OO_U1总结
OO_U1总结
一、简介
1. 第一次作业
- 本次作业是简单的多项式化简,我将输入划分为表达式、项、因子三个层次进行解析。本次作业难点主要在于表达式因子相乘或加减的情况。在训练中官方提供的思路为递归下降解析,但是我使用的并非这个方法,我在每一个层次进行解析再下发给下一个层次,这是一种逻辑上较为简单的方法,但实现时需要处理好几处细节。
2. 第二次作业
- 本次作业新增了三角函数、自定义函数、求和函数,通过面向对象思维进行设计可以较快完成任务。我对代码进行了重构,在要求的基础上进行了大量扩展,主要为了多层嵌套处理与更稳定的乘法与幂的计算。
3. 第三次作业
- 本次作业主要是多层嵌套
(因为押对了没怎么看要求)。得益于第二次重构对自己提出的更高的要求,第三次作业只对三角函数的结果加了一层括号,没有其他改动。
二、设计与架构
1. 第一版
-
类图

-
功能实现
预处理:第一版表达式的分解与合并是分开实现的,在获取到输入准备分析前,先进行了预处理,消去了所有空格以及多余的正负号,这主要是通过工具类NoSpace中的方法完成的。关于负号,受到室友的启发,在预处理中全部转换为-1*的形式,减少了很多要考虑的问题
(有些类中因此出现了冗余的方法但是不敢改)。识别与拆分:在表达式层次,每次要识别到下一个有效正负号才能截取出一个项传给下一层,使用Stack来记录括号,也就是要完整的识别每一对括号,包括嵌套的括号,这个方法也在项到因子层进行了使用。在项层次,每次识别到有效乘号进行截取,再进行最后的因子识别,因子通过继承相同父类实现多态。其中表达式因子会递归进入表达式层次,完成嵌套括号的拆分。
返回拆分结果:每个层次都有toString的重写,在处理表达式乘法时使用工具类MulNew中的方法,处理项的因子相乘也使用同样的方法,依赖多态判断区分。当然这也导致了第一版不够面向对象的问题,在多层嵌套时拆分会出现错误。
