【总结笔记】设计模式
工厂模式介绍
https://zhuanlan.zhihu.com/p/83535678
工厂模式利用 C++ 多态的特性,将存在继承关系的类,通过一个工厂类创建对应的子类对象。工厂模式可分别实现为简单工厂模式、工厂方法模式、抽象工厂模式。
简单工厂模式
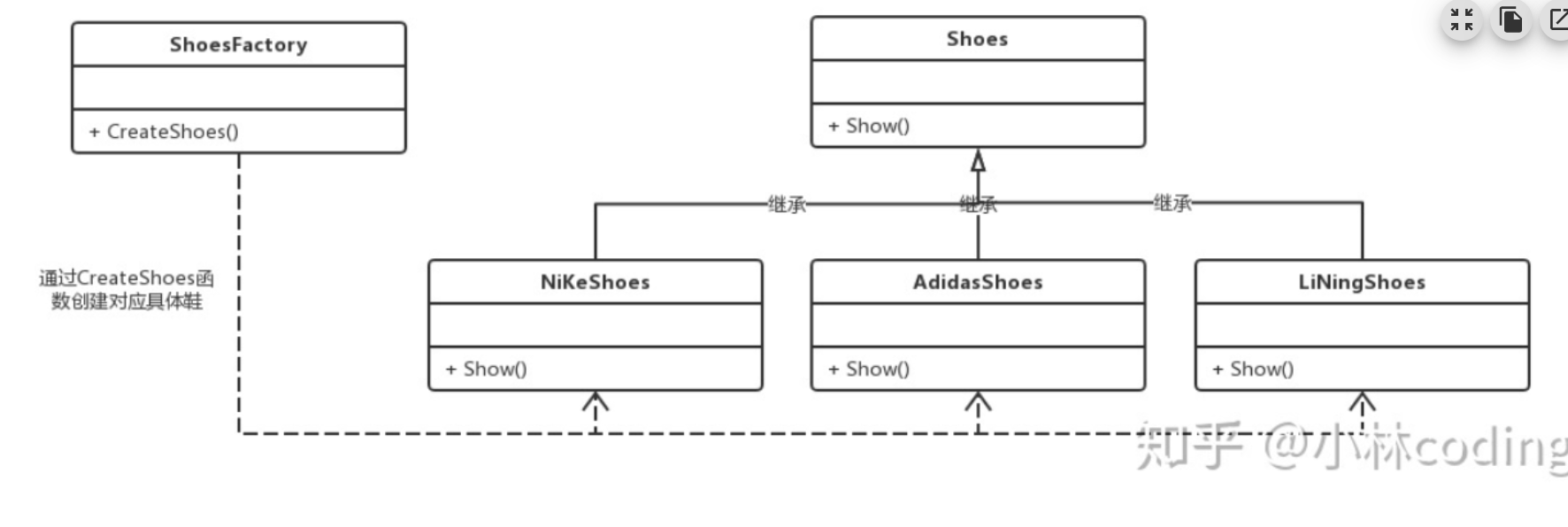
由工厂类、抽象产品类、具体产品类三部分组成。工厂类封装了创建具体产品对象的函数。
缺点:扩展性差,新增产品时,需要修改工厂类。
// 抽象产品类
class shoes {
public:
virtual ~Shoes() {}
virtual void Show() = 0;
};
// 具体产品类1
class NikeShoes : public Shoes {
public:
void Show() {
cout << "I am Nike" << endl;
}
};
// 具体产品类2
class LiNingShoes : public Shoes {
public:
void Show() {
cout << "I am LiNing" << endl;
}
};
enum SHOES_TYPE
{
NIKE,
LINING
}
// 工厂类实现根据鞋子类型创建对应鞋子产品对象
class ShoesFactory {
Shoes *CreateShoes(SHOES_TYPE type) {
switch(type) {
case NIkE:
return new NikeShoes();
break;
case LINING:
return new LININGShoes();
break;
default:
return NULL;
break;
}
}
};
int main()
{
ShoesFactory shoesFactory;
// 从鞋工厂对象创建 Nike
Shoes *pNikeShoes = shoesFactory.CreateShoes(NIKE);
... // 后续调用对象的接口
}
工厂方法模式
工厂方法模式是在简单工厂模式的基础上,再进行一层抽象。
由抽象工厂类、具体工厂类、抽象产品类、具体产品类四部分组成。
特点:把具体产品对象放到具体工厂类实现。
缺点:1)每新增一个产品,就增加一个产品对应的具体工厂类;2)一个生产线只能生成一个产品。
// 抽象工厂类
class ShoesFactory
{
public:
virtual Shoes *CreateShoes() = 0;
virtual ~ShoesFactory() {}
};
// 具体工厂类 1
class NiKeProducer : public ShoesFactory
{
public:
Shoes *CreateShoes()
{
return new NiKeShoes();
