当 \(ans\) 就可以了,然后加一个 \(if\) 条件句判断 \(sum(i,ans)\) 是否等于 \(M\) 即可,若 \(sum(i,ans)=M\) 成立,则输出当前的 \(i\) 和 \(ans\),若不成立,则直接进入 \(i\) 的下一轮循环。
-
这里我们引入C++中STL库中的经典函数:lower_bound
ans=lower_bound(a,a+n,pos)-a;
这个函数的作用是在一个有序数列中找到第一个大于等于给定数值的元素下标,如上代码中,\(ans\) 等于一维有序数组 \(a\) 中从 \(a[0]\) 到 \(a[n-1]\) (注意 \(n\) 是取不到的,左闭右开)第一个大于等于 \(pos\) 的元素的下标。
举个例子:
int a[8]={4,10,11,30,69,70,96,100};
int ans;
ans=lower_bound(a,a+8,11)-a;
这样 \(ans\) 就是第一个大于等于 \(11\) 的元素,运算结果为:\(ans=2\).
之所以说这个方法是二分,是因为lower_bound的实现原理其实就是一个二分查找。
-
熟悉了 lower_bound 的用法之后,我们开始思考如何将这个函数运用在我们的代码中。
-
我们假设找到了一组 \(sum(i,j)=M\),也就是说此时, \(S_{j}-S_{i-1}=M\) 成立,由于我们本轮循环的 \(i\) 是定好的,所以我们对上式移项得到:\(S_{j}=M+S_{i-1}\).
-
结合lower_bound的功能,不难发现我们只需要在区间 \([i+1,M]\) 上找到一个正好大于等于 \(M+S_{i-1}\) 的 \(S_{j}\) ,然后判断 \(S_{j}\) 是否等于 \(M+S_{i-1}\) 即可。
-
至此,我们已经做完了所有的准备工作,接下来就是震撼人心的:
Coding时刻!
代码奉上:
#include <bits/stdc++.h>
using namespace std;
#define ll long long
ll M;
ll s[20000006];
int main()
{
cin>>M;
for(int i=1;i<=M;i++)
{
s[i]=s[i-1]+i;
}
for(int i=1;i<=M;i++)
{
ll pos=s[i-1]+M;
ll ans=lower_bound(s+i,s+M+i,pos)-s;
if(s[ans]==pos) cout<<i<<' '<<ans<<endl;
else continue;
}
return 0;
}

至此,本题的所有测试点都得以通过,顺利AC.
通过这三个方发的迭代,我们之后更应关注代码的繁冗程度,尽可能用快速的执行方法解决问题。
此为算法之真谛。
附加优化:考虑第二个 \(for\) 循环内 \(i\) 的循环范围
-
由于不加这个优化也不会影响本题正常AC,故把此优化作为附加内容,充当各位茶余饭后的休闲。
-
审题发现符合题意的子段至少为两个数字,也就是两个连续的自然数,我们考虑倘若真的存在这样的情况:\(M\) 等于两个连续自然数之和,显然 \([\frac{M}{2}]\) 一定等于较小的那个自然数,针对这个 \(M\),不难发现,如果存在其他符合题意的解,\(i\) 的值也绝对不可能大于 \([\frac{M}{2}]\),因为如果是这样的话,\(j\) 无论取 \(i\) 右侧的哪个值,得到的结果都一定会大于 \(M\).
-
更一般地,即便不存在两个连续的自然数使得 \(M\) 等于这两个连续自然数之和,\(i\) 的最大值也不能超过 \([\frac{M}{2}]\),因为这样会导致 \(sum(i,j)\) 恒大于 \(M\).
-
因此,对于第二个 \(for\) 循环,我们可以将 \(i\) 的右边界设为 \([\frac{M}{2}]\),这样子可以直接节约将近一半的时间,大幅提高代码运行效率。
兔子镇楼(逃


 浙公网安备 33010602011771号
浙公网安备 33010602011771号