化简合并:在化简合并阶段实例化ExpNew类并将所有因子转换为标准项StandardTerm,这里会统计指数、系数、变量名,通过hashmap建立键值对,进行相同项的合并。同样来自于室友的建议,出现了x*x<x**2这种计算方法。
-
性能分策略
第一版所涉及的性能分并不多,除去合并同类项,还有考虑了指数为0、1、2情况,+位于句首可以消去等细节。这些在StandardTerm的toString方法与工具类中NoSpace的部分方法完成。
-
存在的问题
实际上第一版并不够体现面向对象思想,在处理多层括号时会有所问题,并且由于并非边处理边化简,在超长的数据如(x+1)**1000这种会出现爆栈
(虽然这种数据不存在,但我还是希望能处理)。于是乎有了重构的第二版。
2. 第二版
-
类图

-
功能实现
多层嵌套处理:第二版虽然是重构,但是大部分逻辑依旧继承自第一版,所以乘法依旧依赖自因子的多态,即乘法时会调用表达式因子的toString方法。表达式在转换为字符串时一律使用“P”代替“+”将各项连接,这样在乘法时可以直接进行判断而无需担心乘错。每次进出表达式,都进行全套预处理保证不会出现额外的符号、空格等影响嵌套计算的东西,保证每次递归出入的内容都是标准形式。
新增函数:自定义函数引入工厂,工厂负责处理与保存自定义函数的定义。自定义函数内部识别替换变量后转换为表达式,带入表达式因子获取结果;求和函数则是将每次带入表达式因子获取到的结果相加;三角函数直接带入表达式因子获取结果。表达式因子得到了更充分的复用。
避开关键词的替换策略:对于sin与sum结合时i的替换与自定义函数对于xyz先后顺序的替换,存在着很大的坑点。对于避开特定内容如sin中的i,我的处理办法是:先找到关键词,再截取从上一个标记位到关键词前的内容,replace其中的全部变量,因为这部分内容中完全不用担心有关键词,接着直接跳过关键词,更新标记位,直到结尾。
