OO_U3总结
一、简介
- 本单元学习了JML进行规格化设计。JML通过前置条件、后置条件、副作用等对方法与类进行约束,而编程者只需要保证自己的代码实现符合JML规约,便可以保证程序的正确性。这大大化简了代码编写过程中的思考,降低了出错的概率,防止方法或者类之间过度耦合,也改善了一边架构一边写,想到哪里就写到哪里,想错哪里就改一大片这种问题,并且在多人协作各自不同分工时便于代码的整合。
- 虽然JML大幅化简了代码的编写,但实际上这是一种将设计架构与代码编写分开的过程。JML描述本身代表了整体的架构设计,因此先写出完整的JML,后进行代码编写,实际上难度并不会比边想边写低,必须先保证所有JML的准确性,否则代码也无法保证正确性。不过本单元作业的JML已经给出,所以难度降低了很多。
二、关键类的设计与架构
1. 类图
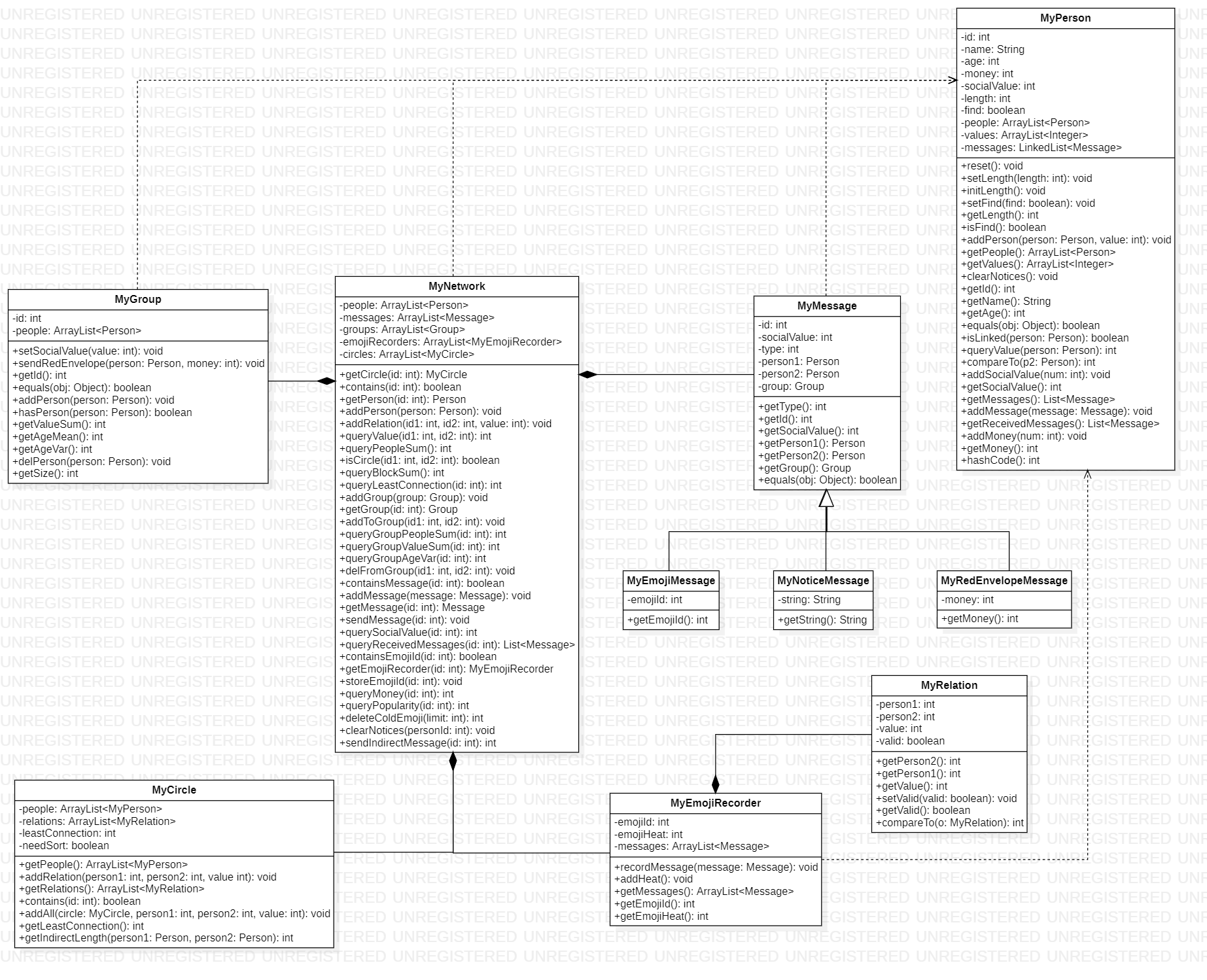
2. 设计与架构
- 在第一次作业中,我定义了MyCircle类,用于记录同个圈子内的人,每个人在增加到NetWork时自己为一个圈子,当添加与他人的关系时,会将两个圈子内合并,如果是同一个圈子内不同的人,则不需要更改,这样做可以使查询两人是否在同一个圈子的方法的时间复杂度降低,但必须满足关系只增不删,否则无法维护。
- 在第二次作业中,求最小生成树的方法借助于MyCircle类实现,一个圈子的最小生成树不会涉及其他圈子。
- 在第三次作业中,新增自定义类MyEmojiRecorder,用于记录使用了同一个emoji的消息的引用,便于删除消息,同时求最短路径也使用了MyCircle类的方法,图的关联性很强,好的类会有更高的扩展性。
三、性能策略
1. 并查集
- 如设计与架构中所说的,使用MyCircle类,将同一个圈子的人直接保存在MyCircle中的容器,查询同一个圈子的时候,只需要根据是否包含这个人找到这个圈子,一个人不会同时存在于不同圈子中,圈子动态维护,保证复杂度被均分到整个进程。
2. 最小生成树
- 最小生成树使用加边法,将同一个圈子中所有的边,按从小到大排序,每次加一条最短的边,如果成环则不算入有效边,直到加入n-1条有效边,n为一个圈子中的节点总数,此时得到即为最小生成树。对于判断是否成环,依旧使用并查集方式,每个节点先属于一个集合,加边时如果加在了不同集合的点,则合并集合,视为有效边,否则为无效边,并删除。
3. Dijkstra算法计算最短距离
- 对于两点之间的最短距离计算,使用堆优化的Dijkstra算法,最基础的Dijkstra算法需要维护一个n*n的可达矩阵,每次计算都要找到离起点距离最近的并且没有使用过的点,用它的边去更新所有其他未找到的节点到起点的距离,这样是n^2复杂度。堆优化指的是,首先放弃可达矩阵,使用邻接表,这样每次更新不需要更新所有的点,只需要更新指定节点可到达的节点,其次,使用基于最小堆实现的优先队列PriorityQueue,保证由小至大的顺序,每次poll取出并删除第一个节点,这样优化了寻找最小节点的时间,当然优先队列插入依旧需要logn复杂度,即总复杂度降至n*logn。
- 实际上经典的Dijkstra算法适用于稠密图,而堆优化的Dijkstra算法适用于稀疏图,当稠密时堆优化的复杂度会比经典的高。因为堆优化的实际实现复杂度为n*k*logn,k为每个节点的度数,即每个节点的邻接点个数,logn为每次更新一个邻节点并插入优先队列需要消耗的复杂度,所以边越少度越小计算越快,适用于稀疏图。而经典Dijkstra算法实际复杂度为n*(n+n),因为查找需要n,更新需要n,因此节点数越少越快,即稠密图。
