mybatis 调用存储过程 示例
准备工作(新手看)
1.创建一个mybatis映射类

只需要创建接口就行,无需创建实现类
2.创建一个mybatis映射文件

注意:
mapper.xml的namespace必须和mapper.java类所在的全路径保持一致,否则无法完成映射;
mapper.java的方法名称必须和mapper.xml的id,名称保持一致,否则方法和SQL匹配不上。
2.确保springboot能够扫描到该类

3.确保spring能够扫描到mapper.xml
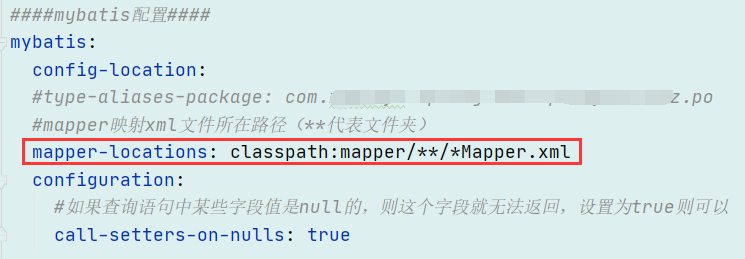
在application.yml配置文件中指定扫描路径
具体实现:
说明:这里调用的是mysql存储过程。
方式一:入参全部罗列出来,返回参数用map接收;
java方法
Map<String, String> getOrgCurrentno(String orgCode, String invoicingClerk, String ivcType, String medicalType);
xml
<!-- id="getOrgCurrentno"一定要与dao层需要匹配的方法名一致 -->
<select id="getOrgCurrentno" statementType="CALLABLE" resultType="java.util.Map">
<![CDATA[
{call PRO_GET_IVCVOUCHER_NUMBER(#{orgCode,mode=IN,jdbcType=VARCHAR},
#{invoicingClerk,mode=IN,jdbcType=VARCHAR},
#{ivcType,mode=IN,jdbcType=VARCHAR},
#{medicalType,mode=IN,jdbcType=VARCHAR},
#{aaa,mode=OUT,jdbcType=VARCHAR},
#{bbb,mode=OUT,jdbcType=VARCHAR})}
]]>
</select>执行结果如下:

语法:
{call 存储过程名称(#{变量名称},#{变量名称},...)}
或者不带{}也是可以的:
call 存储过程名称(#{变量名称},#{变量名称},...)
这里需要注意的是:
第一,statementType的值必须是CALLABLE,貌似是告诉mybatis将要执行的是存储过程;
第二,当返回数据类型使用map接收时,resultType的值可以有4种表现形式:java.util.Map/map/java.util.HashMap/hashmap;
第三,存储过程入参使用IN,返回参数使用OUT(IN和OUT必须大写);
第四,当数据类型不一致时,参数类型需要指定对应的jdbc类型;
第五,当使用map接收返回参数时,在xml中指定的名称与存储过程实际返回的参数名称并没有关系,例如:我上面随便起的aaa,bbb,对存储过程返回结果丝毫没有产生影响;
方式二:入参用java类,返参用map。
java方法
