
机器学习概论
一、机器学习简述
机器学习是通过学习现有的训练数据,获得”知识“,然后把该”知识“应用到新的数据中。机器学习学习现有的训练数据主要分为四个步骤:(一)计算训练数据的特征,(二)选择学习模型,如逻辑斯蒂回归,支持向量机或决策树等模型;(三)确定代价函数,代价函数最小化对应的模型为最佳模型,相同的训练数据不同的代价函数可能会得到不同的最佳模型;(四)确定评价准则,根据评价准则选择模型最优结果对应的参数(参数择优)。机器学习的本质是应用统计学习,统计学习就是计算机系统通过运用数据及统计方法提高系统性能的机器学习。

大部分机器学习可以分为监督学习(supervised learning)和非监督学习(unsupervised learning),监督学习和非监督学习的区别在于是否事先知道训练样本的结果(若值为名义型(nominal),则为分类;值为数值型(numeric),则为回归)。
二、学习算法
模型最优化的过程即是求解代价函数的最小化,学习算法是如何实现代价函数的最小化。
前段时间在学习吴恩达老师的机器学习公开课课程,学习算法采用最多的是随机梯度下降算法(如吴恩达老师讲解的线性回归、逻辑斯蒂回归和支持向量机的代价函数最小化)。根据高等数学梯度原理:函数在该点的梯度方向是增长最快的方向,因此梯度下降算法选择了梯度的反方向,并根据步长(学习率)进行迭代,当满足实现设置的迭代数量或迭代前后的值小于一定的阈值时,则迭代结束,如下图。梯度下降算法是学习算法中最简单的代价函数优化算法,后续公众号文章将着重介绍各种学习算法的理论推导以及给出python代码。

三、机器学习任务
机器学习构建模型的步骤大同小异,获取训练样本的特征构建模型,然后对新输入的测试数据给出结果。
分类
如下图,每个手写数字是28×28的像素图像,可以用向量x表示该数字图像的特征,向量x包含了784维灰度图像,输入为特征向量x,输出为对应的数字0~9,通过训练大量的手写数字集构建分类模型。当输入新的未知手写数字的向量x时,模型给出分类结果0~9。

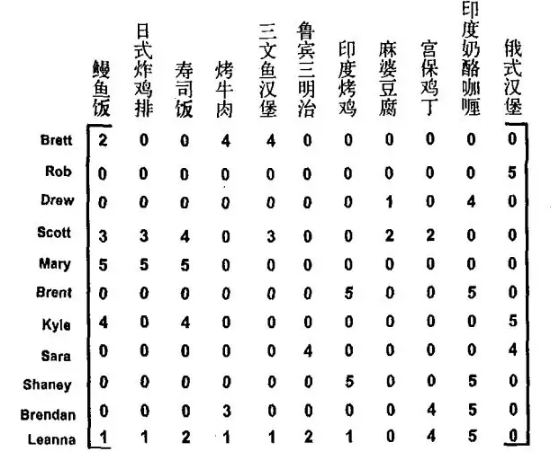
推荐系统
如下图,数据集中行代表用户user,列代表物品item,0代表用户未给物品打分。推荐系统的思想是:(1)计算用户要评价的物品与用户已经评分的物品之间的相似度,(2)根据相似度推算出用户要评价物品的分值。由于用户的评分数据是稀疏矩阵,奇异值分解(SVD)可以将数据映射为低维空间,然后在低维空间运用推荐系统的思想来对未评价的物品进行评分。
机器学习的应用领域非常广泛,比如回归任务,聚类,词语标注,目标检测等。还可以通过应用分成三大类,一个是对于图像的处理,还有一个是对于文本处理和语音,对于图像比如给图像着色,找出图像中的人脸,找出背景图,识别图片中的物体,描述一幅图像等。对于文本处理比如机器翻译,文本分类,文本的情感分析,文本总结,阅读理解等。语音可以是语音识别,生成语音等。
四、人工智能(AI)在医疗产业的应用
前段日子参加了在深圳市人才公园举行的智能医学研讨会,分享下自己比较赞同的关于AI在医疗产业的两个观点,(一)获取医疗样本数据较难,AI在医疗领域构建模型都是针对小样本数据,因此对模型的泛化能力提出了挑战;(二)AI在医疗产业的应用有很多条条框框的限制,如智能筛查癌症系统医疗器械在诊断测试者之前,需要对测试者进行入组判断,若不满足诊断条件则不予测试,这极大的限制了AI医疗产品在医院的推广。因此广州某医院影像中心的教授说未来人工智能在疾病筛查系统不可能完全代替人工筛查,但是人工智能可以在大量耗时的重复工作发挥重要作用,医生可以把节省下来的时间作学术研究工作。
参考:
《机器学习实战》 李锐 李鹏等译
《Pattern Recognition and Machine Learning》 Christopher M.Bishop
《统计学习方法》 李航
https://www.jianshu.com/p/22998509f00c
https://www.cnblogs.com/pinard/p/5970503.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号