

浏览器的工作原理前置知识
线程与进程:
线程是能单独存在的,他是由进程来启动和管理的,启动一个程序的时候,操作系统会为改程序创建一块内存,用来存放代码、运行中的数据和一个执行任务得主线程,这样的运行环境叫进程。
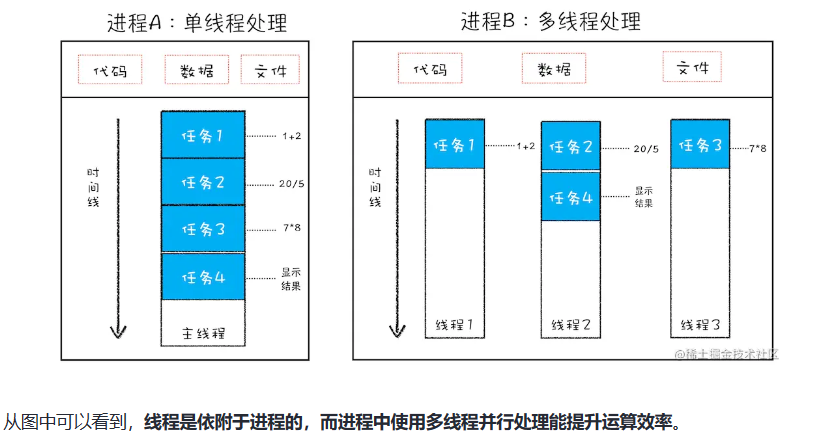
线程与进程的关系特点:
1.进程中的任意一线程出错,都会导致整个进程的崩溃。
2.线程之间共享进程中的数据。
3.当一个进程关闭之后,操作系统会回收进程所占用的内存
4.进程之间相互隔离
浏览器的模块:
网络、插件,js运行环境,渲染引擎,页面
目前浏览器的进程框架:
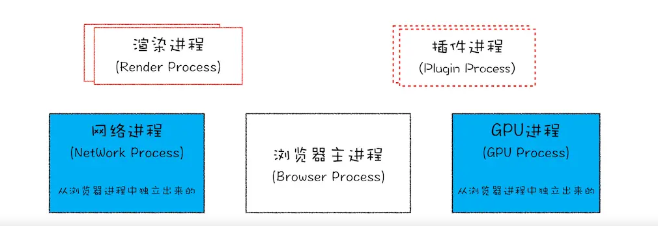
浏览器进程:界面显示,用户交互,子进程管理,同时提供储存功能。
渲染进程:将HTML,CSS和JavaScript转换为用户可以与之交互的网页。
GPU进程:实现3DCss效果,绘制UI界面。
网络进程:负责网页的网络资源加载。
插件进程:负责插件的运行。
HTTP请求流程:(八个阶段)
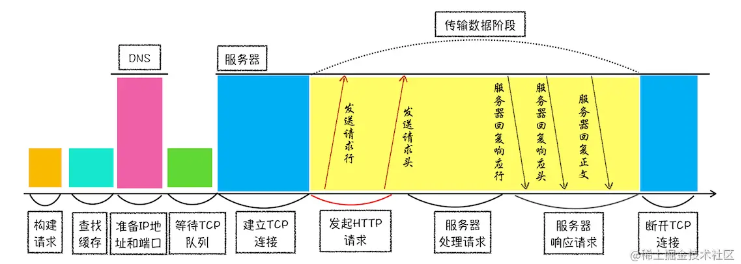
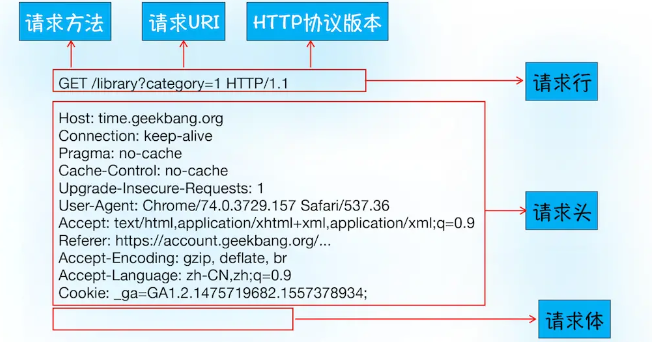
1.构建请求:浏览器构建请求行信息,构建好后,浏览器准备发起网络请求。
GET /index.html HTTP1.1
2.查找缓存:在发起网络请求之前,浏览器会现在浏览器缓存中查询是否有要请求的文件。(有副本则会拦截请求,返回资源副本,并直接结束请求)
3.准备IP地址和端口。浏览器使用HTTP协议作为应用层协议,用来封装请求的文本信息,使用TCP/IP作为传输层协议将它发送到网络上。所以在http工作前,浏览器通过tcp与服务器建立连接,也就是说http的内容是通过tcp的传输数据阶段来实现的。
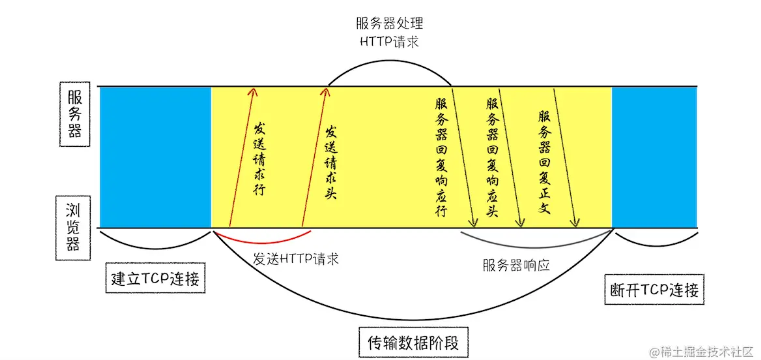
4.等待tcp队列
以Chrome浏览器为例,Chrome 有个机制,同一个域名同时最多只能建立 6 个 TCP 连接,如果在同一个域名下同时有 10 个请求发生,那么其中 4 个请求会进入排队等待状态,直至进行中的请求完成。
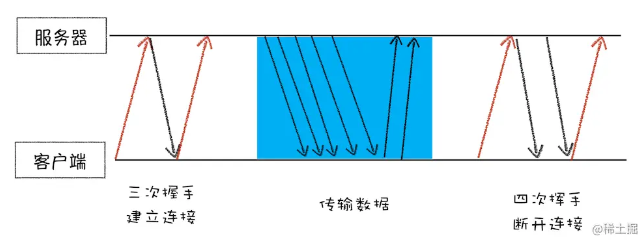
5.建立tcp连接
一个完整的tcp连接生命周期包括了“建立连接”“传输数据”“断开连接”三个阶段。
6.发送http请求
7.服务器端处理http请求流程
8.返回请求: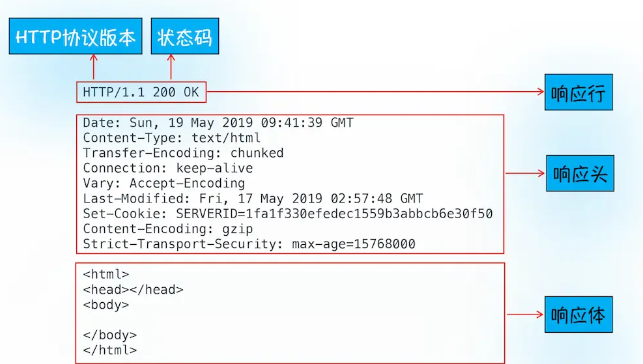
9.断开连接
一般情况下,服务器发送完数据后,就要关闭tcp连接,但是当Connection:Keep-Alive时tcp连接会仍然保持,这样浏览器就可以通过一个tcp连接发送请求,保持tcp连接可以审下去需要连接的时间提升资源加载速度。