Map<String, String> getOrgCurrentno2(Map<String, String> paramsMap);
xml
<select id="getOrgCurrentno2" parameterType="map" statementType="CALLABLE" resultType="hashmap">
<![CDATA[
{call PRO_GET_IVCVOUCHER_NUMBER(#{aa,mode=IN,jdbcType=VARCHAR},
#{bb,mode=IN,jdbcType=VARCHAR},
#{cc,mode=IN,jdbcType=VARCHAR},
#{dd,mode=IN,jdbcType=VARCHAR},
#{ee,mode=OUT,jdbcType=VARCHAR},
#{ff,mode=OUT,jdbcType=VARCHAR})}
]]>
</select>返回的数据是一样的。
第六,到这里,我们就可以得出这样的结论:
入参和返参的参数名称对于mysql来说,没有丝毫影响,即使双方的名称不一样,只要保证顺序一样就是OK的;
第七,经过我的测试发现:
当入参使用map时,parameterType属性是可以不声明的,执行起来没有任何影响。
前4条是硬性规范,后3条只是为了证明不影响正常执行,也就是不规范的用法,最好还是遵守。
无意义深究
我们由上面的第5条和第6条,知道:
对于存储过程来说,它只关注入参和出参的顺序,不关注:参数名称是否和存储过程所需要的形参名称是否一致的问题(这一点和我们调用java方法是一样的,只关注顺序);
唯一起作用的就是:IN和OUT;
存储过程入参
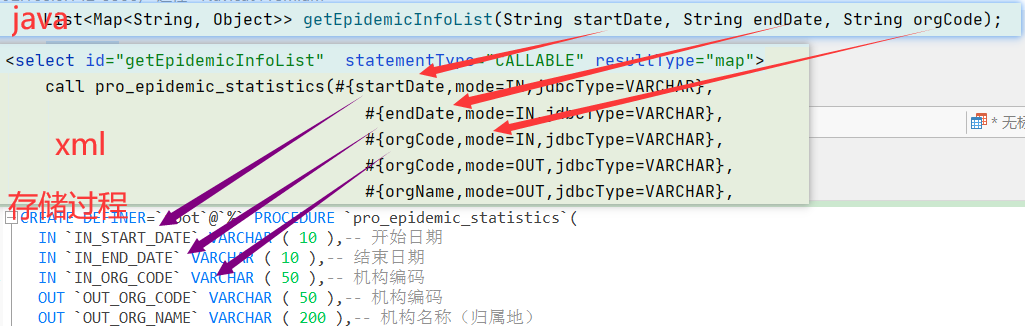
我们可以看到:
java-->xml:xml关于入参的引用,必须要和java当中的参数名称必须匹配,不然获取不到对应的数值(与java入参的顺序无关);
xml-->procedure:xml对于procedure的调用,存储过程只关注入参的顺序,不关注名称是否匹配。
存储过程出参
先看map
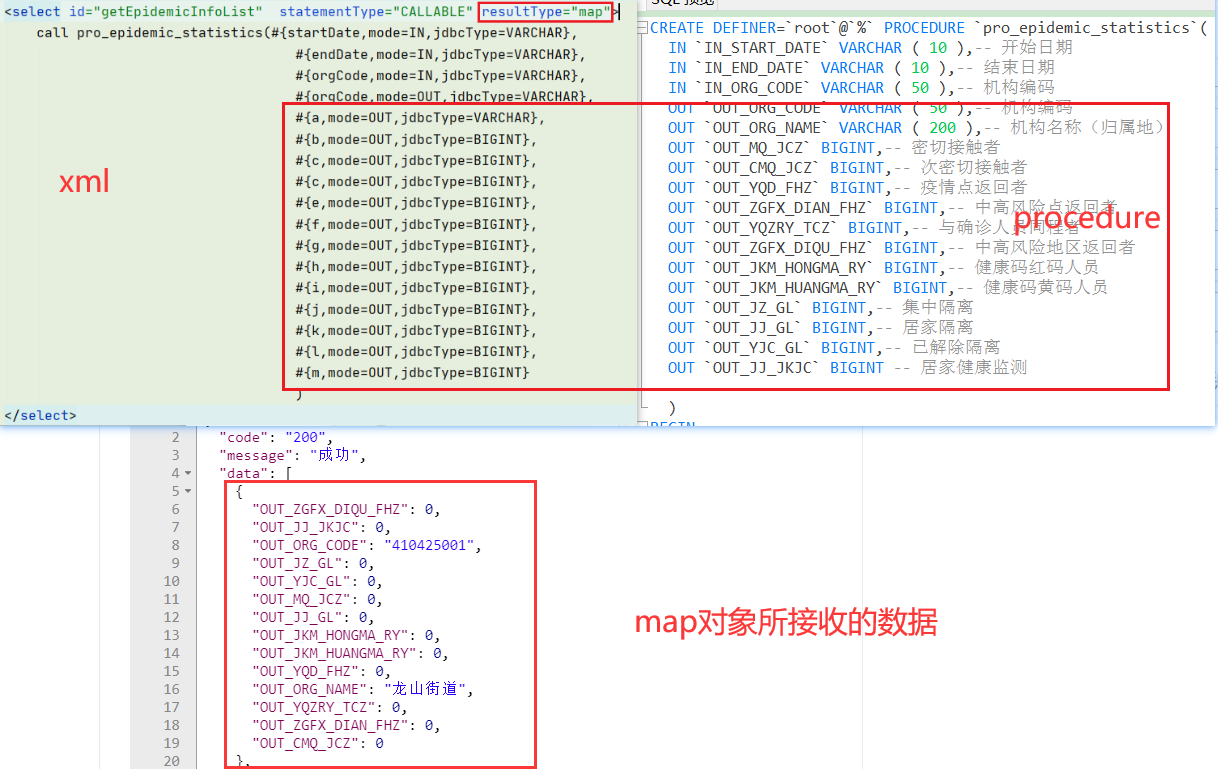
如果存储过程返回的结果集,使用map类来接收的话,我们可以通过上图看到:
对于xml来说,它只关注存储过程返回了什么,而不关注xml配置的那些出参的名称与存储过程返回的字段名称是否匹配的问题;
也就是说:xml配置的返回参数名称形同虚设;
最终,会将存储过程返回的字段名称作为map的key完成数据的接收工作。
再看实体类
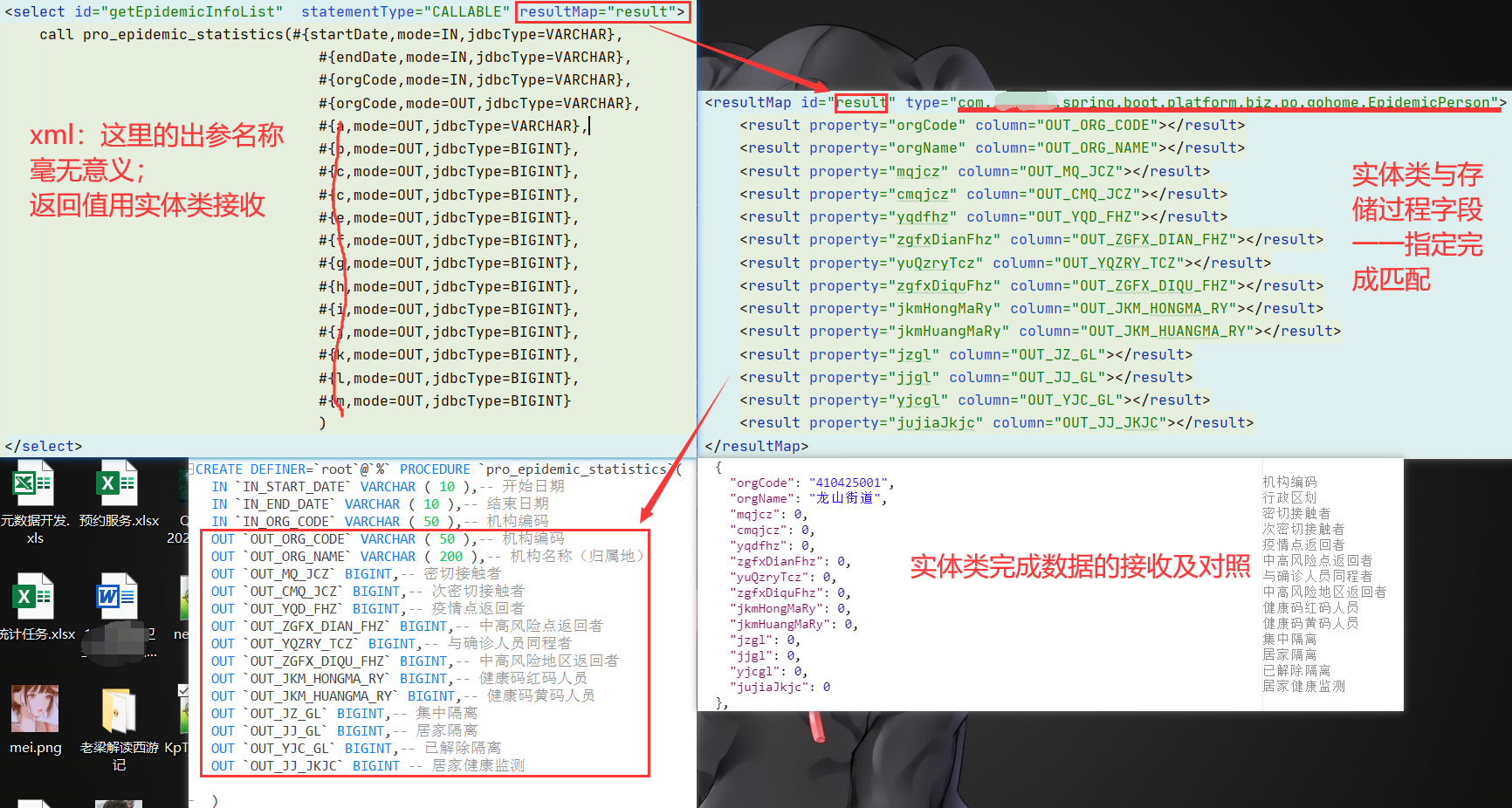
我们可以看到:
当我们用实体类接收存储过程返回数据时,xml配置的出参名称,同样地,毫无意义;
当实体类的字段名称和存储过程返回的字段名称,没有完全对照上时,需要我们手动完成字段的映射、匹配工作。
关于存储过程的调用

结合上面的测试,我们知道:
xml调用存错过程,最终会将参数转换成?完成调用,这也是使得出参和入参的参数名即使和存储过程参数名称不保持一致,也能正常调用和接收返回数据的原因。
关于存储过程的返回参数,如果不需要咱们手动映射jdbc与mysql的数据类型的话,我们也可以使用占位符?来代表返回参数的声明。
<resultMap id="result" type="com.xyhsoft.spring.boot.platform.biz.po.gohome.EpidemicPerson">
<result property="orgCode" column="OUT_ORG_CODE"></result>
<result property="orgName" column="OUT_ORG_NAME"></result>
<result property="mqjcz" column="OUT_MQ_JCZ"></result>
<result property="cmqjcz" column="OUT_CMQ_JCZ"></result>
<result property="yqdfhz" column="OUT_YQD_FHZ"></result>
<result property="zgfxDianFhz" column="OUT_ZGFX_DIAN_FHZ"></result>
<result property="yuQzryTcz" column="OUT_YQZRY_TCZ"></result>
<result property="zgfxDiquFhz" column="OUT_ZGFX_DIQU_FHZ"></result>
<result property="jkmHongMaRy" column="OUT_JKM_HONGMA_RY"></result>
<result property="jkmHuangMaRy" column="OUT_JKM_HUANGMA_RY"></result>
<result property="jzgl" column="OUT_JZ_GL"></result>
<result property="jjgl" column="OUT_JJ_GL"></result>
<result property="yjcgl" column="OUT_YJC_GL"></result>
<result property="jujiaJkjc" column="OUT_JJ_JKJC"></result>
</resultMap>
<select id="getEpidemicInfoList" statementType="CALLABLE" resultMap="result">
call pro_epidemic_statistics(#{startDate,mode=IN,jdbcType=VARCHAR},
#{endDate,mode=IN,jdbcType=VARCHAR},
#{orgCode,mode=IN,jdbcType=VARCHAR},
?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?