}
};
// 具体工厂类 2
class LiNingProducer : public ShoesFactory
{
public:
Shoes *CreateShoes()
{
return new LiNingShoes();
}
};
发布订阅模式 VS 观察者模式
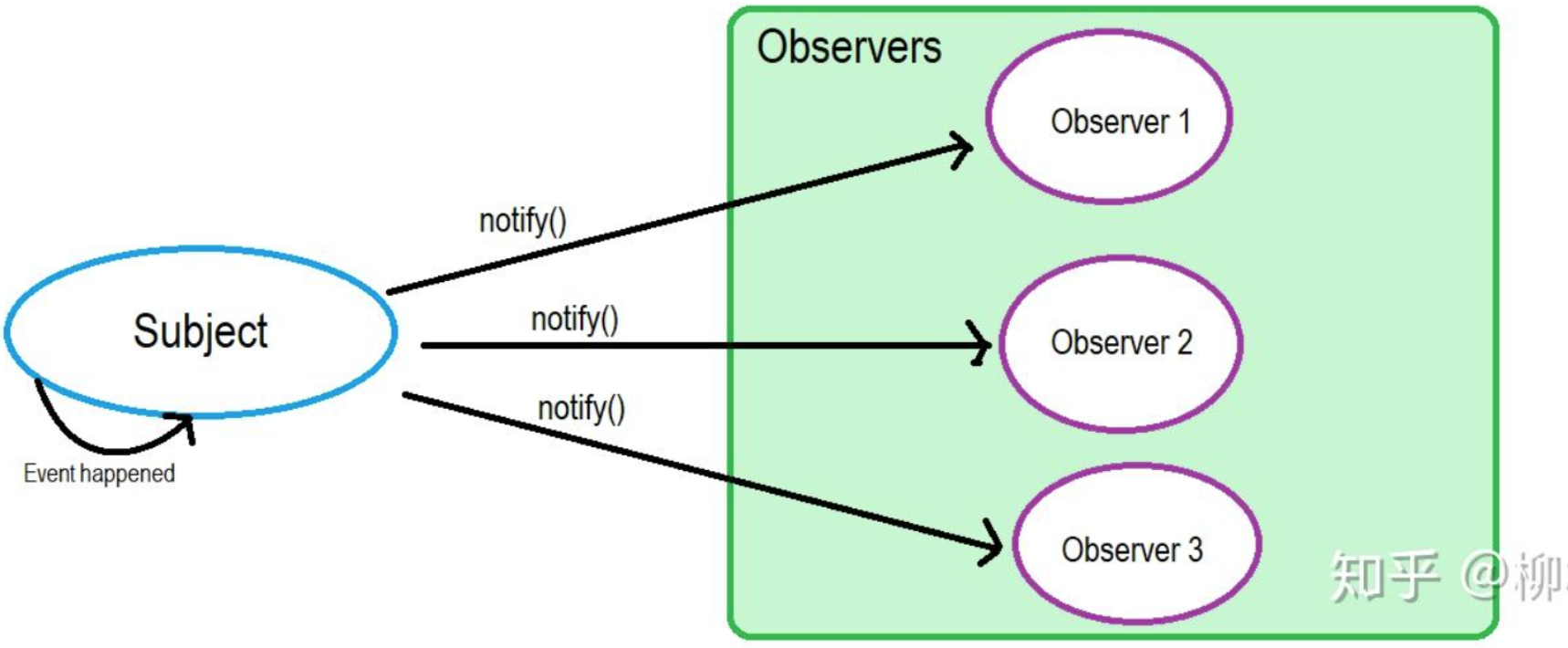
观察者模式是面向接口编程,实现松耦合。被观察者(Subject)只需维护一套观察者(Observer)的集合,这些 Observer 实现相同的接口,Subject 只需要知道,通知 Observer 时,需要调用哪一个统一方法就好。
发布订阅模式中发布者和订阅者之间是完全解耦的。发布者与订阅者彼此不知道对方的存在。它们通过第三方消息队列(经纪人Broker)来实现。
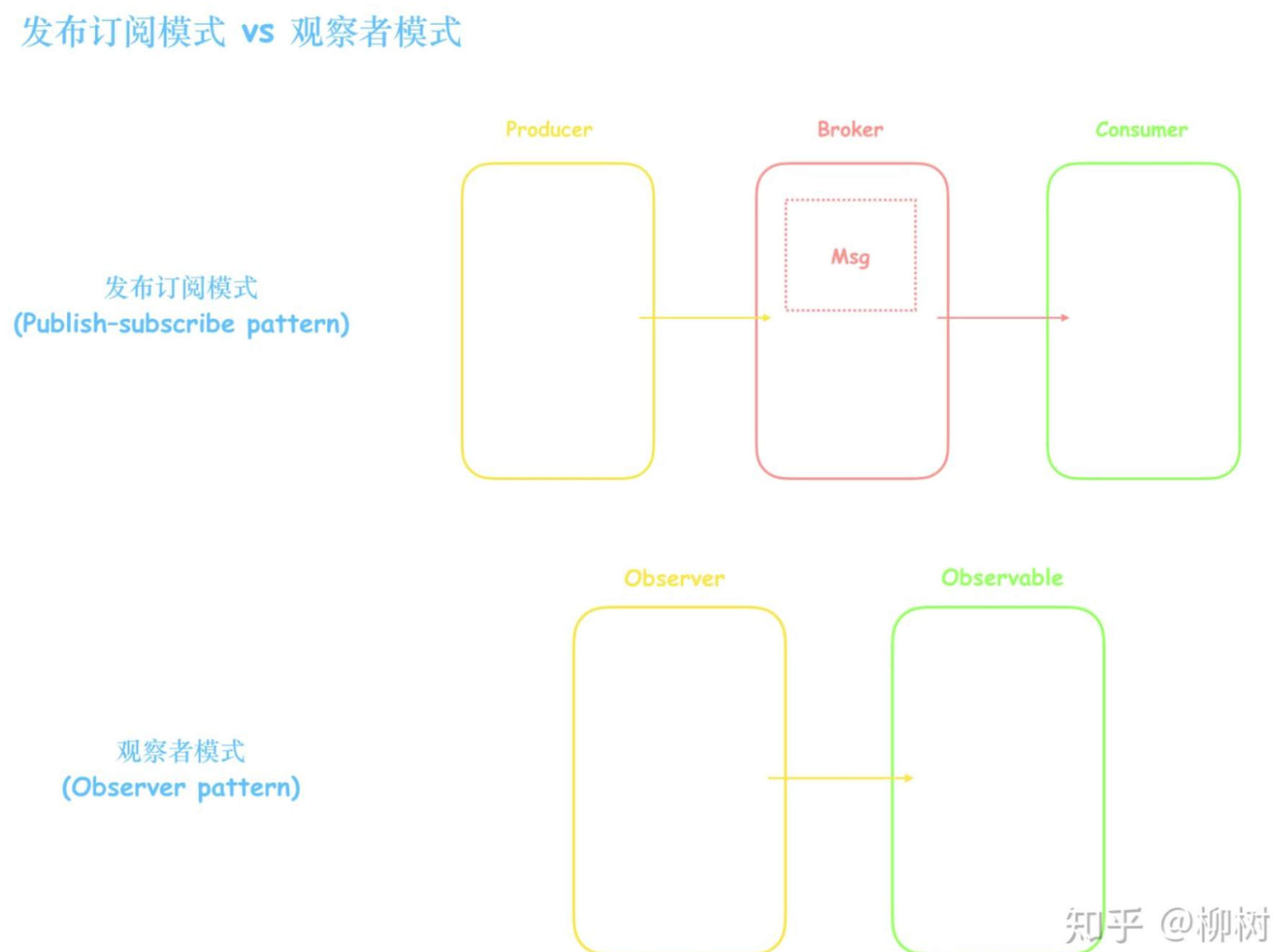
生产消费者模式 VS 发布订阅模式
发布订阅模式是一种特殊的生产消费者模式。在生产消费者模式中,生产者将数据源源不断推送到消息中心,由不同的消费者从消息中心取出数据,它们取出的数据类别是无差别的。
在订阅发布模式中,订阅者首先向消息中心指定自己对哪些数据感兴趣,发布者推送的数据经过消息中心后,每个订阅者拿到的仅仅是自己感兴趣的一组数据。
补充:Kafka 下的生产消费者模式与发布订阅模式
基本概念
Kafka 是一个分布式流数据系统(消息队列),由 Zookeeper 进行集群额管理。整个系统由生产者、Broker Server 和消费者三部分组成。生产者和消费者由开发人员编写,通过 API 连接到 Borker Server 进行数据操作。关注如下 3 个概念:
1)Topic:Kafka 下消息的类别,是逻辑上的概念,用来区分、隔离不同的消息数据。开发人员只需关注数据写入哪个 topic,从哪个 topic 取出数据。
2)Partition:Kafka 下数据存储的基本单元,是物理上的概念。同一个 topic 的数据,被分散的存储在多个 partition 中,这些 partition 可以在一台机器,也可以再多台机器。【这种方式在大多数分布式存储中可看到,例如 ES 的分片技术】
优点:1)有利于水平扩展,避免单台机器在磁盘空间和性能上的限制;2)通过复制来增加数据冗余性,提高容灾能力。
3)Consumer Group:逻辑上的概念,是 Kafka 实现单播和广播的手段。同一个 topic 的数据,会广播给不同的 group,同一个 group 中,只有一个 workers能拿到这个数据。通过多线程或多进程来实现。
生产消费者模式
Producer 负责接收前端上报的数据,投递到对应的 topic 中,在 Consumer 端,所有对该数据感兴趣的业务都可以建立自己的 group 来消费数据。单一 group 内的 worker 个数取决于数据量及业务的实时性。
