
【Kettle】Kettle入门解析(二)




(图片来源于网络,侵删)
Kettle实战1(将Hive表的数据输出到Hdfs)
【1】环境准备
1)进入Kettle的plugins\pentaho-big-data-plugin目录,编辑plugin.properties文件
根据自己的hadoop版本添加不同的类型,我的是cdh的,所以添加cdh514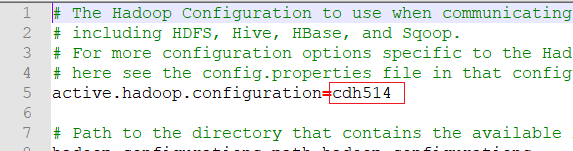
有哪些版本可以在该目录下查看plugins\pentaho-big-data-plugin\hadoop-configurations
2)修改完成后进入自己对应的版本,我的是cdh514,所以进入plugins\pentaho-big-data-plugin\hadoop-configurations\cdh514目录
将集群的Hadoop、Hive配置复制到该目录中
分别是core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、hive-site.xml
3)然后启动Kettle!!!
注意: 如果在连接Hive的时候报错Error connecting to database: (using class org.apache.hive.jdbc.HiveDriver) Illegal Hadoop Version: Unknown (expected A.B.* format),就将自己hadoop对应版本的hadoop-common.jar(我的是hadoop-common-2.6.0-cdh5.14.0.jar)放到根目录的 lib目录下,然后重启Kettle即可!
【2】在Hive中创建库表
前提:开启HDFS、Yarn、HiveMetaStore、HiveServer2
1)创建Kettle库
create database kettle;
use kettle;
- 1
- 2
2)创建Emp、Dept表