导航流程:从输入URL到页面展示,这中间发生了什么
整体流程
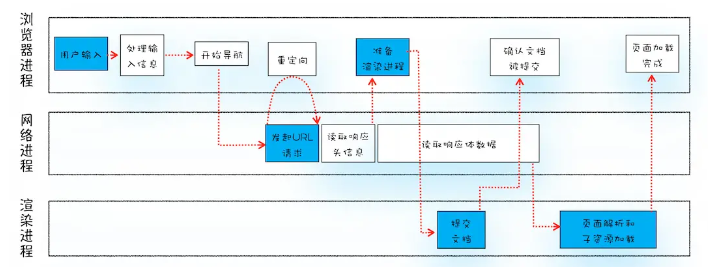
1.浏览器进程发出URL请求给网络进程。
2.网络进程接收到URL请求后,发起网络请求,然后服务器返回http数据到网络进程,网络进程解析http响应头数据,并将其转发给浏览器进程
3.浏览器进程接受到网络进程的响应头数据后,发送CommitNavigation消息到渲染进程,发送CommitNavgation时会携带响应头,等基本信息。
4.渲染进程接受到CommitNagation消息之后,便开始准备接受HTML数据,接受数据的方式是直接和网络进程建立数据管道。
5.最后渲染进程会向浏览器“确认提交”,这是告诉浏览器进程,已经准备好接受和解析页面数据了。
6.浏览器进程更新页面状态。
分析整体流程
1.用户输入url
用户输入完url,按下回车键,浏览器导航栏显示loading状态,但是页面还是呈现前一个页面,这是因为新页面的响应数据还没有获取,这里有一个beforunload事件
改事件允许页面退出之前执行一些数据的清除操作,还可以询问用户是否离开当前页面,可以通过beforeunload事件来取消导航,让浏览器不在进行后续工作。
2.url请求过程
浏览器进程将构建请求行数据,进行进程间通信(IPC)将url请求发送给网络进程类似于下面这个
GET /index.html HTTP1.1
3.网络进程获取到url,先去本地缓存中查找是否有缓存文件,如果有,拦截请求。直接200返回;否则,进入网络请求过程。
4.网络进程请求dns返回域名对应的ip和端口号,如果之前dns数据缓存服务器缓存过当前域名信息,就会直接返回缓存信息;否则,发起请求获取根据域名解析出来的ip和端口号,如果
没有端口号,http默认80,https默认443.如果是https请求,还需要建立tls连接。
5.在进程tcp连接的过程中,Chrome有一个机制,同一个域名下只能建立6个tcp连接,如果在同一个域名下有10个请求发生,那么其中4个请求会进入等待转台,直到进行中的请求完成。
6.tcp三次握手建立连接,http请求加上tcp头部——包括源端口号,目的程序端口号和用于校验数据完整的序号,向下传输。
7.网络层在数据包上加上IP头部——包括源IP地址和目的IP地址,继续向下传输到底层
8.底层通过物理网络传输给目的服务器主机,紧接着目的服务器主机网络层接收到数据包,解析出IP头部,识别出数据部分,将解开的数据包向上传输到传输层。
9.目的服务器主机传输层获取到数据包,解析出TCP头部,识别端口,将解开的数据包向上传输到应用层
10.应用层http解析请求头和请求体,如果需要重订向,HTTP直接返回http响应数据的状态code301或302同时在请求头的Location字段中重定向地址