)
</select>除了上面这种方式,xml与mysql的存储过程相结合还可这样使用:
存储过程最简单的调用方式(推荐使用)
存储过程将将出参全部废掉,只保留入参,直接返回结果集;
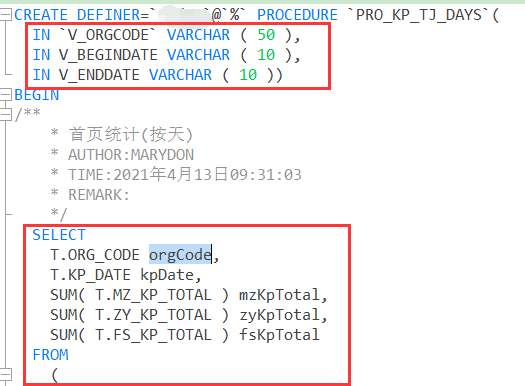
这样一来,xml的调用也会变得简单起来。
我们只要确保用来接收返回数据的实体类字段与存储过程返回字段相匹配即可。

这样做的好处在于:
不仅减少了xml与存储过程双方出错的概率,也降低了编码难度;
提高了返回值的可维护性。
2022年2月20日17:02:11
另外,关于存储过程的调用,call procedure(?,?),这里的入参是java类时,我们也可以使用paramMap进行映射;
需要注意的是:如果有出参的话,出参也需要统一配置到paramMap当中。
存储过程分页
关于总数查询,可以将总数当做结果集中的一列进行返回。
2022年2月14日18:09:39
如果数据量不多的话,如:<100条,我们可以使用java来手动进行分页,完成前后端数据的交互。
List分页示例
查看代码
// Step 3:查询数据
List<EpidemicPerson> epidemicInfoList = scPersonInfoManager.getEpidemicInfoList(startDate, endDate, orgCode);
// 总条数
int total = epidemicInfoList.size();
// 起始数
int start = (pageIndex - 1) * pageSize;
// Step 4:避免恶意传输:起始页 > 总条数,导致数组越界
if (start > total) {
return Results.page(new ArrayList<>(0), (long) total);
}
// Step 5:结束数处理
int end = pageIndex * pageSize;
end = Math.min(end, total); // 返回较小值,否则,数组越界
// Step 6:手动分页(将list中提取所需数据)
// 分页List
List<EpidemicPerson> pageList = new LinkedList<>();
// 从总数据中,返回分页数据
for (int i = start; i < end; i++) {
pageList.add(epidemicInfoList.get(i));
}
// Step 7:返回分页数据
return Results.page(pageList, (long) total);
写在最后
哪位大佬如若发现文章存在纰漏之处或需要补充更多内容,欢迎留言!!!
相关推荐:
本文来自博客园,作者:Marydon,转载请注明原文链接:https://www.cnblogs.com/Marydon20170307/p/14134373.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号