#include <thread>
#include <iostream>
#include <queue>
using namespace std;
class Queue {
public:
queue<int> mq;
mutex mutex_; // 互斥锁
condition_variable cond_; // 条件变量
int maxnum; // 设置队列的长度
/*
* 此用例通过判断 mq 的长度是否满,免去 Cond_Full
*/
public:
Queue(int maxn = 20) : maxnum(maxn) {}
bool Push(int val) {
if (mq.size() >= maxnum) {
cond_.notify_all(); // 通知消费者读取
return false;
}
// unique_lock RAII 机制的互斥锁
unique_lock<mutex> locker(mutex_); // 使用局部锁
mq.push(val);
cond_.notify_all(); // V() 使用结束,通知消费者获取
return true;
}
int Pop() {
unique_lock<mutex> locker(mutex_);
while (mq.empty())
cond_.wait(locker);
int val = mq.front();
mq.pop();
cond_.notify_all();
return val;
}
};
void Producer(Queue *q) {
for (int i=0; i<1000; ++i) {
if (q->Push(i))
cout << "Push:" << i << endl;
else
cout << "Push failed!! " << endl;
this_thread::sleep_for(chrono::seconds(1));
}
}
void Consumer(Queue *q) {
for (int i=0; i<500; ++i) {
auto data = q->Pop();
cout << "Pop:" << data << endl;
this_thread::sleep_for(chrono::seconds(1));
}
}
int main() {
Queue q(10);
thread t1(Producer, &q);
thread t2(Consumer, &q);
t1.join();
t2.join();
return 0;
}
让你手写观察者消费者模型,会涉及哪些 api?
对于被观察者:1)核心的 notify() —— 维护一个数组,存放它的观察者,遍历这个数组,对所有对象进行发送消息;2)append 观察者;3)remove 观察者;