,浏览器会根据code和Location进行重定向操作;如果不是重定向,首先服务器会根据请求头中的If-None-Match的值来判断请求的资源是否被更新,
如果没有更新,就返回304状态码,告诉浏览器之前的缓存还可以使用,就不返回数据了;否则,返回新数据,200的状态码,如果想要浏览器缓存数据,就在响应的头中加入字段
Cache-Control:Max-age=2000
响应的数据又顺着应用层-——传输层——网络层——网络层——传输层——应用层的顺序返回到网络进程。
11.数据传输完成,tcp四次挥手断开连接,如果,浏览器或者服务器在http头部加上如下信息,tcp就会一直保持连接。保持连接可以省下下次建立连接的时间,提升资源加载速度
Connection:Keep-Alive
12.网咯进程将获取到的数据包进行解析,根据响应头中的Content-type来判断响应数据的类型,如果是字节流类型,就将该请求交给下载管理器;如果是text/HTML类型
就通知浏览器进程获取到文档准备渲染。
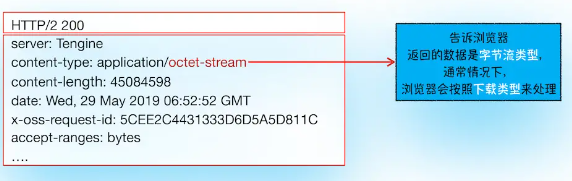
从返回的响应头信息来看,其Content-Type的值是application/octet-stream,显示数据是字节流类型的,通常情况下,浏览器会按照下载类型来处理该请求
需要注意的是,如果服务器配置Content-Type不正确,比如将text/html类型配置成application/octet-stream类型,那么浏览器可能会曲解文件内容比如会将一个本来展示的页面,变成一个下载文件。
13.浏览器进程获取到通知,根据当前页面b是否是从页面a打开的并且和页面a是否是同一个站点(根据域名和协议一样就被认为是同一个站点)如果满足上诉条件,就复用之前网页的进程,否则,新创建
一个单独的渲染进程。
14.浏览器会发出“提交文档”的消息给渲染进程,渲染进程收到消息后,会和网络进程建立传输数据的“管道”,文档数据传输完成后,渲染进程会返回“确认提交”的消息给浏览器进程。
15.浏览器收到“确认提交”的消息后,会更新浏览器的页面状态,包括安全状态,地址栏url,前进后退的历史状态,并更新web页面,此时的web页面是空白页
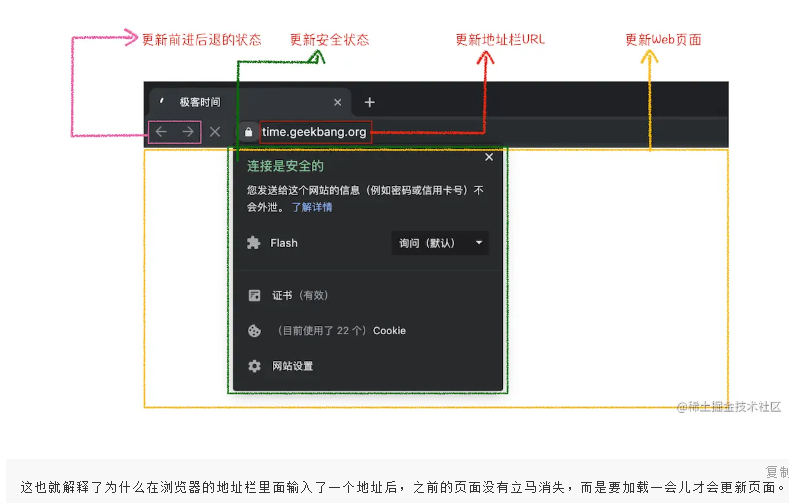
16.渲染进程对文档进行页面解析和子资源加载,HTML通过HTML解析器转成DOM Tree( 二叉树类似结构的东西),css按照css
规则和css解释器转成cssom tree ,两个tree结合,形成render tree (不包含HTML的具体元素和元素要画的具体位置),通过Layout可以计算出每个元素
具体的宽高颜色位置,结合起来,开始绘制,最后显示在屏幕中新页面显示出来。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号