机器学习深度学习八股
1、 逻辑回归如何实现多分类?
修改逻辑回归的损失函数,使用 softmax 函数构造模型解决多分类问题。
2、监督学习和无监督学习的区别
输入的数据有标签则为监督学习,输入数据无标签为非监督学习。
3、训练集中类别不均衡,哪个参数最不准确?
准确度(Accuracy)
解析:举例,对于二分类问题来说,正负样例比相差较大为99:1,模型更容易被训练成预测较大占比的类别。因为模型只需要对每个样例按照0.99的概率预测正类,该模型就能达到99%的准确率。
4、分类算法有哪些?
单一的分类方法主要包括:LR逻辑回归,SVM支持向量机,DT决策树、NB朴素贝叶斯、NN人工神经网络、K-近邻;集成学习算法:基于Bagging和Boosting算法思想,RF随机森林,GBDT,Adaboost,XGboost。
5、谈谈交叉熵
交叉熵可在神经网络中作为损失函数,p 表示真实标记的分布,q 为训练后的预测标记分布,用于度量两个概率分布间的差异性信息。

6、Loss Function 有哪些,怎么用?
平方损失(预测问题)、交叉熵(分类问题)。
7、正负样本不平衡的解决办法?评价指标的参考?
在 CV 方面,使用 Focal Loss。
好的指标:ROC 和 AUC 、F1-score、G-mean
不好的指标:Precision、Recall
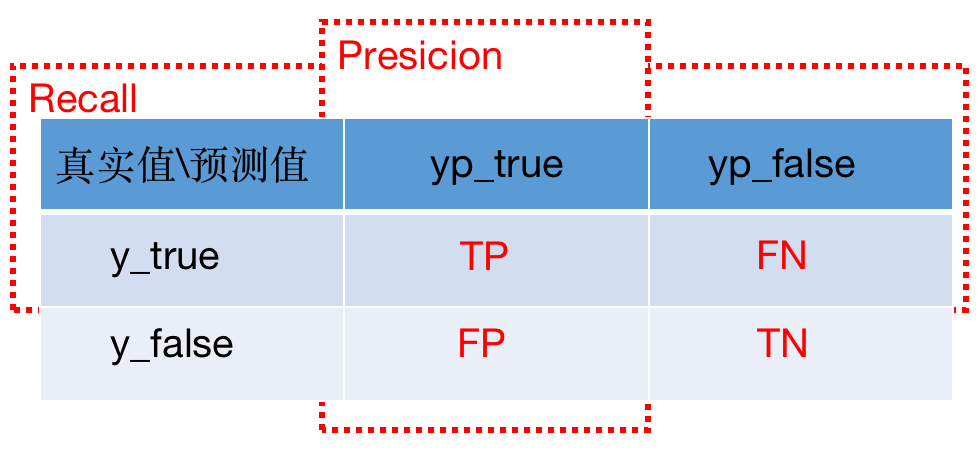
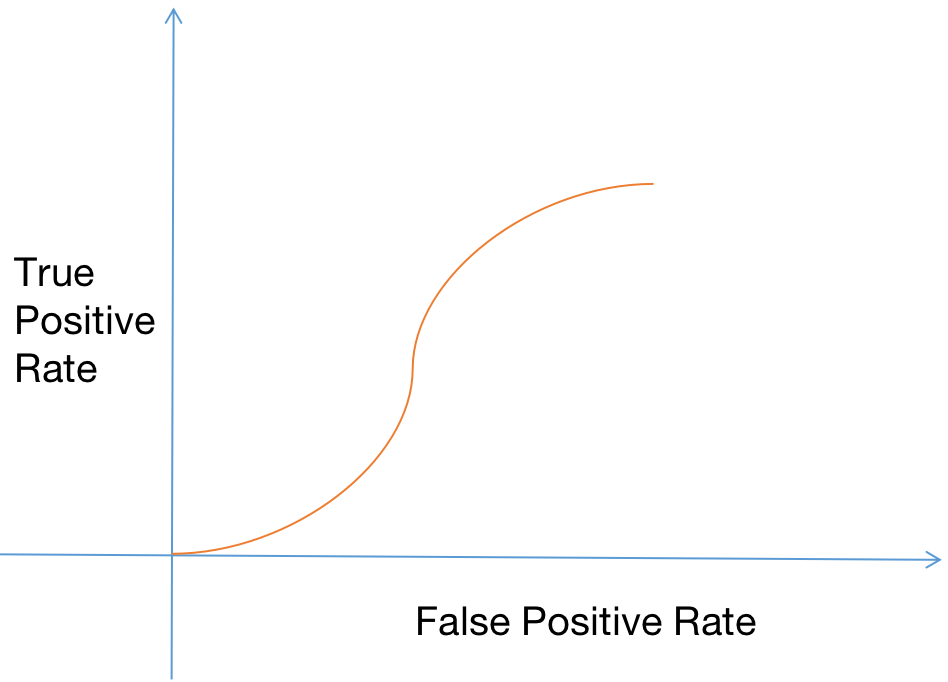
在知道 Precision、Recall 的前提下,如何衡量模型的优劣?
不断地取调整模型的阈值,看看不同阈值条件下,True Positive Rate 与 False Positve Rate 的比值。
8、如何防止过拟合?
1)增加样本数;2)正则化;3)使用不太重的模型;4)使用 dropout
9、什么是 dropout ?
dropout 的作用是防止过拟合。
10、梯度消失、梯度爆炸的问题
由于梯度求导的过程中梯度非常不断累积相乘,以至于很大很大,称为梯度爆炸;
由于梯度求导的过程中梯度非常不断累积相乘,以至于很小很小,称为梯度消失。
解决办法:正则化
11、RCNN、Faster-RCNN、YOLO 的区别
1)RCNN 与 Faster-RCNN
相同:二者都属于两阶段识别图片目标的方法,第一阶段获取候选框 Region Proposal (通过卷积提取 feature map,再通过 anchor boxes在 feature map 上提取候选框);第二阶段在 Region Proposal 上进行分类。
不同:二者的区别只在于获取 Region Proposal 的方式不同,还在损失函数及其他地方做了些优化。
2)YOLO
YOLO 原理:1)将图片 resize 后,resize 成 m*m 的网格;2)对于每个网格,都预测目标置信度,以及在多个类别上的概率;3)由于有多个 anchor,会出现多个预测框,对每个预测框先进行阈值过滤,再使用基于 IOU 进行 NMS。
RCNN 与 YOLO 不同:YOLO 是一阶段将目标检测作为回归问题解决。它将目标检测任务当成回归问题,而不是分类问题。
12、RNN、LSTM、GRU、Transformer 的区别
1)RNN
RNN 将每次网络的输出都保存在一个记忆单元中,将记忆单元进行权重调整,并与下一次的输入一起送入神经网络中。
问题:1)RNN 会导致梯度爆炸问题;2)只考虑近期的状态
2)LSTM
LSTM 的精髓是引入了细胞状态的概念,可以决定哪些状态应该被留下来,哪些状态应该被遗忘,从而实现长期记忆。
3)GRU
加入了 2 个门 —— reset 门和 update 门。reset 门用于确定前一步的隐状态有多少可以输入当前步,update 门用于确认当前步的隐状态有多少可以输出下一步。
与 LSTM 相比:参数更少,模型更容易收敛。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号