- 不过由于数据的限制,稀疏图很容易构造令经典的Dijkstra算法超时,而稠密图再稠密也无法令堆优化的Dijkstra算法超时。即快的时候大家都快,不过有的人更快一点,慢的时候之前快的人就太慢了。
四、针对JML测试
- 这次手动写了一个数据生成器,根据JML规格进行数据的构造,实际上这样做有效的数据大大增加,但也有一定的问题,那就是需要排列组合,规格很多,要想涉及每一种可能性,需要不停调整数据生成器的规则。结果是,尽管我写了很多种生成数据的规则,但是排列组合的情况不够全面,导致生成的数据大部分在合理数据内,对于基础的功能测试比较完善,但对于异常情况测试的不够充分。
- junit单元测试,可以用断言来判断测试结果是否正确。
五、bug与修复
- 在第二次与第三次作业中受到了hack。第二次作业中求Group中所有人的距离,按JML规格是n^3级复杂度,解决方法不是很有效,即只算一半,最后×2。
- 在第三次作业中是由于没有使用堆优化的Dijkstra算法,在上述中也分析过,堆优化的实际实现复杂度为n*k*logn,经典Dijkstra算法实际复杂度为n*(n+n),不过没有经过测试就想当然了,吃了亏,解决办法就是使用优先队列优化复杂度。
六、NetWork扩展作业
1. 生产产品
/*@ public normal_behavior
@ requires contains(id) && (getPerson(id) instanceof Producer);
@ assignable getPerson(id).productsNumber;
@ ensures getPerson(id).productsNumber ==
@ \old(getPerson(id).productsNumber) + 1;
@ also
@ public exceptional_behavior
@ signals (ProducerIdNotFoundException e) !contains(producer) ||
@ (contains(producer) && !(getPerson(producer) instanceof Producer));
@*/
public void produce(int id) throws ProducerIdNotFoundException;
2. 发送广告
/*@ public normal_behavior
@ requires containsMessage(id) && (getMessage(id) instanceof Advertisement);
@ assignable messages;
@ assignable people[*].messages;
@ ensures !containsMessage(id) && messages.length == \old(messages.length) - 1 &&
@ (\forall int i; 0 <= i && i < \old(messages.length) && \old(messages[i].getId()) != id;