防止重复替换的策略:对于xyz先后顺序问题,不能直接replace是由于替换没有从头到尾顺序一次执行完成,如果能够一次性顺序完成替换,不论xyz亦或是其他再冒出来的新情况,都可以直接处理,我的处理办法是:首先继承自刚刚对于跳跃关键词的处理,在每次截取出一段后,使用x|y|z|i|j|k|xxx这种方式将要替换的变量组成正则语法,再顺序使用matcher.find()查找,这样每次都会查找到最近的一个变量,matcher.find()的官方说明是每次找到后下一次查找的起始位置都会从上一次结果的结尾+1开始(说人话就是查找范围不会重叠)。这样一路替换就是顺序的一次性替换,谁在前就替换谁,不存在重复识别到相同变量的问题。
降低耦合:在第一版中,一些类的耦合情况不够明显,但是如果不改动并直接新增至第二版,会造成更复杂的耦合,比如第一版的化简工具类NoSpace,在第二版中我将部分的化简功能直接分配到了各个类的toString方法,做到边分析边化简
(超长的(x+1)**1000之类的也可以不用爆栈了)。总结就是要增加内聚,调整了一些方法的位置。 -
性能分策略:首先合并同类项大改,考虑到不同变量与各自的指数,在转化为标准项StandardProperty时使用hashmap存储变量和各自的指数,并实现了Comparable接口来进行排序。这里听说有的人直接更改容器内容导致结果出错,于是就给每个标准项设置了一个标记位del,来表示自己是否已经被合并到其他项之中,在最后转化时过滤掉这些项。合并前有个判断是否可以合并的方法ableToAdd(),这里可以如果追加内容可以配合合并方法add()进行三角函数的合并,不过我摆烂了,重构好几天吃不消了。
-
存在的问题:这次存在的问题是代码冗余,在重构过程中有些地方已经将坑点处理了,而到了其他地方又试图处理了一遍,然后怕改错又不敢删除。其次是功能多余,比如每个因子都上了一个指数,指数都上了指数,以及求和函数甚至可以使用表达式作为求和起始条件与结束条件等
(被课程组弄怕了)。除此之外可以看到作为父类的Factor,并没有将子类共享部分的数据整合,这是因为重构时考虑不全,原本并没有共享数据的子类在大部分重构任务完成后又追加了新的属性,即没有分析好子类之间的关联。