CREATE TABLE dept(deptno int, dname string,loc string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
- 1
- 2
- 3
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm int,
deptno int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3)插入数据
insert into dept values
(10,'accounting','NEW YORK'),
(20,'RESEARCH','DALLAS'),
(30,'SALES','CHICAGO'),
(40,'OPERATIONS','BOSTON');
- 1
- 2
- 3
- 4
- 5
insert into emp values
(7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20),
(7499,'ALLEN','SALESMAN',7698,'1980-12-17',1600,300,30),
(7521,'WARD','SALESMAN',7698,'1980-12-17',1250,500,30),
(7566,'JONES','MANAGER',7839,'1980-12-17',2975,NULL,20);
- 1
- 2
- 3
- 4
- 5
4)Kettle实战
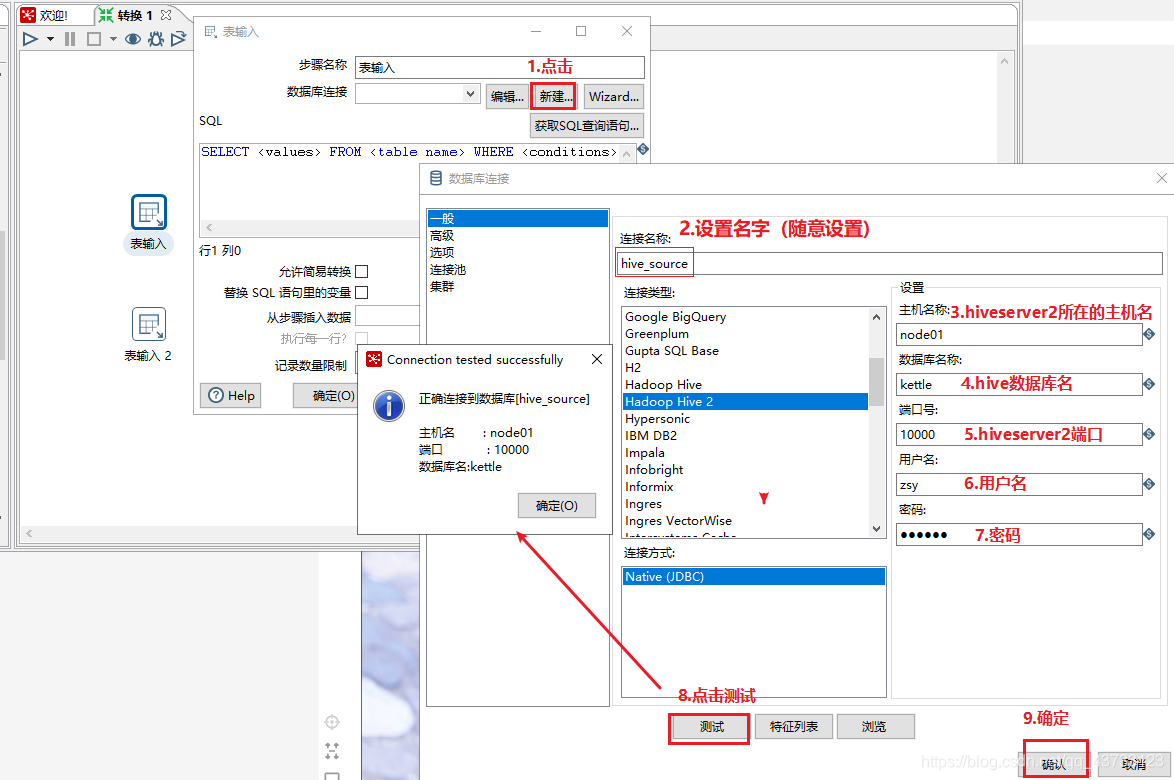
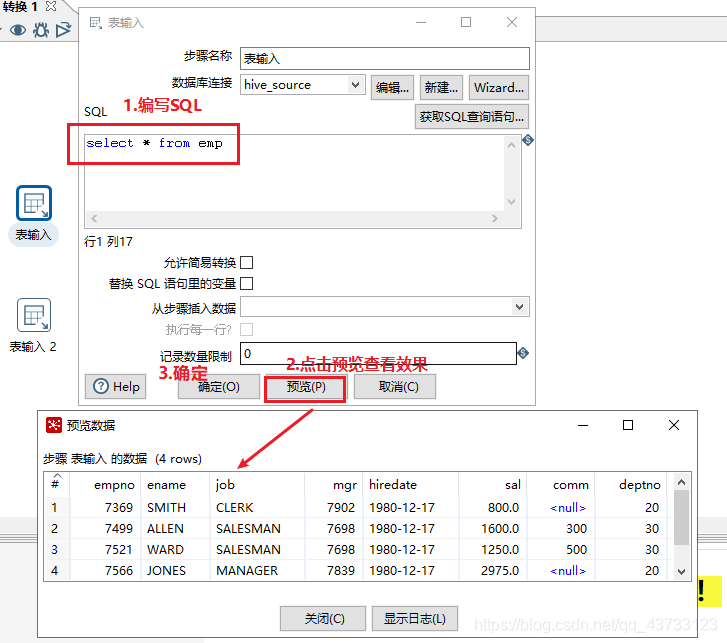
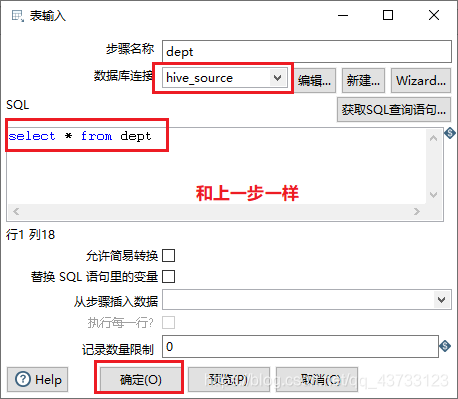
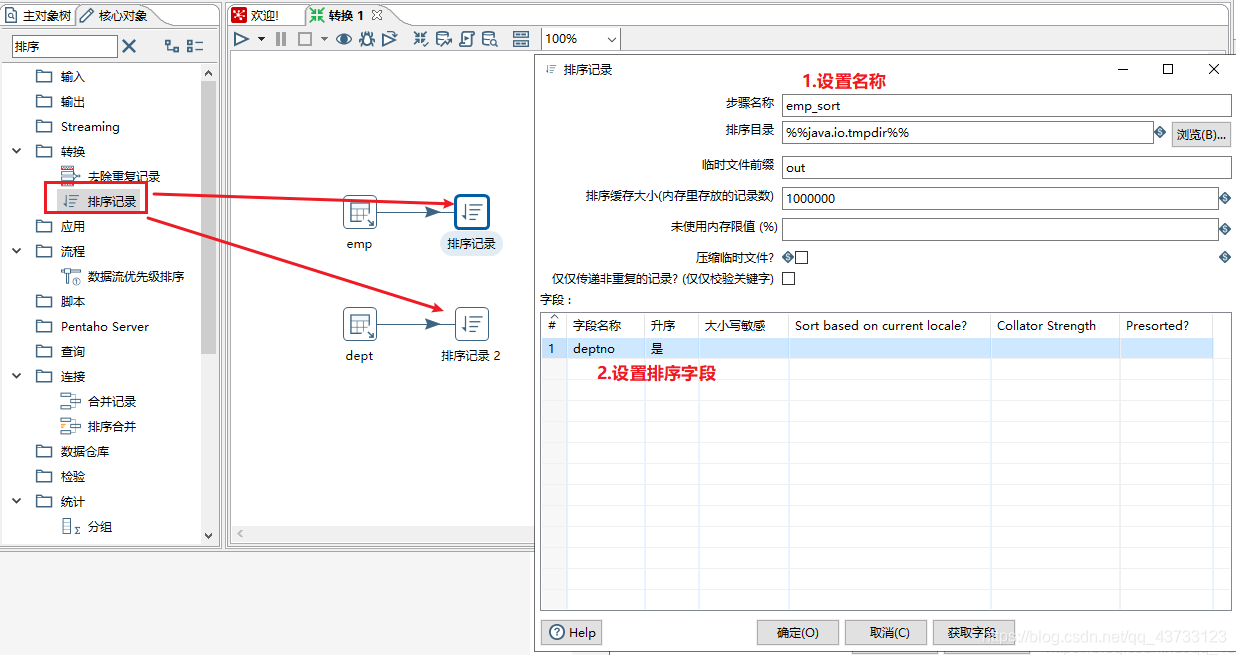

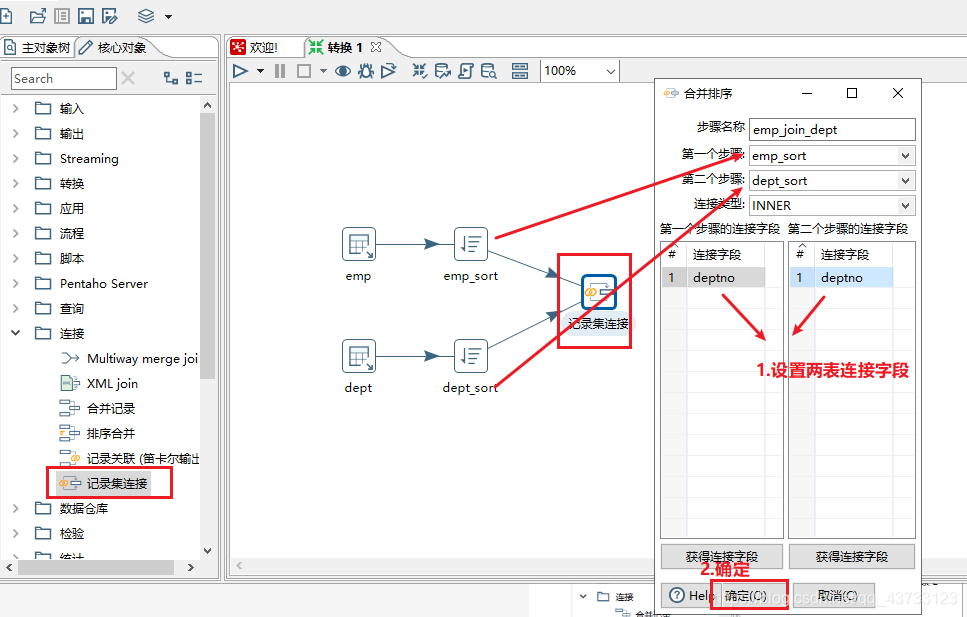

