

Pyquery爬取豆瓣电影Top250
解析网页获取到电影排名,url.评分,星级数据
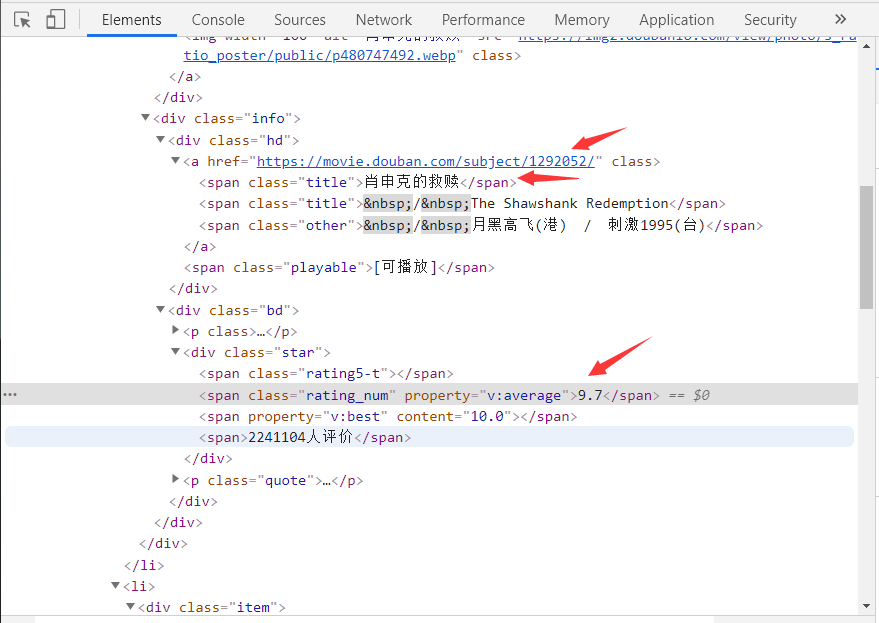
代码如下:
import requests from pyquery import Pyquery as pq # 这里做一个循环,因为每页都展示25部电影信息 for page in range(0, 250, 25): url = 'https://movie.douban.com/top250?start={}'.format(page) headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36' } html = requests.get(url, headers=headers).text html = pq(html) for item in html('.item').items(): num = item.find('.pic em').text() title = item.find('.title').html() link = item.find('.pic a').attr('href') star = item.find('.rating_num').text() file = open("爬取成功.txt", "a", encoding="utf-8") file.write('\n'.join([num, title, star, link])) file.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号