三、基于度量的分析
1. 第一版
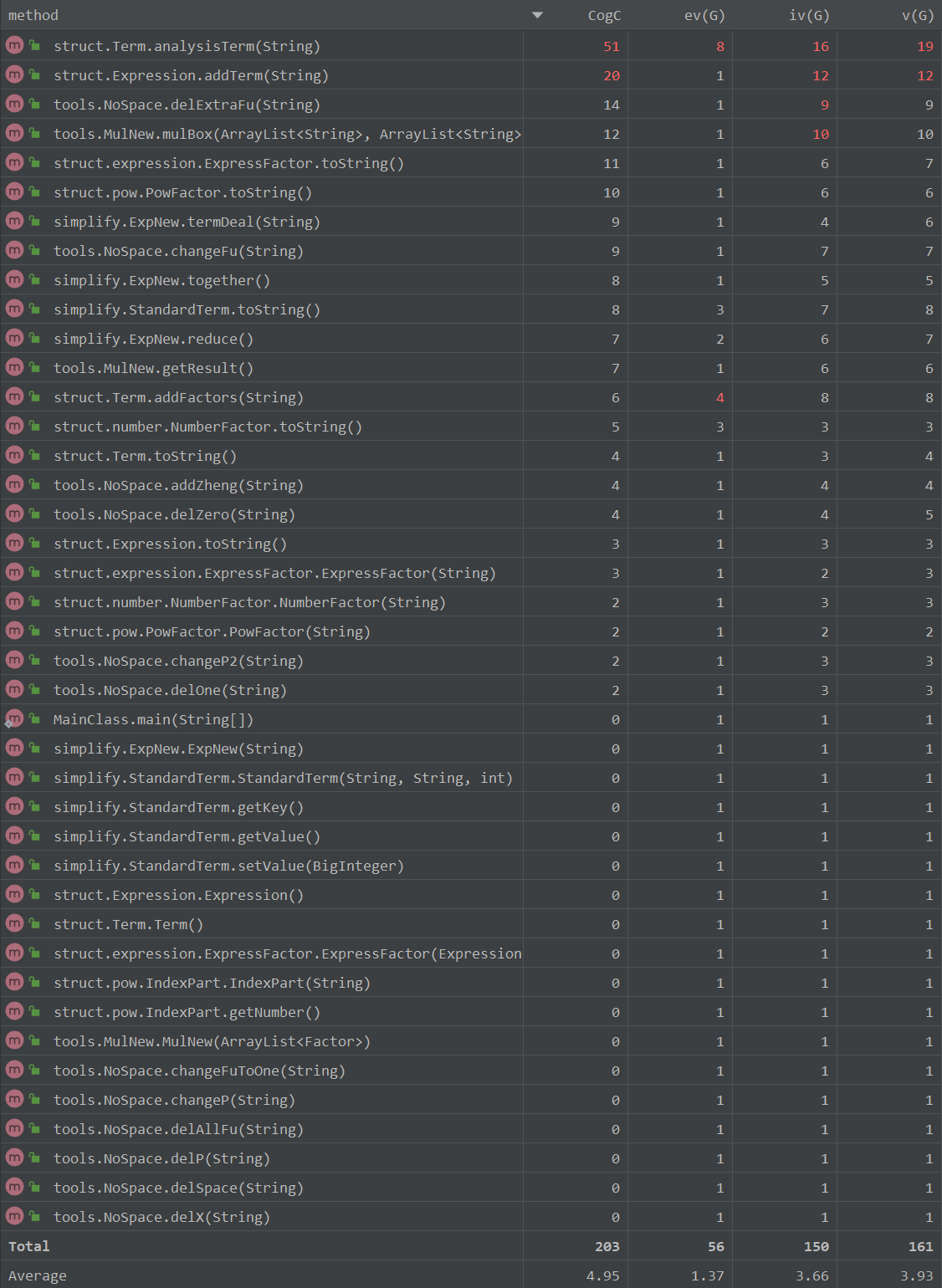
- 度量
对于方法有
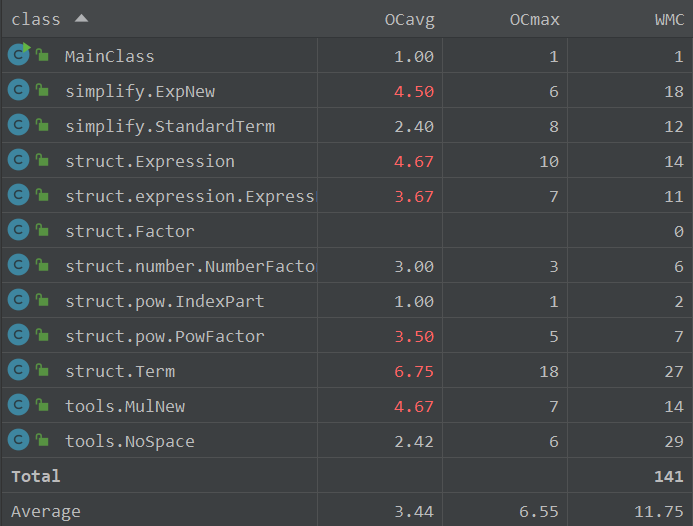
对于类有
- 分析
可以看到有的方法复杂度直接高爆了,其原因是为了第一次做为了避坑嵌套循环加过多的判断条件,许多共有要素没有被提取出,导致了代码重复,这个在第二版中进行了部分优化。自己思考的方法还是拥有过高的耦合度,偏于面向过程了。
2. 第二版
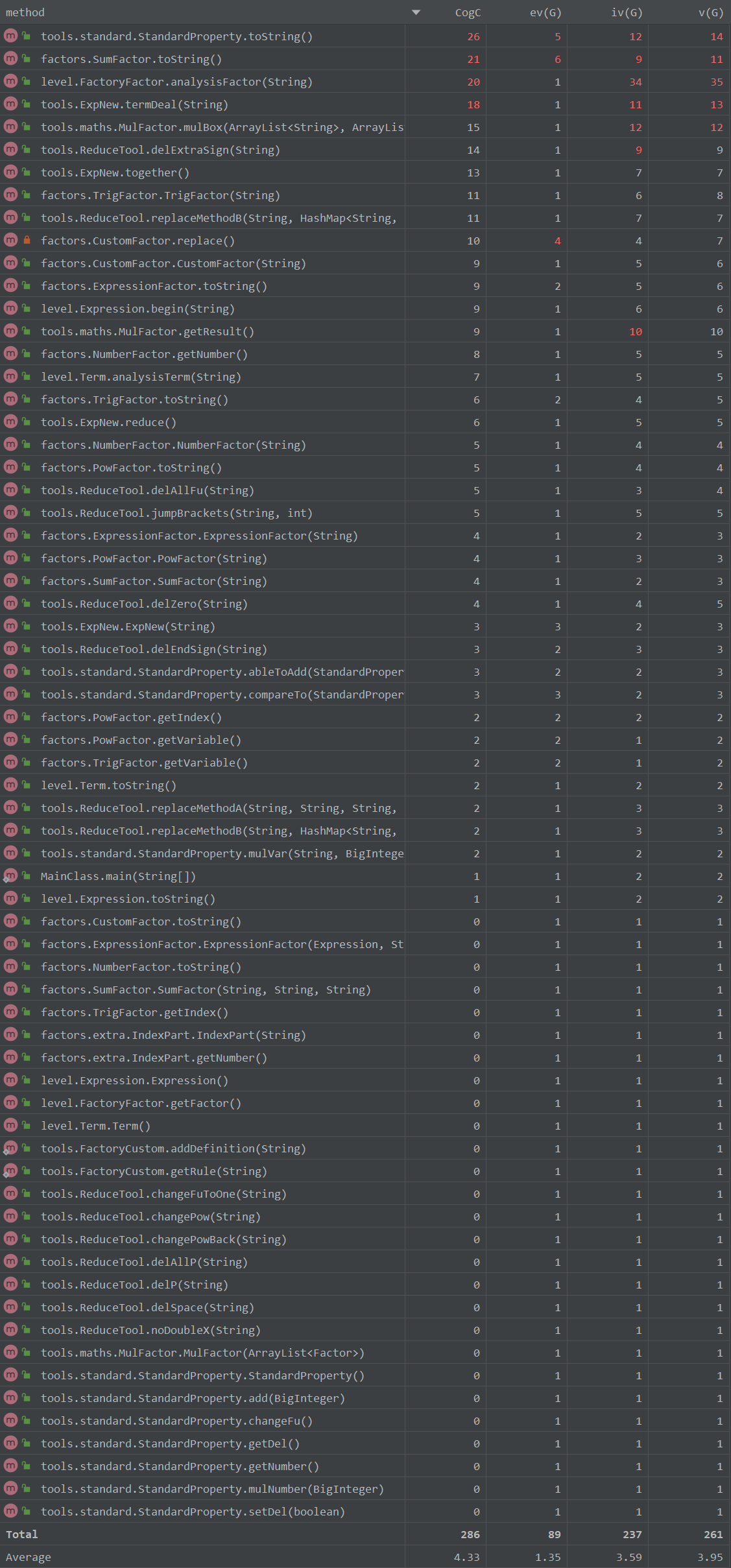
- 度量
对于方法有
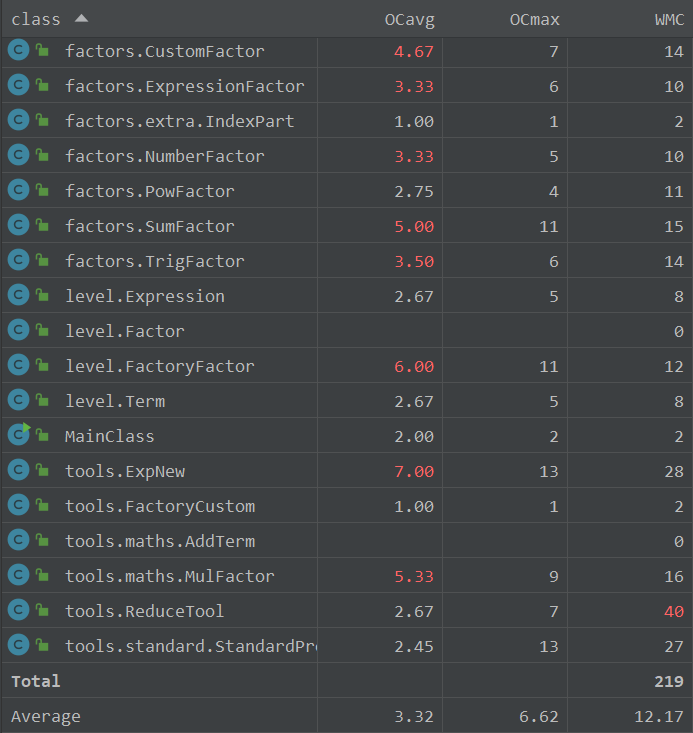
对于类有
- 分析
降了,但没完全降下来,重构中将许多公有部分提出与重整后,依旧没能将复杂度拉到较低水平。这次toString方法复杂度升高了,结合类图可以看出,有的类内部方法个数少,说明在类的内部,方法的划分不够合理,有的方法规模与分指数较多,这也不利于类自身的更新迭代。
四、测试与bug修复
1. 第一次作业
- 在第一次作业中,使用的为第一版架构,在测试时遇到了表达式因子相乘如果外面为负号,内部变号的问题,以及表达式因子带指数而外面为负号的问题,结合方法MulNew的复杂度可以看出这是由于对于乘法的处理方法不是很好造成的,最终解决方案是采取了室友的建议,将“-”转换为“-1*”,最终稳定渡过互测,也没有对其他人发起hack。
- 在学习其他人的代码时,我注意到了更好的预处理,对于“**”,替换为“^”更为合理,这也化简了我第二版的工作量。
2. 第二次作业
- 第二次作业使用的为重构的第二版,在形式验证通过后,我并没有使用大量的数据去验证,这也导致了求和函数的一个重大bug被强测抓到了
(不过互测不让用求和逃过一劫)。第一次调用求和函数时我便在循环加法时改变了其下限,指数调用自身时后续都无法求出结果,这与深拷贝浅拷贝问题相似,在改变数据时必须考虑全面,不过这次的错误与复杂度脱勾了。