@ (\exists int j; 0 <= j && j < messages.length; messages[j].equals(\old(messages[i]))));
@ ensures (\forall int i; 0 <= i && i < people.length;
@ (\forall int j; 0 <= j && j < \old(people[i].getMessages().size());
@ people[i].getMessages().get(j+1) == \old(people[i].getMessages().get(j))) &&
@ people[i].getMessages().get(0).equals(\old(getMessage(id))) &&
@ people[i].getMessages().size() == \old(people[i].getMessages().size()) + 1);
@ also
@ public exceptional_behavior
@ signals (AdvertisementIdNotFoundException e) !containsMessage(id) ||
@ (containsMessage(id) && !(getMessage(id) instanceof Advertisement));
@*/
public void sendAdvertisement(int id) throws AdvertisementIdNotFoundException;
3. 购买产品
/*@ public normal_behavior
@ requires contains(id) && (getPerson(id) instanceof Producer);
@ assignable getPerson(id).productsNumber;
@ ensures getPerson(id).productsNumber ==
@ \old(getPerson(id).productsNumber) - 1;
@ also
@ public exceptional_behavior
@ signals (ProducerIdNotFoundException e) !contains(producer) ||
@ (contains(producer) && !(getPerson(producer) instanceof Producer));
@*/
public void purchaseFromProducer(int id) throws ProducerIdNotFoundException;
七、心得体会
- JML对于编程的规范化非常实用,并且极大降低了出错的可能性,不过在实现时仍需要代码实现,所以更需要关注在基本逻辑正确的前提下,保证代码细节的正确性,JML的撰写能力是否优秀也会决定程序的复杂度。
- 对于时间开销,第一次感受到算法不同时造成的巨大差异,比如室友在使用类与类之间进行多层HashMap嵌套时出现了远高于多层ArrayList的时间开销,所以代码的底层实现原理也需要考虑。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号