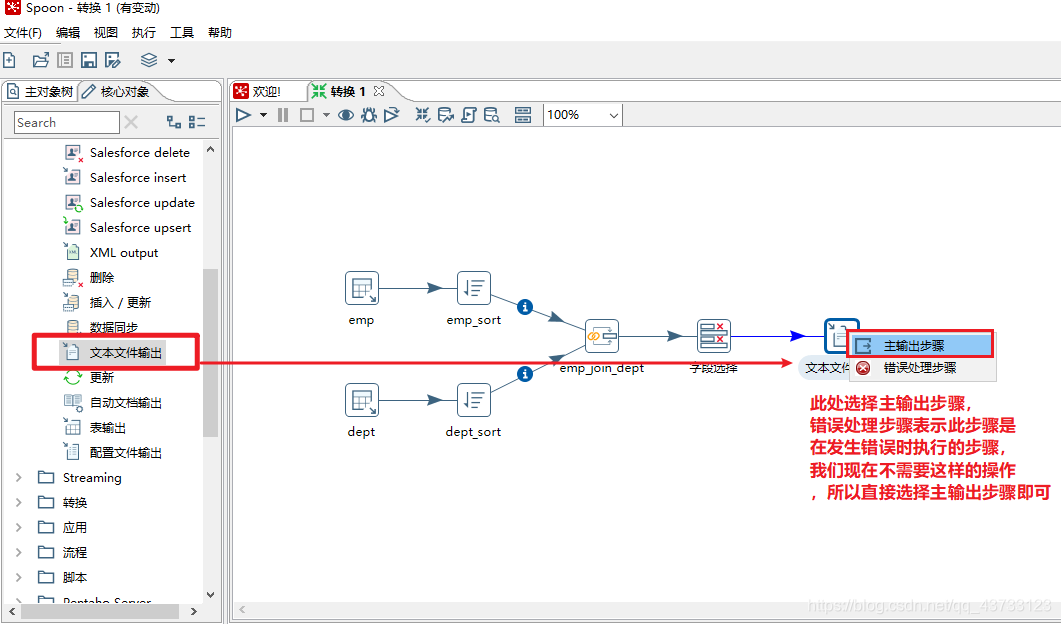
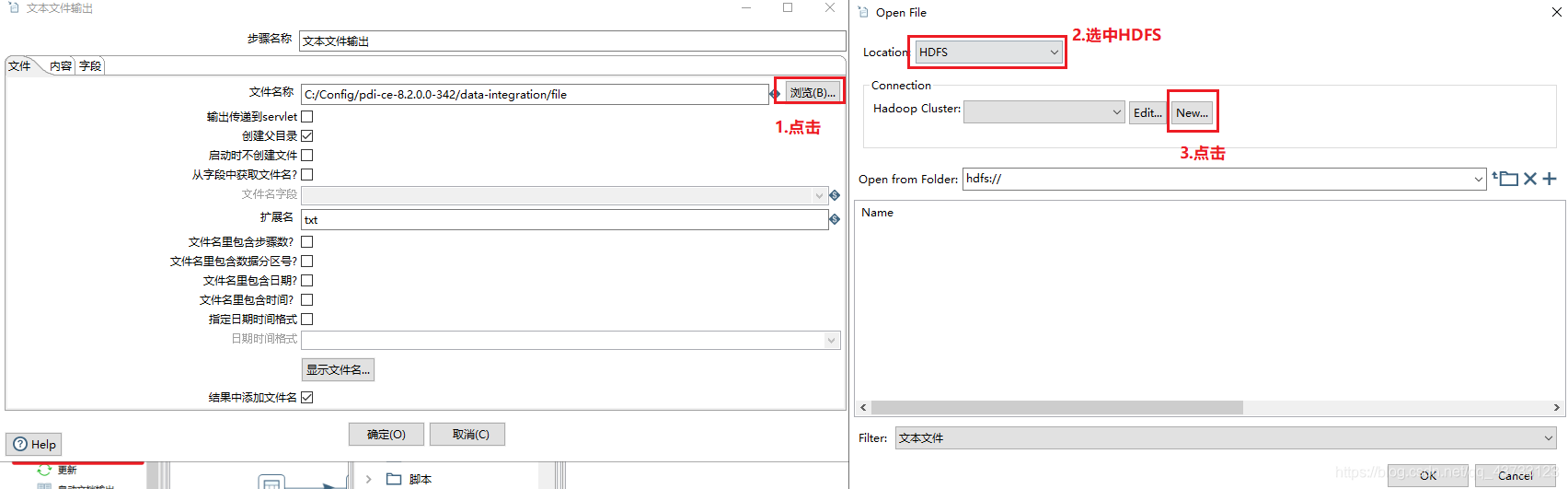


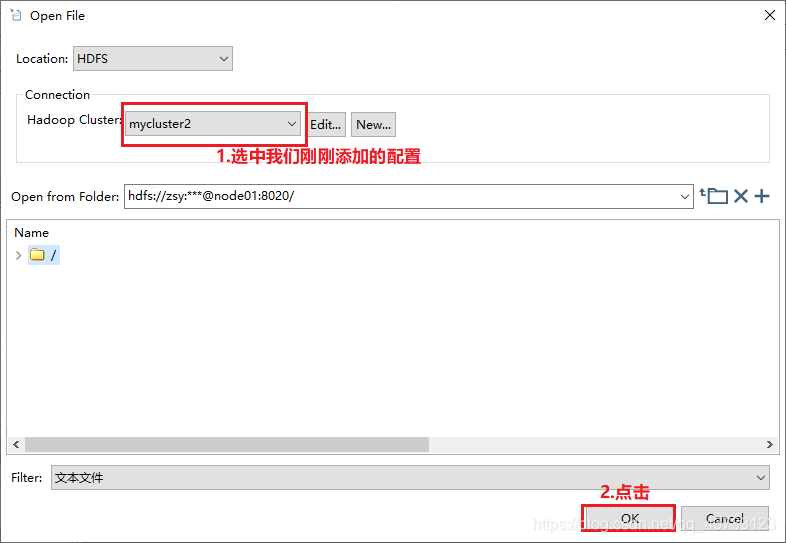

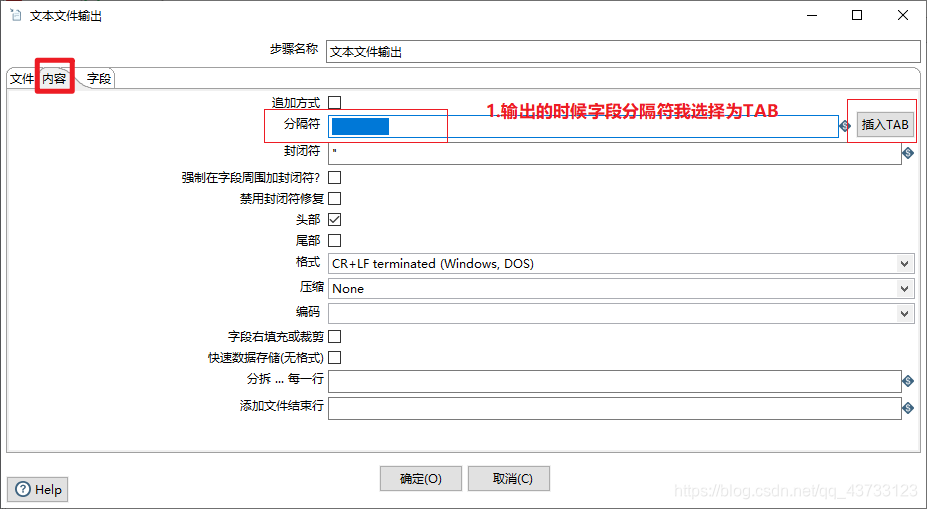

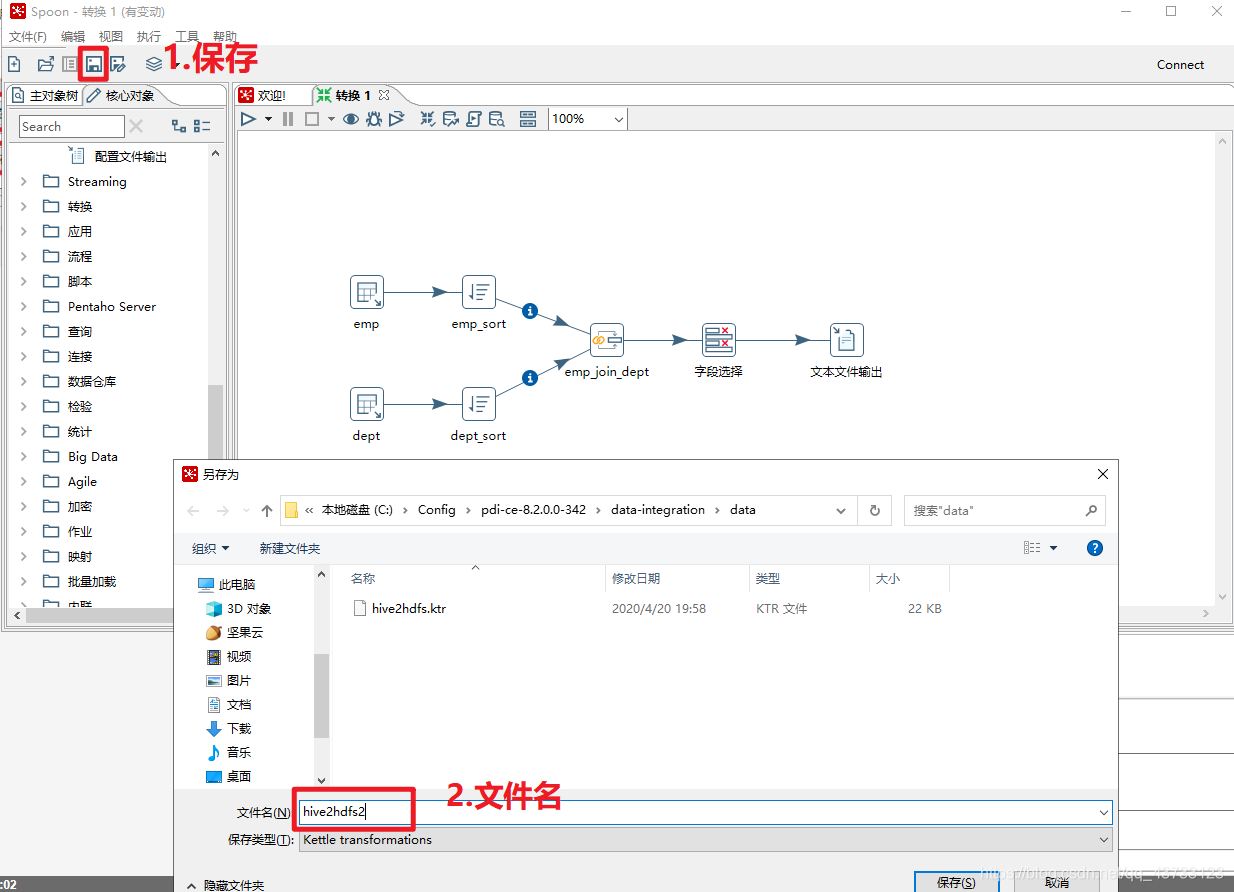
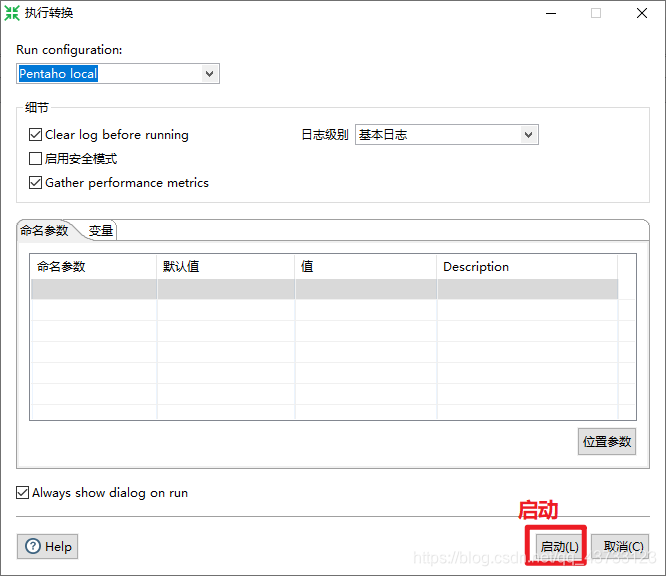
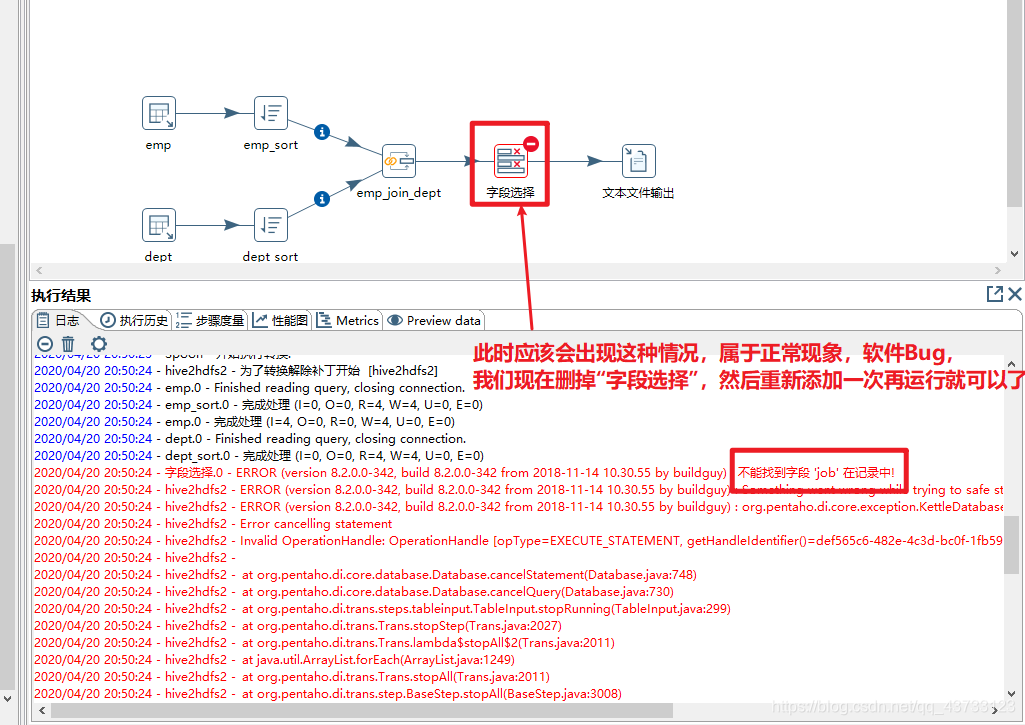
