

06 Spark SQL 及其DataFrame的基本操作
一.
1.Spark SQL出现的 原因是什么?
spark sql是从shark发展而来。Shark为了实现Hive兼容,在HQL方面重用了Hive中HQL的解析、逻辑执行计划翻译、执行计划优化等逻辑,可以近似认为仅将物理执行计划从MR作业替换成了Spark作业(辅以内存列式存储等各种和Hive关系不大的优化);
同时还依赖Hive Metastore和Hive SerDe(用于兼容现有的各种Hive存储格式)。
Spark SQL在Hive兼容层面仅依赖HQL parser、Hive Metastore和Hive SerDe。也就是说,从HQL被解析成抽象语法树(AST)起,就全部由Spark SQL接管了。执行计划生成和优化都由Catalyst负责。借助Scala的模式匹配等函数式语言特性,利用Catalyst开发执行计划优化策略比Hive要简洁得多。
2.用spark.read 创建DataFrame
参考http://www.lining0806.com/spark与pandas中dataframe比对
3.观察从不同类型文件创建DataFrame有什么异同?
参考http://www.lining0806.com/spark与pandas中dataframe比对
4.观察Spark的DataFrame与Python pandas的DataFrame有什么异同?
参考http://www.lining0806.com/spark与pandas中dataframe比对
二.Spark SQL DataFrame的基本操作
创建:
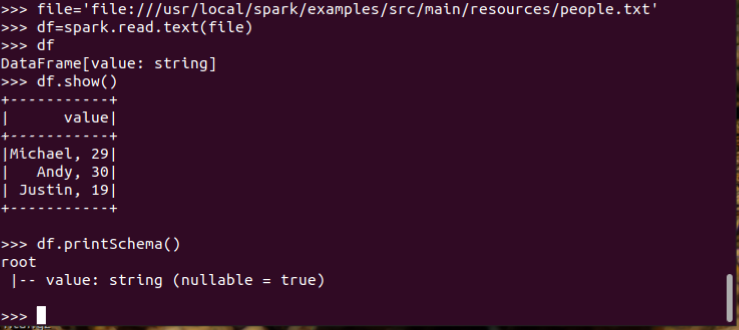
spark.read.text()
打印数据
df.show()默认打印前20条数据
打印概要
df.printSchema()
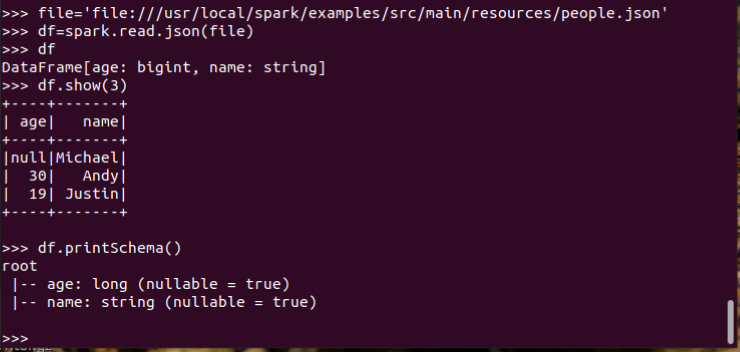
spark.read.json()
打印数据
df.show(n)
打印概要
df.printSchema()
查询总行数
df.count()

df.head(3) #list类型,list中每个元素是Row类

输出全部行
df.collect() #list类型,list中每个元素是Row类

查询概况
df.describe().show()

取列
df[‘name’]
df.name

df.select()

df.filter()

df.groupBy()

df.sort()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号