

爬取虎牙直播颜值类主播封面图
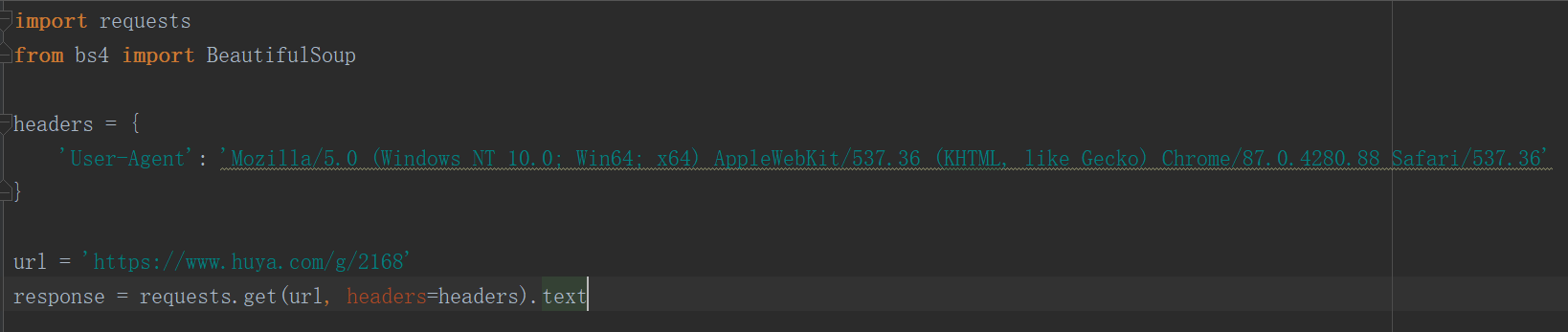
导入包,设置请求头,url地址
使用beatifulsoup解析网页,通过检查可以看到所有图片地址都在属性为class的“pic”中,直接提取。


在这个页面可以看到不止主播封面的图片,还有虎牙直播的logo,二维码等等,所以我们需要精确获取到主播图片的地址

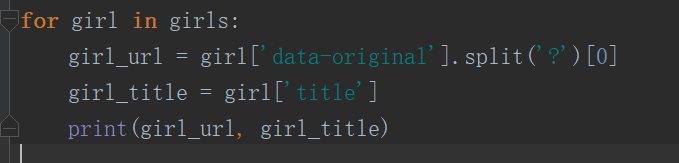
这里就不做保存图片,爬取如下:
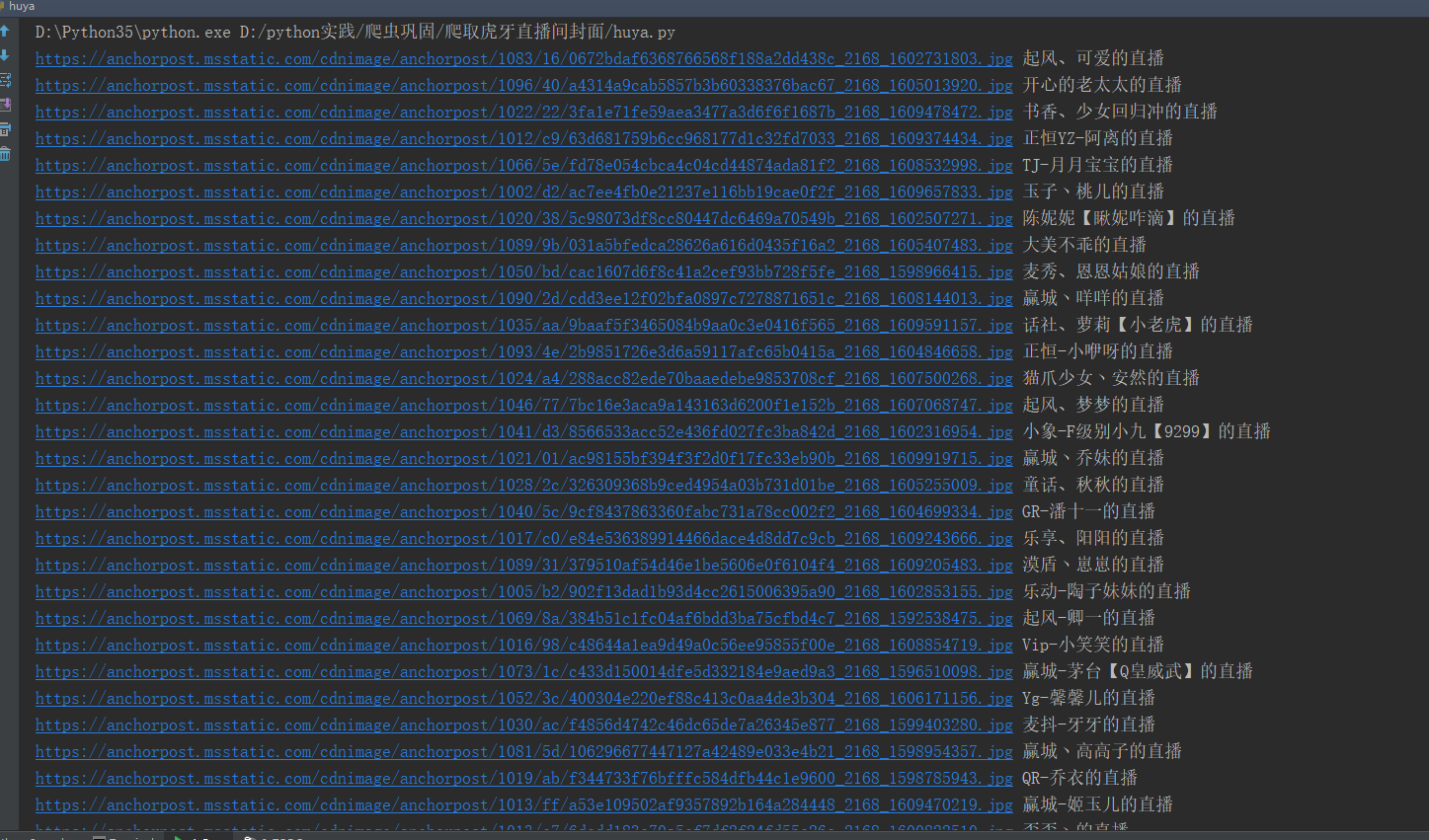
代码如下:
import requests from bs4 import BeautifulSoup headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36' } url = 'https://www.huya.com/g/2168' response = requests.get(url, headers=headers).text soup = BeautifulSoup(response, 'lxml') # class是关键字 它是声明一个类的所以加下划线 girls = soup.find_all('img', class_='pic') for girl in girls: girl_url = girl['data-original'].split('?')[0] girl_title = girl['title'] print(girl_url, girl_title)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号