注意,虽然这里报了错,但是HDFS上已经生成了该文件,需要把HDFS上的空文件删除
重新执行之后结果如下👇
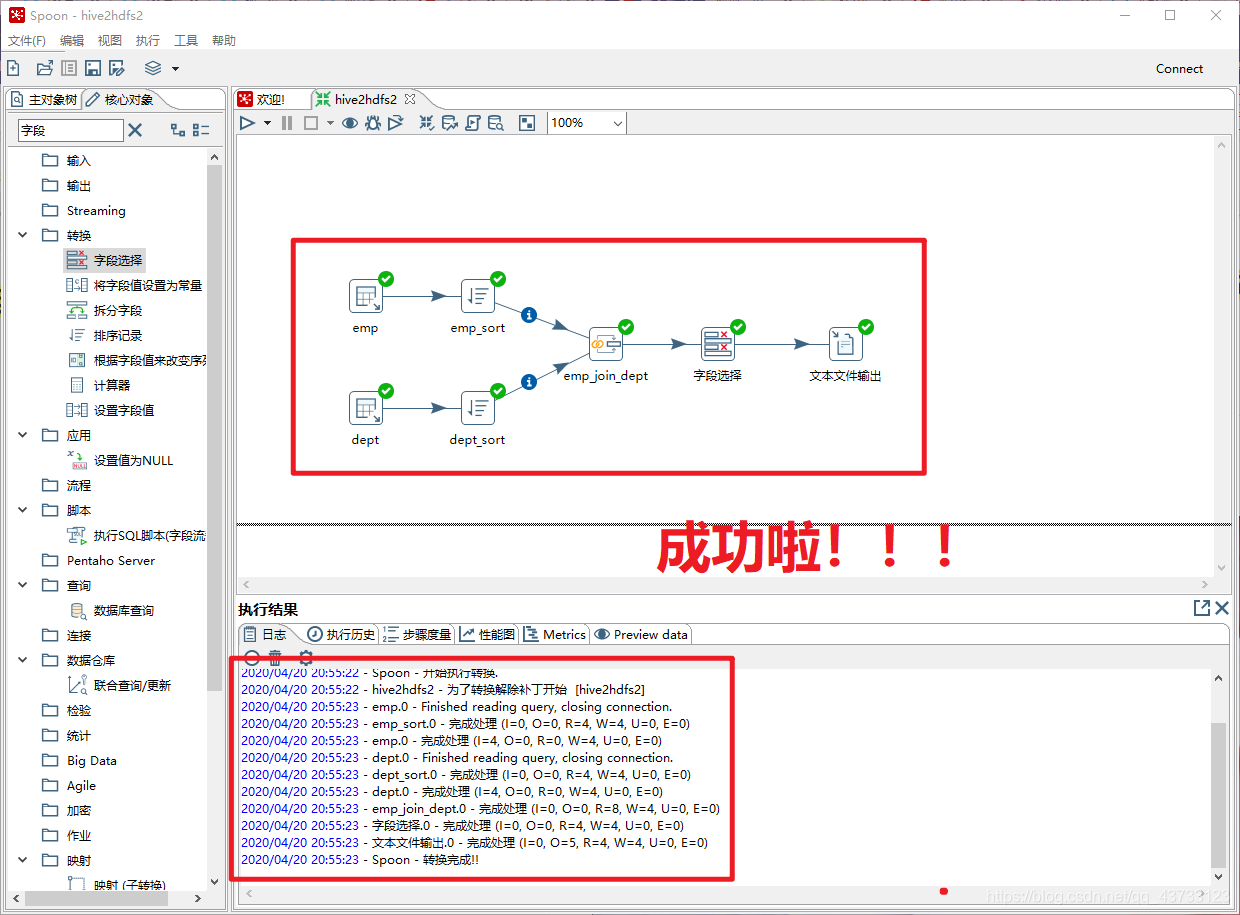
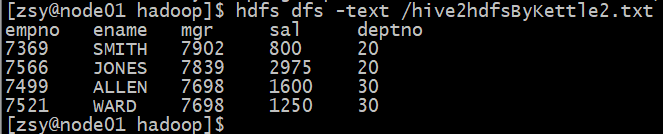
Kettle实战2(将Json数据选取指定列输出到Hdfs)
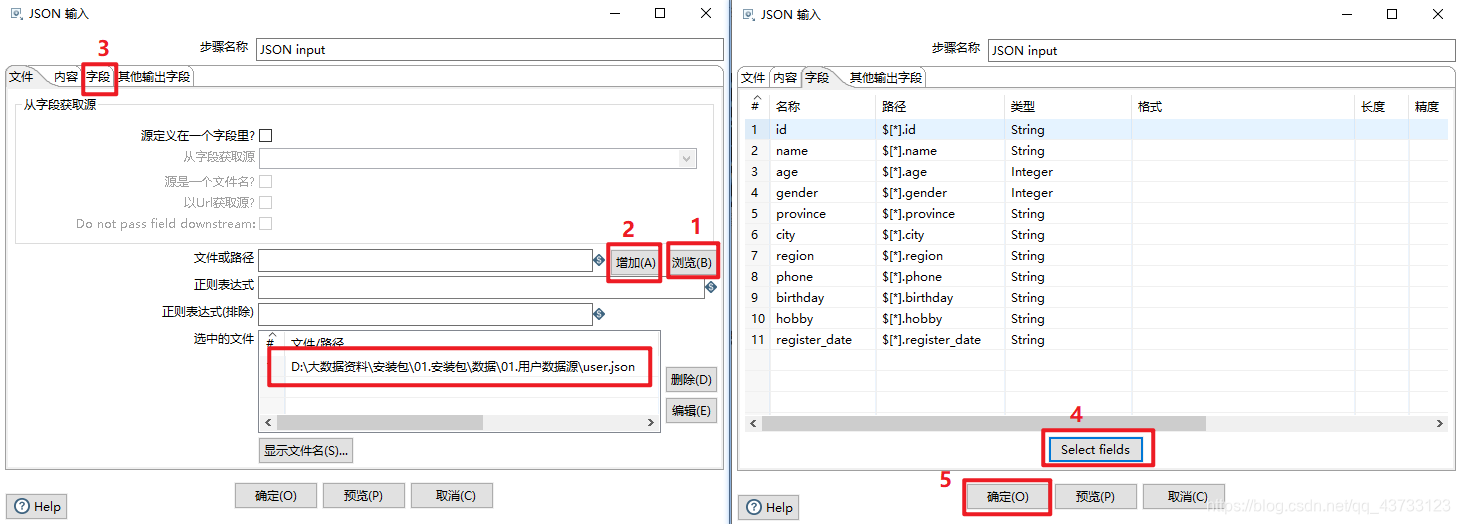
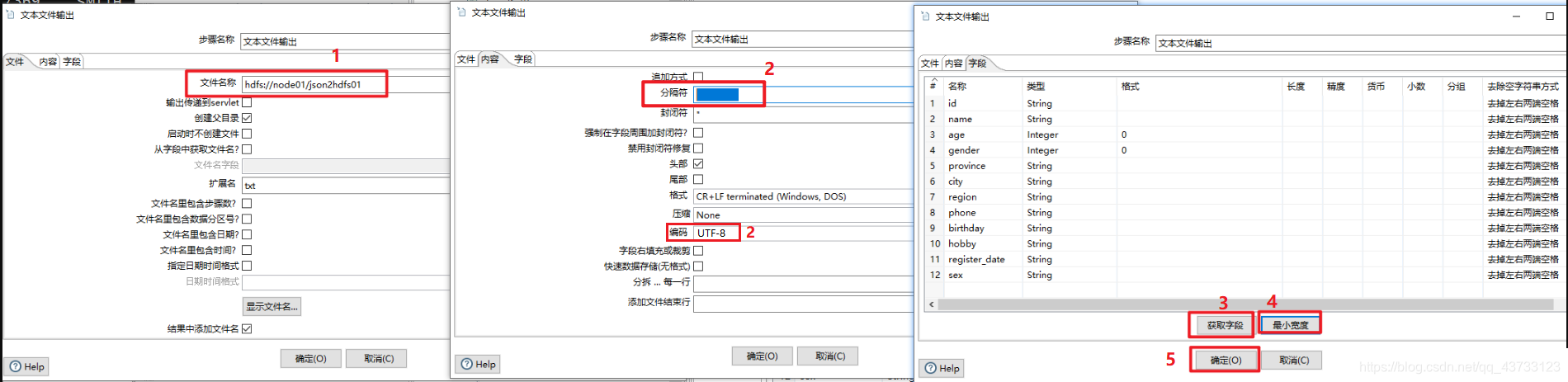


查看结果👇


 浙公网安备 33010602011771号
浙公网安备 33010602011771号