3. 第三次作业
- 第三次作业使用的为第二次作业,在第二次基础上只对三角函数套上了双层括号,这是因为我的三角函数内部是由表达式因子求结果,虽然可以改但是求稳就没有再调整。然后强测互测都被hack了一次(悲)。出问题的仍是求和函数,求和函数下限可以大于上限,不仔细读题的后果,又是与复杂度脱钩的问题。
五、互测
-
第一个是复杂度与耦合度问题,在第一次作业的互测中就感受到了递归下降的巧妙,自己的方法在更新迭代时面临的局限性。在第二次作业中进行了大量的优化,类与类之间的耦合降低,但是类内部方法的划分仍不够合理。形式验证上通过即可稳定通过测试,但是对于超长超大量数据会有问题,虽然这部分在作业上没有要求,但是是与别人的架构相比发现的问题。
-
在第三次互测时成功进行了hack,是手动分析并造出的数据,hack策略为:首先分析第二次作业与第三次作业要求,第三次互测多出了求和函数,并且允许嵌套,那么最容易出问题的便为表达式因子、求和函数、三角函数之间的嵌套,再对一些可能性排列组合,可以筛选出一些易错的数据。
六、心得体会
-
经过本单元的学习,我初步掌握了面向对象的层次化设计方式,对于类该如何划分,对于行为与数据该如何抽象,对于不同层次的数据方法之间该如何管理与协作。同时也初步了解了递归下降的方法,看到了不同人对于同一个任务的不同处理方式,这些设计也拓展了我的思维。
-
程序的鲁棒性不能只由形式验证完成,对于好的架构设计,往往易于验证,并且耦合度低内聚度高的程序更便于维护,在迭代时往往不会只剩重构一个选择。如何降低复杂度,优化设计,是一个必须掌握的能力。
-
闭门造车使不得,室友与讨论区大佬的想法对我的作业起着很大的帮助,尽管设计不同,但是有的坑是不讨论想不到的。
(就连评测姬也出现了cox当成cos的情况) -
下次一定用官方推荐思路。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号