对于观察者:1)核心的 update() —— 收到被观察的信息的处理函数;2)append 被观察者;3)remove 被观察者;
#include <iostream>
#include <vector>
using namespace std;
class Observer {
public:
virtual void update(int data) = 0;
};
class ObserverCat : public Observer {
public:
void update(int m) {
m_state = m;
cout << "ObserverCat Update m = " << m_state << endl;
}
private:
int m_state;
};
class ObserverDog : public Observer {
public:
void update(int m) {
m_state = m;
cout << "ObserverDog Update m = " << m_state << endl;
}
private:
int m_state;
};
class Subject {
private:
vector<Observer*> ObserverVec;
public:
// 对象注册新的观察者
virtual void Register(Observer* pObserver) {
ObserverVec.push_back(pObserver);
}
// 对象取消特定的观察者
virtual void UnRegister(Observer* pObserver) {
for (auto it=ObserverVec.begin(); it!=ObserverVec.end(); ++it) {
if (*it == pObserver) {
ObserverVec.erase(it);
cout << "Unregister success !!!" << endl;
break;
}
}
}
virtual void Notify(int data) {
for (auto it=ObserverVec.begin(); it!=ObserverVec.end(); ++it) {
(*it)->update(data);
}
}
};
int main() {
ObserverCat obCat;
ObserverDog obDog;
Subject sub;
sub.Register(&obCat);
sub.Register(&obDog);
sub.Notify(5);
sub.UnRegister(&obCat);
sub.UnRegister(&obDog);
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号